官方中文文档—->mybatisPlus
mybatisPlus简介
简介
MyBatis-Plus(简称 MP)是一个MyBatis的增强工具,在MyBatis的基础上只做增强不做改变,为简化开发、提高效率而生。
愿景 我们的愿景是成为 MyBatis 最好的搭档,就像魂斗罗中的 1P、2P,基友搭配,效率翻倍

特征
- 无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑;
- 损耗小:启动即会自动注入基本CURD,性能基本无损耗,直接面向对象操作;
- 强大的CRUD操作:内置通用Mapper、通用Service,仅仅通过少量配置即可实现单表大部分CRUD操作,更有强大的条件构造器,满足各类使用需求;
- 支持Lambda形式调用:通过Lambda表达式,方便的编写各类查询条件,无需再担心字段写错;
- 支持主键自动生成:支持多达4种主键策略(内含分布式唯一ID生成器-Sequence),可自由配置,完美解决主键问题;
- 支持ActiveRecord模式:支持ActiveRecord形式调用,实体类只需继承Model类即可进行强大的CRUD操作;
- 支持自定义全局通用操作:支持全局通用方法注入(Write once, use anywhere);
- 内置代码生成器:采用代码或者Maven插件可快速生成Mapper、Model、Service、Controller层代码,支持模板引擎,更有超多自定义配置等您来使用;
- 内置分页插件:基于MyBatis物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通List查询;
- 分页插件支持多种数据库:支持MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer等多种数据库;
- 内置性能分析插件:可输出SQL语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询;
内置全局拦截插件:提供全表delete、update操作智能分析阻断,也可自定义拦截规则,预防误操作;
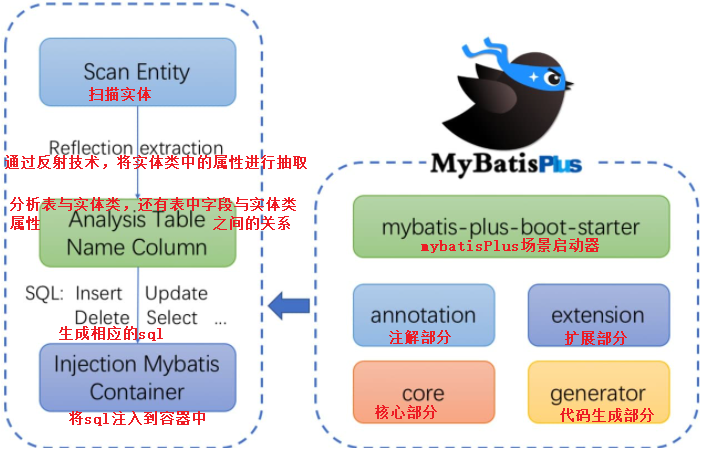
框架结构
入门案例
导入依赖
<!--导入mybatis-plus场景启动器--><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.1</version></dependency><!--导入lombok依赖--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><!--导入mysql驱动依赖--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><scope>runtime</scope></dependency><!--导入德鲁伊连接池--><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.17</version></dependency>
配置文件
spring: datasource: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://ip号/mybatis_plus?characterEncoding=utf-8&useSSL=false username: root password: 12345ssdlh mybatis-plus: configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl #配置日志,可在控制台打印出sql语句实体类
@Data @AllArgsConstructor @NoArgsConstructor public class User { private Long id; private String name; private Integer age; private String email; }mapper接口
import com.atguigu.mybatisplus_01.pojo.User; import com.baomidou.mybatisplus.core.mapper.BaseMapper; import org.apache.ibatis.annotations.Mapper; @Mapper public interface UserMapper extends BaseMapper<User> { }测试
@Autowired private UserMapper userMapper;查询所有数据
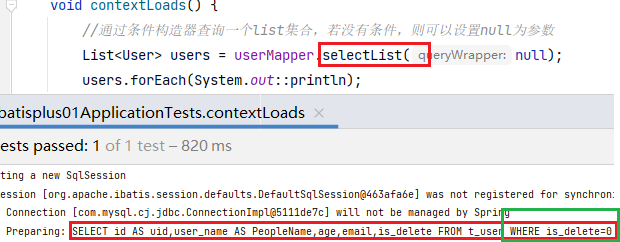
@Test void contextLoads() { //通过条件构造器查询一个list集合,若没有条件,则可以设置null为参数 List<User> users = userMapper.selectList(null); users.forEach(System.out::println); }其他功能
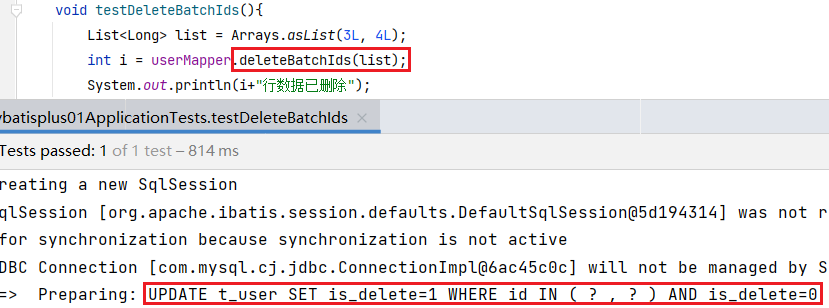
/*插入数据*/ @Test void testInsert(){ User user=new User(null,"斩杀",56,"@zhansha.com"); int i = userMapper.insert(user); System.out.println(i+"行数据已插入,id值为"+user.getId()); //其中插入数据的主键id值会通过雪花算法生成,并可以直接赋给此实体类 } /*根据id删除数据*/ @Test void testDeleteById(){ int i = userMapper.deleteById(1509518991436038145L); //加L表示为long类型 System.out.println(i+"行数据已删除"); } /*根据其他属性设置map集合删除数据*/ @Test void testDeleteByMap(){ Map<String,Object> map=new HashMap<>(); map.put("age",24); map.put("email","test5@baomidou.com"); //可添加多个删除条件,必须满足所有条件的数据才能被删除 int i = userMapper.deleteByMap(map); System.out.println(i+"行数据已删除"); } /*根据id批量删除数据*/ @Test void testDeleteBatchIds(){ List<Long> list = Arrays.asList(3L, 4L); int i = userMapper.deleteBatchIds(list); System.out.println(i+"行数据已删除"); } /*根据id修改数据*/ @Test void testUpdate(){ User user=new User(); user.setId(1L); user.setAge(15); user.setEmail("123@weichat.com"); int i = userMapper.updateById(user); System.out.println(i+"行数据已修改"); } /*根据id查询*/ @Test void testSelect(){ User user = userMapper.selectById(1L); System.out.println(user.toString()); } /*根据id批量查询数据*/ @Test void testSelectBatchIds(){ List<Long> list = Arrays.asList(1L, 2L, 3L, 6L); List<User> users = userMapper.selectBatchIds(list); System.out.println(users.toString()); } /*根据其他属性设置map集合查询数据*/ @Test void testSelectByMap(){ Map<String,Object> map=new HashMap<>(); map.put("name","Jack"); map.put("email","test2@baomidou.com"); //可添加多个查询条件,必须满足所有条件的数据才能查询到 List<User> users = userMapper.selectByMap(map); users.forEach(System.out::println); }自定义sql
也可以自定义sql进行查询,可通过创建mapper映射文件来编写自定义sql;

- 可以在配置文件中配置mapper映射文件的位置,也可以不用配置采用默认路径;
-
通用Service
通用Service CRUD封装IService(opens new window)接口,进一步封装CRUD采用
get查询单行,remove删除,list查询集合,page分页前缀命名方式区分Mapper层避免混淆;- 泛型T为任意实体对象;
- 建议如果存在自定义通用Service方法的可能,请创建自己的IBaseService继承Mybatis-Plus提供的接口IService及其实现类ServiceImpl;
对象Wrapper为条件构造器;
public interface IService<T> {... //泛型T通常填自己创建的实体类public class ServiceImpl<M extends BaseMapper<T>, T> implements IService<T> {... //泛型T通常填自己创建的实体类,泛型M通常填自己创建的mapper映射文件操作
自定义UserService接口
public interface UserService extends IService<User> {}自定义UserServiceImpl接口实现类
@Service public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {}测试
@Autowired private UserService us; @Test//查询总记录数 void test(){ long l = us.count(); System.out.println(l+"条数据"); } @Test//批量添加数据 void testInsertMore(){ List<User> list=new ArrayList<>(); for(int i=1;i<=10;i++){ User user=new User(); user.setName("钢铁侠0"+i+"型"); user.setAge(i*i); user.setEmail(i*i*i+"@qq.com"); list.add(user); } boolean b = us.saveBatch(list); System.out.println("插入成功与否?"+b); }MybatisPlus常用注解
@TableName
实体类名和数据库表名必须保持一致,如果不一致,就需要使用@TableName注解;
单独设置
@TableName("t_user") public class User {... //User为实体类名,t_user为数据库表名批量设置
如果所有的数据库表名对比实体类名都有默认的前缀,亦可以在配置文件中进行全局配置数据库表统一前缀,如下:
mybatis-plus: global-config: db-config: table-prefix: _t #例如:User为实体类名,t_user为数据库表名@TableId
主键名不是id
mybaitsplus中主键名必须叫id,如果不是就需要用到@TableId注解进行标识;
【指的是数据库表的主键名不是id,不是数据库表名和实体类属性名和数据库表列名不一样】public class User { @TableId//将属性所对应的字段指定为主键 private Long uid;//uid为主键名 ...@TableId的value属性
数据表主键名与实体类属性名不一致
public class User { @TableId(value = "id")//id为主键名 //@TableId的value属性用于指定主键的字段 private Long uid;@TableId的type属性
type属性表示当前主键生成策略,默认是雪花算法;
- 只有不手动设置主键值时才会用到主键生成策略,如果自己手动设置了主键值就使用手动设置的值;
常用的主键策略:
| 值 | 描述 | | —- | —- | | IdType.ASSIGN_ID(默认) | 基于雪花算法的策略生成数据id,与数据库id是否设置自增无关 | | IdType.AUTO | 使用数据库的自增策略,注意,该类型请确保数据库设置了id自增, 否则无效 |
如果我们不想用雪花算法,想用mysql的自增策略,需要做以下操作:
- 要将mysql数据库里的表结构改为自增;
- 在主键上标识@TableId注解并在写入type属性值,如下:
public class User { @TableId(value = "id",type = IdType.AUTO) private Long uid; ...统一设置主键生成策略
mybatis-plus: global-config: db-config: id-type: auto #统一设置主键生成策略为自增策略雪花算法
背景
需要选择合适的方案去应对数据规模的增长,以应对逐渐增长的访问压力和数据量。数据库的扩展方式主要包括:业务分库、主从复制,数据库分表。数据库分表
