我们在上一篇文章已经探索了数组的顺序存储和链式存储,而接下来我们就需要正式开始回顾链表这一十分重要的概念了。链表实际上分为四大类,分别是单链表,单向循环链表,双向链表,双向循环链表。
那么显然,单链表的实现我们已经回顾过了,所以本文主要是围绕着单向循环链表来进行分析。
单向循环链表的定义
单链表我们都清楚定义,头结点指向首元结点,尾结点指向空。但是对于单向循环链表来说,尾结点需要指向头结点。我们在上一篇文章里使用到了头结点来辅助我们对单链表的插入,删除等一系列操作。而对于单向循环链表来说,可以选择不带头结点来实现。关于使用头结点的原因可以总结为以下两点:
- 便于首元结点处理
- 便于空表和非空表的统一处理
本文将采取两种不同的方式来进行分析总结。
单向循环链表的结构并不复杂,通过下面的图片我们可以直观的看出尾结点是指向的头结点。
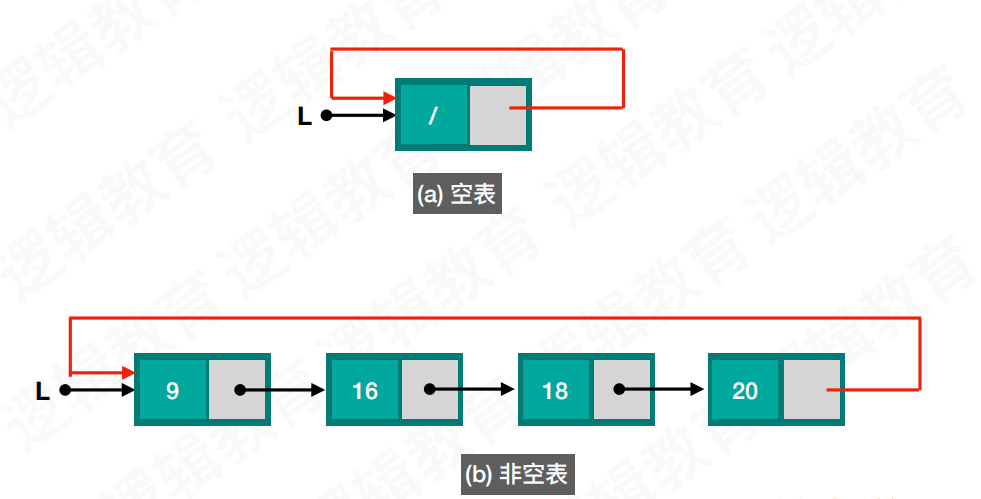
不带头结点的单向循环链表的实现
链表数据结构定义
单向循环链表在结构上和单向链表并无区别,如下所示:
// 单向循环链表节点typedef struct Node {// 数据域ElemType data;// 指针域struct Node *next;}Node;// 单向循环链表结构体指针typedef struct Node *LinkList;
初始化单向循环链表
因为我们现在是讨论的不带头节点的单向循环链表,所以首元节点就是第一个节点。那么在初始化的时候就需要分两种情况。
一种情况是创建首元节点,将数据赋值给首元节点的数据域,然后将首元节点的后继指针指向首元节点本身;
第二种情况是在首元节点之后插入节点,那么就需要新建一个节点,赋值好数据域,接着需要找到待插入的位置。
这里又分为两种方式。
一种是遍历链表到尾节点,将新建的节点插入到尾节点,然后将新建的节点的后继指针指向首元节点;
第二种方式是在最开始声明一个尾节点指针,在首元节点初始化的时候将尾节点指针指向首元节点,然后在后续的插入节点的时候,将尾指针指向的节点的后继指针指向新建的节点,然后让新建的节点的后继指针指向首元节点。最后把尾节点指针指向新建的节点即可。
Status CreateList(LinkList *L)
{
LinkList temp,target;
int num;
printf("输入结点的值,输入0结束\n");
while(1)
{
scanf("%d", &num);
if (num == 0) break;
if (*L == NULL)
{
*L = (LinkList)malloc(sizeof(Node));
if (*L == NULL) return ERROR;
*L->data = num;
*L->next = *L;
}
else
{
for(target=(*L);target->next != *L;target=target->next);
temp = (LinkList)malloc(sizeof(Node));
if (temp == NULL) return ERROR;
temp->data = num;
target->next = temp;
temp->next = *L;
}
}
return OK;
}
Status CreateList2(LinkList *L)
{
LinkList temp,tail;
int num;
printf("输入结点的值,输入0结束\n");
while(1)
{
scanf("%d", &num);
if (num == 0) break;
if (*L == NULL)
{
*L = (LinkList)malloc(sizeof(Node));
if (*L == NULL) return ERROR;
*L->data = num;
*L->next = *L;
tail = *L;
}
else
{
temp = (LinkList)malloc(sizeof(Node));
if (temp == NULL) return ERROR;
temp->data = num;
tail->next = temp;
temp->next = *L;
tail = temp;
}
}
return OK;
}
单向循环链表的插入
我们在之前实现单向循环链表的插入的时候,因为有头节点的存在,使得我们的插入操作只需要找到一个合法的待插入位置插入即可,并不需要做额外的位置上下边界判断。那么,对于不带头节点的单向循环链表来说,是否需要额外判断一些边界情况呢?
