面向对象和类的基本概念
C# 里最有意思的一个体系化架构就是面向对象(Object-oriented)。什么是面向对象呢?
Part 1 面向对象是什么
在 C# 的世界里,我们除了前面的简单的例子可以通过 C# 解决之外,还可以用一种体系化的架构来搞定一个复杂的项目,这个叫做面向对象。
面向对象是什么?面向对象是将世间万物通过代码的形式呈现和体现出来的一种编程范式(Programming Paradigm)。所谓的编程范式,你可以理解成编码的不同风格和方式。比如,我可以把代码写成数学函数调用那样的嵌套过程,这种叫函数式编程(Function-oriented Programming,简称 FP);我还可以把代码写成 C 语言那样,用函数作为执行单位、并依赖于顺序结构、条件结构、循环结构和跳转结构来完成项目编码的过程,称为面向过程编程(Procedure-oriented Programming,简称 PP);最后还剩下一种编程范式,就是面向对象编程了。这里的“对象”并不是指男女朋友,而是把世间万物的个体称为对象。
这三种编程范式,都可以完成同样一个任务,但是从代码的逻辑和代码书写体现来说,写法是不同的。而 C# 是基于面向对象编程的语言,因而我们不得不学习面向对象编程这一个编程范式。
由于面向对象这个编程范式稍微复杂一些(比较体系化),因此内容很多。在这个教程里,我们可能会分成非常多节的内容给大家呈现和介绍,希望你慢慢来。
Part 2 类
2-1 类的概念
类(Class)是贯穿面向对象的基本单位。和 C 语言的面向过程编程一样,函数是贯穿面向过程的基本单位;而类则是面向对象的基本单位。
类是世间万物的抽象,换句话说,如果我们要完成一个很复杂的项目,我们就得把这个项目里需要用到的所有物体用类呈现和体现出来。而类是一个整体,它用代码写出来,拿给别人看这段代码的时候,它就好像在看说明书一样:这个物体可以怎么操作、如何操作、什么时候操作。这就是类。
为什么叫类呢?你想一下,我们所有人,统称叫人类。为什么叫人类呢?因为是人这个类别,因此叫人类。这个类就取自这里:我们将物体用代码呈现出来的这个基本单位就称为类,就是这个原因。
2-2 类的语法
我们使用关键字 class 来表示一个类。在 class 关键字后,紧跟一个标识符,这个名字就是这个代码里体现出来的类的名称,代表的世间万物里究竟什么东西;后紧跟一个大括号,来表示这个类里的具体内容(也就是我刚才说的“可以怎么操作”、“如何操作”和“什么时候操作”。
class Program{}
这是不是很熟悉?是的,这就是最开始我们没有对其解释的 Program。因为 C# 是基于面向对象的编程语言,因此我们不得不将 Main 方法(还有别的自己写的方法)包裹在类里。就算是这个类没有用,我们也得这么写,因为基于面向对象嘛。
当然了,我们将 Main 方法写到 Program 类,那么换句话说,这个 Main 方法是 Program 类的一个成员(Member)。
这一节的内容我们只会接触到方法这一种成员类型,成员还有别的类型,比如属性、事件等等。这些类型的成员在这一节的内容里说不到,因此我们先不管它们。
2-3 类和类的交互
另外,类是基本单位,因此我们需要书写若干个类,来达到类和类之间的关联。这里我们需要学习如何在类之间作调用和交互。
比如,我们拥有一个类、称为 Algorithm,它存储了一个叫做 BubbleSort 的方法,专门用来对一个数组进行排序操作:
class Algorithm
{
public static void BubbleSort(int[] array)
{
for (int i = 0; i < array.Length -1; i++)
{
for (int j = 0; j < array.Length - 1 - i; j++)
{
if (array[j] > array[j + 1])
{
int temp = array[j];
array[j] = array[j + 1];
array[j + 1] = temp;
}
}
}
}
}
然后,我们将在 Program 类里完成调用和交互。
class Program
{
private static void Main()
{
int[] arr = { 3, 8, 1, 6, 5, 4, 7, 2, 9 };
// Before sorting.
for (int i = 0; i < arr.Length; i++)
Console.Write("{0} ", arr[i]);
Console.WriteLine();
Algorithm.BubbleSort(arr);
// Afther sorting.
for (int i = 0; i < arr.Length; i++)
Console.Write("{0} ", arr[i]);
Console.WriteLine();
}
}
请注意代码的第 12 行(Algorithm.BubbleSort(arr); 这一行代码)。这句话是通过 类名.方法名(参数) 的方式来完成不属于这个类的方法的调用的。这里的小数点,我们称为成员访问符(Member Access Operator);在读代码的时候,我们可以翻译成自然语言的“的”:Algorithm.BubbleSort 可读作“Algorithm 类的 BubbleSort 方法”。
在自然世界里,如果我们要想理解这样的代码,我们可以认为
- Algorithm 类表示和存储算法的相关操作;拿给别人看的时候,别人就知道里面的成员都是跟算法相关的;
- Program 类表示程序基本的操作行为,因此拿给别人看的时候,别人就知道这个类专门给程序服务(毕竟带了 Main 方法嘛),他就不会拿着这个类干别的事情;
- Algorithm 类的 BubbleSort 方法从名字上就可以看出是“冒泡排序”,因此对于一个老外来说,这个调用写法就相当于 算法.冒泡排序。是不是写成汉字更好理解呢?
- 实际上,我们前面用到的 Console.WriteLine、Math.Sqrt 等等方法调用下,左边的 Console 和 Math 都是类的名字;而后面的 WriteLine 和 Sqrt 自然就是这些类内部的成员了。
另外,int.Parse、string.Concat 这些方法的前面用的是关键字;但不知道你忘了没有,这些关键字是和 BCL 名等价的。因此,这些关键字最终会被翻译和解析成 Int32、String 这些内部的名称。而实际上,String 也是 C# 里的一个类,只是它是系统提供的,而不是我们自己写的,和 Console、Math 是一样的;而 int 则稍微有点不一样:它是一个结构。结构的内容我们将放在“结构”一个章节里给大家介绍。不过你可以认为结构和类目前都是使用 名称.方法 的方式来调用这些方法的,因此你不必太过担心超纲的内容,至少目前我们还用不到结构的知识点;另一方面,因为语法是相同的(都用 名称.方法),所以其实很好理解。
2-4 如何给类单独创建一个文件
前面的内容足以帮助我们学习和理解面向对象的编程思维,但是我们在写代码的时候,总不可能一个文件里放若干个不同的类吧。如果类太多,就会导致程序的代码文件过于臃肿。一来翻的时候不好看,二来是不方便后续拓展和整体代码,因为都写在一个文件里,如果一个类太大了怎么办。
因此,这一节我想给大家介绍一下,如何用 VS 创建一个独立的类的文件。将一个类存储到一个文件里,不同的类放在不同的文件里,这样就方便我们整理和查看每一个类。
我们先打开解决方案资源管理器,然后找到项目,点击右键,依次选择“Add”(添加)、“New Item…”(新项目……)。 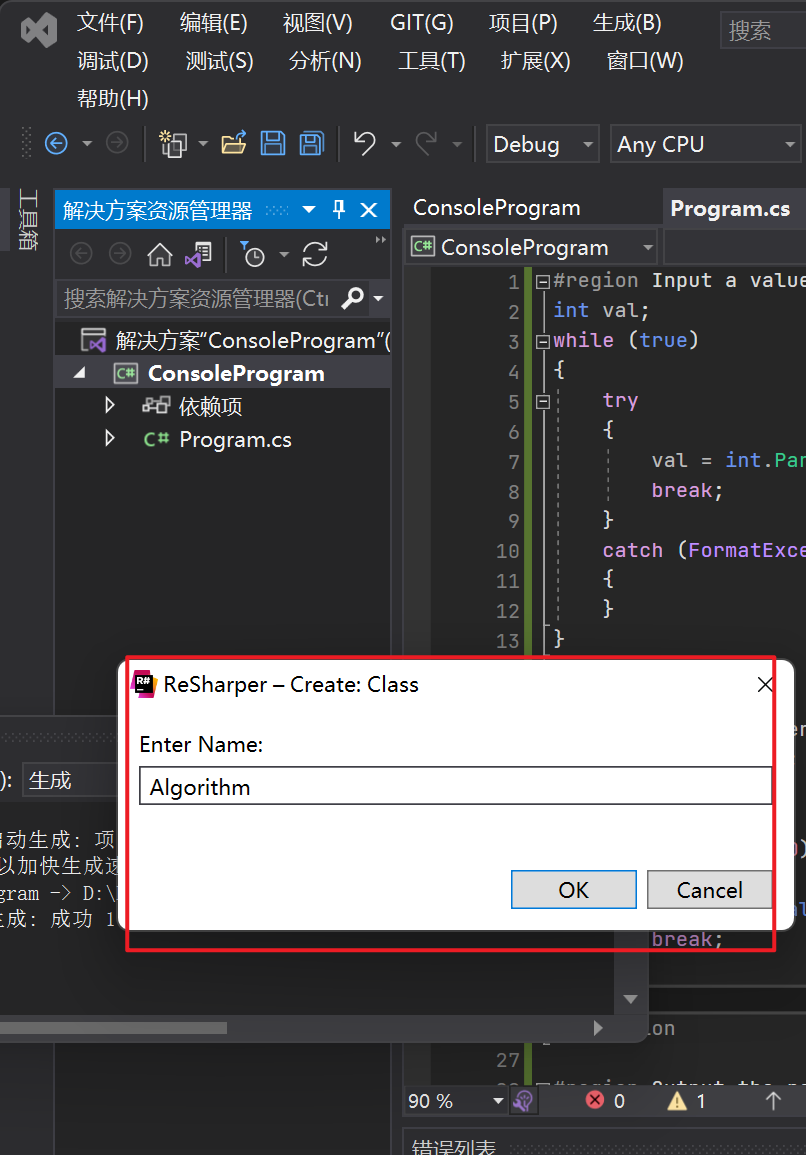
然后,文件创建好了之后,文件默认长这样:
namespace ConsoleProgram;
public class Algorithm
{
public static void BubbleSort(int[] array)
{
for (int i = 0; i < array.Length - 1; i++)
{
for (int j = 0; j < array.Length - 1 - i; j++)
{
if (array[j] > array[j + 1])
{
int temp = array[j];
array[j] = array[j + 1];
array[j + 1] = temp;
}
}
}
}
}
总之,文件变成这个样子。把代码抄过来就行了。整体就是一个创建类文件的过程。
然后,要返回 Program 类的所在文件,还是在解决方案资源管理器里找到 Program.cs,双击它就可以了
Part 3 访问修饰符