将不同业务数据分散存储到不同的数据库服务器,能够支撑百万甚至千万用户规模的业务,但如果业务继续发展,同一业务的单表数据也会达到单台数据库服务器的处理瓶颈。例如,淘宝的几亿用户数据,如果全部存放在一台数据库服务器的一张表中,肯定是无法满足性能要求的,此时就需要对单表数据进行拆分。
单表数据拆分有两种方式:垂直分表和水平分表。示意图如下: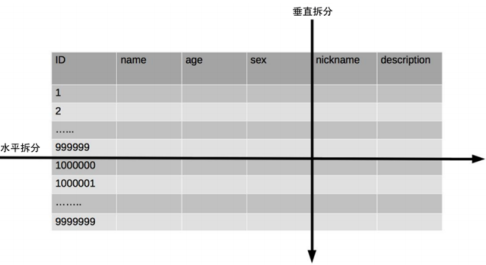
垂直分表
垂直分表适合将表中某些不常用且占了大量空间的列拆分出去。
例如,我们是一个婚恋网站,用户在筛选其他用户的时候,主要是用age和sex两个字段进行查询,而nickname和description两个字段主要用于展示,一般不会在业务查询中用到。description本身又比较长,因此我们可将这两个字段独立到另一张表中,这样在查询age和sex时,就能带来一定性能提升。水平分表
水平分表适合表行数特别大的表,有的公司要求单表行数超过5000万就必须进行分表,这个数字可以作为参考,但并不是绝对标准,关键还是要看表的访问性能。对于一些比较复杂的表,可能超过1000万就要分表了;而对于一些简单的表,即使存储数据超过1亿行,也可以不分表。但不管怎样,当看到表的数据量达到千万级别时,作为架构师就要警觉起来,因为这很可能是架构的性能瓶颈或者隐患。水平分表相比垂直分表,会引入更多的复杂性,例如要求全局唯一的数据id该如何处理;雪花算法
雪花算法是由Twitter公布的分布式主键生成算法,它能够保证不同表的主键的不重复性,以及相同表的主键的有序性。
@TableField
如果数据库表中的非主键名与实体类属性名不一致时,就需要用到@TableField注解;
注:如果数据库表的列名和实体类属性名符合驼峰命名规则,则无需加@TableField注解,因为mybatis-plus默认开启驼峰命名;public class User { @TableId(value = "id",type = IdType.AUTO) private Long uid; @TableField(value = "user_name") private String PeopleName; ....//数据库表列名为user_name@TableLogic
@TableLogic注解用来标识逻辑删除属性字段;
- 物理删除:真实删除,将对应数据从数据库中删除,之后查询不到此条被删除的数据;
逻辑删除:假删除,将对应数据中代表是否被删除字段的状态修改为“被删除状态”,之后在数据库中仍旧能看到此条数据记录;
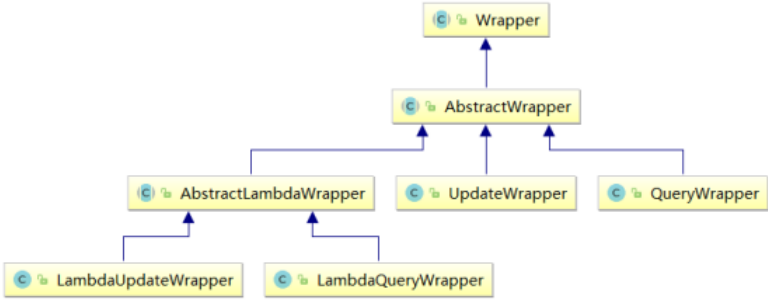
AbstractWrapper:用于查询条件封装,生成sql的where条件;
- QueryWrapper:查询条件封装,删除操作也用和查询相同的QueryWrapper,修改也可以使用QueryWrapper;
- UpdateWrapper:Update条件封装(除了可以设置筛选条件,还可以设置修改的数据);
- AbstractLambdaWrapper:使用Lambda语法;
- LambdaQueryWrapper:用于Lambda语法使用的查询Wrapper;
- LambdaUpdateWrapper:Lambda更新封装Wrapper;
QueryWrapper
组装查询条件
控制台编译的sql:@Autowired private UserMapper userMapper; @Test void test01(){ //查询用户名包含0,年龄在5到20之间,邮箱信息不为null的用户信息; QueryWrapper<User> queryWrapper=new QueryWrapper<>(); queryWrapper.like("user_name","0") .between("age",5,20) .isNotNull("email"); List<User> list = userMapper.selectList(queryWrapper); list.forEach(System.out::println); }==> Preparing: SELECT id AS uid,user_name AS PeopleName,age,email,is_delete FROM t_user WHERE is_delete=0 AND (user_name LIKE ? AND age BETWEEN ? AND ? AND email IS NOT NULL) ==> Parameters: %0%(String), 5(Integer), 20(Integer)

组装排序条件
@Test
void test02(){
//查询用户信息,按照年龄的降序排序,若年龄相同,则按照id升序进行排序
QueryWrapper<User> queryWrapper=new QueryWrapper<>();
queryWrapper.orderByDesc("age")
.orderByAsc("id");
List<User> list = userMapper.selectList(queryWrapper);
list.forEach(System.out::println);
}
控制台编译的sql:
==> Preparing: SELECT id AS uid,user_name AS PeopleName,age,email,is_delete FROM t_user WHERE is_delete=0 ORDER BY age DESC,id ASC ==> Parameters:
组装删除条件
@Test
void test03(){
//删除邮箱中包含xxx字段的用户信息;
QueryWrapper<User> queryWrapper=new QueryWrapper<>();
queryWrapper.like("email","xxx");
int i = userMapper.delete(queryWrapper);
System.out.println(i+"条数据被删除");
}
控制台编译的sql:
==> Preparing: UPDATE t_user SET is_delete=1 WHERE is_delete=0 AND (email LIKE ?) ==> Parameters: %xxx%(String)
组装修改条件
@Test
void test04(){
//将(年龄大于20并且用户名中包含a)或邮箱为null的用户信息
QueryWrapper<User> queryWrapper=new QueryWrapper<>();
queryWrapper.gt("age",20)
.like("user_name","a")
.or()//默认是and连接,如需要or连接的话用”.or()“方法
.isNull("email");
User user=new User();
user.setEmail("test@guigu.com");
user.setPeopleName("雄安命");
int i = userMapper.update(user, queryWrapper);
