jvm性能调优
jvm结构
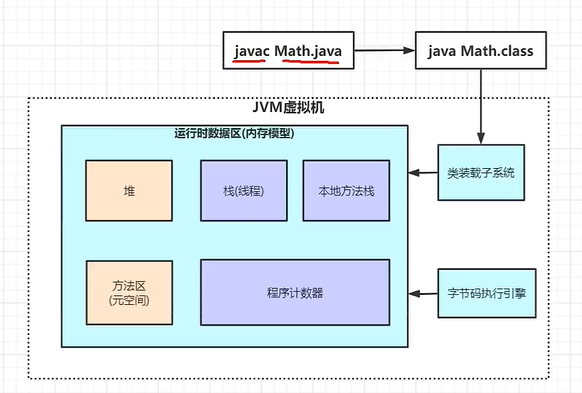
方法区(元空间)
栈
每运行一个线程,都会为这个线程分配一个栈空间(栈空间数据结构就是栈),这个线程中的各个方法以及变量都会获得一块栈帧内存空间,如下: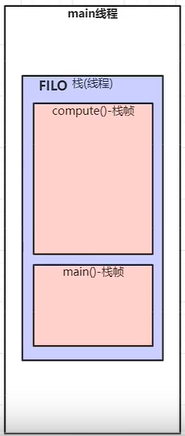
栈帧由四块结构组成:**局部变量表**,**操作数栈**,动态链接,**方法出口**;
**局部变量表**,**操作数栈**:例如一个赋值代码:int a=1;在jvm中进行执行,会先将一个int类型的常量1压入操作数栈,然后将这个int类型的值存入局部变量1(这个局部变量1就相当于局部变量表里面数据的下标索引,其中局部变量0就是调用这个方法的对象他本身),操作数栈就是在对变量值操作时临时提供的一块空间;**动态链接**:将一些符号引用转变为直接引用存放到此;- 符号引用:就比如那些
方法名,变量名,类名之类的统称为java语言的符号; - 直接引用:这个符号被加载到方法区的内存地址称为直接引用,直接引用会放在动态链接里;
- 符号引用:就比如那些
-
程序计数器
程序计数器是每个线程在运行时,jvm都会分配的一块空间,用来记录线程马上或者正在运行的那一行代码的位置(这行代码在方法区里面的内存地址):
假如,我们的的代码正在运行中被更高优先级的线程抢去cpu资源,等这个更高级别线程运行完毕后,cpu就可根据程序计数器记录的位置继续运行我们线程的代码,不必从新开始;
程序计数器记录的地址是动态变化的,它记录的地址值是由字节码执行引擎进行修改的;堆
存放对象;声明一个对象,栈帧内的局部变量表存放的就是这个对象在堆内存中的地址(相当于指针);
Java的基本数据类型不一定存放在栈中,局部变量的基本类型存放在栈中,引用类型的变量名存放在栈中,但是变量名所指向的对象(基本数据类型)存放在堆中。而成员变量,不管是基本类型还是引用类型,变量名和对象都放在堆中。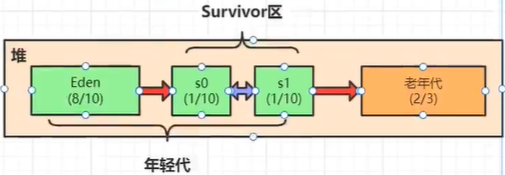
对象分配到堆里面都是优先分配到Eden区的;如果Eden区满了的话,字节码执行引擎的垃圾收集线程就会执行minor gc; minor gc(是回收整个年轻代的):将非垃圾对象赋值到survivor区里面,而将非垃圾对象直接干掉;

- 每经历一次
minor gc,非垃圾对象都会转移到空的survivor区中(s1/s0),且分代年龄+1,当这个非垃圾对象的分代年龄达到15时会直接转移到老年代里面; - 当老年代里面满了之后,就会触发
full gc(回收整个堆里的垃圾对象),但当full gc回收不了垃圾对象,而老年代中还在不停的填加非垃圾对象时,JVM就会发生OOM内存已足; - 挪到老年代有多种情况,一是分代年龄达到15,二是survivor区中放不下了才放到老年代中,其他:

JVM调优减少的就是gc,因为gc会stop the world(例如minor gc``stop the world的区域是整个年轻代,而full gc``stop the world的区域则是整个堆,所以full gc时间要更长),即当执行gc时会停掉所有用户线程的执行(用户会卡一会);
本地方法栈
本地方法:用native修饰的方法,如下:
本地方法在运行的过程中需要用到的内存空间就从本地方法栈分配;
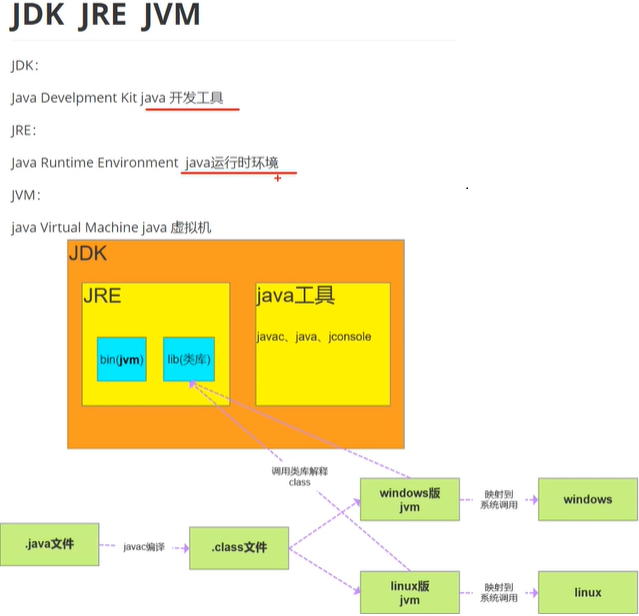
jdk、jre、jvm三者区别
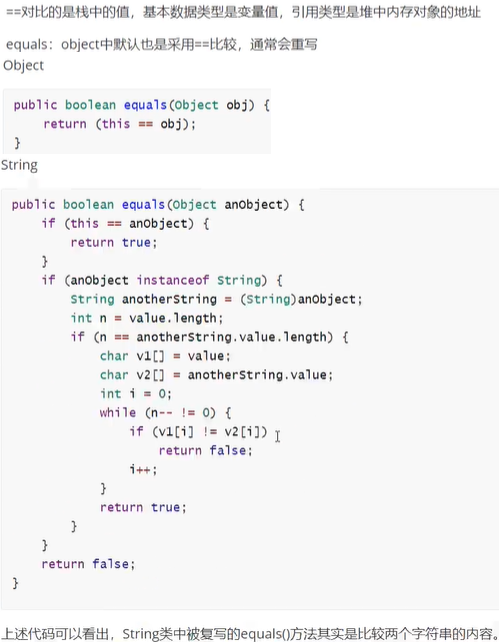
==和equals
final
1、简述**final**作用
最终的;
- 修饰类:表示类不可被继承;
- 修饰方法:表示方法不可被子类覆盖,但是可以重载;
- 修饰变量:表示变量一旦被赋值就不可以更改它的值。
(1)修饰成员变量:
- 如果final修饰的是类变量(即静态变量),只能在静态初始化块中指定初始值或者声明该类变量时指定初始值。
- 成员变量随着对象的创建而存在,随着对象的回收而释放。
- 静态变量随着类的加载而存在,随着类的消失而消失。
- 如果final修饰的是成员变量,可以在非静态初始化块、声明该变量或者构造器中执行初始值。
(2)修饰局部变量:
- 系统不会为局部变量进行初始化,局部变量必须由程序员显示初始化。因此使用final修饰局部变量时,即可以在定义时指定默认值(后面的代码不能对变量再赋值),也可以不指定默认值,而在后面的代码中对final变量赋初值仅一次)

(3)修饰基本类型数据和引用类型数据:
- 如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;
- 如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。但是引用的值是可变的。

2、为什么局部变量和匿名内部类访问局部变量只能访问局部**final**变量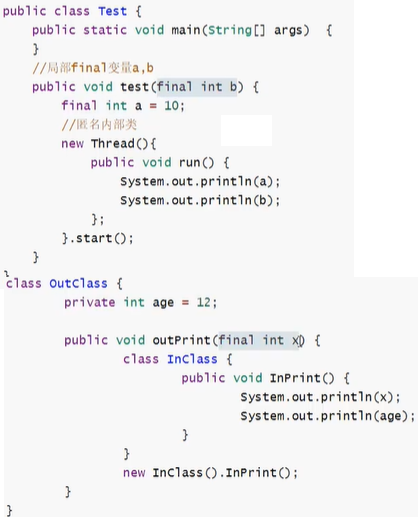
含有内部类的类编译后会有两个calss文件;
首先需要知道的一点是:内部类和外部类是处于同一个级别的,内部类不会因为定义在方法中就会随着方法的执行完毕就被销毁。
这里就会产生问题当外部类的方法结束时,局部变量就会被销毁了,但是内部类对象可能还存在(只有没有人再引用它时,才会死亡)。这里就出现了一个矛盾:内部类对象访问了一个不存在的变量。为了解决这个问题,就将局部变量复制了一份作为内部类的成员变量,这样当局部变量死亡后,内部类仍可以访问它,实际访问的是局部变量的”copy”。这样就好像延长了局部变量的生命周期;
将局部变量复制为内部类的成员变量时,必须保证这两个变量是一样的,也就是如果我们在内部类中修改了成员变量,方法中的局部变量也得跟着改变,怎么解决问题呢?