修饰符(Modifier),指的是在类的声明(class Program 这里),以及方法这些成员上追加的、不是返回值类型的别的关键字信息。比如在前面,public、static、private 还有最开始就知道的 unsafe 关键字,它们一旦写到这些东西上,我们就可以称为它们叫做修饰符。加在类的声明上,我们就称为类的修饰符;加在方法上,就称为方法的修饰符。
修饰符分成两类:访问修饰符(Accessibility)和非访问修饰符(Non-accessibility),下面我们分成这样两类来给大家介绍。
先来说一下访问修饰符。所谓的访问修饰符,本身没有代码层面的意义,它是用来控制成员的可访问级别的。这么说也不明白,我们来详细说明一下具体每一个访问修饰符的用法,然后你自然就知道是干啥的了。
3-1 public 关键字
我们将 public 用于成员上,用来表达这个东西在任何时间任何地方都可以用。只要使用合适的语法(就是前面说的利用成员访问符来写),就可以随便用。
可以看到,我们在 BubbleSort 方法上标记了这个关键字,这是为了干什么呢?这是为了告诉你,这个方法随时都可以用。如果你没有标记这个关键字的话(或者标记了别的访问修饰符的话),这个方法就不可能随时随地都可以用了。所以换句话说,public 关键字的访问级别最高:任何时候都可以用。
3-2 internal 关键字
要想理解 internal 关键字,我们需要介绍一下解决方案和项目之间的关系。
3-2-1 项目和解决方案的概念和逻辑关系
解决方案(Solution),指的是整个程序写的所有代码的整体;而项目(Project)则可以将不同的代码分门别类地存放和归置。解决方案是所有这个程序里的代码的整体,那么项目可以包括同样用途用法的代码,因此解决方案比项目范围更大;而项目则包含代码文件,因此项目比文件的范围大。
项目就是我们在解决方案资源管理器里,那个前面图标是方框带 C# 的这个项目。看到了吗,旁边有一个三角形,点击这个三角形,可以展开/折叠属于整个项目里的代码文件。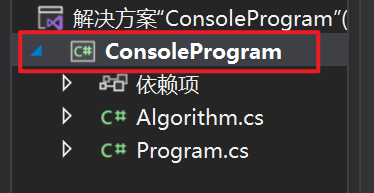
这里 ConsoleProgram就是一个项目;而它上面的 Solution ‘ConsoleProgram’ 就是整个解决方案,其解决方案的名字就叫 ConsoleProgram,这里的单引号里的内容。
一头雾水是吧,为啥解决方案居然和项目名是一样的?一般来说,因为解决方案和项目的关系是“解决方案 > 项目”。但实际上,可以划等号:大多数时候,我们在教学和初学 C# 编程的时候,一个解决方案只需要容纳一个项目就可以了。既然一个解决方案只包含一个项目,那么整个项目名称就完全可以和解决方案的名字是一样的,单纯是为了简单。如果取名不一致的话,可能你会觉得解决方案的代码乱糟糟的。
3-2-2 internal 的实际意义
internal 关键字一般用在类的声明之上(当然也可以用在成员上),这表示这个类或者这个成员,是整个项目里的任意位置可以用;但超出这个项目(比如这个解决方案里有俩项目,另外一个项目里调用这个成员或者类)的话,这个时候,你就“看不见”它了:或者换句话说,你就不可以用这个东西了。
比如这样,我们创建了一个新的项目。然后使用此类。
因为创建新项目这个内容我们没有必要用,所以这里就不展开给大家讲解怎么在同一个解决方案里创建新的项目了。
创建项目和创建类代码文件的方式是一样的,只是选择的东西是 Add project 而不是 Add new item;而且在点选创建的时候,不是在项目上(因为项目里只能创建文件,项目不能嵌套项目),而是只能在解决方案上点右键选择创建。
很遗憾,可以看到代码上报错了。它提示的文字是“’ANewClassInAnotherProject’ is inaccessible due to its protection level”。翻译过来就是,这个类因为访问级别低的关系,你无法使用它。
这里演示给大家看,就是这么一个道理:如果用了 internal 关键字的话,类仅在这个项目里可以随便用;超出了范围就无法使用了。
3-3 private 关键字
最后一个关键字是 private。我们可以看到,目前我们就只有 Main 方法上用到了这个访问修饰符。这个访问修饰符指的是,这个成员仅在这个类里面随便用;超出去的任何位置(不管是别的类还是别的项目),都不可以使用此成员。
可以看到,因为 Main 方法的特殊性,这个方法仅提供给系统自动调用,因而设置为 private 是最安全也是最正确的行为:因为我们禁止让外部的任何一处使用和调用 Main 这个特殊的方法。
当然了,Main 方法本身是特殊的方法,因此你也别想着递归调用它,或者是在类的别处调用 Main 方法本身。虽然这个写法编译器并不会管你:
internal class Program
{
private static void Main()
{
// Simulate a case that uses 'Main' method via another method.
AnotherMethod();
}
private static void AnotherMethod()
{
Main();
}
}
确实是允许的,但这样很危险:因为 Main 本身就是系统特殊方法,你自己用指不定会出什么代码的 bug 呢。如果你递归学习得并不是特别理想,这样的程序必然会导致严重问题的出现。不过从语法上讲,因为设置的 private 允许在类里的别处随便使用它,因此语法是允许这么做的。
C# 的标准版一共有 5 种访问修饰符,但目前只能讲清楚这三种,剩下的两种我们需要在讲了“继承”特性后,才能说。总之你先把这三个记住就可以了。其中,最低的是 private,只能在类里随便用。当然,也没有比 private 还低的级别了,因为级别再低的话,就没有意义了;最高的是 public,随时随地都可以用。
3-4 其它的一些问题
当然了,前文的代码还有一些小的细节需要说明清楚,因此我们这里列出来给大家介绍一下。
3-4-1 类也是可以修饰访问修饰符的
显然,前面的类标记了 internal 就是一个典型的例子。但是,我们来思考一下,给类的声明上标记 private 是不是可行的写法?显然,private class 的组合是不科学的,因为类是面向对象的基本单位,因此类和类之间是独立的代码块。我们要使用这个类,至少也需要保证类本身是可以在项目里访问。否则,这个类就失去了意义:比如说,我给类标记了 private,那么就说明类本身只能在这个类里可以用。这是个啥?整个解决方案代码那么多,居然存在有一个类完全独立开别的代码,只能够自己使用自己,是不是说不过去?
因此,类的访问修饰符最低也必须是 internal,而且,类仅只能用 internal 和 public 这两种访问修饰符。就算我们后面把剩下的两个访问修饰符都说了,类依旧只能用这俩访问修饰符对访问级别进行修饰。
3-4-2 类的访问修饰符和成员的访问修饰符不一致,怎么理解?
internal class Algorithm
{
public static void BubbleSort(int[] array)
{
for (int i = 0; i < array.Length -1; i++)
{
for (int j = 0; j < array.Length - 1 - i; j++)
{
if (array[j] > array[j + 1])
{
int temp = array[j];
array[j] = array[j + 1];
array[j + 1] = temp;
}
}
}
}
}
比如上方这样的代码格式,类的修饰符是 internal,但 BubbleSort 这个成员却用的是比 internal 大的访问级别 public。那么这个 BubbleSort 到底能不能访问呢?最终的访问级别是怎么样的呢?
实际上,套在内部的 BubbleSort 会受到外部 internal 级别的影响,保证这个方法的级别是取 internal 和 public 里较小的那个级别。换而言之,既然类都是 internal 的,那么里面设置的级别肯定得基于 internal 来作判断,对吧。总不能里面成员的访问基本比类的访问级别还大,那就说不过去了。
代码书写上,内部写的是 internal 还是 public 都无所谓,因为最终取的还是 internal;但是实际上,写 public 就是为了省事。因为我们这么设置访问级别的话,假设有一天我想把 Algorithm 类暴露(Expose)出来给用户用了的话,就不一定非得是项目内的使用了;如果你内部的成员设置的是 internal 的话,根据级别要取较小的原则,别的用户还是用不了成员。因此,这么写组合是为了以后代码的可拓展性,是一个好的习惯。
总之:要注意两点:
- 成员的最终可访问级别,是取的类的访问级别和里面的成员的访问级别的较小者;
按照习惯,如果类需要修饰 internal 的话,那么成员依旧使用 public,除非这个成员本来就不是给外人用的。
3-4-3 访问修饰符可以不写吗?