//当实体类属性值不为null时才进行修改;
System.out.println(i+"条数据已修改");
}
控制台编译的sql:
==> Preparing: UPDATE t_user SET email=? WHERE is_delete=0 AND (age > ? AND user_name LIKE ? OR email IS NULL) ==> Parameters: test@guigu.com(String), 20(Integer), %a%(String)
条件的优先级
@Test
void test05(){
//将用户名中包含0并且(年龄大于20或邮箱为null)的用户信息进行修改
QueryWrapper<User> queryWrapper=new QueryWrapper<>();
queryWrapper.like("user_name","0")
.and(x->x.gt("age",20).or().isNull("email"));
//lambda表达式中的属性优先执行
//x形参代表条件构造器
User user=new User();
user.setEmail("test@guigu.com");
user.setPeopleName("小航");
int i = userMapper.update(user, queryWrapper);
System.out.println(i+"条数据已修改");
}
控制台编译的sql:
==> Preparing: UPDATE t_user SET user_name=?, email=? WHERE is_delete=0 AND (user_name LIKE ? AND (age > ? OR email IS NULL)) ==> Parameters: 小航(String), test@guigu.com(String), %0%(String), 20(Integer)
观察and()方法源码可以发现,形参Param其实就是条件构造器,这里用x来代表条件构造器;
/**
* 查询条件封装
* <p>嵌套</p>
* <li>泛型 Param 是具体需要运行函数的类(也是 wrapper 的子类)</li>
*
* @author hubin miemie HCL
* @since 2017-05-26
*/
public interface Nested<Param, Children> extends Serializable {
/**
* ignore
*/
default Children and(Consumer<Param> consumer) {
lambda表达式复习
Lambda是一个匿名函数,我们可以把Lambda表达式理解为是一段可以传递的代吗(将代像数据一样进行传递)。使用它可以写出更简洁、更灵活的代码。作为一种更紧凑的代码风格,使Java的语言表达能力得到了提升。
1、举例:
**(o1,o2)->Integer.compare(o1,o2);**
2、格式:
**->**:lambda表达式的操作符或者箭头操作符**->**左边:指的是**(o1,o2)**,是lambda表达式的形参列表**->**右边:指的是**Integer.compare(o1,o2);**,是lambda表达式的方法体
3、使用(分6种情况):
Consumer<String> consumer1=new Consumer<String>() {
@Override
public void accept(String s) {
}
};
Comparator<Integer> comparator=new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return 0;
}
};
①无参无返回值
②一个参数无返回值
格式:**(类型 参数)->{方法体}**
例如:Consumer<String> consumer=(String s)->{System._out_.println(s);};
③“类型推断”
如果数据类型可以推断出,类型就可以省略,因为可由编译器推断得出,称为“类型推断”;
格式:**(参数名)->{方法体}**
例如:Consumer<String> consumer=(s)->{System._out_.println(s);};
④一个参数时,参数小括号可省略
格式:**参数名->{方法体}**
例如:Consumer<String> consumer=s->{System._out_.println(s);};
⑤两个及以上参数,多条执行语句,有返回值
格式:**(类型1 参数1,类型2 参数3...)->{执行语句1;执行语句2...;return...;}**
例如:
Comparator<Integer> comparator=(o1,o2)->{
System.out.println(o1);
System.out.println(o2);
return o1.compareTo(o2);
};
⑥lambda体只有一条语句时,return和大括号都可以省略
格式:**(类型1 参数1,类型2 参数3...)->返回结果**
例如:Comparator<Integer> comparator=(o1,o2)->o1.compareTo(o2);
4、lambda表达式的本质
5、总结
**->左边**:lambda形参列表的参数类型可以省略(类型推断),如果Lambda形参列表只有一个参数,其一对**()**也可以省略;**->右边**:lambda体应该使用—对**{}**包裹;如果lambda体只有一条执行语句(可能是return语句),可以省略这一对**{}**和return关键字;
组装select查询语句
@Test
void test06(){
//仅查询用户的用户名和邮箱信息
QueryWrapper<User> queryWrapper=new QueryWrapper<>();
queryWrapper.select("user_name","email");
List<Map<String, Object>> list = userMapper.selectMaps(queryWrapper);
list.forEach(System.out::println);
}
控制台编译的sql:
==> Preparing: SELECT user_name,email FROM t_user WHERE is_delete=0 ==> Parameters:
组装子查询
@Test
void test07(){
//用子查询来实现“查询id<=100的用户信息”的功能,如下
/*SELECT * FROM t_user WHERE id IN(
SELECT id FROM t_user WHERE id<=100
);*/
QueryWrapper<User> queryWrapper=new QueryWrapper<>();
queryWrapper.inSql("id","SELECT id FROM t_user WHERE id<=100");