就将局部变量设置为final,对它初始化后,我就不让你再去修改这个变量,就保证了内部类的成员变量和方法的局部变量的一致性。这实际上也是一种妥协。使得局部变量与内部类内建立的拷贝保持一致。
String/StringBuffer/StringBuilder区别和使用场景
String是final修饰的,不可变,每次操作都会产生新的String对象;StringBuffer和StringBuilder都是在原对象上操作;StringBuffer是线程安全的,StringBuilder线程不安全的;StringBuffer中的方法都自动加synchronized修饰的(synchronized线程排队执行,保证线程同步);
性能∶StringBuilder>StringBuffer>String;
场景:经常需要改变字符串内容时使用后面两个;
优先使用StringBuilder,多线程使用共享变量时使用StringBuffer
重载和重写的区别
重载:发生在同一个类中,方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同,发生在编译时。【只有返回值类型不同不是重载,并且编译器还会报错】:
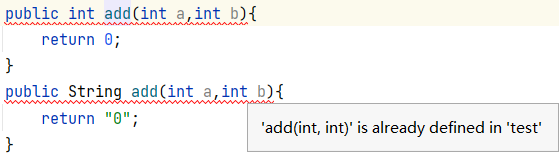
重写:发生在父子类中,方法名、参数列表必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类;如果父类方法访问修饰符为private则子类就不能重写该方法。
接口和抽象类的区别
- 抽象类可以存在普通成员函数,而接口中只能存在
public abstract方法。 - 抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是
public static final类型的。 - 对于
子类/实现类来说抽象类只能继承一个,接口可以实现多个。
接口的设计目的,是对类的行为进行约束(更准确的说是一种有约束,因为接口不能规定类不可以有什么行为),也就是提供一种机制,可以强制要求不同的类具有相同的行为。它只约束了行为的有,但不对如何实现行为进行限制。
而抽象类的设计目的,是代码复用。当不同的类具有某些相同的行为(记为行为集合A),且其中一部分行为的实现方式一致时(A的非真子集,记为B),可以让这些类都派生于一个抽象类。在这个抽象类中实现了B,避免让所有的子类来实现B,这就达到了代码复用的目的。而A减B的部分,留给各个子类自己实现。正是因为A-B在这里没有实现,所以抽象类不允许实例化出来(否则当调用到A-B时,无法执行)。

抽象类是对类本质的抽象,表达的是is a的关系,比如∶BaoMa is a Car。抽象类包含并实现子类的通用特性,将子类存在差异化的特性进行抽象,交由子类去实现。
而接口是对行为的抽象,表达的是like a的关系。比如∶Bird like a Aircraft(像飞行器一样可以飞),但其本质上is a Bird。接口的核心以是定义行为,即实现类可以做什么。至于实现类主题是谁,是如何实现的,接口并不关心。
使用场景:
- 当你关注一个事物的本质的时候,用抽象类;
- 当你关注一个操作的时候。用接口。
抽象类的功能要远超过接口,但是,定义抽象类的代价高。因为高级语言来说(从实际设计上来说也是)每个类只能继承一个类。在这个类中,你必须继承或编写出其所有子类的所有共性。虽然接口在功能上会弱化许多。但是它只是针对一个动作的描述。而且你可以在一个类中同时实现多个接口。在设计阶段会降低难度;
List和Set的区别
**List**:有序,按对象进入的顺序保存对象,可重复,允许多个null元素对象,可以使用Iterator(迭代器)取出所有元素,在逐一遍历,还可以使用get(int index)获取指定下表的元素;**Set**:无序,不可重复,最多允许有一个null元素对象,取元素时只能用Iterator接口取得所有元素,在逐一遍历各个元素;
hashCode与equals
hashCode介绍
hashCode()的作用是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode()定义在JDK的Object.java中,Java中的任何类都包含有hashCode()函数。散列表存储的是键值对(key-value),它的特点是:能根据键快速的检索出对应的值。这其中就利用到了散列码(可以快速找到所需要的对象)
为什么要有hashCode
以“HashSet如何检查重复”为例来说明为什么要有hashCode∶
