指针的概念
为了可以和 C 语言底层做兼容,C# 里也有指针的概念。之所以放在这里讲,一来是为了配合 C 语言的语法顺序,二来是,因为 C# 基本不用指针,所以它并不是很重要。放在后面的一般都是重点知识。
指针(Pointer),名字很奇怪,不过很容易理解:指针本身存储的并非数值,而是某个变量的内存地址。换句话说,这个变量存储的是你家门牌号,几栋几单元等等信息,而不是真正意义的可提供计算的数据。
为了引入指针的概念,我们需要先介绍一个 C# 里新的概念:不安全代码块。
Part 1 不安全代码块
在 C# 里,因为指针本身会引起很复杂且很严重的内存错误的问题,因此 C# 团队为了避免你直接使用指针,发明了一种新的机制:你需要先允许项目可以使用指针,才可以添加指针的相关代码。在 C# 里,使用的那些指针相关代码,叫做不安全代码(Unsafe Code)。
下面我们来说一下,如何让项目启用不安全代码的相关配置。
和之前配置“启用算术溢出”的操作类似,我们也是在解决方案资源管理器里选择项目,然后点击右键选择“Properties”(属性),进入项目配置页面。
然后,找到“Build”(生成)选项卡,找到启用不安全代码的选项“Allow unsafe code”(启用不安全代码),打勾即可。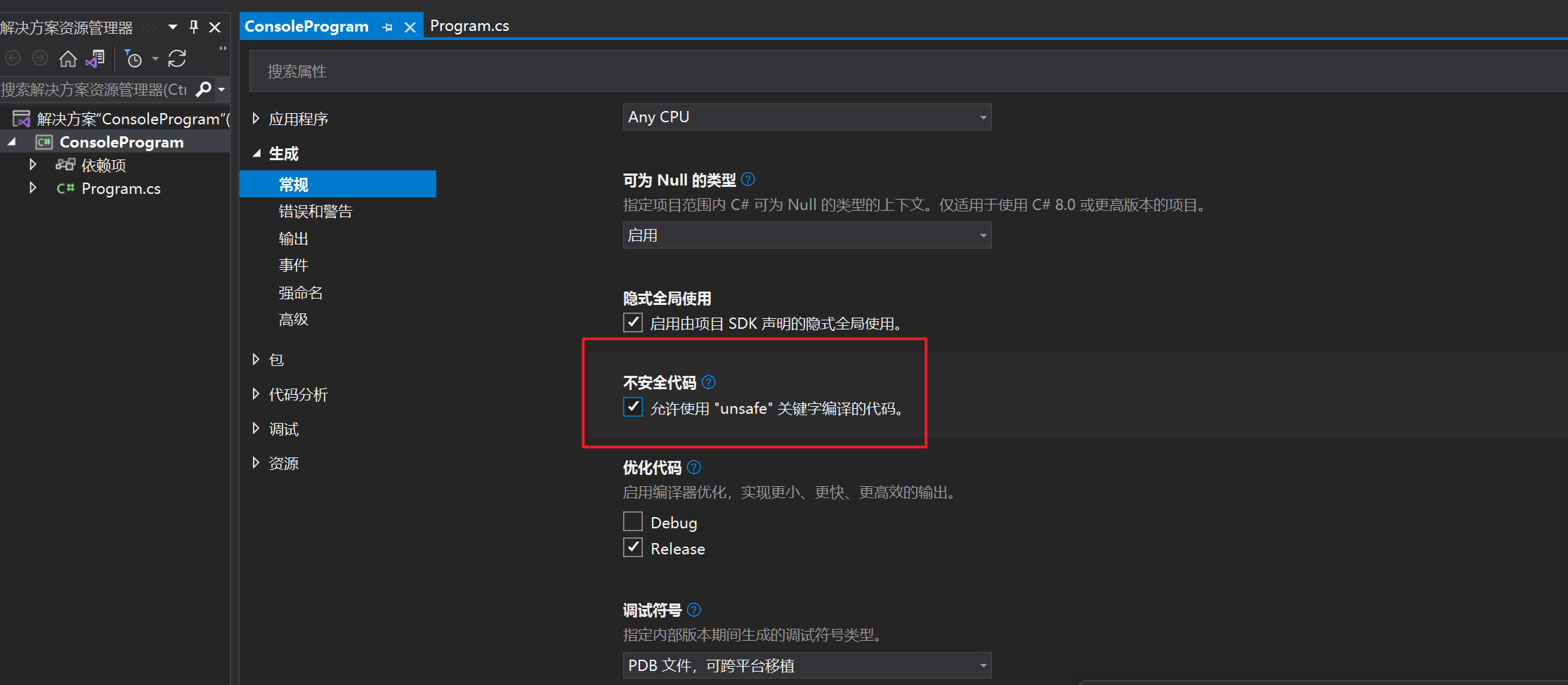
Part 2 指针变量
如果我们在代码里使用指针,我们需要用到两个运算符:*v 和 &v。
unsafe{int a = 30;int* p = &a;Console.WriteLine(*p); //30}
为了表明 p 是指针变量,我们使用 int 类型表达“它是用来存储 int 变量的地址用的”。p 此时是一个 int 类型的指针变量,存储的是 a 变量的内存地址,也就是内存里,“a 的数值到底放哪里”的信息。
接着,我们使用间接地址运算符(简称间址运算符),写成 p 的方式来获取“这个存储的门牌号对应的那么门户里的数值”
这样来书写,就可以通过 p 变量来取得 30 的结果。这就是指针变量的用法。需要注意的是,指针变量的类型“int”,前面的这个 int 表明了指针本身存储的变量的数据类型;换句话说,你不能拿一个 float 的指针变量存储一个 int 变量的地址。
另外请你注意,你在写代码的时候,需要把指针的代码嵌入到 unsafe 包裹起来的大括号里。和 unchecked 和 checked 用法是差不多的。只是 unsafe 是表示一个代码块,因此它不能用于表达式,只能用在代码块上:
using System;internal class Program{private static void Main(){int a = 30;unsafe{m =int* p = &a;Console.WriteLine(*p);}}}
