背景
我们介绍了站点的破解的基本方法和站点破解的站点类型,在知道怎么破解其他站点的同时,我们也要对自己的站点提高防御,避免被他人破解。
防御手段
服务端返回加密和混淆后的内容
浏览器的开发者工具有很强大的搜索功能,根据某个字符串,可以搜索出这个字符串出现的所有地方,无论是在HTML页面,还是js文件,还是接口返回的数据和头部都能搜出来。这样破解者就能很容易的根据页面渲染出来的视频地址找到该地址的来源。
为了加大破解难度,我们需要屏蔽搜索,具体做法如下:
- 首先服务端返回的数据必须进过编码或者加密处理,客户端拿到数据之后再经过解码或者解密还原。这样子破解者就不能轻易的根据渲染出来的地址来搜索了,最简单的实现方式是通过base64编码。
- 其次,代码里的关键字段,不要太语义化,太语义化的字段很容易看出来他是干什么的。比如用来记录视频地址的字段是“videoUrl”,这样破解者一眼就看出它是什么,然后可以根据这个关键字来搜索代码。非语义化的代码可能在开发时比较不友好,那么我们可以定制好统一逻辑,在js代码使用构建工具构建的时候,通过自己编写插件和对应的映射表来统一修改,这样即不影响开发,又能在线上去语义化。
- 另外关键的字符串也不要直接写全在代码里,可以通过拼接的方式来写,比如字符串“abcd”可以写成“ab” + “cd”,这样破解者就很难搜索了。
提高逻辑复杂度
通过加密和混淆可以屏蔽搜索,但是如果代码逻辑太简单,那么破解者根据不需要搜索,就能很容易的破解出来了。所以我们还需要增加站点的复杂度,具体是获取到视频信息的复杂度,有如下做法:
- 视频信息通过鉴权接口获取
首先视频信息不能直接通过服务端渲染直接写在HTML页面里,不管有没有进过加密,这样都太简单了。视频信 息应该通过异步的接口请求得到,而且这个接口是带鉴权的。
接口的鉴权签名生成,可以在服务端生成,然后再返回给客户端,客户端就可以直接拿改签名请求视频信息接口,这样的好处是生成签名的key不必暴露在客户端,比较安全,所以我们也是推荐用这种方式。但是服务端生成签名也需要异步请求,不能直接在返回HTML文件的是直接写在HTML文件上,而且请求该接口的时候,也需要通过关键的参数加密后请求,大致流程如下图: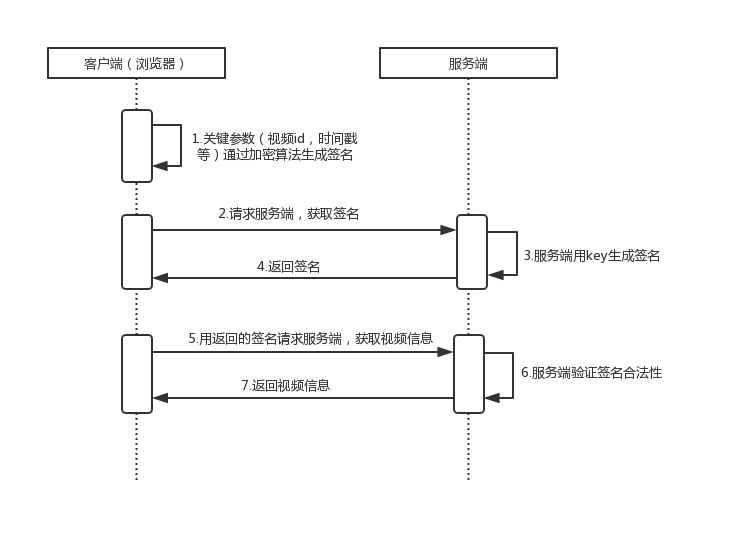
- 鉴权签名生成逻辑尽量复杂
在第一步,通过关键参数生产签名的时候,我们用的加密算法应该尽量的复杂,而且是自定义的,参数的加入过程和生成的过程也要尽量曲折。服务端返回签名的时候也可以隐藏签名或者分多次返回。总之就是越复杂越曲折越好。
- 动态生成代码
我们可以通过动态生成签名算法,把部分签名算法写在服务端,客户端通过接口请求到代码,再通过eval函数执 行代码,这样我们可以通过参数生成动态的签名算法,也可以随时改变算法逻辑。
- 善于伪装和隐藏
请求接口不要太语义化和明显,不然很容易找到,我们可以把关键信息的接口进行伪装,比如写成日志接口的形 式混杂在普通接日志接口里面。数据的返回也不一定要写在body里,还可以写在header里。
举例,通过伪装的接口生成动态代码,并执行,从而反转某个值:
接口:/log?a=xxx&xxxx=xxxx,(看起来就是一个日志接口~)
页端请求代码:
let key = 'this is key'; //需要反转的数据fetch('http://127.0.0.1:3001/log?a=key').then((res)=>{return {'my-header': res.headers.get('my-header') // 从头部获取到代码};}).then((data)=>{eval(atob(data['my-header'])); // 解码并执行代码console.log(key); // 输出值}).catch((error)=>{console.log(error);});
服务端代码:
module.exports = async ctx => {let keyword = ctx.request.query.a;let code = `${keyword}=${keyword}.split("").reverse().join("")`; // 动态代码,字符串反转code = new Buffer(code).toString('base64'); // base64 编码ctx.set('my-header', code); // 写入头部ctx.set('Content-Type', 'image/jpeg'); // 伪装成logctx.body = '';}
看返回和执行结果: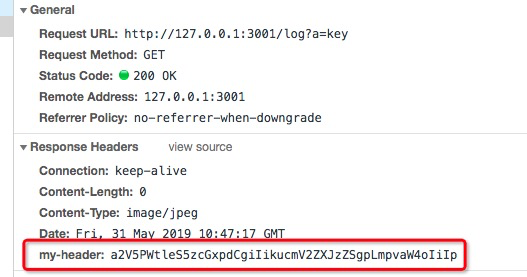
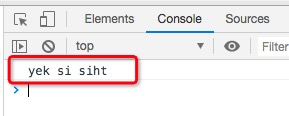
控制台输出了反转后的值。
这是一个比较简单的例子,还有很多地方可以扩展和加强,总之可以通过这种思路,把流程和信息伪装和隐藏,让破解者难以发现。
页端反调试
经过上面的加密和复杂的逻辑处理,我们的站点就比较安全了呢?答案是否定的。我在解析站点的时候也发现部分站点的逻辑和加密都做得很好,让人很难破解,但是最终还是通过浏览器提供的调试工具成功的破解了这些站点。
浏览器的调试工具太强大了,经过调式,可以很容易的跟踪函数调用,从而知道签名和加密的算法。所以我们的目标是让破解者无法使用调式工具,或者在调式的时候导到错误的逻辑里来混淆对方。
思路很简单,我的页面在正常访问的情况下,正常的运行,但当破解者打开浏览器的开发者工具的时候,我们就执行另一套逻辑,或者开启无限循环的断点,从而误导破解者或者不让破解者调试。
做到这些的前提,我们需要知道破解者有没有打开开发者工具,索性浏览器的特性让我们可以这样做。除了火狐浏览器,绝大多数的浏览器在使用console.log()输出dom的时候,都会访问该dom的id属性,我们可以通过设置id的getter来判断用户有没有打开开发者工具,如下:
var opened = false;var element = document.createElement('div');Object.defineProperty(element, 'id', {get: function(){opened = true;}});console.log(element);
火狐浏览器则可以通过输出正则表达式来判断,通过console.log()输出正则表达式,会调用其toString()方法:
var opened = false;var devTools = /./;devTools.toString = function() {opened = true;}console.log(devTools);
