1.Flash型
例子:1905.com
尽管 flash 已经是很落伍的技术了,而且Chrome对 flash 的支持也不那么友好了,但是目前国内的大多数网站,PC端的页面仍然使用着 flash 播放器,一些大网站已经渐渐改用H5播放器。
一般解法
大多数使用flash播放器的站点的解析逻辑跟普通站点差不多,甚至会更好解,因为在flash播放器标签里,通过flashvars属性,很容易就能找到请求视频信息的接口。
以cctv.com为例,在播放器的flashvars属性里找可疑的关键字,然后再到network里面筛选一下,就能找到请求视频信息的接口了,如下图:
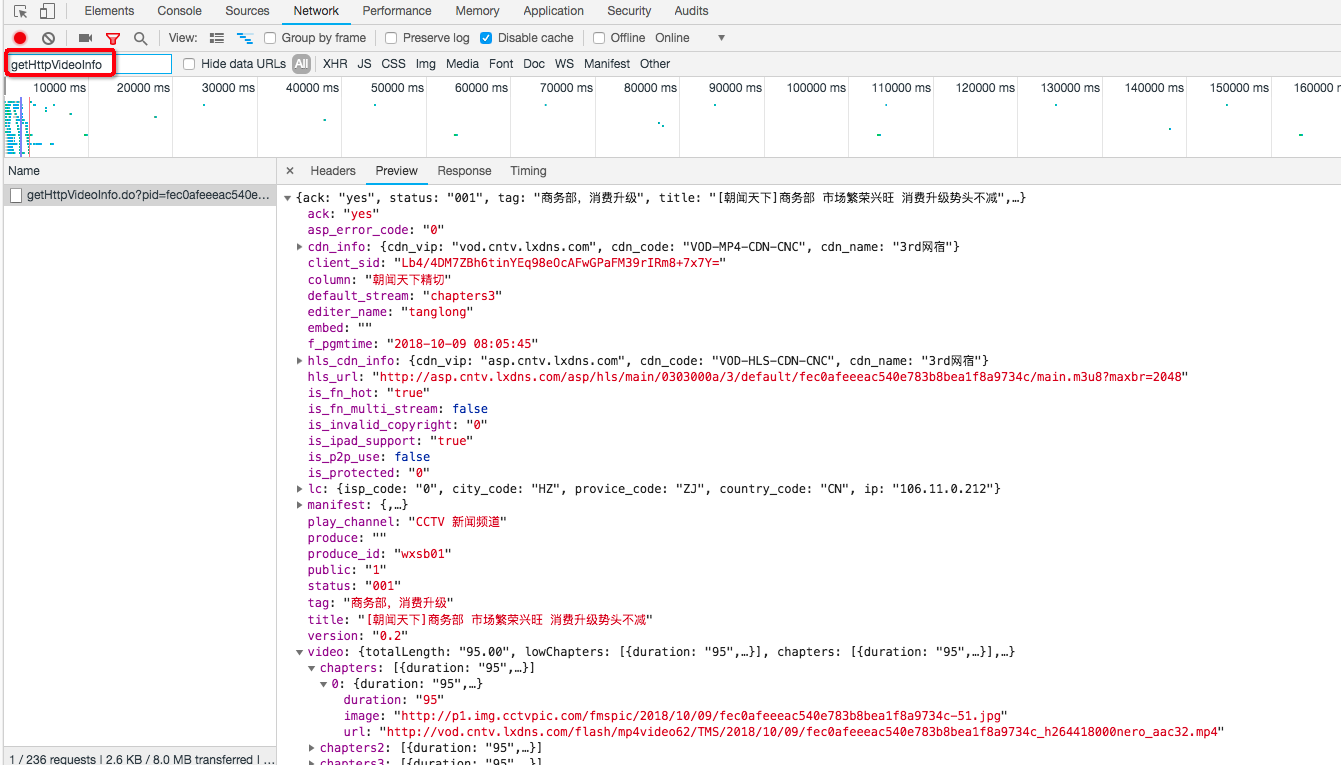
可以试试拿到的视频地址是否能播放或者下载,如果可以,那么解析成功。
反编译flash播放器
flash播放器是打包好的一个swf文件,里面有用ActionScript编写的代码逻辑。在页面上,播放器标签通过flashvars属性,把参数传给flash播放器,形式是query string,比如 ‘a=1&b=2&c=3’,都是自定义的,然后在flash播放器中可以取到flashvars,再做相应的逻辑处理,包括视频信息的获取,都是从flash播放器发出的请求,当然获取到的视频信息也只能存在flash播放器里,而网页的js代码是访问不到的。不过有一点值得庆幸的是,浏览器的network可以监控到由flash发出的请求,这是也是解析flash播放器的关键所在。
