基础查询:select from
019
select 查询列表
from 表名
类似System.out.println(打印东西);
查询列表可以是:表中的字段,常量值,表达式,函数
查询结果是一个虚拟的表格
查询单个字段:Select 字段名1 From 表名
查询多个字段:Select 字段名1,字段名2 From 表名
查询所有字段:Select * From 表名 或枚举所有字段名
查询常量值:select 100; select ‘join’;
查询表达式:select 100*98;
查询函数:select Version();
- 去重关键字:distinct,应用于所有列而不仅是前置它的列
- 指定行关键字:limit,在指定开始行或者行数超出范围时,返回它能返回的那么多行
- 排序子句:order by,在from子句之后,作用的列可以是非选择列,可多列排序(优先级按字段顺序),排序规则:
- 降序(Z-A):关键字desc,z-a-数字-字符
- 升序(A-Z):默认,关键字asc(ASCENDING),字符-数字-a-z
- 筛选子句:where,在from子句之后,order by子句之前
- 操作符:等于(=)、不等于(<>/!=)、小于(<)、大于(>)、小于等于(<=)、大于等于(>=)、在指定的两个值之间(between num1 and num2)
- 多个where子句用and子句或or子句组合,联结或改变where子句中的子句的关键字为逻辑操作符
- and和or优先级:先处理and,后or,and的左右两个条件有隐形的括号,若要调整,用括号重新组合
- 有and和or同时出现,括号分组是必要的,不要依赖默认分组
- in 操作符:限定括号里面的多个值,in (1002,1003),优点:比or快,简化语法,操作符更少,可包含select语句。
- is NULL/is not NULL:筛选(不)为NULL空值的行
- not 操作符:MySQL可对in、between、exists子句否定
- like 操作符:通配符(wildcard) 用来匹配值的一部分的特殊字符,比其他搜索时间更长。技巧:不优先考虑通配符;非必要不放在开始条件;位置不同可能返回错误数据。
- %:任意字符出现任意次数(包括0次),空格会干扰%匹配,空值NULL不匹配
- :与%一样,当只匹配单个字符
- 正则表达式:关键字regexp,不区分大小写,若要区分,使用关键字binary
- .:匹配任意字符
- 与or同等作用:使用 |
- 与in同等作用:使用 [ ]
- 与not同等作用:使用 ^
- 匹配范围:使用 [ - ],如[0-9],[a-z]
- 匹配特殊字符:如 . | - \,使用 \而不是
\转义 ,匹配\字符的是\\;空白元字符:换页(\f)、换行(\n)、回车(\r)、制表(\t)、纵向制表(\v) - 匹配字符类:

- 匹配多个字符:

- 定位符:

- 正则表达式测试:不使用表,如:select ‘hello’ regexp ‘[0-9]’; ```sql select column1 from table1; — 可以完全限定表名:select table1.column1 from table1 select column1,column2,… from table1; select from table1; select count() from table1; — 计算行数
select distinct column1 from table1;
select from table1 limit 5; — 返回前5行,limit 行数 select from table1 limit 3,5; — 返回第3行(不含)后的5行记录,limit 开始行,行数 select * from table1 limit 5 offset 3; — 上一句的替代写法(MySQL)
select from table1 order by column1; select from table1 order by column1,column2; select from table1 order by column1 desc; select from table1 order by column1 desc,column2; — 不指定默认升序
select from table1 where column1 = 2.50;
select from table1 where column1 <= 2.50;
select from table1 where column1 between 5 and 10;
select from table1 where column1 = 2.50 order by column2;
select from table1 where column1 = ‘name1’; — MySQL默认不区分大小写,fuses与Fuses一样
select from table1 where column1 <> ‘name1’;
select * from table1 where column1 is NULL; — 检查空值NULL