List<User> list = userMapper.selectList(queryWrapper);
list.forEach(System.out::println);
}
控制台编译的sql:
==> Preparing: SELECT id AS uid,user_name AS PeopleName,age,email,is_delete FROM t_user WHERE is_delete=0 AND (id IN (SELECT id FROM t_user WHERE id<=100)) ==> Parameters:
UpdateWrapper
@Test
void test08(){
UpdateWrapper<User> updateWrapper=new UpdateWrapper<>();
//将用户名中包含0并且(年龄大于3或邮箱为null)的用户信息进行修改
updateWrapper.like("user_name","0")
.and(i->i.gt("age",3).or().isNull("email"));
//.gt();大于
updateWrapper.set("user_name","还望").set("email","ZUA.com");
int i = userMapper.update(null, updateWrapper);
System.out.println(i+"条数据已修改");
}
控制台编译的sql:
==> Preparing: UPDATE t_user SET user_name=?,email=? WHERE is_delete=0 AND (user_name LIKE ? AND (age > ? OR email IS NULL)) ==> Parameters: 还望(String), ZUA.com(String), %0%(String), 3(Integer)
模拟开发中组装条件
要求:根据条件进行查询(根据用户名模糊查询和年龄区间筛选),如果为空为null为空白符则不筛选该条件;
传统方法
@Test
void test09(){
String username="";
Integer ageBegin=20;
Integer ageEnd=30;
QueryWrapper<User> queryWrapper=new QueryWrapper<>();
if(StringUtils.isNotBlank(username)){
//import org.junit.platform.commons.util.StringUtils;
//isNotBlank判段某个字段是否不为空字符串,不为null,不为空白符;
queryWrapper.like("user_name",username);
}
if(ageBegin!=null){
queryWrapper.ge("age",ageBegin);
//.ge();大于等于
}
if(ageEnd!=null){
queryWrapper.le("age",ageEnd);
}
List<User> list = userMapper.selectList(queryWrapper);
list.forEach(System.out::println);
}
控制台编译的sql:
==> Preparing: SELECT id AS uid,user_name AS PeopleName,age,email,is_delete FROM t_user WHERE is_delete=0 AND (age >= ? AND age <= ?) ==> Parameters: 20(Integer), 30(Integer)
简单写法-condition组装条件
@Test
void test10(){
String username="";
Integer ageBegin=20;
Integer ageEnd=30;
QueryWrapper<User> queryWrapper=new QueryWrapper<>();
queryWrapper.like(StringUtils.isNotBlank(username),"user_name",username)
.ge(ageBegin!=null,"age",ageBegin)
.le(ageEnd!=null,"age",ageEnd);
List<User> list = userMapper.selectList(queryWrapper);
list.forEach(System.out::println);
}
控制台编译的sql:
==> Preparing: SELECT id AS uid,user_name AS PeopleName,age,email,is_delete FROM t_user WHERE is_delete=0 AND (age >= ? AND age <= ?) ==> Parameters: 20(Integer), 30(Integer)
LambdaQueryWrapper
@Test
void test11(){
//根据条件进行查询(根据用户名模糊查询和年龄区间筛选),如果为空为null为空白符则不筛选该条件
String username="";
Integer ageBegin=20;
Integer ageEnd=30;
LambdaQueryWrapper<User> queryWrapper=new LambdaQueryWrapper<>();
queryWrapper.like(StringUtils.isNotBlank(username),User::getPeopleName,username)
.ge(ageBegin!=null,User::getAge,ageBegin)
.le(ageEnd!=null,User::getAge,ageEnd);
List<User> list = userMapper.selectList(queryWrapper);
list.forEach(System.out::println);
}
控制台编译的sql:
==> Preparing: SELECT id AS uid,user_name AS PeopleName,age,email,is_delete FROM t_user WHERE is_delete=0 AND (age >= ? AND age <= ?) ==> Parameters: 20(Integer), 30(Integer)
LambdaUpdateWrapper
@Test
void test12(){
//将用户名中包含0并且(年龄大于3或邮箱为null)的用户信息进行修改
LambdaUpdateWrapper<User> updateWrapper=new LambdaUpdateWrapper<>();
updateWrapper.like(User::getPeopleName,"a")