我们使用这样的格式来允许程序使用不安全的代码。首先,int a = 30; 是正常的赋值语句,只有 int p = &a; 和 Console.WriteLine(p); 里使用到了指针,因此我们只需要把它们两个语句框起来,用 unsafe 关键字加一对大括号包裹起来就可以了。
当然,为了代码的灵活性,也不是不可以把 int a = 30; 放进 unsafe 代码块里。这看你习惯。
另外,为了避免你写代码的时候层次太多,你依然可以在写代码的时候,把 unsafe 写到 Main 的签名上:
using System;internal class Program{private static unsafe void Main(){int a = 30;int* p = &a;Console.WriteLine(*p);}}
Part 3 指针作参数
如果参数是带指针的变量呢?我们可以使用指针来模拟 ref 和 out 参数。
static unsafe void Swap(int* left, int* right){int temp = *left;*left = *right;*right = temp;}
然后调用方:
private static unsafe void Main(){int a = 30, b = 40;Console.WriteLine("{0}, {1}", a, b);Swap(&a, &b);Console.WriteLine("{0}, {1}", a, b);}
指针的用法就是传入地址的形式,以在 Swap 方法里使用到 Main 里的 a 和 b。这个语法虽然不同,但从语义上讲,它就和 ref 参数是一样的了。
out 参数也是一样的道理。
static unsafe bool IsPassedTheExam(int math, int english, int chinese, float* average){float total = math + english + chinese;*average = total / 3;return *average >= 60;}
调用方:
private static unsafe void Main()
{
int math = 70, english = 75, chinese = 55;
float averageScore;
bool passed = IsPassedTheExam(math, english, chinese, &averageScore);
Console.WriteLine(
"He {0} the exam. The average score is {1}.",
passed ? "has passed" : "hasn't passed",
averageScore
);
}
可以从代码里看出,只要我们使用了指针,实际上 ref 和 out 参数我们都能完成。但是我们为什么还需要用 ref 和 out 来代替指针呢?
