
根据命名空间判断,默认为:BEANS_NAMESPACE_URI = “http://www.springframework.org/schema/beans“
如果是默认的命名空间的话,就会进入 DefaultBeanDefinitionDocumentReader # parseDefaultElement(ele, delegate);
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {// import 解析importBeanDefinitionResource(ele);} else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {// alias 解析processAliasRegistration(ele);} else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {// bean 解析processBeanDefinition(ele, delegate);} else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {// 如果是嵌套的beans标签,进行递归// recursedoRegisterBeanDefinitions(ele);}}
bean 标签解析及注册
org.springframework.beans.factory.xml.DefaultBeanDefinitionDocumentReader#processBeanDefinition
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);if (bdHolder != null) {// 解析自定义标签bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);try {// Register the final decorated instance.// 注册BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());} catch (BeanDefinitionStoreException ex) {getReaderContext().error("Failed to register bean definition with name '" +bdHolder.getBeanName() + "'", ele, ex);}// Send registration event.getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));}}
bean 标签是最常用,也是最复杂的一个标签。了解该标签如何实现,那么其他的标签就迎刃而解了。
- 首先由 BeanDefinitionParserDelegate 解析得到 BeanDefinitionHolder 实例,其拿到了例如 className、 id、alias 等属性;
- 如果有自定义的属性,需要进一步解析下;
- 解析完毕后利用 BeanDefinitionReaderUtils 进行 bean 的注册;
-
解析 BeanDefinition
首先从第一步:BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele); 解析BeanDefinition 开始。(parseBeanDefinitionElement(ele, null); 方法第二个参数为 null 表示该结点没有父节点。)
@Nullablepublic BeanDefinitionHolder parseBeanDefinitionElement(Element ele) {return parseBeanDefinitionElement(ele, null);}
@Nullablepublic BeanDefinitionHolder parseBeanDefinitionElement(Element ele, @Nullable BeanDefinition containingBean) {// bean idString id = ele.getAttribute(ID_ATTRIBUTE);// bean 名称String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);// bean 的别名List<String> aliases = new ArrayList<>();// name可能有多个,通过,;或者空格隔开的if (StringUtils.hasLength(nameAttr)) {String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);aliases.addAll(Arrays.asList(nameArr));}// 判断下没有ID就拿第一个名称作为IDString beanName = id;if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {beanName = aliases.remove(0);if (logger.isTraceEnabled()) {logger.trace("No XML 'id' specified - using '" + beanName +"' as bean name and " + aliases + " as aliases");}}// 判断bean的名称和别名是否重复if (containingBean == null) {checkNameUniqueness(beanName, aliases, ele);}// 解析 bean 元素到 BeanDefinitionAbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);if (beanDefinition != null) {if (!StringUtils.hasText(beanName)) {try {if (containingBean != null) {// 根据Spring的命名规则给bean设置一个名字beanName = BeanDefinitionReaderUtils.generateBeanName(beanDefinition, this.readerContext.getRegistry(), true);} else {beanName = this.readerContext.generateBeanName(beanDefinition);// Register an alias for the plain bean class name, if still possible,// if the generator returned the class name plus a suffix.// This is expected for Spring 1.2/2.0 backwards compatibility.String beanClassName = beanDefinition.getBeanClassName();if (beanClassName != null&& beanName.startsWith(beanClassName)&& beanName.length() > beanClassName.length()&& !this.readerContext.getRegistry().isBeanNameInUse(beanClassName)) {aliases.add(beanClassName);}}if (logger.isTraceEnabled()) {logger.trace("Neither XML 'id' nor 'name' specified - " +"using generated bean name [" + beanName + "]");}} catch (Exception ex) {error(ex.getMessage(), ele);return null;}}String[] aliasesArray = StringUtils.toStringArray(aliases);return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);}return null;}
整体处理过程:
- 依次得到结点的 id、name、alias;
- 进一步解析其他属性到 GenericBeanDefinition 中;
- 如果 bean 还没有 beanName 那么就根据默认规则生成一个名字;
- 最后将解析得到信息封装到 BeanDefinitionHolder 对象中。
那么接下来需要看第2步中,如何进一步解析的?