我们分析一下,在不带头节点的单向循环链表中插入新节点不外乎三种情况。
- 在首元节点之前插入新节点
- 在首元节点和尾节点之间插入新节点
- 在尾节点后面插入新节点
1.在首元节点之前插入新节点
这种情况下的插入位置显然不需要去通过遍历来得到,但是有一个重点就是要让尾节点的后继指针指向新的首元节点。
2.在首元节点和尾节点之间插入新节点
这种情况需要先通过遍历得到待插入节点的前一个节点,然后就是让新节点指向前一个节点后继指针指向的节点,然后让前一个节点指向新节点即可。
3.在尾节点后面插入新节点
乍一看这种情况貌似要比情况二特殊,因为要改变尾节点的后继指针的指向。但其实我们分析一下,我们在这种情况下也需要先找到待插入节点的前一个节点,也就是尾节点,然后让新节点指向尾节点的后继指针指向的节点,也就是首元节点。然后让原来的尾节点指向新节点。其实这么一分析,我们就可以发现情况二和情况三的处理步骤是一模模一样样的。
所以实际上这里只需要分为两种情况来判断即可,即在首元节点之前插入和在首元节点之后插入。
我们话不多说,直接上代码吧。
Status ListInsert(LinkList *L, int place, int num)
{
LinkList temp,target;
int i = 1;
if (place == 1)
{
// 在首元节点之前插入
temp = (LinkList)malloc(sizeof(Node));
if (temp == NULL) return ERROR;
temp->data = num;
// 遍历找到尾节点
for (target = *L;target->next != *L;target=target->next);
temp->next = *L;
*L = temp;
target->next = *L;
}
else
{
// 在首元节点之后插入
temp = (LinkList)malloc(sizeof(Node));
if (temp == NULL) return ERROR;
temp->data = num;
// 遍历找到待插入位置的前一个节点
// 这里之所以是不等于 place - 1,是因为在 while 循环内部只会循环待插入位置的前一个位置减一次
target = *L;
while(target->next != NULL && i != place - 1)
{
target = target->next;
i++;
}
temp->next = target->next;
target->next = temp;
}
return OK;
}
单向循环链表的删除
删除其实和插入很类似,也只需要分删除首元节点和删除非首元节点两种情况。
- 删除首元节点
声明一个临时节点指向首元节点,然后让链表指针指向首元节点的后继节点,接着遍历找到尾节点,让尾节点指向新的首元节点,最后释放掉原来的首元节点。
- 删除非首元节点
通过遍历找到待删除节点的前一个节点,然后让临时节点指向待删除节点,然后让前一个节点指向待删除节点的后一个节点,最后释放掉待删除节点。
Status ListDelete(LinkList *L, int place, ElemType *e)
{
LinkList target,temp;
int i;
if (place == 1)
{
temp = *L;
*L = temp->next;
for(target = *L;target->next != *L;target=target->next);
target->next = *L;
*e = temp->data;
free(temp);
}
else
{
for(i = 1,target = *L;target->next != *L && i != place - 1;target=target->next, i++);
temp = target->next;
target->next = temp->next;
*e = temp->data;
free(temp);
}
return OK;
}
单向循环链表的遍历
遍历单向循环链表的话比较简单,只需要从首元节点开始遍历到某个节点的后即指针为首元节点为止。但是这里有个细节,因为首元节点就是链表中的第一个节点,所以需要在循环开始前先执行一次打印。
Status ListTraverse(LinkList L)
{
LinkList p = L;
do {
printf("%5d", p->data);
p = p->next;
} while (p != L);
return OK;
}
单向循环链表的查询
对于单向循环链表的查询,只需要明确遍历的条件即可。在遍历完成后还需要判断没有找到的情况。
int findValue(LinkList L, int value)
{
int i = 1;
LinkList p = L;
int tempValue = p->data;
while(p->next != L && p->data != value)
{
p = p->next;
i++;
}
if (p->next == L && p->data != value) return -1;
return i;
}
带头节点的单向循环链表的实现
分析完了不带头节点的情况,我们再分析带头节点的单向循环链表。
链表数据结构定义
首先还是基础的数据结构的定义,这一块没什么多说的,还是一样的配方。
// 单向循环链表节点
typedef struct Node {
// 数据域
ElemType data;
// 指针域
struct Node *next;
}Node;
// 单向循环链表结构体指针
typedef struct Node *LinkList;
初始化带头节点的单向循环链表
接着是初始化,因为有头节点的存在,所以首元节点就不是链表中的第一个节点了。那么也就无需判断首元节点的特殊情况了,也就是说只有插入的情况,我们直接上代码。
Status CreateList(LinkList *L)
{
LinkList target,temp;
int num;
// 先创建空的头节点
*L = (LinkList)malloc(sizeof(Node));
if (*L == NULL) return ERROR;
(*L)->next = *L;
printf("输入结点的值,输入0结束\n");