因为 ref 和 out 的语义更强,编译器知道这里的参数是传入引用和输出用的,因此编译器就知道怎么去处理和帮助你写代码:比如 ref 参数,因为在调用方和方法里使用相同的变量,因此我们无法避免方法里使用变量的数值信息;因此编译器必须让你为 ref 参数给定了初始赋值才能传入;另外一方面,因为你用 out 修饰参数,因此编译器知道你这里的参数是输出用的,因此在方法没有为参数赋值的时候,编译器就会产生错误信息告诉你,必须给这个变量赋值才能继续使用方法。这两点,指针本身是无法确定具体用途的,因此编译器本身也不知道怎么帮助你写代码。
Part 4 无类型指针
C# 还允许无类型指针。无类型指针指的是我们为了兼容任何类型的指针才产生的写法。我们使用 void* 表示这个类型。
int a = 30;
float b = 30F;
decimal c = 30M;
byte d = 30;
void* pa = &a, pb = &b, pc = &c, pd = &d;
比如这个写法下,pa、pb、pc 和 pd 四个变量都是 void* 类型的,但上述四个变量都可以使用地址符号来赋值。这种格式虽然可以这么写,但大多数时候我们都不使用它,因为类型本身一旦赋值过去后,指针变量本身就无法确定是什么类型的了,因此我们无法对这种类型的指针变量使用间址运算符。
栈内存和堆内存
为了能学习后面的知识点,我们先需要掌握栈内存和堆内存的基本概念。
本节没有代码,所以纯理论的东西都很枯燥。如果你想要了解它们,那么只能慢慢学。
Part 1 简述
在 C# 程序里,有两个主要的内存区域,可以临时提供和存储数据的内存空间。内存空间存储这些数据是为了在程序执行的时候反复使用它们。如果不存储的话,每一次数据都需要从外界读取,然后使用一次就读取一次。一来是速度慢,二来是不符合程序设计的灵活性。
为了保证数据处理的灵活性,C# 存储数据的最重要的两处数据存储空间就有栈内存(Stack Memory)和堆内存(Heap Memory)。栈内存用来执行方法的过程的时候,存储方法执行期间的临时变量啊这些数据信息;而堆内存则是存储很复杂的数据信息。在 C# 里,数组在执行 new 语句后,就被放在了堆内存里;而临时变量(比如 int a = 3; 的 a 作为临时变量,就在栈内存里存储。
Part 2 栈内存和堆内存的区别
它们的作用都是存储数据信息,用于计算。从存储的角度来说,它们是没有区别的;但是从内存分配和内存大小来说,就有区别了。
你可以试着认为堆内存是实验楼,而栈内存就是教学楼。如果拿出一个具体的例子来说明的话,你可以这么去理解:在体育活动(程序运行)期间,学生肯定需要进入操场(运算器)里参与活动(进行运算)。但是,教学楼(栈内存)往往相较于实验楼(堆内存)距离操场(运算器)要更近一些,因此会更快到达操场参与体育活动(运算)。而实验楼可以存储很多仪器设备(内存空间很大),但教学楼只能容纳学生学习(方法调用),其它都不行,因此,教学楼(栈内存)空间可能会比实验楼(堆内存)空间要小。
栈内存相较于堆内存来说,执行速度会更快一些;相反堆内存里存取数据要慢一点。但就存储空间来说,由于栈内存执行效率比堆内存要高,因此不可能让所有数据都丢进栈内存,这样会把栈内存空间撑爆,导致很严重的内存溢出的问题。因此,像是数组这类可以存储较多数据的东西,也确实只能放在堆内存里;相反,像是 int 啊、double 类型的这些临时变量,不管你初始化多少个,因为是单独的一个变量的初始化过程,因此都是被 C# 放在了栈内存里。
所以:
- 堆内存空间更大,但效率更低;
-
Part 3 能否将临时变量丢入堆内存,或者把数组丢入栈内存?
