1、使用用户正向投票
基于用户正向投票数:按照单位时间内用户对内容的正向投票的绝对值,对内容进行降序排列。
优点:简单,每次跟新排名迅速
缺点:统计周期内的热门内容持续”霸榜”,而在下一个周期可能会一落千丈
2、引入连续时间衰减系数
Hacker News是一个网络社区,可以张贴链接,也可以讨论某个主题。它的排名策略同时考考虑用户正向投票数和时间因素。

- P:帖子得票数,P-1表示忽略发帖人的票数
- T:表示发帖的时间(单位为小时)。T+2可能是因为原始文章转贴到Hacker News平均需要两个小时,所以+2还原最新帖子的实际发生时间。
- G:表示重力因子(G>1),即将帖子排名往下拉的力量
从上面公式看出:
1、帖子的票数P-1越多,内容的排名得分越高。也可以在这个项上增加指数变成 ,通过增加或减小的来控制得票数对最终分数的影响。
,通过增加或减小的来控制得票数对最终分数的影响。
2、随着发帖时间T+2的增长,内容排名得分减小。指数G是用来调节发帖时间增长对排名得分的影响。通过调整G的大小,保证即使是热点新闻事件也会在设定的曝光时长之后,平滑的退出排行榜首页。
投票数对排名的影响:
plot(