public AbstractBeanDefinition parseBeanDefinitionElement(Element ele, String beanName, @Nullable BeanDefinition containingBean) {// 缓存beanthis.parseState.push(new BeanEntry(beanName));// 解析class属性String className = null;if (ele.hasAttribute(CLASS_ATTRIBUTE)) {className = ele.getAttribute(CLASS_ATTRIBUTE).trim();}// 解析parent属性String parent = null;if (ele.hasAttribute(PARENT_ATTRIBUTE)) {parent = ele.getAttribute(PARENT_ATTRIBUTE);}try {// 创建 GenericBeanDefinition 用来装载属性AbstractBeanDefinition bd = createBeanDefinition(className, parent);// 解析各种属性parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));// 解析元数据parseMetaElements(ele, bd);// 解析 lookup-method 属性parseLookupOverrideSubElements(ele, bd.getMethodOverrides());// 解析 replaced-method 属性parseReplacedMethodSubElements(ele, bd.getMethodOverrides());// 解析构造函数parseConstructorArgElements(ele, bd);// 解析property子元素parsePropertyElements(ele, bd);// 解析qualifier子元素parseQualifierElements(ele, bd);bd.setResource(this.readerContext.getResource());bd.setSource(extractSource(ele));return bd;} catch (ClassNotFoundException ex) {error("Bean class [" + className + "] not found", ele, ex);} catch (NoClassDefFoundError err) {error("Class that bean class [" + className + "] depends on not found", ele, err);} catch (Throwable ex) {error("Unexpected failure during bean definition parsing", ele, ex);} finally {this.parseState.pop();}return null;}
可以看出,依次解析了class 属性、parent 属性、其他常用属性、元数据、构造器、property子元素、qualifier子元素,那么基本所有的标签都解析完毕了。那么接下来依次来看是如何解析的。
新建属性容器 BeanDefinition
解析的时候创 GenericBeanDefinition 来装载相关的属性,还有其他的实现类如下: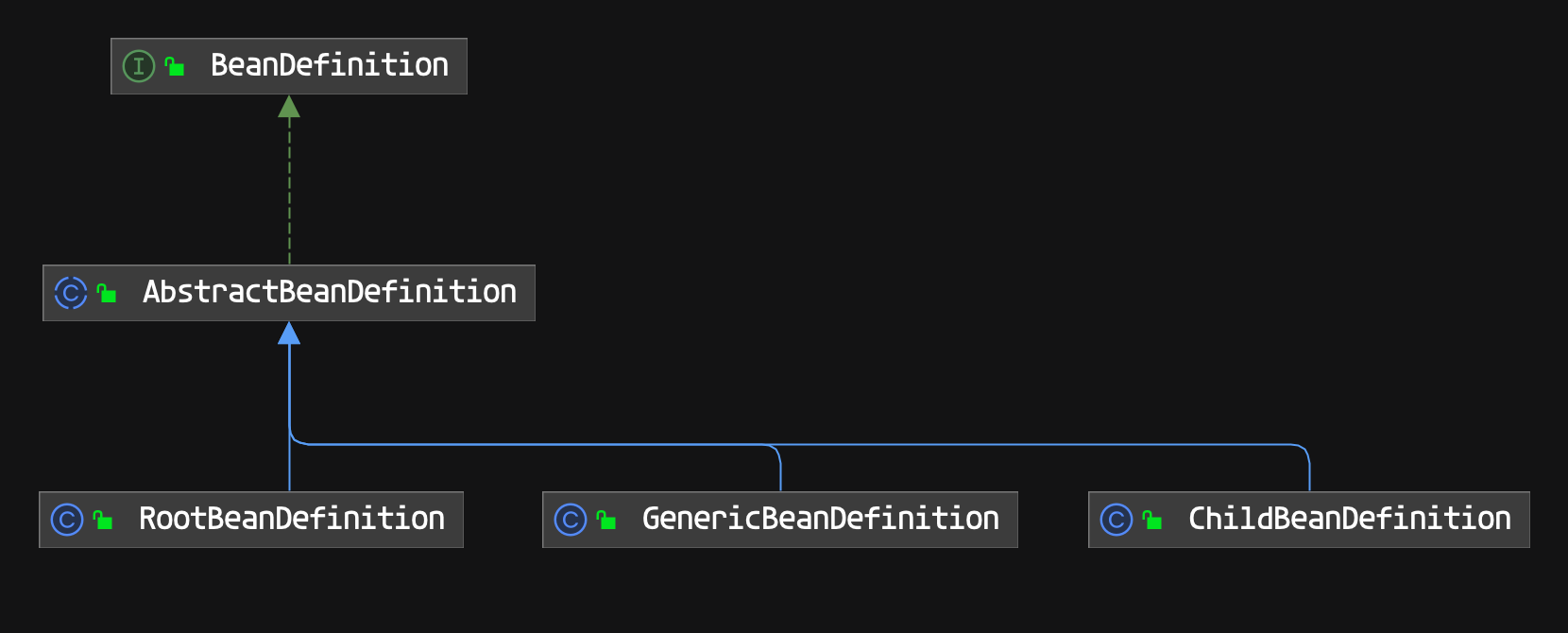
BeanDefinition 是一个接口,在 Spring 中存在三种实现:RootBeanDefinition、 ChildBeanDefinition 以及 GenericBeanDefinition。三种实现均继承了 AbstractBeanDefiniton,其中 BeanDefinition 是配置文件
创建 GenericBeanDefinition 方法是委托 BeanDefinitionReaderUtils#createBeanDefinition 来实现。
protected AbstractBeanDefinition createBeanDefinition(@Nullable String className, @Nullable String parentName)throws ClassNotFoundException {return BeanDefinitionReaderUtils.createBeanDefinition(parentName, className, this.readerContext.getBeanClassLoader());}
public static AbstractBeanDefinition createBeanDefinition(@Nullable String parentName, @Nullable String className, @Nullable ClassLoader classLoader)throws ClassNotFoundException {GenericBeanDefinition bd = new GenericBeanDefinition();bd.setParentName(parentName);if (className != null) {if (classLoader != null) {bd.setBeanClass(ClassUtils.forName(className, classLoader));}else {bd.setBeanClassName(className);}}return bd;}
解析各种属性
org.springframework.beans.factory.xml.BeanDefinitionParserDelegate#parseBeanDefinitionAttributes
public AbstractBeanDefinition parseBeanDefinitionAttributes(Element ele, String beanName,@Nullable BeanDefinition containingBean, AbstractBeanDefinition bd) {// 解析 scope 属性if (ele.hasAttribute(SINGLETON_ATTRIBUTE)) {error("Old 1.x 'singleton' attribute in use - upgrade to 'scope' declaration", ele);} else if (ele.hasAttribute(SCOPE_ATTRIBUTE)) {bd.setScope(ele.getAttribute(SCOPE_ATTRIBUTE));} else if (containingBean != null) {// Take default from containing bean in case of an inner bean definition.bd.setScope(containingBean.getScope());}// 解析 abstract 属性if (ele.hasAttribute(ABSTRACT_ATTRIBUTE)) {bd.setAbstract(TRUE_VALUE.equals(ele.getAttribute(ABSTRACT_ATTRIBUTE)));}// 解析 lazy-init 属性String lazyInit = ele.getAttribute(LAZY_INIT_ATTRIBUTE);if (isDefaultValue(lazyInit)) {lazyInit = this.defaults.getLazyInit();}bd.setLazyInit(TRUE_VALUE.equals(lazyInit));// 