这是一个好问题。C# 按照语法规则规定,内置的类型被分成值类型(Value Type)和引用类型(Reference Type)两种。值类型就是 int、double 这类基本数据分类的类型。这些类型在写成临时变量的时候,只存储在栈内存里;而引用类型则是 string 和数组这类型的东西。它们往往不定长,随着数据的变化而产生不同的存储大小,因此它们可能会很大,因而在定义它们的临时变量的时候,它们是存储在堆内存里的。
而目前的语法来说,就算是 string 很短,我们也不能丢进栈内存;相反,我们也不能把 int、double 这类型的东西丢入堆内存里。语法是做不到的,而这个规定是 C# 语法本身的规则,所以你无法修改。但是,以后我们会慢慢学习到新的内存,比如类类型、比如结构类型。在说到这些东西之后,我们就可以明白了,其实我们是可以通过别的方式来实现值类型丢进堆内存,或者引用类型丢进栈内存的问题的。Part 4 垃圾回收器
堆内存和栈内存还有一大区别是,使用完毕后,内存空间里面的数据的去向。就像是红细胞从出现到凋亡的整个过程,C# 规划了一个模型来收集这些废弃的东西。堆内存里的数据一旦分配后,数据就一直存储起来。但实际上,如果我们不去使用它们的话,这个变量也会一直存储在那里;但相反的是,栈内存的空间一旦在某个方法执行完毕后,空间里面的数据就自动随着这个方法自动销毁掉。这个行为是自动的。
但是,既然堆内存的数据一直都放在那里的话,那么我们不断去声明需要堆内存存储的变量的话,内存空间占用就会越来越大,最终撑爆内存。因此,当某个时候发现变量已经不可能使用到了的话,C# 就会启用垃圾回收器(Garbage Collector,简称 GC),来全盘扫描用不上的堆内存变量。换句话说,我们在做工作做任务的时候,垃圾回收器就辅助我们在找不用的东西,将它们自动处理掉。因为栈内存空间是自动销毁的,所以 GC(垃圾回收器,以后就写简写了)不会去在意栈内存空间,它只关心堆内存的变量。
比如我现在有 20 个堆内存的变量。当这些变量一旦不再使用后,GC 会按照它自己的节奏,开始启动回收机制。将所有没用到的变量自动回收销毁掉,并重新将变量的内存空间按照次序重新摆放起来。因为堆内存的变量大小都不一定一样大,因此,它可能是这样的:
接着,假设变量 B、D 和 F 我们都不再使用了,GC 就会在某个时候开始启动垃圾回收机制。将它们找出来:
然后销毁掉。销毁之后,可以发现,比如 C 和 E 之间缝隙太小。如果我们要安排别的变量存储进来的话,显然是肯定不够放的(因为可能很少有机会创建占空间这么小的变量了),因此,GC 会进行压缩(Compact)处理,将这些小缝隙清除掉,把变量拼在一起:
可以发现,一旦这么处理后,内存存储的地址必然会发现变动。比如 A 变量可能没有变动,但 C 的地址就会往前偏移一点;同理,E 和 G 也是一样的。因此,GC 会有这样的一些隐式行为。希望我们注意。
另请注意,这种隐式行为是我们不学习这些知识点就一定不会知道的东西。但是后续的一些语法,就会用到它们才能理解,因此希望你注意。
总之: GC 只处理堆内存空间;
- GC 按照自己的节奏,对堆内存进行处理。一旦发现某个变量以后都不会使用了的话,变量的内存空间就会被 GC 自动销毁,并通过“紧凑”处理将销毁后的变量空间消除掉,防止以后变量存储过程之中无法利用到这些零散的小空间;
- GC 是 C# 里自带的处理机制,因此你可以跟他打配合,但是你不能期望去改变它的处理行为。
指针和数组
前文我们说过了堆内存和栈内存的基本存储姿势,现在我们说一下对于指针相关的数组操作。Part 1 栈内存数组
什么?数组元素少?是的,那么我们是可以允许使用别的语法来完成这一点的。我们使用关键字 stackalloc 来创建栈内存的数组。