(30 - 1) / (t + 2)^1.8,
(60 - 1) / (t + 2)^1.8,
(200 - 1) / (t + 2)^1.8
) where t=0..24
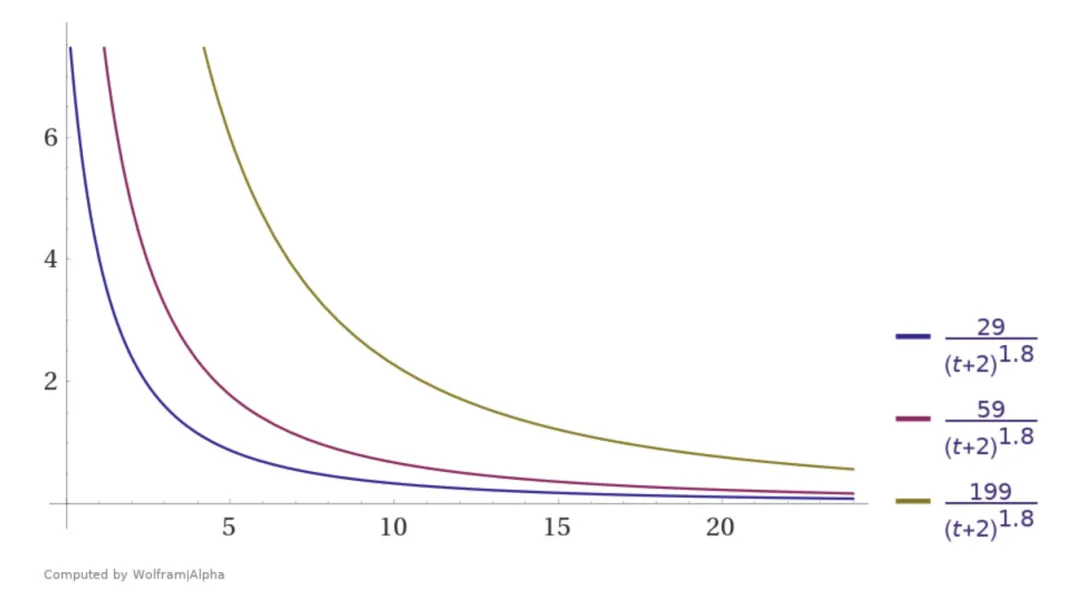
由图可以看出随着时间t的增大,投票数的大小对最终的得分影响不大。
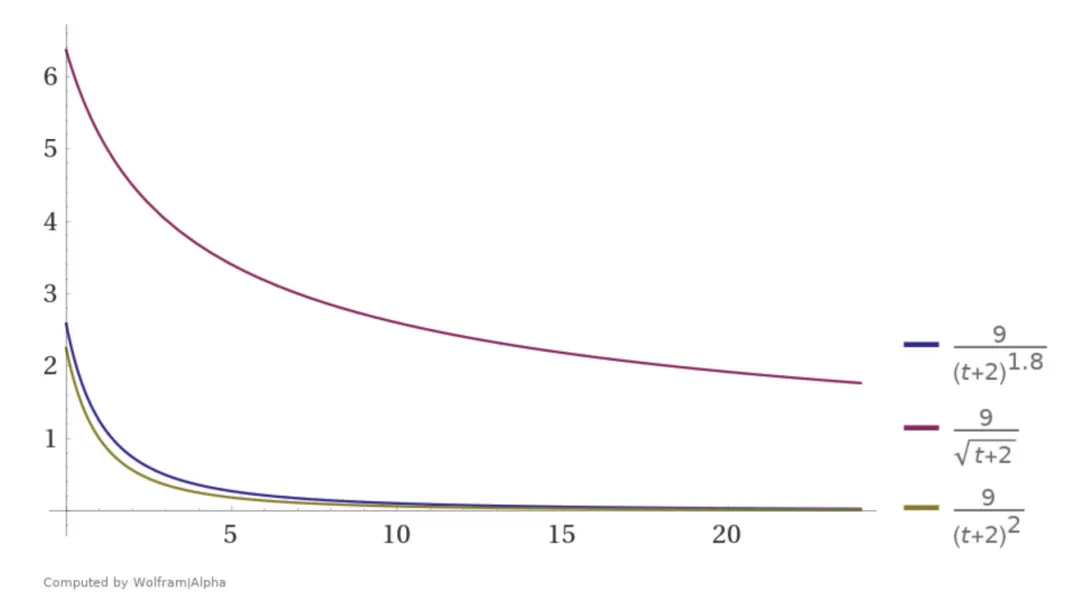
重力因子G
plot(
(p - 1) / (t + 2)^1.8,
(p - 1) / (t + 2)^0.5,
(p - 1) / (t + 2)^2.0
) where t=0..24, p=10
3、引入反对票
Reddit 同时考虑赞成和反对票,并通过时间信息来加强这一点 (y=-1,0,1)
(y=-1,0,1)
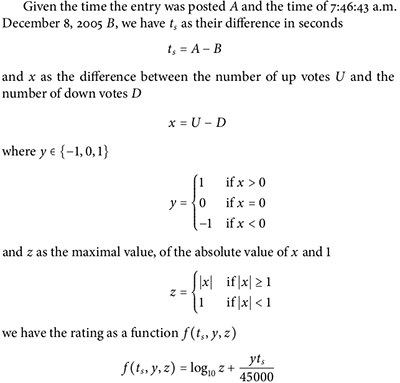
cpdef double _hot(long ups, long downs, double date):
"""
The hot formula. Should match the equivalent function in postgres.