解析 autowire 属性String autowire = ele.getAttribute(AUTOWIRE_ATTRIBUTE);bd.setAutowireMode(getAutowireMode(autowire));// 解析 depends-on 属性if (ele.hasAttribute(DEPENDS_ON_ATTRIBUTE)) {String dependsOn = ele.getAttribute(DEPENDS_ON_ATTRIBUTE);bd.setDependsOn(StringUtils.tokenizeToStringArray(dependsOn, MULTI_VALUE_ATTRIBUTE_DELIMITERS));}// 解析 autowire-candidate 属性String autowireCandidate = ele.getAttribute(AUTOWIRE_CANDIDATE_ATTRIBUTE);if (isDefaultValue(autowireCandidate)) {String candidatePattern = this.defaults.getAutowireCandidates();if (candidatePattern != null) {String[] patterns = StringUtils.commaDelimitedListToStringArray(candidatePattern);bd.setAutowireCandidate(PatternMatchUtils.simpleMatch(patterns, beanName));}} else {bd.setAutowireCandidate(TRUE_VALUE.equals(autowireCandidate));}// 解析 primary 属性if (ele.hasAttribute(PRIMARY_ATTRIBUTE)) {bd.setPrimary(TRUE_VALUE.equals(ele.getAttribute(PRIMARY_ATTRIBUTE)));}// 解析 init-method 属性if (ele.hasAttribute(INIT_METHOD_ATTRIBUTE)) {String initMethodName = ele.getAttribute(INIT_METHOD_ATTRIBUTE);bd.setInitMethodName(initMethodName);} else if (this.defaults.getInitMethod() != null) {bd.setInitMethodName(this.defaults.getInitMethod());bd.setEnforceInitMethod(false);}// 解析 destroy-method 属性if (ele.hasAttribute(DESTROY_METHOD_ATTRIBUTE)) {String destroyMethodName = ele.getAttribute(DESTROY_METHOD_ATTRIBUTE);bd.setDestroyMethodName(destroyMethodName);} else if (this.defaults.getDestroyMethod() != null) {bd.setDestroyMethodName(this.defaults.getDestroyMethod());bd.setEnforceDestroyMethod(false);}// 解析 factory-method 属性if (ele.hasAttribute(FACTORY_METHOD_ATTRIBUTE)) {bd.setFactoryMethodName(ele.getAttribute(FACTORY_METHOD_ATTRIBUTE));}// 解析 factory-bean 属性if (ele.hasAttribute(FACTORY_BEAN_ATTRIBUTE)) {bd.setFactoryBeanName(ele.getAttribute(FACTORY_BEAN_ATTRIBUTE));}return bd;}
这里解析了bean上所有能出现的属性。
解析 meta 标签
<bean id="aa" class="cn.xxx.Abean"><meta key="mykey" value= "hello" /></bean>
这是一个额外的声明,当需要使用里的信息的时候可以通过 BeanDefinition 的 getAttribute(key)方法进行获取。但它并不会注册进bean的属性容器中,只是在解析的时候可以使用它。
解析方法如下:
public void parseMetaElements(Element ele, BeanMetadataAttributeAccessor attributeAccessor) {NodeList nl = ele.getChildNodes();for (int i = 0; i < nl.getLength(); i++) {Node node = nl.item(i);if (isCandidateElement(node) && nodeNameEquals(node, META_ELEMENT)) {Element metaElement = (Element) node;String key = metaElement.getAttribute(KEY_ATTRIBUTE);String value = metaElement.getAttribute(VALUE_ATTRIBUTE);BeanMetadataAttribute attribute = new BeanMetadataAttribute(key, value);attribute.setSource(extractSource(metaElement));attributeAccessor.addMetadataAttribute(attribute);}}}
解析 lookup-method
获取器注入,它并非常用。如下代码:
public abstract class GetBeanTestpublic void showMe(){this.getBean().showMe ()}public abstract User getBean ()}
<bean id="getBeanTest"class="test.lookup.app.GetBeanTest"><lookup-method name="getBean" bean="teacher"/></bean>
它的作用:动态的将 teacher 所代表的 bean 作为 getBean 的返回值。
其解析方法:
public void parseLookupOverrideSubElements(Element beanEle, MethodOverrides overrides) {NodeList nl = beanEle.getChildNodes();for (int i = 0; i < nl.getLength(); i++) {Node node = nl.item(i);if (isCandidateElement(node) && nodeNameEquals(node, LOOKUP_METHOD_ELEMENT)) {Element ele = (Element) node;String methodName = ele.getAttribute(NAME_ATTRIBUTE);String beanRef = ele.getAttribute(BEAN_ELEMENT);LookupOverride override = new LookupOverride(methodName, beanRef);override.setSource(extractSource(ele));overrides.addOverride(override);}}}