while(1)
{
scanf("%d", &num);
if (num == 0) break;
temp = (LinkList)malloc(sizeof(Node));
if (temp == NULL) return ERROR;
temp->data = num;
// 找到尾节点
for(target=*L;target->next != *L;target=target->next);
temp->next = target->next;
target->next = temp;
}
return OK;
}
同样的,我们还是采用一个尾指针来实现插入:
Status CreateList(LinkList *L)
{
LinkList tail,temp;
int num;
// 先创建空的头节点
*L = (LinkList)malloc(sizeof(Node));
if (*L == NULL) return ERROR;
(*L)->next = *L;
tail = *L;
printf("输入结点的值,输入0结束\n");
while(1)
{
scanf("%d", &num);
if (num == 0) break;
temp = (LinkList)malloc(sizeof(Node));
if (temp == NULL) return ERROR;
temp->data = num;
tail->next = temp;
temp->next = *L;
tail = temp;
}
return OK;
}
带头节点的单向循环链表的插入
对于插入操作来说,还是需要判断插入的位置是否是首元节点,不过我们并不需要改变尾节点的后继指针的指向,因为头结点一直没有变,只有首元节点可能会发生改变。
// 单向循环链表的插入
Status ListInsert(LinkList *L, int place, int num)
{
LinkList temp, target;
int i;
if (place == 1)
{
// 插入的位置刚好是首元节点的位置
// 1.创建 temp 成功与否
temp = (LinkList)malloc(sizeof(Node));
if (!temp) return ERROR;
temp->data = num;
// 2.因为我们现在是带头结点的
// 所以并不需要去改变尾节点的指向
// 让新的结点的后继指针指向原来的首元节点
temp->next = (*L)->next;
// 让头结点的后继指针指向新的首元节点
(*L)->next = temp;
}
else
{
// 插入的位置是首元节点之后的位置
// 1.创建temp,成功与否
temp = (LinkList)malloc(sizeof(Node));
if (!temp) return ERROR;
temp->data = num;
// 2.找到插入的前一个位置 target
for(i = 1, target = (*L)->next;target->next != *L && i != place - 1;target = target -> next,i++);
// 让新节点的后继指针指向 target 后继指针指向的节点
temp->next = target->next;
// 让 target 后继指针指向新的节点
target->next = temp;
}
return OK;
}
带头节点的单向循环链表的删除
同样的,对于删除操作来说,也不需要判断要删除的是否是首元节点,上代码。
// 单向循环链表的删除
Status ListDelete(LinkList *L, int place)
{
LinkList temp,target;
int i;
// 如果首元节点为空,则删除没有意义,返回 ERROR
temp = (*L)->next;
if (temp == NULL) return ERROR;
if (place == 1)
{
// 如果删除的是首元节点
// 只需要取出首元节点,然后让头结点的后继指针指向首元节点的后继指针指向的节点
temp = (*L)->next;
(*L)->next = temp->next;
free(temp);
}
else
{
// 2.删除其他位置
/**
1.删除位置的前一个位置 target
2.temp = target->next;
3.target->next = temp->next;
4.free(temp);
*/
for (i = 1, target = (*L)->next;target->next!=*L && i != place - 1;target = target->next, i++);
temp = target->next;
target->next = temp->next;
free(temp);
}
return OK;
}
带头节点的单向循环链表的遍历
遍历的话只需要将初始的节点设为首元节点即可。
Status show(LinkList L)
{
// 获取到首元节点
LinkList temp = L->next;
// 从首元节点开始遍历,当遍历到尾节点时结束
do {
printf("%5d", temp->data);
temp = temp->next;
} while (temp != L);
printf("\n");
return OK;
}
带头节点的单向循环链表的查询
同样的,查询也是如此。
int findValue(LinkList L, int value)
{
int i = 1;
LinkList temp = L->next;
while (temp->next != L && temp->data != value)
{
temp = temp->next;
i++;
}
// 如果找到尾节点还没有找到,返回 -1
if (temp->next == L && temp->data != value) return -1;
return i;
}
总结
今天我们一起探索了单向循环链表的创建,插入,删除,查询和遍历。我们还分析了带头结点和不带头结点的两种情况。可以看到,在单向循环链表的场景下,有无头节点并没有显著减少判断的逻辑。所以在使用单向循环链表的时候,可以选择不带头节点。

若有收获,就点个赞吧
0 人点赞