对象加入HashSet时,HashSet会先计算对象的hashcode值来判断对象加入的位置,看该位置是否有值,如果没有、HashSet会假设对象没有重复出现。但是如果发现有值,这时会调用equals()【如果放的是自定义对象的话就需要自己重写**equals()**了】方法来检查两个对象是否真的相同。如果两者相同,HashSet就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。这样就大大减少了equals()的次数,相应就大大提高了执行速度。
- 两个相等的对象
hashcode值一定也是相同的; - 两个
hashcode值相同的对象,不一定相等; equals()方法被覆盖过,则hashcode方法也必须被覆盖;hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该class的两个对象无论如何都不会相等(即使这两个对象指向相同的数据);ArrayList与LinkedList**ArrayList**:基于动态数组,连续内存存储,适合下标访问(随机访问)。扩容机制:因为数组长度固定,超出长度存数据时需要新建数组,然后将老数组的数据拷贝到新数组,如果不是尾部插入数据还会涉及到元素的移动(往后复制一份,插入新元素),使用属插法并指定初始容量可以极大提升性能、甚至超过
linkedList(linkedList可能需要创建大量的node对象)
**LinkedList**:基于链表,可以存储在分散的内存中,适合做数据插入及删除操作,不适合查询;需要逐—遍历,
遍历LinkedList必须使用iterator,不能使用for循环,因为每次for循环体内通过get(i)取得某一元素时都需要对list重新进行遍历,性能消耗极大。另外不要试图使用indexOf等返回元素索引,并利用其进行遍历,使用indexlOf对list进行了遍历,当结果为空时会遍历整个列表。
ConcurrentHashMap原理
jdk7:
- 数据结构∶
ReentrantLock+Segment+HashEntry,一个Segment中包含一个HashEntry数组,每个HashEntry又是一个链表结构; - 元素查询:二次
hash,第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部; - 锁:
Segment分段锁,Segment继承了ReentrantLock,锁定操作的Segment,其他的Segment不受影响,并发度为segment个数,可以通过构造函数指定,数组扩容不会影响其他的segmentget方法无需加锁(volatile保证不会读到脏数据);
jdk8:
- 数据结构∶
synchronized+CAS(即乐观锁check-and-set)+Node+红黑树,Node的val和next都用volatile修饰,保证可见性查找,替换,赋值操作都使用CAS; - 锁∶ 锁链表的
head节点,不影响其他元素的读写,锁粒度更细,效率更高,扩容时,阻塞所有的读写操作、并发扩容 - 读操作无锁:
Node的val和next使用volatile修饰,读写线程对该变量互相可见数组用volatile修饰,保证扩容时被读线程感知;如何实现一个
IOC容器
- 配置文件配置包扫描路径;
- 递归包扫描获取
.class文件; - 反射、确定需要交给IOC管理的类;
- 对需要注入的类进行依赖注入;
- 配置文件中指定需要扫描的包路径;
- 定义一些注解,分别表示访问控制层、业务服务层、数据持久层、依赖注入注解、获取配置文件注解;
- 从配置文件中获取需要扫描的包路径,获取到当前路径下的文件信息及文件夹信息,我们将当前路径下所有以
.class结尾的文件添加到一个**Set**集合中进行存储; - 遍历这个
**set**集合,获取在类上有指定注解的类,并将其交给IOC容器,定义一个安全的Map用来存储这些对象; 遍历这个IOC容器,获取到每一个类的实例,判断里面是有有依赖其他的类的实例,然后进行递归注入;
java类加载器有哪些
JDK自带有三个类加载器:
bootstrap ClassLoader、IExtClassLoader、AppClassLoader。BootStrapClassLoader是ExtClassLoader的父类加载器,默认负责加载%JAVA_HOME%``lib下的jar包和class文件。ExtClassLoader是AppClassLoader的父类加载器,负责加载%JAVA_HOME%/lib/ext文件夹下的jar包和class类。AppClassLoader(系统类加载器,线程上下文加载器)是自定义类加载器的父类,负责加载classpath下的类文件。实现自定义类加载器需要继承ClassLoader;
其余内容wps中保存有**《210道面试题》**;

若有收获,就点个赞吧
0 人点赞