解析 replaced-method
方法替换:可以在运行时用新的方法替换现有的方法。与之前的 look-up 不同的是,replaced-method 不但可以动态地替换返回实体bean,而且还能动态地更改原有方法的逻辑。
首先测试使用
测试 bean,用于业务需要去替换OrgMethod的change方法。
public class OrgMethod {public void change() {System.out.println("change!");}}public class OrgMethodReplace implements MethodReplacer {@Overridepublic Object reimplement(Object obj, Method method, Object[] args) throws Throwable {System.out.println("change replaced!");return null;}}
xml 注册bean
<?xml version="1.0" encoding="UTF-8"?><beansxmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd"><bean id="orgMethod" class="cn.lichenghao.replacedmethod.OrgMethod"><replaced-method name="change" replacer="orgMethodReplace"/></bean><bean id="orgMethodReplace" class="cn.lichenghao.replacedmethod.OrgMethodReplace"/></beans>
测试
@DisplayName("测试 replaced-method")@Testpublic void replaceMethodTest() {ClassPathXmlApplicationContext context= new ClassPathXmlApplicationContext("replacemethod.xml");OrgMethod orgMethod = context.getBean(OrgMethod.class);orgMethod.change();}// 结果change replaced!
看下解析的源码
public void parseReplacedMethodSubElements(Element beanEle, MethodOverrides overrides) {NodeList nl = beanEle.getChildNodes();for (int i = 0; i < nl.getLength(); i++) {Node node = nl.item(i);// 仅 bean 标签下的 replaced-method 有效if (isCandidateElement(node) && nodeNameEquals(node, REPLACED_METHOD_ELEMENT)) {Element replacedMethodEle = (Element) node;// 原始方法String name = replacedMethodEle.getAttribute(NAME_ATTRIBUTE);// 替换的方法String callback = replacedMethodEle.getAttribute(REPLACER_ATTRIBUTE);// 记录到 ReplaceOverride 中ReplaceOverride replaceOverride = new ReplaceOverride(name, callback);// Look for arg-type match elements.// 记录参数List<Element> argTypeEles = DomUtils.getChildElementsByTagName(replacedMethodEle, ARG_TYPE_ELEMENT);for (Element argTypeEle : argTypeEles) {String match = argTypeEle.getAttribute(ARG_TYPE_MATCH_ATTRIBUTE);match = (StringUtils.hasText(match) ? match : DomUtils.getTextValue(argTypeEle));if (StringUtils.hasText(match)) {replaceOverride.addTypeIdentifier(match);}}replaceOverride.setSource(extractSource(replacedMethodEle));overrides.addOverride(replaceOverride);}}}
解析 constructor-arg 标签
构造函数是及其重要的,解析也是相对较复杂的。
比如:
<bean id="user" class="cn.com.lichenghao.model.User"><constructor-arg index="0" value="张无忌"></constructor-arg></bean>
对于构造函数的解析,交给了方法 parseConstructorArgElement((Element) node, bd);
public void parseConstructorArgElements(Element beanEle, BeanDefinition bd) {NodeList nl = beanEle.getChildNodes();for (int i = 0; i < nl.getLength(); i++) {Node node = nl.item(i);if (isCandidateElement(node) && nodeNameEquals(node, CONSTRUCTOR_ARG_ELEMENT)) {parseConstructorArgElement((Element) node, bd);}}}
public void parseConstructorArgElement(Element ele, BeanDefinition bd) {// 属性索引String indexAttr = ele.getAttribute(INDEX_ATTRIBUTE);// 属性类型String typeAttr = ele.getAttribute(TYPE_ATTRIBUTE);// 属性名称String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);if (StringUtils.hasLength(indexAttr)) {try {int index = Integer.parseInt(indexAttr);if (index < 0) {error("'index' cannot be lower than 0", ele);} else {try {this.parseState.push(new ConstructorArgumentEntry(index));// 解析得到值Object value = parsePropertyValue(ele, bd, null);// 得到的值交给 valueHolderConstructorArgumentValues.ValueHolder valueHolder = new ConstructorArgumentValues.ValueHolder(value);if (StringUtils.hasLength(typeAttr)) {valueHolder.setType(typeAttr);}if (StringUtils.hasLength(nameAttr)) {valueHolder.setName(nameAttr);}valueHolder.setSource(extractSource(ele));// 