比如这个例子里,我们使用 stackalloc int[10] 来创建一个长度 10 的栈内存数组。稍微注意两个地方。第一个地方是,stackalloc 替换为 new 的时候,和原始的创建数组的写法是一样的;第二个地方是,左侧变量 arr 的类型是 int* 而不是 int[]。这一点可能你需要注意了。因为栈内存分配的结果必然是一个指针表达的数组,因此必须用指针表示。int* arr = stackalloc int[10];
另外,在 C 语言里我们知道,数组和指针基本上没有啥大的区别,因此索引器 [] 可以用在指针上。比如 a[1] 和 p[1] 都是可以的语法。
这样写是可以的。不过,C# 里,stackalloc 和 new 有一点不一样的是,stackalloc 反馈的是一个指针,因此我们不能使用初始化的语法,即那个大括号,写初始数值的列表,你必须写成这样:Console.WriteLine(arr[1]);
比如这样。int* p = stackalloc int[3]; p[0] = 1; p[1] = 10; p[2] = 100;Part 2 指针的加减运算
数组是长条形的存储结构,那么我们怎么通过指针来取元素呢?在讲数组的指针操作之前,我们先来说一下指针的加减法。
我们定义的指针变量:
注意 ptr 的初始化语句。我们使用 arr + 1 表示的是取 arr[1] 元素的地址。C# 里,我们定义两种运算:int* arr = stackalloc int[5]; int* ptr = arr + 1; // Here.
arr + n 表示取 arr[n] 的地址,即等价于 &arr[n];
arr - n 表示取 arr[-n] 的地址,即等价于 &arr[-n]。
可能减法不是很好理解。你将这里 arr 当成一个指针,加 n 就表示往后移动,那么减去 n 就是往前移动了。举个例子。 ```csharp int* arr = stackalloc int[5]; arr[0] = 1; arr[1] = 10; arr[2] = 100; arr[3] = 1000; arr[4] = 10000;
int* ptr = arr + 3;
Console.WriteLine(ptr[-1]); Console.WriteLine(*(ptr - 2));
我们试着看一下这两个例子。ptr[-1] 表示以 arr[3] 为基准往前移动 1 个单位,因此此时指向的位置是 arr[2],因此第一个输出语句是输出 arr[2] 的数值 100;而第二个的话,它和 arr[-2] 是一个意思,即指向 arr - 2 这个地方,然后取这个地方的数值。显然是 10,因此输出的就是 10。<br />正是因为如此,我们需要为指针定义指向变量的类型。因为指针是可以执行加减法运算的。如果类型是 void* 的话,由于类型无法确定,因此程序并不知道我们到底需要往前或往后偏移单位的时候,走多远的距离。不同的数据类型占据的内存空间大小是不一样的,这就导致了使用 void* 接收会无法确保移动长度的问题。
<a name="FVvV0"></a>
### Part 3 固定语句
在使用栈内存数组的过程中,因为它是在栈内存里,因此变量是不会受到 GC 的影响的;但相反,由于数组被放在堆内存里,因此如果我们使用指针取得变量的地址的话,因为是间接取值的关系,GC 万一回收了这个数组的内存,这个指针不就产生很严重的内存问题了吗?<br />因此,C# 发明了一种机制,叫做数组的固定(Fix)。固定数组后,数组在使用指针运算期间就无法被 GC 回收。
<a name="DtYR8"></a>
#### 3-1 数组的固定
固定语句是这么写的:
```csharp
fixed (int* p = arr)
{
// ...