C# 里为了保护代码的安全性,一般是取最小的原则:尽量越小越好。因此,C# 是做了这么一个代码约定的:如果不写的话,默认就是这个成员可访问级别的最小的这种。举个例子,类的最小访问级别是 internal,因此如果不写访问修饰符到类的声明上的话,我们就默认这个类是 internal 的;如果成员没有书写访问修饰符的话,那么我们默认这个方法是只能在类里随便用的,即 private 的。
所以,让我们来总结一下这几个访问修饰符:public 关键字:随时随地都可以用。
- internal 关键字:只有当前的项目里可以用;而出了这个项目后,这个东西就不能用了;
- private 关键字:只能用在类里面的成员,表示只能在这个类里随便用;超出去的任何位置都是不能用的。
另外,访问修饰符的默认情况如下:
- 类的声明上,如果缺省访问修饰符,默认是 internal;
- 成员上,如果缺省访问修饰符,默认是 private。
Part 4 static 修饰符
因为非访问修饰符,我们就用到了 static,而 unsafe 这类修饰符我们在之前已经介绍过,因此这一部分的内容我没有写成“非访问修饰符”,而是写的“静态修饰符”。
4-1 实例和静态的概念
static 一词对于初学者来说非常不友好,因为它并不是很好从单词的字面意思上理解。方法是类的执行核心,我们可通过 类.方法 的格式使用它,那么自然而然就意味着方法我们可以无忧无虑地使用它们,只要访问修饰符级别合适,方法的调用肯定是得心应手的。
不过,C# 还存在一类成员,称为实例成员(Instance Member)。和静态成员不同,实例成员往往会和一个物体或个体做一个绑定。比如减肥、跑步等行为,如果我们要写成代码的话,就必然会和一个人的个体单独进行绑定(因为跑步和减肥都是一个人自己的行为)。如果人的减肥和跑步这些行为我们依然使用 static 来表达的话,显然就不合理了。可以从代码里看到,我们前面使用和利用的行为,都不需要依赖于个体就可以执行:比如 int.TryParse、Console.WriteLine、Math.Sqrt。第一个是把字符串解析成整数的行为,它显然并不依赖于任何一个整数个体;而控制台打印文字到屏幕上的过程,也不是依赖于哪一个控制台,因为我们就一个控制台用来显示内容,因此它并不依赖于一个泛指的个体。你可能会问我,求平方根总是依赖于一个数值了吧!是的,但是 C# 代码的思维是:求平方根是一个统一规范的操作流程,它是绑定一个数值“参与运算”,而并不是“依赖于”数值本身。另外,Math 这个类还包含了很多方法,可提供给我们使用(比如求绝对值啊、正弦啊、取对数什么的)。计算我们可以让它按类型进行绑定来使用,就需要把这些东西写进这个类型的类(或是之前说的结构)的代码文件里。但是,这样又会使得整个类型的代码变得相当多。因此,利用静态成员而不是实例成员的思维方式,可以避免类型变得很臃肿。
关于实例的用法和语法,我们将在下一节的内容给大家介绍。它的内容也是非常多,要慢慢来学才行。
4-2 让我们现在再来理解静态方法
说完静态和实例的区别后,我们再回到头看 static 方法,你就会轻松不少。我们之前写了不少的代码,比如求质数之类的程序。我们再次把代码放到这里。
using System;
internal class Program
{
private static void Main()
{
// Input a value.
int val = InputValue();
// Check whether the number is a prime number.
bool isPrime = IsPrime(val);
// Output the result.
OutputResult(isPrime, val);
}
static int InputValue()
{
int val;
while (true)
{
try
{
val = int.Parse(Console.ReadLine());
break;
}
catch (FormatException)
{
}
}
// Returns the value.
return val;
}
static bool IsPrime(int number)
{
for (int i = 2; i <= Math.Sqrt(number); i++)
{
if (number % i == 0)
{
return false;
}
}
return true;
}
static void OutputResult(bool isPrime, int number)
{
if (isPrime)
Console.WriteLine("{0} is a prime number.", number);
else
Console.WriteLine("{0} isn't a prime number.", number);
}
}
请观察代码的修饰符。我们最开始就强制性让大家添加 static 关键字。这是有道理的:首先,Main 方法并不依赖于什么东西,它是系统自动调用的方法,是一个特殊的方法,因此我们必须在 Main 上追加 static 关键字;而其它的方法,都是在 Main 里得到了调用。既然 Main 都是静态的了,那么我们没有理由给这些其它被调用方法让他们改实例的:因为它们是 Main 调用的,Main 都不依赖于实体,那么调用的这些方法,肯定也不会依赖于实体对象才对。我总不能说,我拥有一个 Program 的实体对象,才能计算这些东西吧。显然没有必要也没有意义(毕竟,一个 Program 的实体是什么,这我怎么理解都不知道)。因此,定义成静态的方法,显然是正确的思维。
静态我们就先说到这里。
顺带一提,这些方法都是给 Main 方法服务的,所以肯定不能给别处用了,自然就没有写访问修饰符。当然了,写也最好写 private,你说是吧。
Part 5 文档注释
为了帮助我们书写代码,和查看代码的相关信息,C# 提供了一种机制,叫做文档注释(Documentation Comment)。文档注释可以直接将代码的描述信息呈现到代码贴士里,以便我们鼠标放到每个成员上查看信息的时候,可以直接看到描述文字。
当然,如下我们会介绍非常多的文档注释的相关写法,但是有些我们用不上,就简单说一下;有些重要的我们就写详细一点。
5-1 文档注释的架构
我们先来说一下文档注释的用途和架构。文档注释用三斜杠开头:///,在斜杠后,书写注释文字。它们并不会影响程序的执行,因为它们是注释文字。但是,文档注释提供了一个规范的书写格式,只要我们按照格式写,你就可以发现,这些注释文字就会显现在代码贴士上。
图上这个小条我们暂且称它“代码贴士”。一旦我们在上方追加叙述文字后:
你就会发现,这段文字的描述信息就呈现上来了。只要我们鼠标放在 InputValue 上,我们就可以看到它。
文档注释是通过类似 XML 的扩展语法标记来完成说明的,它可以写在类上,也可以写在成员上。文档注释用到的标记非常多,但是都有自己的用途,因此有必要给大家说明清楚具体用法。
下面我们来说一下基本的零部件。
5-2 基本文档注释块
5-2-1 summary 块
图上就用到了 summary。我们写上成对的 summary,前面用尖括号,后面也是尖括号,但里面的 summary 左侧要加上一个斜杠,用来表示标记是结束的。在期间,我们书写文字,这些文字是用来描述被注释的对象(方法啊、类什么的)的基本信息用的。文字可以有很多,如果一行写不下的话,可以换行书写。
5-2-2 remarks 块
和 remarks 块差不多,它也是描述文字,用来表示这个东西的基本信息的。不过区别在于,remarks 块是可选的,你可以不写 remarks,但 summary 是必须有的。remarks 是补充说明文字,比如说我们要对求质数的核心方法写文档注释的话,summary 块的内容可能是“计算一个数,是否是一个质数。”;但 remarks 的文字则可能是“请注意,由于是计算质数,因此传入的数字必须得是一个大于 1 的正整数”。
5-2-3 returns 块
如果方法具有返回值的话,我们可能需要用 returns 块来表达这个方法的返回值到底返回了个什么。比如说,判别质数的返回值一定是一个 bool 结果,那么 returns 块里的内容可能就是“一个 bool 类型的数值,用来表示是否是质数:是则返回 true,否则返回 false”。
5-2-4 param 和 paramref 块
param 块是一个单标记的 XML 块,它专门描述叙述一个参数,以及参数的对应解释。举个例子,在 IsPrime 方法里,我们需要传入一个 int 类型的数据。这个时候,我们可以在方法的文档注释里追加一行 The number to check.,就可以达到描述参数的效果。
当然,因为是描述参数的文字,所以它不会直接呈现到代码贴士里。你需要在调用的时候才看得见:
调用方:
可以看到,只有在输入了这个左小括号 ( 后,才会提示这个文字信息。
当然了,我们只需要追加到文档注释里,因此我们不需要在意书写 param 标记的具体位置。你可以把它放在最开始,也可以放在最后面。只要包含这个解释文字,那么文字就会正常显示到代码贴士里。
接着,我们可以在文档注释的别处引用这个参数。举个例子,我们在描述 number 参数的时候,可以类似前面讲解 remarks 块那样,追加解释文字,提示用户在使用的时候建议使用大于 1 的正整数。不过,这个时候我们会用到 number 参数作为解释的一部分:“请注意参数 number 需要大于等于 2”。此时这个 number 你可以手写到文档注释里,不过建议的格式是使用 paramref 这个单标记的块。
/// <summary>
/// Please note that the argument
/// should be greater than 1 due to the method checking whether the number is a prime,
/// which will be unmeaningful when the number isn't an integer,
/// or the value is lower than 2.
/// </summary>
例如我们提取出了这段文字,里面第 2 行里,就用到了这个写法。
5-2-5 example 块
example 块很少用到,它也不会在任何时候呈现到代码贴士里。example 是追加到文档注释里,表示代码使用的一些相关示例的。你可以在 example 块里追加一些格式。
/// <summary>
/// For example, you should write "bool result = IsPrime(17);" to determine
/// whether the number 17 is a prime, and the variable 'result' stores and
/// indicates the result.