判断重复指定相同参数if (bd.getConstructorArgumentValues().hasIndexedArgumentValue(index)) {error("Ambiguous constructor-arg entries for index " + index, ele);} else {bd.getConstructorArgumentValues().addIndexedArgumentValue(index, valueHolder);}} finally {this.parseState.pop();}}} catch (NumberFormatException ex) {error("Attribute 'index' of tag 'constructor-arg' must be an integer", ele);}} else {// 如果没有 indextry {this.parseState.push(new ConstructorArgumentEntry());Object value = parsePropertyValue(ele, bd, null);ConstructorArgumentValues.ValueHolder valueHolder = new ConstructorArgumentValues.ValueHolder(value);if (StringUtils.hasLength(typeAttr)) {valueHolder.setType(typeAttr);}if (StringUtils.hasLength(nameAttr)) {valueHolder.setName(nameAttr);}valueHolder.setSource(extractSource(ele));bd.getConstructorArgumentValues().addGenericArgumentValue(valueHolder);} finally {this.parseState.pop();}}}
整体过程: 首先得到属性索引、类型、名称; 分支1:设置了 index 属性
- 解析 constructor-arg 子元素(比如:value);
- 结果放到 ConstructorArgumentValues.ValueHolder,并设置参数类型和名称;
- 判断是否重复设置了参数。
- ValueHolder 添加至当前 BeanDefinition 的 constructorArgumentValues 的 indexedArgumentValues 属性中。
分支2:没有设置 index 属性
- 解析 constructor-arg 子元素;
- 结果放到 ConstructorArgumentValues.ValueHolder,并设置参数类型和名称;
- ValueHolder 添加至当前 BeanDefinition 的 constructorArgumentValues 的 genericArgumentValues 属性中。
所以不管有无index操作都是一样的,但是最终存放的地方是不同的。
那么再看下是如何解析子属性的?
@Nullablepublic Object parsePropertyValue(Element ele, BeanDefinition bd, @Nullable String propertyName) {String elementName = (propertyName != null ?"<property> element for property '" + propertyName + "'" :"<constructor-arg> element");// Should only have one child element: ref, value, list, etc.// 每个标签只能有一个子标签类型NodeList nl = ele.getChildNodes();Element subElement = null;for (int i = 0; i < nl.getLength(); i++) {Node node = nl.item(i);// description 和 meta 不处理if (node instanceof Element&& !nodeNameEquals(node, DESCRIPTION_ELEMENT)&& !nodeNameEquals(node, META_ELEMENT)) {// Child element is what we're looking for.if (subElement != null) {error(elementName + " must not contain more than one sub-element", ele);} else {subElement = (Element) node;}}}// 不能同时用 ref 和 value 属性boolean hasRefAttribute = ele.hasAttribute(REF_ATTRIBUTE);boolean hasValueAttribute = ele.hasAttribute(VALUE_ATTRIBUTE);if ((hasRefAttribute && hasValueAttribute) ||((hasRefAttribute || hasValueAttribute) && subElement != null)) {error(elementName +" is only allowed to contain either 'ref' attribute OR 'value' attribute OR sub-element", ele);}if (hasRefAttribute) {// ref属性的处理,使用RuntimeBeanReference封装对应的ref名称String refName = ele.getAttribute(REF_ATTRIBUTE);if (!StringUtils.hasText(refName)) {error(elementName + " contains empty 'ref' attribute", ele);}RuntimeBeanReference ref = new RuntimeBeanReference(refName);ref.setSource(extractSource(ele));return ref;} else if (hasValueAttribute) {// value属性的处理,使用TypedstringValue封装TypedStringValue valueHolder = new TypedStringValue(ele.getAttribute(VALUE_ATTRIBUTE));valueHolder.setSource(extractSource(ele));return valueHolder;} else if (subElement != null) {// 解析子元素return parsePropertySubElement(subElement, bd);} else {// Neither child element nor "ref" or "value" attribute found.// 既没有ref也没有value也没有子元素error(elementName + " must specify a ref or value", ele);return null;}}
- 首先忽略子标签 description、meta;
- 提取 constructor-arg 上的 ref 和 value 属性,为了保证以下情况不可以发生:
- 既有 ref 属性又有 value 属性。只能有其中一个!
- 有 ref 或者 value ,还有子元素。已经指定了,不需要子元素指定了!