在通过请求视频信息的api拿到视频地址后,还要看看这个地址是否可播。一般情况下,拿到的地址不需要什么加工就可以直接播放或者下载了。但是也有一些站点,在flash请求到视频地址后,还要经过一些加密,把加密后的签名参数带上才能正常播放或者下载。
例子:www.1905.com:http://www.1905.com/video/play/1252931.shtml?fromMovie=1279932
该站点是一个电影相关的站点,解H5页面能拿到MP4文件,但是不是高清的,PC端页面有更高清的FLV文件,为了拿到更高清的视频,还是需要解PC端。通过上面介绍的方法,很容易就能找到该站点请求视频信息的api,通过返回的内容,很容易找到视频的地址:http://mmsvideopublic2.m1905.com/2018/01/31/v20180131OO9L0HESYP87CXZC/v20180131OO9L0HESYP87CXZC.flv。然而这个播放地址不能直接请求,直接请求的话会返回403。
我们可以通过network可以看到,flash请求的播放地址是这样的:http://mmsvideopublic2.m1905.com/2018/01/31/v20180131OO9L0HESYP87CXZC/v20180131OO9L0HESYP87CXZC.flv?key1=201810091344&key2=1c6f36720cedab2a6b13134942ec86e0&sr=1&p=371294359041431,拷贝出来之后也可以直接请求。
对比两个地址,发现flash真正请求的播放地址多了几个参数,而这些参数,正是flash播放器里的代码逻辑加上的。