}
我们使用关键字 fixed 来表示,下面的 arr 我需要固定;而等号左侧的变量 p 是 arr 这个堆内存数组的首地址。然后,使用大括号就可以在大括号内部使用这个 p。但是,我们无法修改 p,只能通过赋值给别的指针变量来修改。比如说 int* q = p; q++; 类似这样的形式来修改 q 的数值,p 只能读取用。
举个例子,我们要计算一个数组每一个元素加起来的和。
int sum = 0;
fixed (int* p = arr)
{
int times = 0;
for (int* ptr = p; times <= arr.Length; times++, ptr++)
{
sum += *ptr;
}
}
Console.WriteLine(sum);
比如像是这样的形式。在循环里,我们使用 ptr 来作为游标,移动 ptr 的指向来达到遍历整个数组的过程。稍微注意一点的地方是,数组即使固定了,我们也无法通过指针本身来确定数组的大小。因此,我们还需要一个叫 times 的临时变量来表示到底移动了多少次。
稍微注意一点的是,它和 C 语言不同,对数组本身使用地址符号和对数组的元素使用地址符号都是 C 语言允许的写法,但是 C# 里,我们只能写 int p = arr 或 int p = &arr[0] 这种格式,而不能写成 int* p = &arr。
3-2 字符串的固定
和普通数组稍显不同的地方是,字符串的固定。字符串的固定被 C# 特殊处理过,因此我们如果固定了一个字符串的话,那么这个字符串必然是“一个字符数组,外带一个终止字符”。
终止字符(Terminator),专门标记一个字符串是否结尾。它写成 ‘\0’,但我们一般书写字符串字面量的时候,都不写它。另外,C# 有特殊处理,即使字符串的中间有这个终止字符都是可以的,它只是在固定字符串的时候才会发生作用,表示字符串的结尾。
字符串的固定和数组的固定写法完全一样。
fixed (char* p = "Hello, world!")
{
for (char* ptr = p; *ptr != '\0'; ptr++)
{
Console.WriteLine(*ptr);
}
}
比如这样。我们直接将字符串的字面量(或者变量)写到 fixed 语句的小括号里,等号左侧则使用 char 类型的指针变量来接收。然后,下面使用 for 循环来遍历整个字符串。另外,这里我们可以直接以 ptr != ‘\0’ 作为条件判断。如果遇到 ‘\0’ 的时候,我们就可以认为整个字符串结束了;否则 ptr 不断往后移动。
稍微注意一下。字符串在 C# 里是不可变的。换句话说,我们无法通过前文介绍字符串的那些内容来改变字符串里的字符;相反地,我们怎么调用那些方法,最终都是产生一个新的字符串,来作为结果。但是,我们使用指针的话,字符串不可变的特征就会被打破。
using System;
internal class Program
{
private static unsafe void Main()
{
string a = "Hello, world!";
fixed (char* p = a)
{
for (char* ptr = p; *ptr != '\0'; ptr++)
{
*ptr = 'a';
}
}
Console.WriteLine(a);
}
}
我们来看这一则完整的例子。在最后调用后,整个字符串的所有字符全都会被改成 ‘a’。 
和底层的互操作
本文难度较大,是因为这个概念是 C 语言没有的,因此理解起来比较困难;相反,这个编程语言允许和 C 语言的代码进行交互使用。
另外,这篇文章可以考虑在以后学习了其它的知识点后,再来回头看。反正也不是很重要。
Part 1 互操作性
互操作性(也叫交互性,Interoperability),指的是 C# 的代码上可以跑 C 和 C++ 的程序的代码。从另外一个角度来说,由于我们允许使用这样的机制来执行程序,因此我们可以允许 C# 跑 Linux 上的 C 语言程序,因此平台不相同了。所以,这个情况一般也可以记作 P/Invoke。
其中 P/Invoke 的 P 是 Platform(平台)的缩写。所以 P/Invoke 也就叫做平台调用。
我们来举个例子。由于我们是黑框程序(控制台),因此我们想要用弹窗告知用户一些信息。但是,C# 的控制台又不是平时肉眼所见的弹框,因此我们需要借助别的方法来产生这个弹框。
我们这里要用到 C 语言和 C++ 里用的函数:MessageBox。这个函数被存放在 user32.dll 这个文件里。
using System;
using System.Runtime.InteropServices;
public class Program
{
public static void Main()
{
// Invoke the function as a regular managed method.