/// </summary>
比如这样。实际上,这里是可以直接搁代码的,不过代码块我们将在稍后介绍到。
5-2-6 exception 块
很多时候,可能有方法需要自己产生异常(通过 throw-new 语句抛出一些异常)。这个时候,我们可以通过文档注释,提供给用户,让用户在查看方法本身的时候,可以看到这个方法可能会在内部产生的异常。
它的格式和 param 差不多,它的格式也是差不多的。不过这里,参数用到的是 name=”” 的格式,而这里,我们写的是 cref=””,这一点需要你注意。
/// <exception cref="FormatException">
/// Throws when input is invalid (not a real number).
/// </exception>
比如这样写,追加到文档注释里,表示这个方法可能会在输入不合法的时候产生 FormatException 异常类型。不过在用户查看的时候,注释文字是看不见的,而是显示成类似这样:
5-3 内联文档注释块
有一部分写法,是内联到前面介绍的块里的,并不是单独写的。下面介绍一些基本的写法。
5-3-1 c、code 块
c 和 code 块都是嵌入到 summary 啊、remarks 里使用的内联块。它们表示一段代码或者内联的代码。比如我们现在在书写这篇文章的时候,“summary 和普通单词 summary”的区别在于,前者我们使用了内联代码的渲染。我们也可以把这样的东西写进文档注释里。写法是
/// <example>
/// For example, you should write bool result = IsPrime(17);to determine
/// whether the number 17 is a prime, and the variable 'result' stores and
/// indicates the result.
/// </example>
比如 bool result = IsPrime(17); 就可以写成一个内联代码块。另外,如果这个内联的代码较长的话,我们可以考虑单独提行书写,比如这样:
/// <example>
/// For example, in the <see langword="for"/> loop, we can write this:
/// <code>
/// for (int i = 0; i < 100; i++)
/// {
/// if (IsPrime(i))
/// {
/// Console.WriteLine("{0} is a prime!", i);
/// }
/// }
/// </code>
/// </example>
比如这样。
顺带一提,
5-3-2 u、i、b 和 a 块
这个相比不用多说了。这个是 HTML 沿用下来的标记。u 是下划线,i 是斜体,b 是加粗,而 a 则是超链接。
我们拿 a 标记来举例说明用法。
/// <summary>
/// To output the result. If the <paramref name="number"/> is a prime, the console
/// will output a line of <see cref="string"/> tells "The specified number is a prime";
/// otherwise, "The specified number isn't a prime".
/// For more information you can visit
/// <a href="https://mathworld.wolfram.com/PrimeNumber.html">this page</a>.
/// </summary>
比如这里第 6 行就是一段引用 a 标记的写法。而查看代码贴士的时候:
5-3-3 para 块
para 块就是作为一个段落呈现的。比如前文里,我们可以把它拆成两个段落来呈现:
/// <summary>
/// <para>
/// To output the result. If the <paramref name="number"/> is a prime, the console
/// will output a line of <see cref="string"/> tells "The specified number is a prime";
/// otherwise, "The specified number isn't a prime".
/// </para>
/// <para>
/// For more information you can visit
/// <a href="https://mathworld.wolfram.com/PrimeNumber.html">this page>/a>.
/// </para>
/// </summary>
5-3-4 list 块
最后最麻烦的是这个 list 块。list 块有三种用法,分别是“渲染表格”、“渲染有序列表”和“渲染无序列表”。我们挨个来说一下。
/// <returns>
/// A <see cref="bool"/> result indicating that. All possible cases are:
/// <list type="table">
/// <item>
/// <term><c><see langword="true"/></c></term>
/// <description>The number <b>is</b> a prime.</description>
/// </item>
/// <item>
/// <term><c><see langword="false"/></c></term>
/// <description>The number <b>isn't</b> a prime.</description>
/// </item>
/// </list>
/// </returns>
在之前的 IsPrime 函数里,我们介绍了返回值。但是返回值的描述并不详细,因此我们可以列表来表达。上方的这个描述文字写起来很丑,不过可以将就着看。
我们使用 和
一对标记来表达一个表格。里面是表格的具体内容。接着,我们使用 item 标记来写一行文字。表格只能由两列构成,这个是文档注释限制了的,因为这里的表格仅用来表达“数值:意思”这样的一组概念。
在 item 块里,我们嵌套 term 和 description 块分别表示“数值:意思”的“数值”部分和“意思”部分。到时候,代码贴士将我们这个表格渲染成这样:
在最下方就可以看到显示的表格。
前面我们说的是 list type=”table”,接着我们来说下别的值。list type=”number” 表示渲染一个有序列表;而 list type=”bullet” 则渲染一个无序列表。它们里面呈现项目的用法是一致的,所以我们一起说。
在呈现有序或无序列表的时候,我们里面就只需要嵌套一个单纯的 item 块就可以了。我们不需要在 item 里继续嵌套 term 和 description 块,因为这俩是给表格提供渲染用的。
如果要写若干项目,我们只需要挨个写出来内容(文字),直接丢进 item 里就可以了。
/// <list type="bullet">
/// <item>
/// <c><see langword="true"/></c>: The number <b>is</b> a prime.
/// </item>
/// <item>
/// <c><see langword="false"/></c>: The number <b>isn't</b> a prime.
/// </item>
/// </list>
5-3-5 see 和 seealso 块
see 块和 seealso 块用来引用除了参数之外的别的东西,比如说类啊、方法之类的。举个例子。
/// <summary>
/// To output the result. If the <paramref name="number"/> is a prime,
/// the console will output a line of <see cref="string"/> tells
/// "The specified number is a prime"; otherwise, "The specified number isn't a prime".
/// </summary>
/// <remarks>
/// Although we know that we can call the method <see cref="IsPrime(int)"/>
/// to check whether the number is a prime, but here the parameter
/// <paramref name="isPrime"/> is used for checking and switching the output result
/// without any extra calcuations.
/// </remarks>
/// <param name="isPrime">
/// A <see cref="bool"/> value indicating whether the <paramref name="number"/> is a prime.
/// </param>
/// <param name="number">The number to output.</param>
/// <seealso cref="IsPrime(int)"/>
static void OutputResult(bool isPrime, int number)
{
if (isPrime)
Console.WriteLine("{0} is a prime number.", number);
else
Console.WriteLine("{0} isn't a prime number.", number);
}
可以从这个方法的文档注释里看到,我们内嵌了一个
这么写的作用是为了表达实际上真正的类和方法在哪里。如果你直接写 string 和 IsPrime 的文本到注释里的话,我们就无法通过纯文本来反推出这个玩意儿的具体位置。而写成 see 的话,当鼠标移动到写文档注释的这个成员上、系统会弹出代码贴士的时候,我们可以直接用鼠标单击这个信息,就可以跳转到对应的代码位置上去。
点击这里的 IsPrime 后,代码就会自动跳转到 IsPrime 方法那里去。
另外,seealso 和 see 差不多,只是 seealso 是单独用的。它写在最外面,表示在文档注释里用到的(用 see 块引用了的)类型、成员信息。就好像你写的论文里的“参考文献”、文章里的“另请参考”这种东西。
5-4 文档注释的注释
呃,我们甚至可以给文档注释本身写一个注释文字信息,来提供一些帮助程序员自己开发代码的时候完善文档注释的帮助文字。它的格式和 HTML 的一样,也是 。
///
文档注释的注释是不呈现也不会渲染的,因此我们大大方方写进去就可以了。
5-5 完整例子
总之,这里给大家提供文档注释的书写规范:我们使用前面求质数的程序给大家展示文档注释。
using System;
/// <summary>
/// Indicates the main class that contains the main method.
/// </summary>
internal class Program
{
/// <summary>
/// The <c>Main</c> method, which is the main entry point of the whole project.
/// </summary>
private static void Main()
{
// Input a value.
int val = InputValue();
// Check whether the number is a prime number.
bool isPrime = IsPrime(val);
// Output the result.
OutputResult(isPrime, val);
}
/// <summary>
/// Input a value.
/// </summary>
/// <returns>The value.</returns>
static int InputValue()
{
int val;
while (true)
{
try
{
val = int.Parse(Console.ReadLine());
break;
}
catch (FormatException)
{
}
}
// Returns the value.
return val;
}
/// <summary>
/// Determines whether the specified number is a prime one.
/// </summary>
/// <remarks>
/// Please note that the argument <paramref name="number"/>
/// should be greater than 1 due to the method
/// checking whether the number is a prime,
/// which will be unmeaningful when the number isn't an integer,
/// or the value is lower than 2.
/// </remarks>
/// <param name="number">The number to check.</param>
/// <returns>
/// A <see cref="bool"/> result indicating that. All possible cases are:
/// <list type="bullet">
/// <item>
/// <c><see langword="true"/></c>: The number <b>is</b> a prime.
/// </item>
/// <item>
/// <c><see langword="false"/></c>: The number <b>isn't</b> a prime.
/// </item>
/// </list>
/// </returns>
static bool IsPrime(int number)
{
for (int i = 2; i <= Math.Sqrt(number); i++)
{
if (number % i == 0)
{
return false;
}
}
return true;
}
/// <summary>
/// <para>
/// To output the result. If the <paramref name="number"/> is a prime, the console
/// will output a line of <see cref="string"/> tells
/// "The specified number is a prime"; otherwise, "The specified number
/// isn't a prime".
/// </para>
/// <para>
/// For more information you can visit
/// <a href="https://mathworld.wolfram.com/PrimeNumber.html">this page</a>.
/// </para>
/// </summary>
/// <remarks>
/// Although we know that we can call the method <see cref="IsPrime(int)"/>
/// to check whether the number is a prime, but here the parameter
/// <paramref name="isPrime"/> is used for
/// checking and switching the output result without any extra calcuations.