.and(i->i.gt(User::getAge,3).or().isNull(User::getEmail));
updateWrapper.set(User::getPeopleName,"大黄").set(User::getEmail,"email.com");
int i = userMapper.update(null, updateWrapper);
System.out.println(i+"条数据已修改");
}
控制台编译的sql:
==> Preparing: UPDATE t_user SET user_name=?,email=? WHERE is_delete=0 AND (user_name LIKE ? AND (age > ? OR email IS NULL)) ==> Parameters: 大黄(String), email.com(String), %a%(String), 3(Integer)
插件
1、分页插件
MyBatis Plus自带分页插件,只要简单的配置即可实现分页功能,如下:
添加配置类
@Configuration
public class MyBatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){
MybatisPlusInterceptor interceptor=new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}
测试
@Autowired
UserMapper userMapper;
@Test
public void testPage01(){
//分查询所有数据,1是显示条目的起始索引(从1开始),每次查3条
Page<User> page=new Page<>(1,3);
userMapper.selectPage(page, null);
System.out.println("当前查询数据:"+page.getRecords());
System.out.println("当前页码:"+page.getCurrent()+";每页显示条数;"+page.getSize());
System.out.println("总页数:"+page.getPages());
System.out.println("总记录数:"+page.getTotal());
System.out.println("是否有上一页:"+page.hasPrevious());
System.out.println("是否有下一页:"+page.hasNext());
}
控制台编译的sql:
==> Preparing: SELECT id AS uid,user_name AS PeopleName,age,email,is_delete FROM t_user WHERE is_delete=0 LIMIT ? ==> Parameters: 3(Long)
【因为mybatis-plus中分页的起始索引从1开始,故当起始索引=1时,分页起始索引可以省略】
自定义分页功能
即:自定义我们的查询语句,在自己写的sql语句中通过分页插件来实现分页功能;
mapper接口
@Mapper
public interface UserMapper extends BaseMapper<User> {
/*通过年龄查询用户信息并分页
*page:MyBatisPlus提供的分页对象,必须位于mapper接口中第一个参数的位置*/
Page<User> selectPageVo(@Param("page")Page<User> page,@Param("age")Integer age);
}
mapper映射文件
<select id="selectPageVo" resultType="User">
select id as uid,user_name as PeopleName,age,email from t_user where age > #{age}
</select>
注意:如果resultType不想写全类名,可以直接在配置文件中配置类型别名所对应的包:
mybatis-plus:
type-aliases-package: com.atguigu.mybatisplus_01.pojo
#配置类型别名所对应的包(默认别名为表名且不区分大小写)
测试
@Test
public void testPage02(){
Page<User> page=new Page<>(1,3);
userMapper.selectPageVo(page, 3);
System.out.println("当前查询数据:"+page.getRecords());
System.out.println("当前页码:"+page.getCurrent()+";每页显示条数;"+page.getSize());
System.out.println("总页数:"+page.getPages());
System.out.println("总记录数:"+page.getTotal());
System.out.println("是否有上一页:"+page.hasPrevious());
System.out.println("是否有下一页:"+page.hasNext());
}
==> Preparing: select id as uid,user_name as PeopleName,age,email from t_user where age > ? LIMIT ? ==> Parameters: 3(Integer), 3(Long)
注意:由于是自定义的sql语句,因此查到了已经逻辑删除了的数据;
2、乐观锁
乐观锁与悲观锁
- 上面的故事,如果是乐观锁,小王保存价格前,会检查下价格是否被人修改过了。如果被修改过了,则重新取出被修改后的价格。
如果是悲观锁,小李取出数据后,小王只能等小李操作完之后,才能对价格进行操作。
乐观锁实现流程
数据库中添加version字段;
- 取出记录时,获取当前version;
更新时,version+1,如果
where语句中的version版本不对,则更新失败;Mybatis-Plus实现乐观锁
实体类
在实体类中表示版本号的字段上面添加
@Version注解,如下:@Data @NoArgsConstructor @AllArgsConstructor public class Product { private Long id; private String name; private Integer price; @Version//表示乐观锁版本号字段 private Integer version; }配置类
配置类中添加乐观锁组件,如下:
@Configuration public class MyBatisPlusConfig { @Bean public MybatisPlusInterceptor mybatisPlusInterceptor(){ MybatisPlusInterceptor interceptor=new MybatisPlusInterceptor(); interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL)); //添加分页插件 interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor()); //添加乐观锁插件 return interceptor; } }通用枚举
表中的有些字段值是固定的,例如性别(男或女),此时我们可以使用MyBatis-Plus的通用枚举来实现;
数据库中插入枚举类型
枚举类
@AllArgsConstructor @Getter public enum SexEnum { MALE(1,"男"), FEMALE(0,"女"); @EnumValue//在枚举类型中要填入数据库的属性上面标注此注解 private Integer sex; private String sexName; }实体类
@TableName("t_user") @Data @AllArgsConstructor @NoArgsConstructor public class User { @TableId(value = "id",type = IdType.AUTO) private Long uid; @TableField(value = "user_name") private String PeopleName; private Integer age; private String email; private SexEnum sex; @TableLogic private int isDelete; }application.yaml
mybatis-plus: #扫描通用枚举的包 type-enums-package: com.atguigu.mybatisplus_01.enums测试
@Autowired UserMapper userMapper; @Test void test01(){ User user=new User(); user.setPeopleName("张十年"); user.setAge(16); user.setSex(SexEnum.FEMALE); int i = userMapper.insert(user); System.out.println(i+"条数据插入了"); }mybatis-plus代码生成器
简介
mybatis-plus代码生成器与mybatis逆向工程的区别:
mybatis逆向工程:通过表逆向生成
实体类,mapper接口,mapper映射文件;- mybatis-plus代码生成器:通过表生成
控制层,业务层,持久层,mapper接口,mapper映射文件;引入依赖
<!--导入mybatis-plus代码生成器--> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-generator</artifactId> <version>3.5.1</version> </dependency> <!--导入freemarker依赖 代码生成过程中会使用到freemarker引擎模板--> <dependency> <groupId>org.freemarker</groupId> <artifactId>freemarker</artifactId> <version>2.3.31</version> </dependency>快速生成程序
```java import com.baomidou.mybatisplus.generator.FastAutoGenerator; import com.baomidou.mybatisplus.generator.config.OutputFile; import com.baomidou.mybatisplus.generator.engine.FreemarkerTemplateEngine;
import java.util.Collections;
public class xxxxx { public static void main(String[] args) { FastAutoGenerator.create( “jdbc:mysql://124.70.84.192:3306/mybatisplus?characterEncoding=utf-8&userSSL=false”, //数据库链接地址 “root”, //用户名 “12345ssdlh”)//密码 .globalConfig(builder -> { builder.author(“atguigu”) //设置作者 //.enableSwagger() //开启swagger模式 .fileOverride() //覆盖已生成文件 .outputDir(“E:\Pictures\mysql”); //指定生成文件的输出目录 }) .packageConfig(builder -> { builder.parent(“com.atguigu”) //设置父包名 .moduleName(“mybatisplus”) //设置父包模块名 .pathInfo(Collections.singletonMap( OutputFile.mapperXml, “E:\Pictures\mysql”)); //指定mapperXml生成路径 }) .strategyConfig(builder -> { builder.addInclude(“t_user”) //设置需要生成的表名 .addTablePrefix(“t“, “c_”);//设置过滤表前缀 }) .templateEngine(new FreemarkerTemplateEngine()) //使用Freemarker引擎模板,默认的是Velocity引擎模板 .execute(); } }
执行之后的结果如下:<br />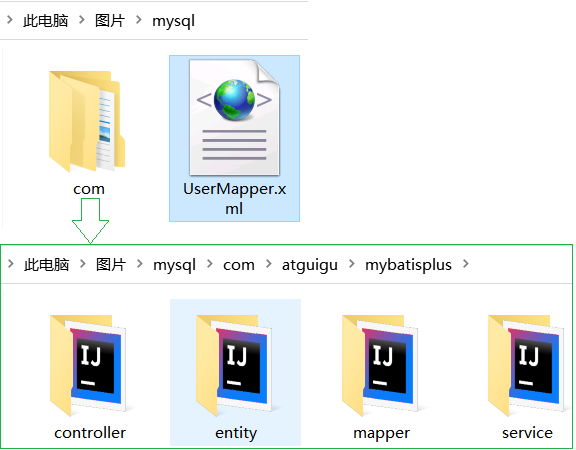
<a name="Pao7W"></a>
# 多数据源
- 适用于多种场景:纯粹多库、 读写分离、 一主多从、 混合模式等
- 场景说明:我们创建两个库,每个库一张表,通过一个测试用例分别获取用户数据(1个库)与商品数据(另1个库),如果获取到说明多库模拟成功;
<a name="em9Hl"></a>
## 引入依赖
```xml
<!--导入多数据源依赖-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>dynamic-datasource-spring-boot-starter</artifactId>
<version>3.5.0</version>
</dependency>
配置文件配置多数据源
spring:
#配置数据源信息
datasource:
dynamic:
#设置默认的数据源或者数据源组,默认值即为master
primary: master