MessageBox(null, "Command-line message box", "Attention!", 0);
}
// Import user32.dll (containing the function we need) and define
// the method corresponding to the native function.
[DllImport("user32")]
static extern unsafe int MessageBox(
void* hWnd, // The handle of the window. Just input null is okay.
string lpText, // The inner text to display.
string lpCaption, // The caption of the window.
uint uType // Just input 0 is okay.
);
}
我们如果要使用这个函数,如果我们要用这个函数,就需要使用一个语法:[DllImport(“user32”)]。以方括号记号标记在方法上方的模式叫做特性(Attribute)。
接着,因为写进 C# 代码的方法是外来导入的,因此这样的方法称为外部方法(External Method)。这样的方法需要在签名上添加 extern 关键字以表示方法是外来的。这个方法带有四个参数分别是 void*、string、string 和 uint,并返回一个 int 类型结果。
什么?你不知道这个参数为啥是这样?互操作性是从 C/C++ 引入的函数,所以这个得网上搜资料才知道。这个函数的声明并不是拿给你背的。
另外,但凡有一个参数的类型,还有返回值类型写错,整个程序都会崩溃,因为这样的函数在文件里因为参数和返回值无法对应起来,就会导致传参失败。
然后我们试着运行下这个程序。你在看到控制台打开的时候,立刻弹出一个新的白色框,提示一段文字;这些文字都是在刚才 C# 代码里写的这些字符串。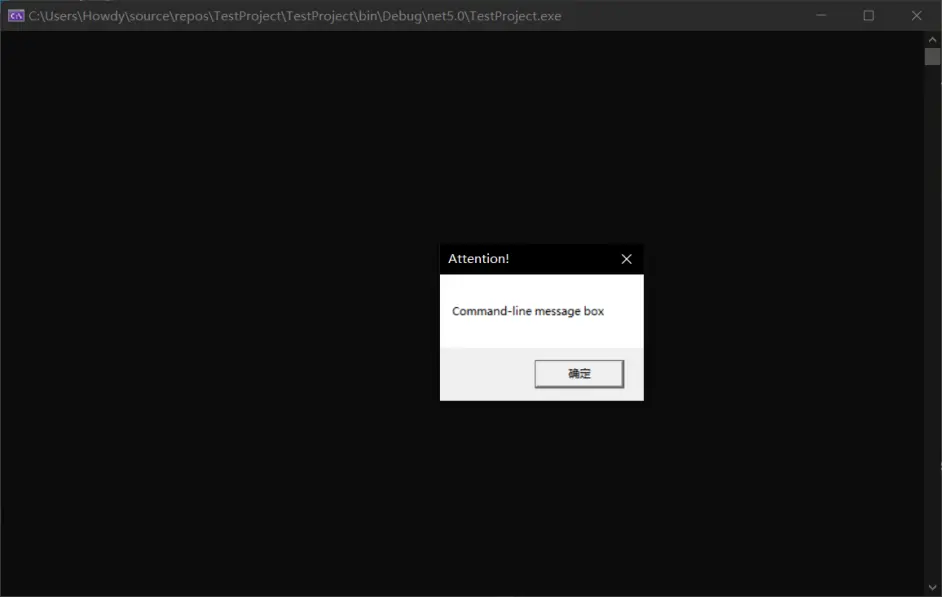 这就是运行结果了。
这就是运行结果了。
然后提一句,这里引用 C/C++ 的函数的过程叫做调用(Invoke)。这里的调用(invoke)和之前介绍方法的调用(call)是不一样的英语单词,只是中文里用的是同一个词语,在英文环境下,它们并不是一个意思。这里的调用(invoke)指的是一种“回调”过程:方法本身并不是我们控制的调用,因为底层的代码并非由我们自己实现,而过程是自动调用的;而相反地,方法里的调用(call)过程,是我们自己控制的,我想这么调用就这么调用。
Part 2 MarshalAs 标记
这样的代码是不严谨的。因为底层实现的关系,C 语言里的 int 类型大小并不是完全和 C# 语言的 int 类型正确对应起来的,因此,我们需要指定参数在交互的时候,和 C 语言里真正对应起来的转换类型。
看一下这个例子。我们除了用上方的 [DllImport] 以外,还需要为参数添加 [MarshalAs] 修饰。
// Import user32.dll (containing the function we need) and define
// the method corresponding to the native function.