/// </remarks>
/// <param name="isPrime">
/// A <see cref="bool"/> value indicating whether
/// the <paramref name="number"/> is a prime.
/// </param>
/// <param name="number">The number to output.</param>
/// <seealso cref="IsPrime(int)"/>
static void OutputResult(bool isPrime, int number)
{
if (isPrime)
Console.WriteLine("{0} is a prime number.", number);
else
Console.WriteLine("{0} isn't a prime number.", number);
}
}
实例、构造器和字段
前一节我们讲到了基本的面向对象的使用方式。我估计你也看得不是很懂,是因为你没有转换思维方式,还是用的 C 语言那套面向过程的编程模式。总之,慢慢熟悉一下面向对象的写法格式,用类来把代码规范规划出来,构成一整个项目,这是 C# 最基本的编程范式。
今天我们要说的是另外一个面向对象里重要的基本概念:实例(Instance)。
Part 1 什么是实例
在之前我们简单说到过,实例和静态的区别是,实例是将一个事物用代码呈现出来的时候,一个单独的个体。要想写成代码,我们就得考虑写成代码的时候,操作的行为是以个体为单位的形式,还是没有单独的个体操作的形式。实例和静态方法的区别就在于,只需要去掉 static 修饰符,就从静态方法改成实例方法了。
Part 2 字段
2-1 字段的概念
只说方法,可能不一定能体现出实例的真正作用。我们来写一个真正的例子。我们现在用 Person 类来表达一个人,存储这个人的基本信息(姓名、性别等等信息)。
class Person
{
public string Name;
public int Age;
public bool IsBoy;
}
下面我们来看一下这个例子。这个例子里我们给 Person 里写了三个直接以分号结尾,也没有括号的语句。这个格式的东西我们称之为字段(Field)。字段的作用就是存储这个类里基本的数据信息;而如果用面向对象的角度来说,Person 类专门用来表达一个人的个体的基本数据信息,而 Name 字段可以理解成这个人的姓名这个基本信息、Age 则是年龄、而 IsBoy 则是表达这个人是不是男生。
可以看到,这三个字段都没有任何一个标记了 static 修饰符。这意味着这三个字段都是实例字段。之前说过静态方法,因为它的整个行为和操作过程都和个体无关;但是这里给出的三个字段都跟个体联系上:因为这些字段信息存储的都应该是一个个体本身的信息。
字段可以有很多,也可以一个都没有。字段体现整个“个体”本身的基本数据信息。有些时候,要想精确描述和表达一个个体的具体内容,就必须得很多字段;但是有时候,一个都不需要也是可以的。
2-2 字段的用法
字段的信息怎么和我们交互呢?这就需要我们通过变量或者 Console.ReadLine 来输入了。
现在,我们可以考虑在 Main 方法里,给定一些基本的变量,而且变量的类型对于字段的类型要一一匹配。
// Stores the values.
Person person = new Person(); // Creates a new instance by 'new' clause.
person.Name = "Sunnie";
person.Age = 25;
person.IsBoy = true; // Maybe...
// Output the value.
Console.WriteLine(
"The {0}'s name is {1}, {2} {3} old.",
person.IsBoy ? "boy" : "girl",
person.Name,
person.Age,
person.Age == 1 ? "year" : "years" // Decide singular or plural.
);
我们注意第 2 行代码。这一行的代码我们用到了和 throw-new 一致的 new 类名() 的格式,然后将整个表达式赋值给左侧的 person 的变量(似乎,确实是在定义和赋值变量,因为变量的定义就是这么写的)。
接着,我们给变量录入了一些数值,并使用的是 .Name、.Age 这样的书写。是不是很眼熟?是的,之前学习字符串操作的时候,我们用过一个叫做 .Length 的写法来获取字符串的长度;而在数组的后面直接跟上 .Length 得到的则是数组的元素数。是的,这里我们依然用的是这个小数点。小数点相信已经深入人心了:它就是我们之前前一节的成员访问运算符,读作“的”。不论在获取数组长度和字符串长度的时候,都是跟一个单独的个体关联起来的,因而它们(Length 这样的东西)都是实例成员。只是说,这些是系统提供的,你无法查看内部的代码,只能看到它有这么一个东西的存在。但是用法和我说的它的用法是没有出入的。
它就和数组的用法是一样的,数组的索引器(arr[i])有两种用法:
- arr[i] = value;(赋值)
- Console.WriteLine(arr[i]);(取值)
这里的成员访问运算符所构成的表达式,也是如此:既可以赋值,也可以取值。取值就是类似第 10 到第 13 行里这么使用;而赋值就是最开始的第 3 到第 5 行的代码。
Part 3 构造器
3-1 构造器的概念
在第 2 行,我们用到了这个 new 表达式,这个表达式得到结果赋值给左侧的过程称为实例化(Instantiation);而你可以认为,new Person() 里的 Person() 是一个没有返回值(即 void 类型返回值)、不需要参数的一个特殊的方法,而这个特殊的方法,则可以认为是一个就叫做 Person 的方法。
这种和类名重名的方法,称为构造器(Constructor)。构造器和字段一样,也都是这个类的成员类型。构造器是一类特殊的方法,它专门使用 new 关键字,来调用它们;而我们自己是无法调用的。
3-2 构造器到底是实例还是静态成员
这个说法估计你也没明白,我们这么解释一下。按照道理来说,方法的调用方式是 类名.成员(静态成员的调用方式)或者是 变量.成员(实例成员的调用方式)。但是,构造器到底应该是实例成员,还是静态成员呢?按道理来说,它最终产生一个个体出来,然后赋值给左边的所谓“变量”(只是这里的变量的类型用是 Person 而不是 int 这样的数据类型了)。按道理来说,因为它没有绑定任何一个个体,只是产生个体,因此应该属于静态成员;而使用静态成员的调用方式,那就得是 Person.Person() 了:前面这个 Person 是类名,而后面这个 Person 在前面说过,它是一个和类名同名的特殊方法的方法名称。但是你这么写,C# 编译器会告诉你,这么写不对:
它会告诉你,这么写不对:因为 Person 类里没有叫 Person 的方法。这是为什么呢?因为构造器是一类特殊的方法,因此我们无法通过这样的形式调用。也正是因为如此,构造器并不能认为是静态的成员。
那难道就是实例成员吗?看起来也不是。刚已经解释过了,构造器是创建和产生一个个体,而不是绑定和使用个体。但是,很遗憾地通知你,构造器是实例成员。原因很简单:因为它不是静态成员,所以它就是实例成员了。
实际上是这样的。因为它的创建过程是在对个体创建内存空间,然后将结果赋值给左侧的这个“变量”。从细节上讲,它确实在改动这个个体。不过这个改动是在初始化,就好比给变量赋初始值一样,这个初始数值不也得凭空产生吗?既然要产生出来那就必然会有一定的内存的复杂操作,所以它是在改动这个个体的。
那么至此,我们需要注意和掌握的两个内容就是:
- 构造器是实例成员,而不是静态成员。另外构造器是实例成员,也只能是实例成员;
- 构造器必然只能使用 new 关键字,带上构造器写法来使用。
正是因为构造器只能是实例成员,因此我们无法对构造器添加和追加 static 修饰符。
3-3 自定义构造器
构造器既然是特殊的方法,那么我们就得知道参数传入的问题。构造器只能是无参(Parameterless)的吗?实际上不是。
构造器可由我们自行定义,而 Person() 这个无参构造器是系统自动生成的:只要我们不自己定义构造器的话,无参构造器就会自动生成;而要定义构造器的话,这个无参构造器系统就不会给你自动产生。
这么说也不明白,我们还是拿例子来解释。
class Person
{
public string Name;
public int Age;
public bool IsBoy;
public Person(string name, int age, bool isBoy)
{
Name = name;
Age = age;
IsBoy = isBoy;
}
}
我们来看第 7 行开始的格式写法。我们就把构造器当成方法来看,那么参数表列的格式和方法的书写格式完全一致;而构造器本身是不带返回值的,因而我们干脆就不让你写返回值类型。当然了,你可以带有访问修饰符。显然,构造器是拿给外部用的,那么你在这里,写 private 是不合适的。而之前就说过,构造器也是成员。成员的默认的访问修饰符是 private,因此我们不能省略这个访问修饰符。因此,整个构造器的签名就长成这样。
然后,我们在构造器的里面写的是赋值。我们把参数写出来,正好对应上每一个字段,这样保证每一个字段都能够赋值完成。
在调用方,我们需要修改构造器的那行代码。因为我们刚才说过,一旦我们自定义了构造器后,无参构造器就不会默认产生,因此我们这么写此时会出错。
改成这样:
// Stores the values.
Person person = new Person("Sunnie", 25, true);
我们可以看到,代码改成这样了。我们按照顺序将数据传入到里面去,最终就会得到一个这样的个体,赋值给左侧。
3-4 其它的构造器的问题
3-4-1 如果我们不对一些字段赋值,这样写可以吗?