利用 JPEXS Free Flash Decompiler (下载链接)工具,我们就可以看到flash播放器里的代码了。首先下载安装JPEXS Free Flash Decompiler。然后下载站点的flash播放器,即swf文件,如下:
然后再用 JPEXS Free Flash Decompiler 打开flash播放器: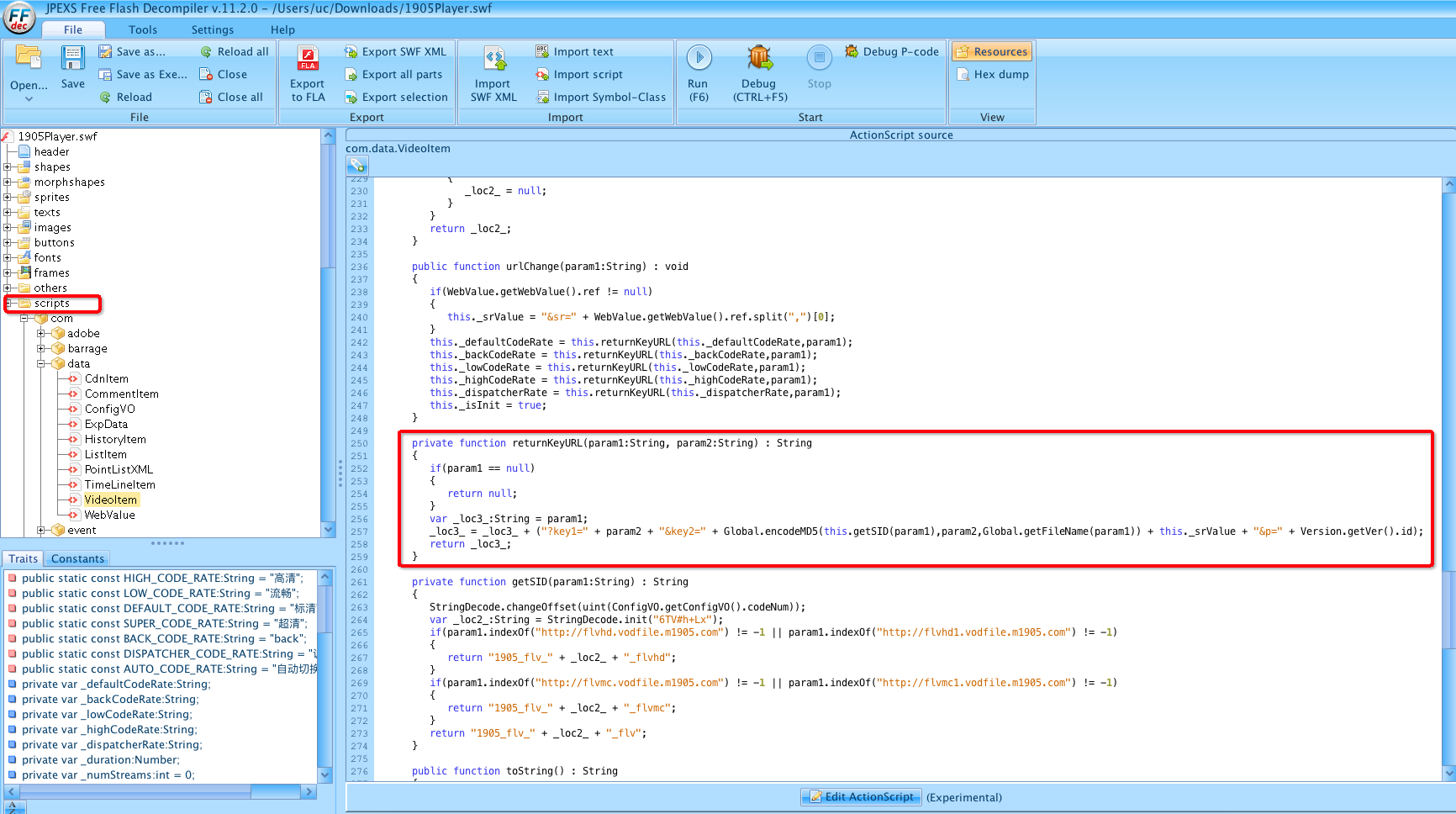
这时候,在代码里面,找到了播放地址后面带的参数的生成方式。如果觉得不好找,可以右键script目录,把代码导出来,再用自己喜欢的编辑器打开,然后全局搜索,就能很快的找到对应的代码了。
找到代码,理解代码逻辑后,还要把ActionScript的代码翻译成JavaScript的代码,好在两者的语法相差不大,翻译起来也不会太麻烦。
到此,解析完成。
2.媒体源扩展 API(MSE)
例子:coub.com
MSE 是实际上是一系列 API 的集合。它的全称为:Media Source Extensions,MSE提供了实现无插件且基于 Web 的流媒体的功能,使用 MSE,媒体串流能够通过 JavaScript 创建,并且能通过使用
站点分析
coub有两种视频文件,他们的链接都直接暴露在页面上,手机端的播放链接是经过编码处理的,直接看看不出来是一个播放地址,需要经过编码处理后才能使用,编码逻辑在js文件上也能找到。PC端的播放地址链接就直接是播放地址,只不过这个地址下载下来的文件在浏览器还是视频播放软件都不能播放,也就是这个原因,pc端的破解才有些麻烦。
那么问题来了,coub的PC端是怎么播放视频?
