基本思想
布隆过滤器的结构主要由BitMap和k个hash函数组成,其实现思想为:
- 插入:将一个插入的元素使用k个hash函数进行k次运算,将得到的hash值对应BitMap中对应的bit置为1
- 查找:将要查找的元素使用k个hash函数进行k次运算,将得到的hash值对应BitMap中对应的bit,如果所有的对应的bit都为1,则说明可能存在,只要有0,则肯定不存在
- 删除:不支持删除
优点
相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器不需要存储key,存储空间和插入、查询复杂度都是O(1)。另外布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
缺点
但是布隆过滤器的缺点和优点一样明显。误算率是其中之一。随着存入的元素数量增加,误算率随之增加。另外,一般情况下不能从布隆过滤器中删除元素.。删除某一个元素时,如果别的元素通过某个hash函数算出来的结果也落在了被删除元素相同的bit上,则会造成误删现象。
例如数据库中有三条记录,分别为 iPhone手机(id=5)、小米手机(id=10)、华为手机(id=12),经过3次hash计算,落在了其对应的bit上,如图
此时用户要查找一台诺基亚手机(id=18),经过3次hash计算,发现对应偏移量为13的bit对应的值为0,则说明诺基亚手机肯定不存在。如果此时用户要查找一台魅族手机(id=20),该手机不在数据库上,但其计算的hash值都落在了bit为1的位置上,这就导致了误判。
/** @Author 松岛安* */public class BloomFilter {int size;BitSet bits; // bit数组,bitMap long /64public BloomFilter(int size) {this.size = size;bits = new BitSet(size);}public void add(String key) { //O(1)int hash1 = hash_1(key);int hash2 = hash_2(key);int hash3 = hash_3(key);bits.set(hash1, true);bits.set(hash2, true);bits.set(hash3, true);}public boolean isExit(String key) {int hash1 = hash_1(key);if (!bits.get(hash1))return false;int hash2 = hash_2(key);if (!bits.get(hash2))return false;int hash3 = hash_3(key);if (!bits.get(hash3))return false;return true;}public int hash_1(String key) {int hash = 0;int i;for (i = 0; i < key.length(); ++i) {hash = 33 * hash + key.charAt(i);}return Math.abs(hash) % size;}public int hash_2(String key) {final int p = 16777619;int hash = (int) 2166136261L;for (int i = 0; i < key.length(); i++) {hash = (hash ^ key.charAt(i)) * p;}hash += hash << 13;hash ^= hash >> 7;hash += hash << 3;hash ^= hash >> 17;hash += hash << 5;return Math.abs(hash) % size;}public int hash_3(String key) {int hash, i;for (hash = 0, i = 0; i < key.length(); ++i) {hash += key.charAt(i);hash += (hash << 10);hash ^= (hash >> 6);}hash += (hash << 3);hash ^= (hash >> 11);hash += (hash << 15);return Math.abs(hash) % size;}}
误判率推导
布隆过滤器的关键在于误判率的大小,通常情况下要求要小于 “0.1%” ,这与我们的BitMap的长度和hash函数的个数有关。假设BitMap的长度为m,hash函数的个数为k
在一次hash运算中,某个位置上的bit被置为1的概率为 1/m,反之,为0的概率为
k次运算后该bit还是为0的概率为
如果插入了n个元素,该位置的bit还是为0的概率为
如果插入了n个元素,该位置的bit为1的概率为
若某一个元素存在,则其对应的k个位置的bit都为1的概率为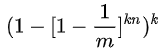
但是该方法可能会错误的认为某一原本不在集合中的元素却被检测为在该集合中,所以误判率为(某个元素不存在,但你告诉我其存在的概率为这么大)
具体推导请参考 Bloom Filter - the math
当我们指定了误判率p之后,就可以确定m和k之间的关系
hash函数的个数为

BitMap的长度为

若有收获,就点个赞吧
0 人点赞