实际上,是可以的。C# 允许你不给变量赋值。那么这个字段如果不赋值的话,就会保持这个类型的默认数值作为初始结果。
举个例子,假设我们还是用无参构造器初始化的话,那么产生的个体,最终得到的 Name 的数值是 null、Age 的数值是 0,而 IsBoy 的数值则是 false。这个 null 是什么呢?你可以这么想这个问题。类产生的个体一般都很大,因为它是多个字段构造搭起来的。而且是不定长的。这个 null 就相当于没有内存空间存储这个个体。换句话说,给 person 这个“变量”赋值 new 出来的个体,和赋值 null 的区别是,一个会产生一个个体出来,而另外一个则完全不会产生个体。你按照集合的空集来理解就行:它不占任何存储空间,只是一个概念上的不存储数据的一种存在。因此,对于字符串来说,null、空字符串的区别就是,一个是有内存空间占据的,一个则是完全不影响程序的无内存空间占据的。
而 0 和 false 作为默认数值就比较好理解了,因此我就不用多说了。这一点在数据类型里就说过一次。
3-4-2 构造器是没返回值的,那怎么 new 的时候可以赋值给变量?
这个问题问得好。答案也比较好说:就是特殊处理过。构造器本身并不会用 return 带出数值结果,但是本身是在对一个个体修改内部的数据。这个正在创建和改动的个体,就是整个 new 表达式的结果。但是可以从这个说法里看出,这个带出的个体我们是无法通过代码书写出来的,因此我们就没有写了。
3-4-3 构造器可以重载吗?可以重载的话,我能自己定义无参构造器吗?
答案是可以的。构造器允许重载,它和方法是差不多的,因此重载规则是一样的。而因为无参构造器会在自己定义构造器后自动消失,因此我们可以自己手动把无参构造器写出来:
class Person
{
public string Name;
public int Age;
public bool IsBoy;
public Person()
{
}
public Person(string name, int age, bool isBoy)
{
Name = name;
Age = age;
IsBoy = isBoy;
}
}
是的,就是一个单纯的大括号,里面啥都不写。因为无参构造器,难道还想跟这些字段给初始数值吗?反正系统会自己赋值给字段初始化默认数据(null、0、false 那个,刚才说过了)。
当然了,你如果不喜欢 null 的话,你可以手动在里面添加一行代码,来提供字符串的初始化行为,比如这样:
public Person()
{
Name = "";
}
其它的两个就不必赋值了。
Part 4 readonly 修饰符
是的,字段在前面我们已经介绍了赋值和取值过程。但是你有没有发现一个问题,这个字段就算写了构造器,后续也是依然可以修改和变动的:
// Stores the values.
Person person = new Person("Sunnie", 25, true);
// Output the value.
Console.WriteLine(
"The {0}'s name is {1}, {2} {3} old.",
person.IsBoy ? "boy" : "girl",
person.Name,
person.Age,
person.Age == 1 ? "year" : "years"
);
person.IsBoy = false; // Here we modify the field 'IsBoy'.
注意最后一行代码,我们确实改动了 IsBoy 字段。但是按照道理来讲,person 个体应该只在实例化后就不能再变动了。这个时候,我们可能会需要一个全新的关键字:readonly 关键字。你很容易就可以拆开这个关键字为两个单词:read 和 only。是的,就是 read-only 这个合成英语单词的合并写法。read-only 在英语里是只读的意思,这意味着,一旦修饰了 readonly,这个成员就不再可以修改和变动了。
那么很明显可以看出,readonly 是只能放在字段上的。因为它是针对于修改和变动来作为限制和约束,那唯一适用的对象就只有字段了,因此,readonly 只能用在类的字段上。
public readonly string Name;
public readonly int Age;
public readonly bool IsBoy;
我们将 Person 类的字段替换成这样的写法,即在访问修饰符 public 和类型名称中间插入 readonly 修饰符,这就表示字段只读了。只读的字段就无法在初始化(实例化)后再次变动和修改。
我们返回到调用方:
我们确实看到了错误信息:“一个只读的字段是无法赋值的”。
如果你觉得,这个字段只能在实例化的时候修改变动数据的话,那么字段请使用 readonly 修饰符修饰它,来保证以后无法修改它。
另外,除了我们给字段本身标记 readonly 以外,我们还可以为字段本身设置 static,因此字段是具有 static readonly 双重组合的修饰符表达的。
考虑一种情况。我们如果想要创建一个默认的个体,这个个体我怕别人用的时候乱用,我就打算写成一个只读的静态字段。在别人想要使用的时候,通过静态成员的访问方式来对个体进行访问,这样就可以避免他们不会使用这个类了。
我们将无参构造器用 private 修饰,而是给他们提供一个只读的静态字段 DefaultInstance,并赋值 = new Person()。看看这有什么奇妙的理解方式:
class Person
{
public static readonly Person DefaultInstance = new Person();
public readonly string Name;
public readonly int Age;
public readonly bool IsBoy;
public Person(string name, int age, bool isBoy)
{
Name = name;
Age = age;
IsBoy = isBoy;
}
private Person()
{
Name = "";
}
}
注意第 3 行。我们书写的这个写法。字段允许直接在后面就赋值,和变量的写法是一样的,这是 C# 允许的。而我们将无参构造器更改成 private 级别,这是防止别人使用的时候,在外部调用。如果想要使用默认的数值的话,我们提供了 DefaultInstance 字段。
于是,用户在使用的时候,必须这么写:
// Stores the values.
Person person = Person.DefaultInstance;
用这个写法,我们就可以通过作者给出的模式让你来获取默认情况的个体。
哦对,顺带一说。这种故意将无参构造器改成 private 修饰,然后提供一个静态的只读字段来表达默认数据的行为,称为单例模式(Singleton)。这种写法是一种固定的设计模式。所谓的设计模式就是为了帮助和辅助我们使用一些固定的软性规定,达到代码的固定书写格式,来达到一种模式化的意义。设计模式有非常多种,单例模式是其中的一种。
属性与封装
Part 1 为什么需要封装
面向对象拥有一些基本的特性。这些特性让我们理解和明白面向对象的意义。面向对象的三大特性:封装(Encapsulation)、继承(Inheritance)和多态(Polymorphism)。我们为了学习面向对象,我们不能一口气都介绍了,因此我们一个一个学习。今天先介绍的特性是封装。
1-1 封装的意义
考虑前面的代码。我们写了一个 Person 类。不过,我们写的代码提供给别人使用的时候,就好像我们无法查看系统提供的类,只能使用一样。
如果我们不将数据做好良好的包装、数据处理好,别人就可能会乱使用数据:比如说,给字段乱赋值。显然,人的年龄按道理来说是必须处于 0 到大概 150 之间。如果别人拿到数据的时候,故意或者无意赋值 200,或者是 -15,按照数据类型来说,数据没有超过这个数据类型的范围;但是这些数据对于“人的年龄”这个数据来说,是无效的数值。于是,我们就得考虑这种预防错误发生的情况。
可是,字段本身是用来赋值的,这我们无法防止;于是我们需要在某处给予数据的处理。举个例子。我们书写构造器的时候,可以防止此点。
public Person(string name, int age, bool isBoy)
{
if (name == null)
throw new ArgumentNullException("name");
if (age < 0 || age > 150)
throw new ArgumentOutOfRangeException("age");
Name = name;
Age = age;
IsBoy = isBoy;
}
我们可以追加两句代码。如果 name 为 null 的时候,显然名字是不合适的,于是我们就需要使用异常这个手段,终止程序来告知用户输入错误;同理,age 如果超出合适的范围的话,就通过另外的异常来产生错误信息,告知用户无法这么使用。
1-2 相关问题
1-2-1 ArgumentNullException 和 ArgumentOutOfRangeException 异常
这两个异常是我们全新使用的异常。异常是我们通过积累来使用的,这一点我们之前讲到异常结构的时候,说过这一个部分的内容。
这两个异常专门表示参数数值不正确的时候的异常。前者的异常类型名称带有 null 这个单词,这表示这个异常用在参数为 null 的时候;而后者写的是 out of range,这表示参数的数值超出了合理的范围。当一个数据在赋值的时候超出了实际的范围,我们可以使用这两个异常来处理。另外需要注意的是,这两个异常在 new 的时候,写这个错误参数的名字,比如说这里的 name,我们就写上这个名字:”name”。因为我们需要传入的是错误参数的参数名而不是它的数值,因此写 “name” 而非 name。
另外,这两个异常类型要想使用,需要你使用 using System; 指令。这一点我们不必多说,因为大多数异常类型都是在 System 这个命名空间下的。
1-2-2 异常可以解决问题,但为什么非得异常来报错呢?
问题不是很清晰。我们举个例子来让你明白这个问题想问什么。
我们刚才的代码里,第 4 和第 7 行用了 throw-new 语句来产生异常个体来报错,但是之前我们说过一个方案:如果 name 参数为 null 的话,我们干脆给 Name 字段赋值 “
这个说起来不是很容易。实际上,我们完全可以采用这个方案。但我们使用了异常的方案来处理这种情况。假如我们针对 age 参数来理解的话:如果用户赋值 -20 的话,显然是不正常的赋值形式,因此我们得处理这种非法数值的情况。假设我们不使用异常来告知用户,而是采用赋默认值的形式来的话:
if (age < 0 || age > 150)
Age = 0; // Invalid value.
else
Age = age; // Valid value.
当然你也可以写成一句话:
Age = age < 0 || age > 150 ? 0 : age;
可是,这么写有一个很隐蔽的问题。假如,用户这么书写代码来对 Person 的个体修改数值并显示该数值。
Person person = new Person("Sunnie", -20, true);
Console.WriteLine(
"{0} is {1} {2} old.",
person.Name,
person.Age,
person.Age == 1 ? "year" : "years"
);
这会输出什么?光看这段代码的话,我们无从知道 Person 内部的赋值和处理逻辑,而最终,明明输入的是 -20,而输出的字符串却是 “Sunnie is 0 years old.”,用户一看这代码的执行结果:欸,很奇怪啊!输入的 -20 怎么在输出的时候改成 0 了?从另一方面来说,如果你在写内部的代码的话,如果真这么处理的话,那我怎么知道我是真输入了 0 这个合法数字,还是因为输入了错的数字而导致赋了默认数值 0 呢?