- ref 属性使用 RuntimeBeanReference 封装。
; - value 属性通过 TypedStringValue 处理;
- 解析子元素:
<constructor-arg><map><entry key="key"value="value"/></map></constructor-arg>
对于子元素的解析,交给方法 parsePropertySubElement
@Nullablepublic Object parsePropertySubElement(Element ele, @Nullable BeanDefinition bd) {return parsePropertySubElement(ele, bd, null);}
@Nullablepublic Object parsePropertySubElement(Element ele, @Nullable BeanDefinition bd, @Nullable String defaultValueType) {if (!isDefaultNamespace(ele)) {return parseNestedCustomElement(ele, bd);} else if (nodeNameEquals(ele, BEAN_ELEMENT)) {BeanDefinitionHolder nestedBd = parseBeanDefinitionElement(ele, bd);if (nestedBd != null) {nestedBd = decorateBeanDefinitionIfRequired(ele, nestedBd, bd);}return nestedBd;} else if (nodeNameEquals(ele, REF_ELEMENT)) {// A generic reference to any name of any bean.String refName = ele.getAttribute(BEAN_REF_ATTRIBUTE);boolean toParent = false;if (!StringUtils.hasLength(refName)) {// A reference to the id of another bean in a parent context.refName = ele.getAttribute(PARENT_REF_ATTRIBUTE);toParent = true;if (!StringUtils.hasLength(refName)) {error("'bean' or 'parent' is required for <ref> element", ele);return null;}}if (!StringUtils.hasText(refName)) {error("<ref> element contains empty target attribute", ele);return null;}RuntimeBeanReference ref = new RuntimeBeanReference(refName, toParent);ref.setSource(extractSource(ele));return ref;} else if (nodeNameEquals(ele, IDREF_ELEMENT)) {return parseIdRefElement(ele);} else if (nodeNameEquals(ele, VALUE_ELEMENT)) {return parseValueElement(ele, defaultValueType);} else if (nodeNameEquals(ele, NULL_ELEMENT)) {// It's a distinguished null value. Let's wrap it in a TypedStringValue// object in order to preserve the source location.TypedStringValue nullHolder = new TypedStringValue(null);nullHolder.setSource(extractSource(ele));return nullHolder;} else if (nodeNameEquals(ele, ARRAY_ELEMENT)) {return parseArrayElement(ele, bd);} else if (nodeNameEquals(ele, LIST_ELEMENT)) {return parseListElement(ele, bd);} else if (nodeNameEquals(ele, SET_ELEMENT)) {return parseSetElement(ele, bd);} else if (nodeNameEquals(ele, MAP_ELEMENT)) {return parseMapElement(ele, bd);} else if (nodeNameEquals(ele, PROPS_ELEMENT)) {return parsePropsElement(ele);} else {error("Unknown property sub-element: [" + ele.getNodeName() + "]", ele);return null;}}
解析 property 标签
完成对 property 属性的解析
<bean id="user" class="cn.com.lichenghao.model.User"><property name="userName" value="张无忌"></property></bean>或者<bean id="user" class="cn.com.lichenghao.model.User"><property name="strings"><array><value>1</value><value>2</value></array></property></bean>
同样是找到所有的 property 标签,交给 parsePropertyElement 方法去解析
public void parsePropertyElements(Element beanEle, BeanDefinition bd) {NodeList nl = beanEle.getChildNodes();for (int i = 0; i < nl.getLength(); i++) {Node node = nl.item(i);if (isCandidateElement(node) && nodeNameEquals(node, PROPERTY_ELEMENT)) {parsePropertyElement((Element) node, bd);}}}
public void parsePropertyElement(Element ele, BeanDefinition bd) {String propertyName = ele.getAttribute(NAME_ATTRIBUTE);if (!StringUtils.hasLength(propertyName)) {error("Tag 'property' must have a 'name' attribute", ele);return;}this.parseState.push(new PropertyEntry(propertyName));try {if (bd.getPropertyValues().contains(propertyName)) {error("Multiple 'property' definitions for property '" + propertyName + "'", ele);return;}Object val = parsePropertyValue(ele, bd, propertyName);PropertyValue pv = new PropertyValue(propertyName, val);parseMetaElements(ele, pv);pv.setSource(extractSource(ele));bd.getPropertyValues().addPropertyValue(pv);} finally {this.parseState.pop();}}
处理的套路和上边其他标签处理方式类似:
- 判断名称是否为空;
- 判断属性重复;
- 解析结果交给 PropertyValue;
设置到 BeanDefinition中的 propertyValues属性中。
解析 qualifier 标签
完成对 qulifier 标签的解析,这个标签的作用和使用注解的作用一样,通常我们更多使用的是注解。
<bean id="myTestBean"class="bean.MyTestBean"><qualifier type="org.Springframework.beans.factory.annotation.Qualifier" value="qf"/></bean>
找到这个标签,挨个处理。
public void parseQualifierElements(Element beanEle, AbstractBeanDefinition bd) {NodeList nl = beanEle.getChildNodes();for (int i = 0; i < nl.getLength(); i++) {Node node = nl.item(i);if (isCandidateElement(node) && nodeNameEquals(node, QUALIFIER_ELEMENT)) {parseQualifierElement((Element) node, bd);}}}
public void parseQualifierElement(Element ele, AbstractBeanDefinition bd) {String typeName = ele.getAttribute(TYPE_ATTRIBUTE);if (!StringUtils.hasLength(typeName)) {error("Tag 'qualifier' must have a 'type' attribute", ele);return;}this.parseState.push(new QualifierEntry(typeName));try {AutowireCandidateQualifier qualifier = new AutowireCandidateQualifier(typeName);qualifier.setSource(extractSource(ele));String value = ele.getAttribute(VALUE_ATTRIBUTE);if (StringUtils.hasLength(value)) {qualifier.setAttribute(AutowireCandidateQualifier.VALUE_KEY, value);}NodeList nl = ele.getChildNodes();for (int i = 0; i < nl.getLength(); i++) {Node node = nl.item(i);if (isCandidateElement(node) && nodeNameEquals(node, QUALIFIER_ATTRIBUTE_ELEMENT)) {Element attributeEle = (Element) node;String attributeName = attributeEle.getAttribute(KEY_ATTRIBUTE);String attributeValue = attributeEle.getAttribute(VALUE_ATTRIBUTE);if (StringUtils.hasLength(attributeName) && StringUtils.hasLength(attributeValue)) {BeanMetadataAttribute attribute = new BeanMetadataAttribute(attributeName, attributeValue);attribute.setSource(extractSource(attributeEle));qualifier.addMetadataAttribute(attribute);} else {error("Qualifier 'attribute' tag must have a 'name' and 'value'", attributeEle);return;}}}bd.addQualifier(qualifier);} finally {this.parseState.pop();}}
解析结果
完成了上面各种标签的解析,也就把 xml 配置的 bean 转变成了 GenericBeanDefinition。
它是 AbstractBeanDefinition 的子类,大部分属性保存在这里。
到这里完成了bean 标签解析及注册的第1步:首先由 BeanDefinitionParserDelegate 解析得到 BeanDefinitionHolder 实例,其拿到了例如 className、 id、alias 等属性;
- 如果有自定义的属性,需要进一步解析下;
- 解析完毕后利用 BeanDefinitionReaderUtils 进行 bean 的注册;
- 最后发出通告,告诉相关的监听器,bean 已经加载完毕。
解析默认标签中的自定义标签
完成了上一步后,接下来看如何解析默认标签中的自定义标签?