[DllImport("user32")]
[return: MarshalAs(UnmanagedType.I4)]
static extern unsafe int MessageBox(
void* hWnd,
[MarshalAs(UnmanagedType.LPStr)] string lpText,
[MarshalAs(UnmanagedType.LPStr)] string lpCaption,
[MarshalAs(UnmanagedType.U4)] uint uType
);
C 语言和 C++ 里,字符串是以 ‘\0’ 作为终止字符的。因此,我们在指定的时候,为了严谨需要添加 [MarshalAs(UnmanagedType.LPStr)]。这个写法专门表示和指明这个参数在调用的时候会自动转换成 C 语言和 C++ 的这种字符串形式。另外,最后一个参数我们固定指定 [MarshalAs(UnmanagedType.U4)] 表示传入的是 unsigned int 类型,大小是 4 个字节。
然后,第 4 行的 [return: MarshalAs(UnmanagedType.I4)] 实际上指的是,这个函数的返回值在底层是什么类型的。这里写成这样表示,底层是 C/C++ 里的 int 类型。
Part 3 调用变长参数函数
在 C 语言和 C++ 里,拥有一个特殊的函数类型,叫做变长参数函数。变长参数使用三个小数点来表达。这种函数我们怎么写 C# 代码呢?难道是 params 参数修饰吗?
实际上不是。因为 C 语言和 C++ 里的变长参数实现模型和 C# 的是不一样的,因此我们需要借助一个特殊的关键字来完成:__arglist。这个关键字比较特殊的地方在于,它是以双下划线开头的关键字。
using System.Runtime.InteropServices;
internal class Program
{
private static unsafe void Main()
{
int a = 25, b = 45;
Printf("a + b = %d\n", __arglist(a + b));
}
[DllImport("msvcrt", EntryPoint = "printf")]
[return: MarshalAs(UnmanagedType.I4)]
static extern int Printf(
[MarshalAs(UnmanagedType.LPStr)] string format,
__arglist
);
}
稍微注意一下的是,我们这里要用到一个地方的修改:[DllImport] 里要在后面追加一个叫 EntryPoint = “printf” 的写法。
这个修改是为了指定执行的方法在 DLL 文件里名字是什么。因为 C# 的方法约定是使用大写字母开头的单词,因此我们写大写的话,可能会导致这个叫 Printf 的函数在文件里找不到。因此我们追加这个东西来告知程序在处理的时候自动去找 printf。
运行程序。我们可以看到结果:
这就是 C# 里使用 C/C++ 里的变长参数的办法。
Part 4 总结
至此,我们就把 C# 的指针大致给大家说了一下。指针的内容比较复杂,特别是本节的内容可能让你看得是一头雾水。没有关系。以后还有更难的东西(不是
好好学。这点内容可以以后来看,至于重要不重要,我相信你自己应该是知道的。

若有收获,就点个赞吧
0 人点赞
