需求来源
朋友家物业需要收集小区人员的核酸证明图片,大致流程如下:
- 一个excel表格,里面存储的是人员的姓名和身份证号
- 在查询网站上输入人员的姓名及身份证号
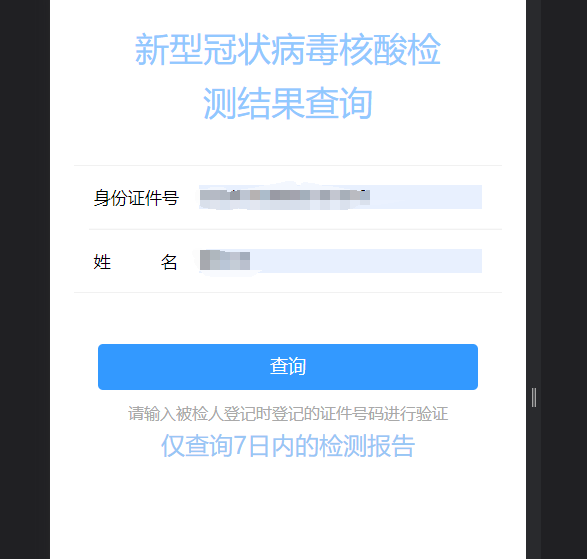
- 进入报告总览界面,获取第一条核酸证明记录
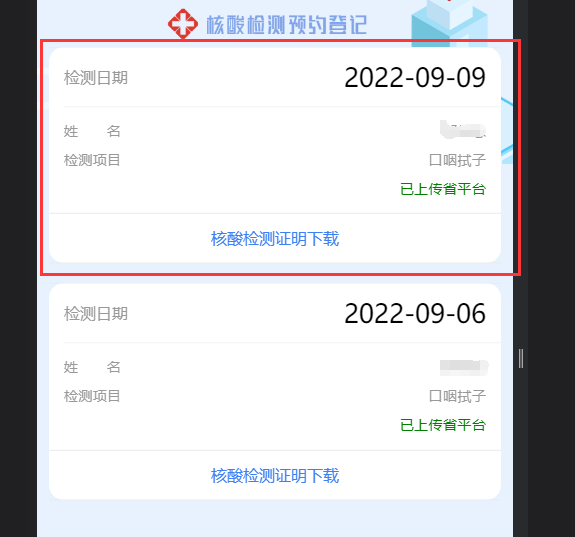
- 下载里面的核酸证明

需求分析
- 读取excel,获取人员信息并转成数组
- 需要做一个类似登录的验证,获取cookie,后面携带cookie获取信息。
- 界面html解析,获取第一条a标签的地址
- 正则表达式,将查看的地址中的report转换为down即可生成图片资源的连接
pandas.read_excel:解析excelurllib:网络请求http.cookiejar:存储cookieBeautifulSoup:解析htmlrequests:获取链接中的图片资源
读取excel
```python import pandas as pd
def get_excel_data():
# 读取excel第2列和第3列的信息name_id = pd.read_excel("data.xlsx", usecols=[1, 2], header=0)# 将读取成功的信息转换为数组格式lists = name_id.values.tolist()result = []# 以姓名、id的对象形式存入结果集for person_list in lists:result.append({"name": person_list[0],"id": person_list[1]})return result
<a name="frmPs"></a>### 登录(验证)并存储cookie```pythonimport urllib.requestimport urllib.parseimport http.cookiejardef login(name, idcard):form_data = {'IDCard': idcard, 'xm': name}# 将对象格式转换为urlencode格式postdata = urllib.parse.urlencode(form_data).encode()# 创建请求体request = urllib.request.Request('验证身份的api', postdata)# 发送请求response = opener.open(request)# 存储cookiefor item in cookiejar:Cookie = '%s=%s' % (item.name, item.value)# 将cookie放入全局的请求头中headers['Cookie'] = Cookie
携带cookie访问报告总览界面
这一步主要进行两个操作:
- 获取界面html
- 解析界面html并找到第一个a标签中的href属性值
def to_my_report():# 进入网页request = urllib.request.Request('界面的地址')# 获取网页源码response = opener.open(request)# 解析网页htmlsoup = BeautifulSoup(response.read(), 'lxml')# 返回第一个a标前的href属性值return soup.a.attrs['href']
下载图片链接中的图片资源
```python import requests
def get_photo(img_url, file_name):
# 请求资源链接r = requests.get(img_url, headers=headers, stream=True)if r.status_code == 200:# 调用open将资源流存入文件夹with open('./photo/' + file_name + '.jpg', 'wb') as f:f.write(r.content)return Trueelse:return False
<a name="pjjdL"></a>### 整合以上方法```pythonif __name__ == '__main__':# 记录下载的结果count = 0count_fail = 0count_un_res = 0download_fail_person = []un_res_person = []# 获取人员信息数组person_list = get_excel_data()try:# 遍历人员信息for data in person_list:# 获取cookielogin(data['name'], data['id'])# 拿到带guid的href链接href = to_my_report()print("正在下载{}".format(data))# 如果是javascript:void(0)则说明核酸结果未出if href == 'javascript:void(0)':count_un_res += 1un_res_person.append(data)else:# 若结果已出则将链接中的report通过replace换为down(即图片资源链接)if get_photo(base_url + href.replace('report', 'down'), data['name']):count += 1else:count_fail += 1download_fail_person.append(data)except Exception as err:print('下载中断,请检查网络后重试')finally:print('已下载:', count)print('未出结果:', count_un_res)print('下载失败:', count_fail)print('共计:', count + count_un_res + count_fail)print('未出结果人员名单:', un_res_person)print('下载失败人员名单:', download_fail_person)input("按任意键退出:")
小结
两小时就搞完的东西真的不好意思收别人钱哈哈哈哈哈,朋友的舅舅非要给,小赚100💸

若有收获,就点个赞吧
0 人点赞