"""
s = score(ups, downs) # 赞成票和反对票的差 x
order = log10(max(abs(s), 1)) # 受肯定、否定的程度 z
if s > 0: # 投票倾向sign, y
sign = 1
elif s < 0:
sign = -1
else:
sign = 0
seconds = date - 1134028003 # 文章新旧程度 t
return round(sign * order + seconds / 45000, 7) # 45000等于12.5小时
对数部分:
- z表示,abs(赞成票-反对票)。
- 这里用的是以10为底的对数,z=10可以得到1分,z=100可以得到2分。这意味着前z=10分和后来z=90分(乃至后面的z=900分)会产生相同的权重。即第一次的”种子投票”会对得分产生重大影响,越往后投票贡献的力量越小。这样可以保证即使是新文章也可以迅速获得分数、得到曝光;但同时不会产生某个文章突然爆红的现象,
分数部分:
- t越大,得分越高:新文章得分会高于老文章
- 分母45000秒,等于12.5个小时。即新帖比25小时前的文章自动高2分。结合对数部分,如果旧文章想在25小时继续保持原先的分数,在25小时内他的z值必须增加100倍。
- y 的作用是决定加分或减分。天然的让得到大量净赞成票的文章排名靠前,赞成票与反对票接近或相等的文章其次,得到净反对票的文章会排在最后。
4、更加泛化的牛顿冷却定律
这是一个更一般的数学模型。我们可以把”热文排名”想象成一个自然冷却的过程:
任一时刻,网站中所有的文章,都有一个“当前温度”,温度最高的文章排在最前面。
如果一个用户对某篇文章投了赞成票(评论或者其他的操作),改文章的温度就上升一度
随着时间的流逝,所有文章的温度都逐渐“冷却”,而且冷却的速度和当前的温度-初始温度的差值成正比

求解微分后,得到:
如果H=0,那么公式为:
将这个公式用在“排名算法”,就相当于:
如果假定一篇新文章的初始分数为100分,24小时以后“冷却”为1分,那么可以计算得到“冷却系数”约等于0.192
简答来说,如果选择牛顿冷却,需要以下几步:
- 设定新文章的初始温度
- 设定冷却速度
- 设定温度增加I的方式
- 当某项有赞成票时,触发并重新计算当前温度,并记录当前时间
- 使用以上公式根据当前温度对项目进行排序
5、引入文章评论、浏览对文章排名的影响
Stack Overflow 引入了文章评论对问题热度热度排名的影响[3]。一旦有人回答了某个问题,其他人可以对这个回答投票(赞成或者反对),以表明对这个回答的态度。通过评论也可以找出某个时间段内热点的问题:即哪些问题最被关注、得到了最多的讨论。
Stack Overflow网站
问题的浏览次数Qviews:以10为底的对数;10得一分、100得俩分,即后来者影响力变小
Qscore = 赞成票-反对票。如果某个问题越收到好评,排名自然应该靠前
Qanswers表示回答的数量,代表有多少人参与这个问题。这个值越大,得分将成倍放大。Qanswers等于0,这时Qscore得分再高也没有用,意味着再好的问题,也必须有人回答,否则就进不了热点问题排行榜。
回答得分Ascores:“回答”比“问题”更有意义。得分越高,代表回答的质量越高。
距离问题发表的时间Qage和距离最后一个回答的时间Qupdated,单位是秒。随着时间流逝,这俩个值都会越变越大,导致分母增大,因此总得分会越来越小。
Stack Overflow 热点问题的排名,与参与度(Qviews和Qanswers)和质量(Qscore和Ascores)成正比,与时间(Qage和Qupdated)成正比
方法对比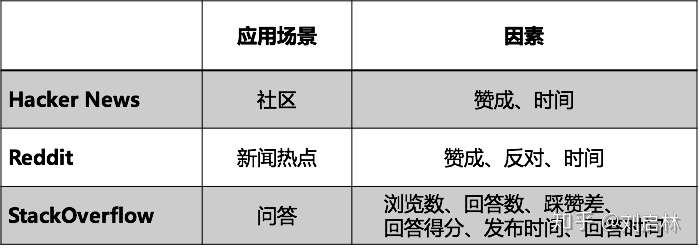
参考
1、贝壳找房 | 基于内容热度的推荐
2.Reddit 排名算法工作原理(https://www.aqee.net/post/how-reddit-ranking-algorithms-work.html)
3.What formula should be used to determine “hot” questions?(https://meta.stackexchange.com/questions/11602/what-formula-should-be-used-to-determine-hot-questions)
4、冷却系数的计算https://zhuanlan.zhihu.com/p/80884372
5、http://www.woshipm.com/pmd/723735.html
6、https://www.6aiq.com/article/1602588064973
7、产品经理需要了解的算法——热度算法和个性化推荐(http://www.woshipm.com/pmd/723735.html)
8、今日头条算法原理(全)
9、人民网二评算法推荐:别被算法困在“信息茧房”(http://opinion.people.com.cn/n1/2017/0919/c1003-29544724.html)
10、置信区间是什么https://www.cnblogs.com/garfieldcgf/p/11990139.html

若有收获,就点个赞吧
0 人点赞