我们把上面两个方法写成一个通用的检查方法,然后定时去检测,就能及时了阻止开发者调式了:
function isDevToolsOpened() {var opened = false;if (navigator && navigator.userAgent && navigator.userAgent.indexOf('Firefox') > -1) {var devTools = /./;devTools.toString = function() {opened = true;}console.log(devTools);} else {var element = document.createElement('div');Object.defineProperty(element, 'id', {get: function() {opened = true;}});console.log(element);}console.clear && console.clear();return opened || false;}setInterval(() => {if (isDevToolsOpened()) {// 检测到用户打开开发者工具,开启无限断点~while (true) {eval('debugger;');}}}, 1000);
通过这段代码的控制,用户没有打开浏览器的开发者工具的时候,页面会正常运行,只要用户打开浏览器开发者工具,页面就会陷入无限的点断状态,从而阻止用户调式。
现在我们已经加上了反调试机制,那么对手就没有办法轻易破解了吧~ ^_^
NO~!非常不幸的是,Chrome实在是太强大,在59版本之后,推出了Headless Chrome,一个无界面形态的Chrome,同时推出 Puppeteer Node.js库,puppeteer库提供了一个高级 API 来通过 DevTools 协议控制 Chromium 或 Chrome。puppeteer的使用教程这里就不详细说明了。
使用puppeteer,还可以拦截页面发出的请求,并且改变返回的数据,通过这些功能特性,破解者可以正常的调式我们经过反调试处理的页面。
方法很简单,找到检测开发者工具大代码文件,并保存到本地,注释掉检测部分的代码。然后使用puppeteer打开Chromium,拦截该文件的请求,并返回我们修改后的文件就可以了~
来看代码,我们把检测部分的代码直接写在html文件上,正常情况下打开开发者工具,页面被debug中。
接下来我们使用puppeteer来打开页面,代码如下:
const puppeteer = require('puppeteer');const fs = require('fs');(async function() {const browser = await puppeteer.launch({timeout: 15000,headless: false, // 使用页面模式devtools: true, // 默认开启开发者工具});const page = await browser.newPage();// 开启请求拦截await page.setRequestInterception(true);page.on('request', request => {// 