select from table1 where column1 <= 2.50 and column2 = ‘name1’ and …; select from table1 where column1 <= 2.50 or column2 = ‘name1’ or …; select from table1 where column1 = ‘name1’ or column1 = ‘name2’ and column3 <=2.50; select from table1 where (column1 = ‘name1’ or column1 = ‘name2’) and column3 <=2.50; —重新组合
select from table1 where column1 in (1002,1003,…); select from table1 where column1 not in (1002,1003,…); select * from table1 where column1 not between 5 and 10;
select from table1 where column1 like ‘jet%’; — 以jet开头,这时区分大小写,Jet或者jet前有空格则不匹配 select from table1 where column1 like ‘%jet%’; — 包含jet,jet开头的也匹配 select * from table1 where column1 like ‘- jet’; — 匹配实例:1 jet
select from table1 where column1 like ‘1000’; — 不返回数据,
select from table1 where column1 regexp ‘1000’;
— 返回数据,原因like匹配整个列,若被匹配文本在列值中出现like不会找到它,也不返回行
— 若要实现与like同样作用,可使用定位符^和$
select from table1 where column1 regexp binary ‘JetPack .000’;
select from table1 where column1 regexp ‘1002|1003|1004’;
select from table1 where column1 regexp ‘[123] ton’; — 或1 ton或2 ton或3 ton
select from table1 where column1 regexp ‘[^123] ton’; — 匹配除1 ton,2 ton,3 ton之外的
select from table1 where column1 regexp ‘[1-3] ton’;
select from table1 where column1 regexp ‘\.’;
select from table1 where column1 regexp ‘\([0-9] stick?\)’; — 匹配实例:TNT (1 stick),TNT (5 sticks)
select from table1 where column1 regexp ‘[[:digit:]]{4}’; — 匹配实例:1000,2000
select ‘hello’ regexp ‘[0-9]’;
<a name="QIKOy"></a># 条件查询:where 字句select<br />查询列表<br />from<br />表名<br />where<br />筛选条件<br />分类:- 按条件表达式筛选- 条件运算符:> < = != <> <= >=- 按逻辑表达式筛选- 逻辑运算符:&& || !and or not- 模糊查询- like- between and- in- is null<a name="dvnum"></a>## where if 应用where if( , , )```sqlSELECT * FROM book WHERE IF(price > 120, btypeid=10, btypeid=11);
组合查询:union 多条select语句
- 组合查询:执行多个查询(多条SELECT语句),并将结果作为单个查询结果集返回。这些组合查询通常称为并(union)或复合查询(compound query)。
- 使用场景:
- 在单个查询中从不同的表返回类似结构的数据;
- 对单个表执行多个查询,按单个查询返回数据。
- 组合查询操作符:union,放在单条语句之间
- 注意:
- 两条或以上select语句才可使用union
- 每个查询必须包含相同的列、表达式或聚集函数(列不要求相同顺序)
- 包含或取消重复的行:多条select中有相同的结果,union默认取消重复行,若要返回所有行(包含重复行)使用union all
- 对组合查询结果排序:只在最后使用一条order by子句
select c_id,g_id,g_price from table1 where g_price <=5 or c_id in (1001,1002);
-- 等价于
select c_id,g_id,g_price from table1 where g_price <=5
union
select c_id,g_id,g_price from table1 where c_id in (1001,1002);
3. 分组查询:group by 子句
- 前面计算字段都是应用于整列,如何要分组计算各自的最大值、平均值、和、…?