因此,我们认为,在这种情况下,在内部将 -20 改成 0 的这种方案会导致很隐蔽的问题,因此我们不建议这么指定代码的执行方案,故我们采用了前者:抛出异常。
Part 2 属性成员
前面我们介绍了一些完全基础的成员类型:方法、字段和构造器。接下来我们单独拿一节内容介绍另外一种新的成员类型:属性(Property)。
2-1 引例
先来考虑前面的例子。我们在构造器里可以处理属性的赋值,可问题在于,如果我们想要重载构造器的话,参数可能就不一致了:我们没有必要非得把全部的参数都赋上数值,比如这里的 Name 字段。于是我们就可以考虑写成两个构造器:
public Person(int age, bool isBoy)
{
if (age < 0 || age > 150)
throw new ArgumentOutOfRangeException("age");
Name = "";
Age = age;
IsBoy = isBoy;
}
public Person(string name, int age, bool isBoy)
{
if (age < 0 || age > 150)
throw new ArgumentOutOfRangeException("age");
Name = name == null ? "" : name;
Age = age;
IsBoy = isBoy;
}
因为构造器有两个,因此我们就得针对于 age 参数使用同样的数据校验的代码(就那个 if)。显然,写两遍是没有必要的,因此,属性这个成员就诞生了。
我们将前面的 Name 字段、Age 字段全部改成 private 的修饰符,并改成“下划线+驼峰命名法”,而单独添加一个。
public class Person
{
private string _name;
private int _age;
private bool _isBoy;
public Person(string name, int age, bool isBoy)
{
Name = name;
Age = age;
IsBoy = isBoy;
}
public string Name
{
get
{
return _name;
}
set
{
_name = value == null ? "" : value;
}
}
public int Age
{
get
{
return _age;
}
set
{
if (value < 0 || value > 150)
throw new ArgumentOutOfRangeException("value");
_age = value;
}
}
public bool IsBoy
{
get
{
return _isBoy;
}
set
{
_isBoy = value;
}
}
}
代码略长,因为大多都是大括号占了单独的一行。我们使用格式 public 类型 属性名称 { get { 操作 } set { 操作 } } 来书写一个属性。
2-2 语法描述
由于我们对每一个字段都写了一个属性,因此有三个属性。三个属性的写法是类似的,因此我们选一个介绍即可。我们拿第二个 Age 属性作介绍。我们单独抽取出 Age 属性的代码:
public int Age
{
get
{
return _age;
}
set
{
if (value < 0 || value > 150)
throw new ArgumentOutOfRangeException("value");
_age = value;
}
}
我们使用一对大括号,包装 get 方法和 set 方法。我们将 get 方法称为属性的取值器(Getter),而把 set 方法称为属性的赋值器(Setter)。取值器是取出对应字段的信息,因此我们直接写 return _age;、return _isBoy; 这样的语句就好;而赋值器里则是给 _age、_isBoy 这些字段赋值的过程,以及数据校验的过程。
另请注意,正是因为如此,赋值器的返回值类型是根据属性本身动态变化的,因此我们不在 get 上写返回值类型;另外,get 方法也不需要参数,因为它仅提供返回字段的数据,因此无需参数就可以获取。同时,set 方法里,我们会带有一个从外部传入的参数,而不返回任何数据。这个外部传入的参数,它的数据类型也是根据属性本身的类型来确定的。
正是因为赋值器和取值器的参数类型和返回值类型动态变化,且它们的签名模式是固定的,因此我们只需要写 get 和 set 关键字即可。而 set 方法里固定会从外部带入一个数值进来,因此这个数值是固定存在的,我们使用 value 关键字代表这个参数。比如说在代码里,我们直接将参数 value 拿来使用即可,而无需在意它为什么之前从没声明出来。
2-3 相关问题
2-3-1 为什么非要下划线+驼峰?
可以看到,此处的字段从原始的帕斯卡命名法改成了下划线+驼峰命名法。我们之前简单说过,驼峰命名法和帕斯卡命名法仅仅是代码的规范,并不属于语法约定和要求。你完全可以不遵照这个规则来命名,因此这个写法只是一个写法而已。那么,为什么我们会采用这个写法呢?下面我来说一下下划线和驼峰的组合到底是为什么。
这个问题,我们需要将下划线和驼峰命名法拆开,分成两个部分来解释。我们先来说驼峰。因为属性用大写来保证我们前面赋值的过程和原始字段用的大写作匹配,而大写开头这个是 C# 建议的一种规范,因此,我们将属性用大写字母开头的帕斯卡命名法;而此时,字段变成了后台的数据存储了,因此字段此时被改成了 private,我们无法从外部访问和使用到它。显然,属性和字段是配对书写的,因此一套属性和字段,它们用的单词是完全一样的;但是,如果字段和属性用的单词一样,连大小写都一样的话,C# 肯定是不允许的,因为重名了嘛。重名了,我们使用成员访问运算符的时候,就没办法区分到底谁是谁了。因此肯定是不允许的。那么,既然是后台的字段,那么这个字段还是用小写吧。这就是为什么属性用大写开头的帕斯卡命名法、而字段是小写开头的驼峰命名法。
再来说一下下划线的问题。这个之所以放在后面讲而先说帕斯卡,是因为这个说起来要困难一点。VS 在写 C# 代码的时候相当方便,因为它有一个叫做智能提示(Intellisense)的东西。智能提示会尽量智能地告知我们,我们输入的代码现在是这样的话,下一步输入的东西应该是什么。比如说我们输入了 person.,既然小数点已经出来了,那么自然而然地,我们就知道这里的小数点是成员访问运算符,智能提示就会给出所有这个类型里的实例成员,我们选择到合适的提示项目后,按 Tab 按键或 Enter 按键,就可以自动补全这个实例成员到代码里。就像这样:
这个列表就是智能提示了。我们按方向键 ↑ 和 ↓ 来切换选项;也可以多输入一些字母,来精确筛选包含这些字符的实例成员名。
不过,我们从按键是无法区别和区分我们到底需要大写的还是小写的单词。有时候,我们在录入代码的时候,一旦我们输入了比如 Name 的话,智能提示因为无法确定开头字符,而会同时提示字段和属性。当你在字段最前面追加了下划线后,我们就能够完全避免开头字符是字母而使得智能提示无法知道我们到底需要属性还是字段:
比如图里,我们只需要输入一个下划线字符,智能提示就知道我这里需要使用字段,因此它会优先把所有字段全部筛选出来,避免我们的误用。因此,字段前面追加下划线是故意的,毕竟下划线是可以写进标识符的,因此我们故意找了下划线来完成这个任务。
2-3-2 为什么配套的那个字段不再只读了呢?
可能你已经注意到了这个细节。我们在代码里,字段的 readonly 修饰符被我去掉了。实际上,追加 readonly 会保证代码出问题。这是为什么呢?set 方法是属性的赋值器,这表示这个字段可能会在使用的过程之中更改和修改值。既然数值会被修改,那么字段就不能标记只读。
Part 3 使用属性的赋值器和取值器
我们介绍了如何写属性的代码;但是我们还没有说这个属性怎么使用呢?还记得字段吗?字段最开始我们使用赋值和取值的时候,就直接用的是成员访问运算符就可以搞定。
是的,C# 的属性为了避免语法复杂,就采用了相同的语法。比如说:
person.Age = 13; // Calls 'person.Age.set(int value)'.
Console.WriteLine(person.Age); // Calls 'person.Age.get()' and returns an 'int' value.