#严格匹配数据源(默认false)
#为true时未匹配到指定数据源抛异常,
#为false时未匹配到指定数据源时使用默认数据源
strict: false
datasource:
master:
url: jdbc:mysql://124.70.84.192:3306/mybatis_plus
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 12345ssdlh
slave_1:
url: jdbc:mysql://124.70.84.192:3306/mybatis_plus_1
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 12345ssdlh
创建User相关
实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
@TableName("t_user")
public class User {
@TableId
private Integer id;
private String userName;
private Integer age;
private Integer sex;
private String email;
@TableLogic
@TableField("is_delete")
private Integer isDeleted;
}
mapper
@Mapper
public interface UserMapper extends BaseMapper<User> {}
service
import com.atguigu.Bean.User;
import com.baomidou.mybatisplus.extension.service.IService;
public interface UserService extends IService<User> {}
import com.atguigu.Bean.User;
import com.atguigu.mapper.UserMapper;
import com.atguigu.service.UserService;
import com.baomidou.dynamic.datasource.annotation.DS;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.springframework.stereotype.Service;
@Service
@DS("master")
public class UserServiceImpl
extends ServiceImpl<UserMapper, User>
implements UserService {}
创建Product相关
实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Product {
private Integer id;
private String name;
private Integer price;
@Version
private Integer version;
}
mapper
@Mapper
public interface ProductMapper extends BaseMapper<Product> {}
service
import com.atguigu.Bean.Product;
import com.baomidou.mybatisplus.extension.service.IService;
public interface ProductService extends IService<Product> {}
import com.atguigu.Bean.Product;
import com.atguigu.mapper.ProductMapper;
import com.atguigu.service.ProductService;
import com.baomidou.dynamic.datasource.annotation.DS;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.springframework.stereotype.Service;
@Service
@DS("slave_1")
public class ProductServiceImpl
extends ServiceImpl<ProductMapper, Product>
implements ProductService {}
测试
@Autowired
UserService userService;
@Autowired
ProductService productService;
@Test
void test01(){
System.out.println(userService.getById(1));
System.out.println(productService.getById(1));}
结果:
1、都能顺利获取对象,则测试成功;
2、如果我们实现读写分离,将写操作方法加上主库数据源,读操作方法加上从库数据源,自动切
换,是不是就能实现读写分离? **@DS**可以注解在类上或方法上;
MyBatisX插件
- MyBatis-Plus为我们提供了强大的mapper和service模板,能够大大的提高开发效率;
- 但是在真正开发过程中,MyBatis-Plus并不能为我们解决所有问题,例如一些复杂的SQL,多表联查,我们就需要自己去编写代码和SQL语句,我们该如何快速的解决这个问题呢,这个时候可以使用MyBatisX插件;
- MyBatisX一款基于IDEA的快速开发插件,为效率而生。
MyBatisX插件用法:—->>官方介绍
IDEA安装MyBatisX插件如下:
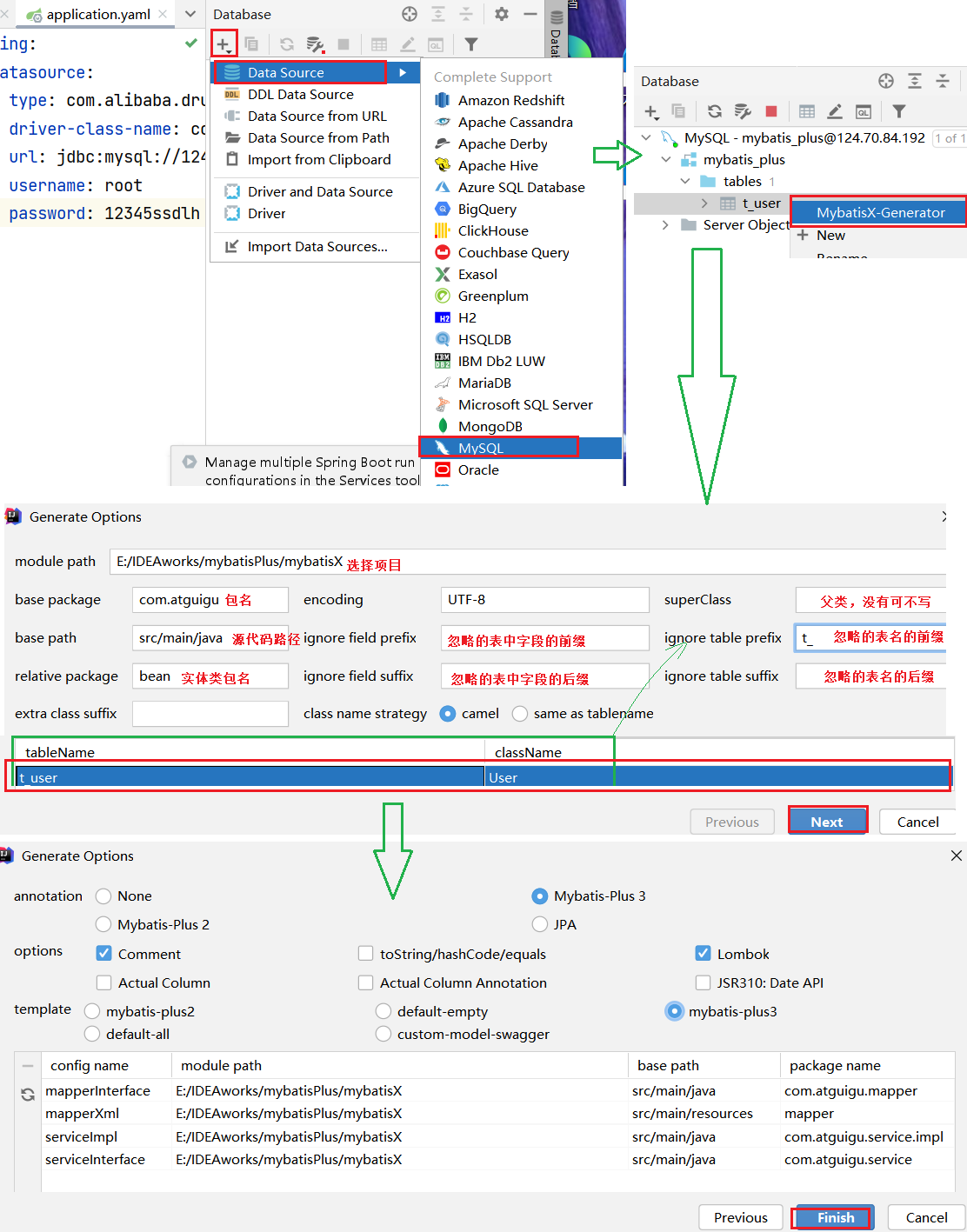
mybatisX快速生成mapper,service,bean等
mybatisX快速生成CRUD
添加
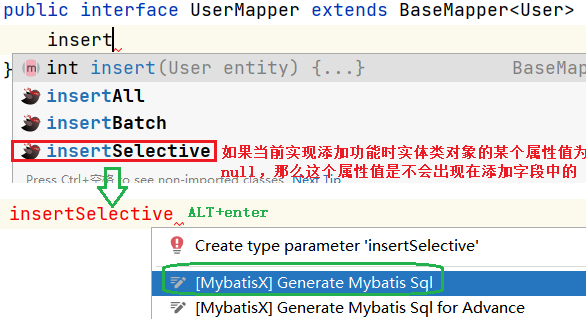
之后就可直接生成mapper接口方法和mapper映射文件中的sql语句;
删除
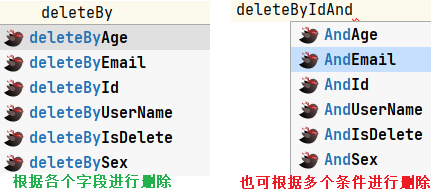
之后同上alt+enter进行选择,之后就可直接生成mapper接口方法和mapper映射文件中的sql语句;
修改
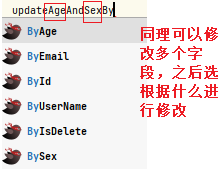
之后同上alt+enter进行选择,之后就可直接生成mapper接口方法和mapper映射文件中的sql语句;
查询
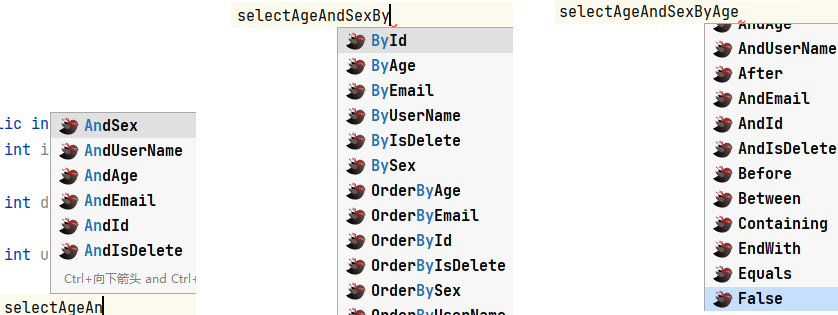
之后同上alt+enter进行选择,之后就可直接生成mapper接口方法和mapper映射文件中的sql语句;

若有收获,就点个赞吧
0 人点赞