- 分组子句:group by子句
- 可包含多列,使得能对分组嵌套,将在最后规定的分组上进行汇总
- group by列出的列必须是检索列或有效的表达式(不能是聚集函数),select和groupby的表达式应一致,不能使用别名
- 除聚集函数,select的每个列必须在groupby子句给出
- 分组列中有NULL行,则将NULL分为一组
- group by出现在where之后,order by之前
- group by rollup(A,B,…):返回汇总行:AB分组汇总,A分组汇总,总汇总行
- group by cube(A,B,…):返回汇总行:AB分组汇总,A分组汇总,B分组汇总,总汇总行
- group by grouping sets(A,B,…):返回汇总行:A分组汇总,B分组汇总
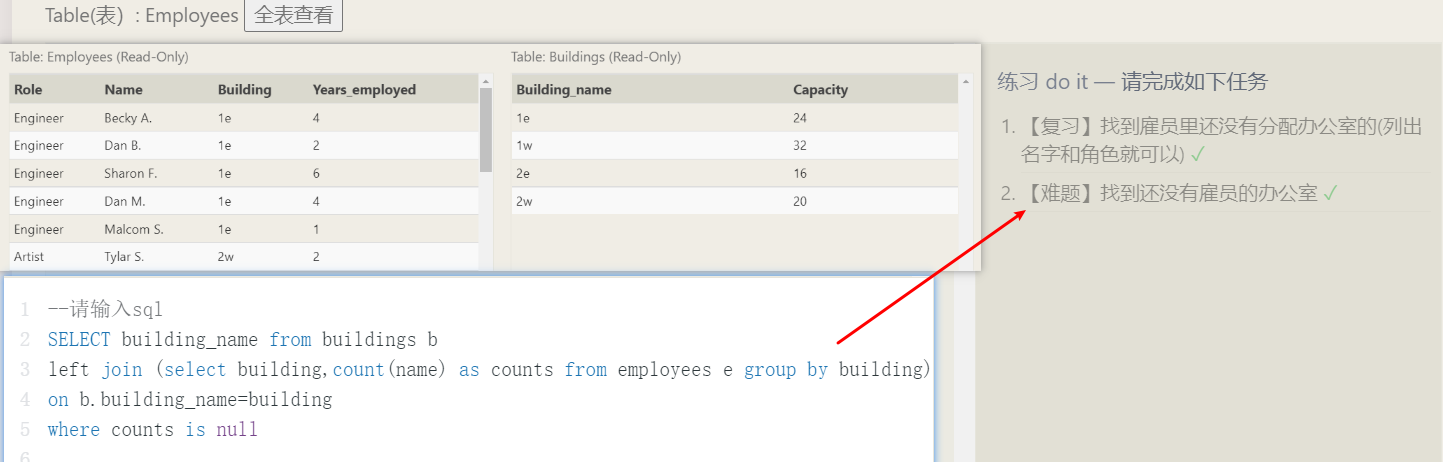
- 过滤分组:例如:列出至少有两个订单的所有顾客,这里不能用where(没有分组的概念)
- 替代where(过滤行)作用:having子句(过滤分组),适用于所有where子句,只有关键字差别
- where:数据分组前进行过滤,where排除的行不包括在分组中
- having:数据分组后进行过滤
- 分组和排序:group by之后应给出order by,不要依赖group by排序 ```sql select name,count() as num from table1 group by name; select name,count() as num from table1 group by name with rollup;
select name,count() as num from table1 group by name having count() >=2; select name,count() as num from table1 group by name having count() >=2 order by num; — 分组后按计数值排序(升序) select name,count() as num from table1 where column1 >=10 group by name having count() >=2;
<a name="GI8yz"></a>
# 4. 子查询:select
- 利用子查询进行过滤
- 子查询总是从内向外处理
- 子查询嵌套数量无限制,考虑性能,不能嵌套太多
- where的子查询应该保证select和where子句中相同数目的列,可单列、多列
- 子查询一般与 in 结合使用,也可用于测试等于(=)、不等于(<>)等
- 子查询作为计算字段 使用
- 相关子查询:涉及外部查询的子查询,必须使用完全限定列名
```sql
-- 案例:table1:订单号num,客户ID,订单日期date table2:物品名称g_name,订单号num table3:客户ID,客户姓名c_name...
-- 需求:列出订购物品goods1的所有客户信息
-- 单条语句
select num from table2 where g_name = 'TNT2'; -- 检索出物品TNT2的所有订单号
select ID from table1 where num in (20005,20007); -- 检索上一句的订单号的所有客户ID
select c_name from table3 where ID in (10001,10004); -- 检索上一句ID的所有客户信息
-- 用子查询组合
select ID from table1 where num in (select num from table2 where g_name = 'TNT2'); -- 前两句组合
select c_name from table3 where ID in (select ID from table1 where num in (select num from table2 where g_name = 'TNT2'));
-- table3中显示每个客户的订单总数:1从table3检索客户列表,2对每个客户统计table2中的订单数目
select count(*) as orders from table2 where ID = 10001;
select (select count(*) from table2 where table2.ID = table3.ID) as orders from table3;

若有收获,就点个赞吧
0 人点赞