索引器
上回我们说完了属性的基本用法,它把字段包装起来,避免外部调用的时候出现赋值的错误。今天我们来讲一下第二类属性:索引器(Indexer)。
索引器也称为有参属性(Parameterful Property),因为它除了和属性的基本用法差不多以外,还可以带有一些自定义的额外参数信息。索引这个词语在 C 语言里就已经存在了,不过它不能自定义。C 语言里,我们取一个数组或者指针对应位置的数据的时候,会使用索引运算符,就是那个中括号语法。
在 C# 里,为了灵活使用语法,C# 贴心地为我们提供了自定义索引器的机制,并把索引器当成了面向对象的一种成员,可见地位还是很高的。
Part 1 引例
假设我们设计了两个数据结构,一个是链表节点(Node),一个则是叫链表(List)。假设我们暂时不考虑那些增删改查的处理代码,而只关心基本的过程的话:
public class Node
{
private int _value;
private readonly Node _next;
public Node(int v, Node next) { _value = v; _next = next; }
public int Value { get { return _value; } set { _value = value; } }
public Node Next { get { return _next; } }
}
public class List
{
private readonly Node _start;
public List(Node start) { _start = start; }
public Node Start { get { return _start; } }
}
这里啰嗦一下前面好像没有说过的语法点。因为它们经常用到,但因为这些东西比起别的知识点来说不是那么重要,所以我们不必单独拿一节内容给大家讲,干脆就在这里说了。 首先是这里的 List 类下的 Start 属性和 Node 类下的 Next 属性。这两个属性是没有 set 方法的。在 C# 里,这个语法是允许的,这种属性被称为只读属性(Read-only Property)。这里的“只读”和字段的“只读”略有不同。字段里,“只读”指的是字段的数据无法修改而标记的 readonly 修饰符;而属性里,因为属性是两个方法(get 和 set 方法)的整合形式的成员,因此我们是无法对方法标记 readonly 修饰符的;而另一方面,因为属性只有 get 方法,因此它仅用来取值,所以用户就无法使用 属性 = 数值 的赋值语法对后台的这个字段作赋值了。因此从这个角度来说,它是“只读”的:只用来读取数据的。从另外一个角度来说,我们无法使用 属性 = 数值 的赋值语法,也就无从通过别的方式对这个后台字段赋值了。后台字段此时就是只读的了,因此这个字段可以标记 readonly 修饰符。 第二。我们可以看到 Node 类型里,有一个 Node 自己这个数据类型的字段。这个语法称为递归类型成员(Recursed Member)。按道理讲,如果这个 A 类型下有 A 类型的字段的话,那么数据存储就可能无休止地使得存储空间膨胀起来直到撑爆内存。但实际上是这样的吗?C# 其实并不会导致这种情况的发生。它采用了指针的概念。Node 类型是用类写成的,每一个 C# 的类里,所有用到的类类型的成员,都会被认为一个特殊的指针。换句话说,这个成员实际上是一个指针变量,它指向的就是另外一块内存区域,存储的就是这个成员的数据内容了。而就原本的这个对象来说,假设它只有一个 int 类型的数据,和一个 A 这个类类型的数据的话,那么整体这个对象的存储空间只占据 int 的大小,和一个指针类型的存储大小的总和。因此,数据本身并不会像我们想的那样:放在一起导致内存被撑爆。 最后,因为类类型的东西在存储到别的对象里作为一个成员而存在的时候,它是一个指针。因此,类类型的所有数据,它们的默认数值是 null。这个 null 在字符串里讲过,它表示“没有内存分配”。是的,引用类型一般都较大,而且大小不固定,所以用 null 专门表达这些类型的对象“还没有内存分配”。那么,如果我们没有针对字段赋初始数值的话,所有字段会被赋值为“它这个类型的默认数值”。比如说 int 类型的默认数值是 0,而 Node 类型的默认数值就是 null 了。如果不写,就等价于在字段最后追加 = null;。
大概就这个样子。下面我们针对于这里的 List 类型来思考取元素的问题。
我们认为 List 是一个链表,因为它带有一个起头节点(Start 属性)。那么,我们通过移动“指针”,来达到遍历链表的过程。
int count = 0;
for (Node temp = Start; temp != null; temp = temp.Next)
{
count++;
}
比如这段代码。我们假设初始化的时候,给 temp 这个临时变量赋值 Start。然后,让 temp 不断执行 temp = temp.Next 这样的过程。temp 是 Node 类型的,而 Node 类型里包含 Next 属性,这个 Next 属性的意思是“当前链表节点的下一个节点;如果链表没有下一个节点的话,这个属性的数值就是 null”。那么不断 temp = temp.Next 就是在不断让 temp 的“指针”移动到下一个节点上去的过程。直到中间的条件 temp != null 不成立的时候,循环退出。
在循环体里,我们不断执行 count++ 操作,这表示每移动一次 temp 的“指针”,count 就会自动增加一个单位。对,没有错,这个 count 就是在记录整根链表的总节点个数。
C# 里,所有类类型的东西都是可以直接使用 == null 和 != null 的语法判别对象是不是 null 这个数值的。但是,这个等号和不等号后面是不能写别的东西的,比如 == 3。因为 Node 类型怎么可能可以和一个 int 作比较呢?要比较也只能比较两个 Node 类型才对啊。
C# 的 == 和 != 在值类型(就是前面说的那些个系统自带类型,string 除外)里,是判别数值是不是相同;但在类里,== 和 != 默认是判断指针是否一致,即两个对象是否指向的是同一块内存空间。显然,我们可以构造出两个数值上完全一样的 Node 类型的变量,但我们使用 == 和 != 是无法判别里面存储的数值是否一致的,因此一定要注意,== 和 != 在类里的比较行为。
所以,我们可以使用属性 Length,并把这段代码抄进去,来计算链表的总长度。
public class List
{
private readonly Node _start;
public List(Node start) { _start = start; }
public Node Start { get { return _start; } }
public int Length
{
get
{
int count = 0;
for (Node temp = Start; temp != null; temp = temp.Next)
{
count++;
}
return count;
}
}
}
Part 2 索引器的语法
索引器之所以还有个名字叫做有参属性,是因为它的格式和属性的语法基本一样,也是使用 get 和 set 来表达传入的信息。不过因为它还会带有额外参数,因此还是有不一样的语法。
假设,我们使用索引器来表达“这个链表的第几个节点”。这个“几”就是索引器参数。那么它的语法是这样的:
public Node this[int index]
{
get
{
int p = -1; // Please consider why here 'p' is assigned -1 as the initial value.
for (Node temp = Start; temp != null; temp = temp.Next)
{
p++;
if (p == index)
{
return temp;
}
}
return null;
}
}
可以从代码里看到,get 是我们要实现的,set 方法实现起来太复杂了(牵扯到链表里上下两个节点的指针的变动),因此我们暂时不考虑,也没有必要这里讲这么难的东西,毕竟这不是数据结构的课程。
我们只是改良了一下 Length 属性的 get 方法的代码。我们使用 p 表示和记录当前走到第几个节点了。如果 p 一直往下移动,走到和 index 的数值一样的时候,我们就认为,我们走到了这个节点上,于是就把 temp 的数据(之前说过 temp 是类类型的变量,因此它表达的是一个指针,相当于把指针作为数值)返回出去。另外一方面,如果我们传入的 index 不正常的话(比如链表还没有那么长,但你传入的 index 超过了这个总长度,显然就没有意义),于是我们返回 null 默认表达一个隐式信息:index 不正常。当然,这里你抛异常也行。
这里我们要说的是两个点。一个是语法上 public Node this[in index] 里的 Node,另一个是 this[int index]。
第一,Node 表达的意思和属性里表达的意思是一样的。写在索引器声明之前,如果是 get 方法,就表示这个属性的返回值类型;如果是 set 方法,就表示赋值的这个隐式变量 value 是什么类型的。索引器也是一样,get 方法里,表示这个返回值的类型是 Node;在 set 方法里则表示 value 这个隐式变量是 Node 类型的(从外部传进来的数值)。虽然我们这里 set 方法没有实现,但你肯定知道它的用法,对吧。
第二,this[int index]。这个语法看起来有点怪,我们说一下意思。this 是一个 C# 的关键字,它大概有四个用法:
索引器声明里(this[int index] 里这个 this);
构造器串联调用(: this(参数) 里这个 this,这个还没讲);
this 引用(this.成员 里这个 this,这个也没讲);
扩展方法的参数(this 类型 参数名,这个是 C# 3 才有的特性,所以还没有讲)。
当然了,这些语法我们之后慢慢都会接触到,不过我们这里需要了解的是其中的第一个用法。这里的 this 你可以理解成“一个万能替换变量”。当 Node 类型的变量出来之后,这个变量名就可以直接配合索引器运算符 [] 来表示取值。数组里,我们使用 arr[3] 来取 arr 这个数组的第 4 个元素的数值,而这里的 arr 就是一个数值类型的变量,它的写法格式就和这里的 this[参数] 是一样的,而具体碰到什么变量了,就把这个变量替换掉这里的 this 来表达索引器,比如说 list[3] 来取链表的第 4 个节点。这就是为什么索引器的声明语法这么奇怪的原因。
另外,在索引器参数里,我们是写成类似方法的参数一样的形式,先写类型,然后再写参数名。这个参数名是可以在 get 和 set 方法里用的。另外因为方法的特殊性,set 方法里你还可以用 value 这个隐式变量。
那么,语法我们就说到这里。下面我们来说一下索引器的使用。
Part 3 索引器的用法
下面我们说一下索引器的用法。其实也没啥好说的,和属性还有字段的方式完全一样,放在等号左侧就表示赋值(自动调用 set 方法);放在别的地方作为表达式计算的时候,就用的是 get 方法)。比如说:
Node a = new Node(1, null);
Node b = new Node(2, a);
Node c = new Node(3, b);
List list = new List(c);
Console.WriteLine(list[2].Value);
这表示什么呢?这显然就表示我们要取出 list[2] 这个节点,然后取 Value 属性作为结果输出。显然 list[2] 就是 a 了,因此我们可以看到输出的结果是 1。
Part 4 其它的问题
最后说两个无关紧要的问题,可能你会有这样的疑惑。
4-1 参数个数是否无限制
索引器的参数(比如前面这个 int index)可以无限制往后追加吗?
实际上,是可以的。索引器参数并没有规定非得只能有一个。你看,C# 里,矩形数组不就是可以后面用逗号分隔每一个数值吗?索引器在声明出来的时候,你完全可以写很多参数进去,比如这样:
public A this[int a, int b, int c, double d, float e, string f]
{
get { … }
}
这样是可以的。只是你在调用索引器的时候,你也得写这么多参数进去:variable[0, 1, 2, 3.0, 4F, “hello”]。
4-2 索引器是否可以重载
既然构造器、方法都能重载,那么索引器呢?
是的,索引器也能重载,毕竟它也是有参的存在。方法、构造器之所以可以重载,是因为它们都是有参数的成员。索引器是可以重载的,因为它也可以自定义参数和参数类型。只是我们从 C 语言里学习过来,可能有一种经验主义思维,以为 C# 索引器好像只能用 int 一样。实际上,并不是。因此,只要满足前面那些个重载规则,索引器也是可以重载的。 作者:SunnieShine https://www.bilibili.com/read/cv11140920 出处:bilibili

若有收获,就点个赞吧
0 人点赞