首先来看下,使用自定义标签的配置是什么样的,如下所示:<bean id="test" class="test.Myclass"><mybean:user username="aaa"/></bean>
这里完成了 bean 标签解析及注册的前2步:
- 首先由 BeanDefinitionParserDelegate 解析得到 BeanDefinitionHolder 实例,其拿到了例如 className、 id、alias 等属性;
- 如果有自定义的属性,需要进一步解析下;
- 解析完毕后利用 BeanDefinitionReaderUtils 进行 bean 的注册;
-
注册 BeanDefinition
解析完毕后,开始注册 BeanDefinition。可以看出来,分别通过名称、别名来注册。
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
org.springframework.beans.factory.support.BeanDefinitionReaderUtils#registerBeanDefinition
public static void registerBeanDefinition(BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)throws BeanDefinitionStoreException {// Register bean definition under primary name.String beanName = definitionHolder.getBeanName();registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());// Register aliases for bean name, if any.String[] aliases = definitionHolder.getAliases();if (aliases != null) {for (String alias : aliases) {registry.registerAlias(beanName, alias);}}}
通过 beanName 注册
首先获得 beanName ,然后开始注册
@Overridepublic void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)throws BeanDefinitionStoreException {// 非空校验Assert.hasText(beanName, "Bean name must not be empty");Assert.notNull(beanDefinition, "BeanDefinition must not be null");// BeanDefinition 有效性校验if (beanDefinition instanceof AbstractBeanDefinition) {try {((AbstractBeanDefinition) beanDefinition).validate();} catch (BeanDefinitionValidationException ex) {throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,"Validation of bean definition failed", ex);}}// 根据bean名称从缓存中获取bean定义BeanDefinition existingDefinition = this.beanDefinitionMap.get(beanName);if (existingDefinition != null) {// 如果缓存中已经有改bean,并且定义不允许覆盖,那么直接抛异常if (!isAllowBeanDefinitionOverriding()) {throw new BeanDefinitionOverrideException(beanName, beanDefinition, existingDefinition);} else if (existingDefinition.getRole() < beanDefinition.getRole()) {// e.g. was ROLE_APPLICATION, now overriding with ROLE_SUPPORT or ROLE_INFRASTRUCTUREif (logger.isInfoEnabled()) {logger.info("Overriding user-defined bean definition for bean '" + beanName +"' with a framework-generated bean definition: replacing [" +existingDefinition + "] with [" + beanDefinition + "]");}} else if (!beanDefinition.equals(existingDefinition)) {if (logger.isDebugEnabled()) {logger.debug("Overriding bean definition for bean '" + beanName +"' with a different definition: replacing [" + existingDefinition +"] with [" + beanDefinition + "]");}} else {if (logger.isTraceEnabled()) {logger.trace("Overriding bean definition for bean '" + beanName +"' with an equivalent definition: replacing [" + existingDefinition +"] with [" + beanDefinition + "]");}}// 覆盖老的bean定义this.beanDefinitionMap.put(beanName, beanDefinition);} else {if (hasBeanCreationStarted()) {// 已有bean被标记为创建中// Cannot modify startup-time collection elements anymore (for stable iteration)synchronized (this.beanDefinitionMap) {this.beanDefinitionMap.put(beanName, beanDefinition);List<String> updatedDefinitions = new ArrayList<>(this.beanDefinitionNames.size() + 1);updatedDefinitions.addAll(this.beanDefinitionNames);updatedDefinitions.add(beanName);this.beanDefinitionNames = updatedDefinitions;removeManualSingletonName(beanName);}} else {// 还都在解析阶段,没有创建bean,直接加到缓存中// Still in startup registration phasethis.beanDefinitionMap.put(beanName, beanDefinition);this.beanDefinitionNames.add(beanName);removeManualSingletonName(beanName);}this.frozenBeanDefinitionNames = null;}if (existingDefinition != null || containsSingleton(beanName)) {resetBeanDefinition(beanName);} else if (isConfigurationFrozen()) {clearByTypeCache();}}
