1、索引失效
- 全值匹配
- 最左前缀法则
- 不在索引上做操作(计算,函数,类型转换)
- 存储引擎不能使用索引中范围条件右边的列
- 尽量使用覆盖索引,只访问索引的查询,索引列和查询列一致
- mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表查询
- is null ,is not null 无法使用索引
- like以通配符开头,mysql索引失效
- 解决like ‘%字符串%’时索引不被使用的方法?
- 使用覆盖索引,所查的字段被索引包含
- 解决like ‘%字符串%’时索引不被使用的方法?
- 字符串不加单引号索引失效
- 少用or,用它连接时索引失效
2、优化总结
全值匹配我最爱,最左前缀要遵守
带头大哥不能死,中间兄弟不能断
索引列上少计算,范围之后全失效
LIKE百分写最右,覆盖索引不写星
不等空值还有or,索引失效要少用
VAR引号不可丢,SQL高级也不难
3、查询优化
- 小表驱动大表
- order by关键字优化
- 避免使用filesort
- 尽可能满足最佳左前缀
- 如果不在索引列上,产生两种算法
- 双路排序: MySQL 4.1之前
- 单路排序:从磁盘读取查询需要的所有列,按照order by列在buffer中进行排序输出,避免了第二次读取数据,把随机IO变为了顺序IO,但是他会使用更多的空间,因为它把每一行都保存在内存中
- 问题:如果sort_buffer(假设1g)小于要排序的数据大小(假设4g),那么就要创建临时文件进行多次排序合并,比双路还要耗时
- 优化策略: 增大sort_buffer_size值 、增大max_length_for_sort_data,避免使用select * 只查询需要的字段

- 问题:如果sort_buffer(假设1g)小于要排序的数据大小(假设4g),那么就要创建临时文件进行多次排序合并,比双路还要耗时
- group by关键字优化
- 实质是先排序后分组,遵守索引最左前缀原则
- 无法使用索引列时,增大sort_buffer_size 和 max_length_for_sort_data
- where高于having,能写where尽量不要写having
- 慢查询日志
- 是MySQL提供的一种日志记录,用来记录响应时间超过阙值的sql,时间可通过long_query_time设定,默认10s
- MySQL默认不开启慢查询日志
- 查询:show variables like ‘%slow_query_log%’
- 开启:set global slow_query_log = 1; 作用于当前数据库,MySQL重启后失效
- 如果要永久开启,修改my.cnf文件,[mysqld]下增加或修改参数(slow_query_log = 1 ; slow_query_log_file = ../slow_query.log),然后重启服务
- show variables like ‘%long_query_time%’ 查看默认时间
- set global long_query_time = x ; 需要断开连接或者重开会话才生效
- show global status like ‘%slow_queries%’ 查看慢查询的记录次数
- 日志分析工具 : mysqldumpslow
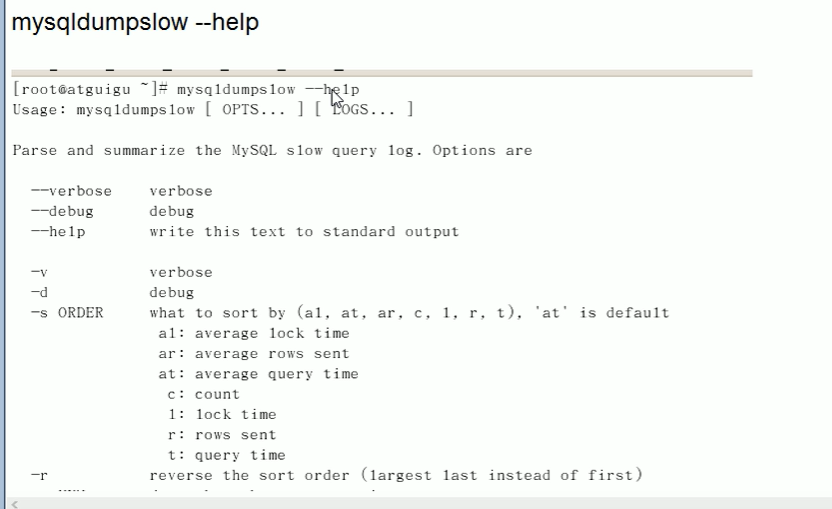


- show profile:
- 可分析当前语句执行的资源消耗情况,用于SQL的调优测量
- 默认情况关闭,并保存最近15次结果
- 步骤:
- 开启功能 1、show variables like ‘profiling’ 2、set profiling = on
- 运行sql
- 查看结果 show profiles


- 如果出现以下信息,危!!!
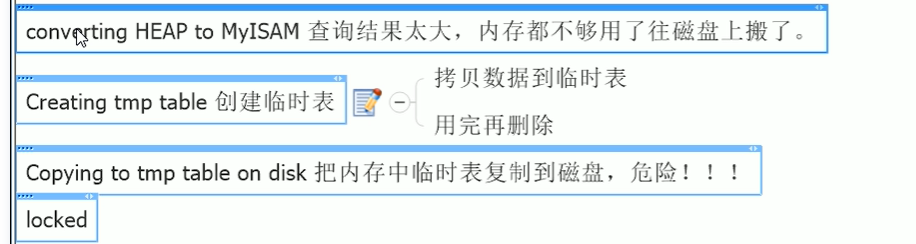
- 可以查看的参数包含如下

- 全局查询日志(只建议在测试环境使用):
- 启用:set global general_log = 1; set global log_output = ‘TABLE’;
- 之后,编写的sql都会保存在general_log表中
分析:
- 观察,至少跑一天,观察生产慢SQL情况
- 开启慢查询日志,设置阙值,比如超过5s就是慢SQL,并且抓取
- explain + 慢SQL分析
- 如果还没有解决,可以使用show profile 查询SQL在MySQL服务器里面的执行细节和生命周期
- SQL数据库服务器的参数优化
4、in 和 exists
- exists:
- select * from A where exists (subquery);
- 将主查询的数据,放到子查询中做条件验证,根据验证条件的true 和 false 来确定数据结果是否保留
- select * from A where A.id in (select id from B); 当B的数据集 > A 使用in
- select * from A where exists (select 1 fom B where A.id = B.id); 当A数据集 < B 使用exists

若有收获,就点个赞吧
0 人点赞