coub站点PC端使用了MSE的技术实现视频播放,使用MSE的好处就是可以操作视频文件的二进制流,coub站点就是利用这个功能,对视频文件进行修改,才能正常播放视频文件。还有coub站点的视频文件和音频文件是相互独立的文件,甚至时间长度都不一样,也是使用了MSE接口才能把这两个文件合并播放。
coub站点播放视频文件的大致做法是这样的:该站点在PC端播放的mp4文件在服务端都经过修改,客户端请求到的是经过修改过的文件,无法正常播放。在客户端,通过使用MSE接口提供的功能对mp4文件修改为可播放的文件,然后进行播放。
正常的mp4文件的头部为ftyp box,描述的文件的版本、兼容协议等,而最开始的4个字节表示ftyp box的长度,ftyp box的长度一般是几十个字节,用4个字节表示长度的话,前两个字节基本为0。
coub修改的就是前面两个字节的值,伪造ftyp box长度,导致MP4文件不能正常播放。
解决方法
在java端下载视频的时候,把视频文件前两个字节的值设为0即可,这样处理后的文件为正常的可播放的mp4文件。
总结
通过对coub站点解析发现,视频播放和加密的方法又多了一种,即通过服务器修改视频文件的某个特殊位置的值,使视频文件不能正常播放,客户端请求到文件后把文件修改回来再进行播放。
这样做的好处是即使知道了文件的地址,如果不知道修改规则的话也无法播放视频,还有可以对视频文件和音频文件分离,加强防盗能力。
但是也存在缺点,就是浏览器兼容问题,MSE兼容性如下: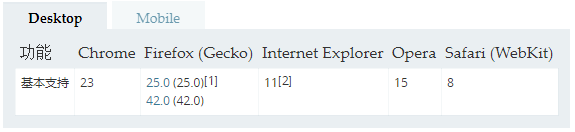

下载完才能播放了,就是麻烦了一点。
3.使用第三方请求工具
问题出现
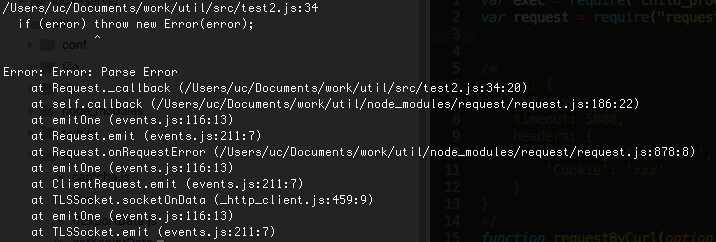
经过查资料发现,node的http模块在解析response的时候,会解析其头部信息,当发现头部信息错误并无法解析的时候,就会报这个错误。postman大概也存在这样的解析机制,导致解析失败,而浏览器和其他的一些可发送http请求的工具则没有这样的机制或者处理得比较好,才没有报错。
为了验证这个错误,在本地启动http服务,在返回数据的时候,把Content-Length的值设置成与实际返回的数据长度不一致:
var http = require('http');http.createServer(function(request, response) {var sendData = 'are you ok?'response.writeHead(200, {'Content-Length' : sendData.length - 1});response.end(sendData);}).listen(8888);
然后分别用浏览器,node和postman,curl等工具访问http://127.0.0.1:8888/,得到以下结果:
| 工具 | 结果 |
|---|---|
| 浏览器 | body:are you ok Content-Length: 10 |
| node | 程序报错 |
| postman | Could not get any response |
| curl | body:are you ok Content-Length: 10 |
从结果看到客户端请求的两种结果:无法正在解析或者可以解析,但是数据被截断,从而证实了秒拍视频接口返回的头部确实存在错误。
解决方法
现在看来,要请求到秒拍视频接口的返回数据,有两种方法:
1.服务端返回正确的头部信息。
2.使用其他请求工具。
由于这是第三方站点的服务端,所以指望其返回正确的头部信息是不太可能的事情了,所以只能使用第二种方法,即使用其他工具请求接口。
我们可以在node端,调用curl工具来发送请求,来得到数据,这样可以绕过node的http模块的解析错误。
node的提供child_process模块,有一个exec方法,这个方法可以执行shell命令,然后获取到执行命令后的输出结果,我们利用这个方法来执行调用curl的命令,在封装一下的代码如下:
var exec = require('child_process').exec;function requestByCurl(option, callback) {var cmd = `curl -X GET '${option.url}' --connect-timeout ${ option.timeout? option.timeout / 1000 : 5}`;for(var h in option.headers){cmd += ` -H '${h}:${option.headers[h]}'`;}exec(cmd, function(err, stdout, stderr) {if (err) {return callback(err, '');}return callback(null, stdout);})}
这样调用该方法就可以像正常调用request模块一样来发送请求了。
总结
通过设置response header的Content-Length值和实际返回数据的长度不一致,可以使部分http客户端无法正常解析到结果,而浏览器却毫无问题,由此可想,是不是可以将此作为一种防爬取策略呢?虽然不能百分百解决被爬取的问题,但是提高了门槛,也拦掉了部分爬取了。

若有收获,就点个赞吧
0 人点赞