过程:
- 首先是参数有效性,不能为空或者空字符串;
- BeanDefinition 的最后一次校验,主要为了 methodoverrides 属性,校验 methodoverrides 是否与工厂方法并存或者methodoverrides 对应的方法有没有;
- 对 bean 已经注册的处理,如果不能覆盖的话,抛异常,否则直接覆盖;
- 对于bean 没有被注册过的处理:
- 如果有其他 bean 在创建中了,那么加锁处理缓存map,涉及到其他线程来访问该 map;
- 如果没有 bean 在创建中,表明还在解析阶段,直接加入 map 中,因为还涉及不到并发访问;
- 加入 map 缓存;
- 重置,清除与之相关的缓存;
通过 aliases 注册
有了根据名称注册后,那么根据别名注册就容易理解了。最终添加到 aliasMap 缓存中。@Overridepublic void registerAlias(String name, String alias) {Assert.hasText(name, "'name' must not be empty");Assert.hasText(alias, "'alias' must not be empty");synchronized (this.aliasMap) {if (alias.equals(name)) {this.aliasMap.remove(alias);if (logger.isDebugEnabled()) {logger.debug("Alias definition '" + alias + "' ignored since it points to same name");}}else {String registeredName = this.aliasMap.get(alias);if (registeredName != null) {if (registeredName.equals(name)) {// An existing alias - no need to re-registerreturn;}if (!allowAliasOverriding()) {throw new IllegalStateException("Cannot define alias '" + alias + "' for name '" +name + "': It is already registered for name '" + registeredName + "'.");}if (logger.isDebugEnabled()) {logger.debug("Overriding alias '" + alias + "' definition for registered name '" +registeredName + "' with new target name '" + name + "'");}}checkForAliasCircle(name, alias);this.aliasMap.put(alias, name);if (logger.isTraceEnabled()) {logger.trace("Alias definition '" + alias + "' registered for name '" + name + "'");}}}}
注册完毕
将解析好的bean定义注册完毕后,也就完成了 bean 标签解析及注册的前3步:
- 首先由 BeanDefinitionParserDelegate 解析得到 BeanDefinitionHolder 实例,其拿到了例如 className、 id、alias 等属性;
- 如果有自定义的属性,需要进一步解析下;
- 解析完毕后利用 BeanDefinitionReaderUtils 进行 bean 的注册;
- 最后发出通告,告诉相关的监听器,bean 已经加载完毕。
通知监听器注册完成
这里并没有做什么特殊的处理,开发人员可以注册监听器实现自定义的处理。getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
到此为止,bean 的解析及注册就完成了!alias 标签的解析
首先来看 alias 标签的使用方式。 ```xml
学习了bean标签的解析,再看这个 alias 标签的解析就容易的多了。
1. 验证标签属性空值;
2. 注册别名;
3. 发送通知;java
protected void processAliasRegistration(Element ele) {
String name = ele.getAttribute(NAME_ATTRIBUTE);
String alias = ele.getAttribute(ALIAS_ATTRIBUTE);
boolean valid = true;
if (!StringUtils.hasText(name)) {
getReaderContext().error(“Name must not be empty”, ele);
valid = false;
}
if (!StringUtils.hasText(alias)) {
getReaderContext().error(“Alias must not be empty”, ele);
valid = false;
}
if (valid) {
try {
getReaderContext().getRegistry().registerAlias(name, alias);
} catch (Exception ex) {
getReaderContext().error(“Failed to register alias ‘“ + alias +
“‘ for bean with name ‘“ + name + “‘“, ele, ex);
}
getReaderContext().fireAliasRegistered(name, alias, extractSource(ele));
}
}
<a name="aagpF"></a>
## import 标签的解析
如果想要分模块的话,可以采用 import 标签来导入配置xml
解析过程也很容易理解:java
protected void importBeanDefinitionResource(Element ele) {
// 配置文件地址
String location = ele.getAttribute(RESOURCE_ATTRIBUTE);
if (!StringUtils.hasText(location)) {
getReaderContext().error(“Resource location must not be empty”, ele);
return;
}
// 解析系统环境变量
// Resolve system properties: e.g. “${user.dir}”
location = getReaderContext().getEnvironment().resolveRequiredPlaceholders(location);
Set解析过程:
1. 首先得到导入资源的地址;
2. 然后解析地址中的系统环境变量,比如:${user.dir} ;
3. 判断是绝对路径还是相对路径;
4. 如果是绝对路径,那么就调用解析方法去递归解析;
5. 如果是相对路径,那么把路径转换成绝对路径去解析 ;
6. 解析完毕后,发送通知。
<a name="WHJBR"></a>
## beans 标签的解析
很明显,beans 标签的解析,就是递归解析 bean 标签🏷。xml
<?xml version=”1.0” encoding=”UTF-8”?>

若有收获,就点个赞吧
0 人点赞