如果请求的url是目标url,则返回本地修改过的文件if( request.url() == 'http://127.0.0.1:3001/index.html'){let body = fs.readFileSync(__dirname + '/file/replace.html');request.respond({status: 200,contentType: 'text/html; charset=utf-8',body: body,});}else{// 不做处理,放行请求request.continue();}});// 访问页面await page.goto('http://127.0.0.1:3001/index.html').catch((err) => {console.log('get page err', err);page.close();return;});})();
运行之后看到效果如下,检测的代码被注释掉了: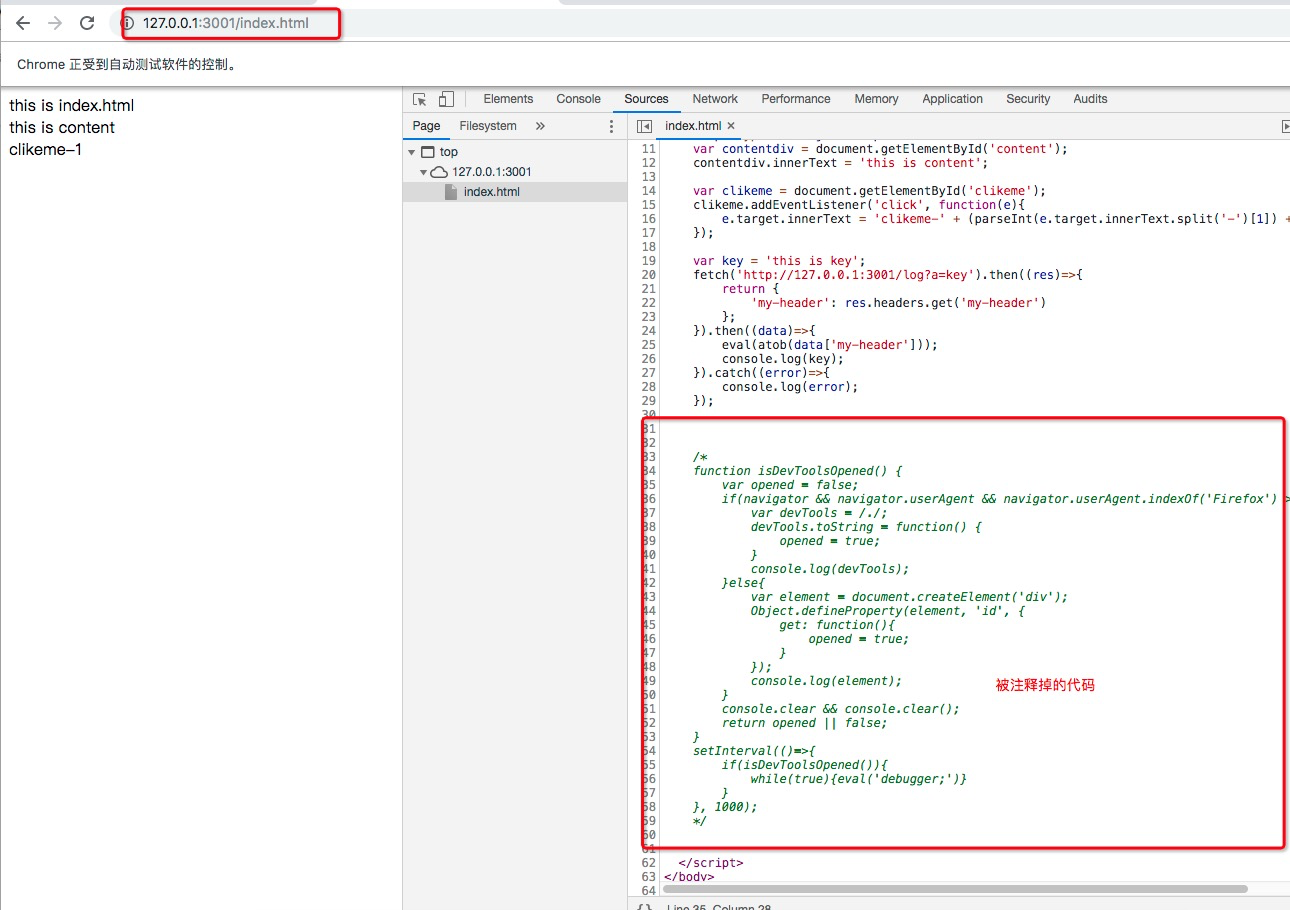
通过使用puppeteer的处理,我们依然可以继续调试页面程序。但是这不能说明我们做的反调式功能没有用,它虽然还是能被破解,但是这个破解门槛已经比较高了,可以拦截很大部分破解者。再说就算我们的程序做得再复杂,源码始终都是暴露出来的,实在不行,也完全可以把代码全部保存到本地之后再慢慢看,而反调试机制至少能人破解者感到恶心吧~
防服务端渲染解析
通过上面的一系列处理,正常的人工解析已经比较难了。但是破解者可以利用服务端渲染解析页面的方式来破解我们的防御,如使用htmlunit,PhantomJS,Chrome-headless等技术。
一旦破解者使用服务端渲染解析页面,在不折损用户体验的条件下(如使用变态的验证码),我们就很难在阻止破解者来破解我们的站点了,唯一能做的就是让破解者不那么轻易的用通用方式来处理我们的站点。
首先我们先了解一下,服务端渲染能怎么破解我们的站点,我们再根据这些方式,来做防御。
- 能模拟浏览器的运行,然后轻易的获取到video的DOM对象,再获取到里面的src属性。
- 能拦截请求和伪造请求响应,然后破解我们做的反调式机制。
- 能得到所有的请求数据,然后得到视频地址URL,或者直接得到视频。
针对第一点,我们的页面在渲染的时候,先不马上渲染video标签,等用户点击播放视频的时候,才动态的创建video标签,并且video标签的src属性不能直接使用视频地址,而是使用Blob对象生成的url(blob:http://XXX),
这样破解者就不能轻易的得到video的DOM对象,需要模拟用户点击播放按钮后才能得到video的DOM对象,得到video的DOM后,也不能得到真正的视频url。
针对第二点,我们可以吧反调试逻辑放在多个文件,并且跟正常播放逻辑混淆,让破解者不能轻易的过滤文件并注释掉。
针对第三点,我们可以伪造几个请求,返回跟视频一样的Content-Type和Content-Length,或者把视频分片,在播放的时候再分别请求。
总结
因为前端的代码始终是暴露在用户端的,所以不管我们如何防御,破解者总有办法破解我们的防御,我们能做的只是在不折损用户体验的前提下,提高破解难度,阻止大部分的破解而已,不能百分之百的防御。

若有收获,就点个赞吧
0 人点赞
