概况
技术选型
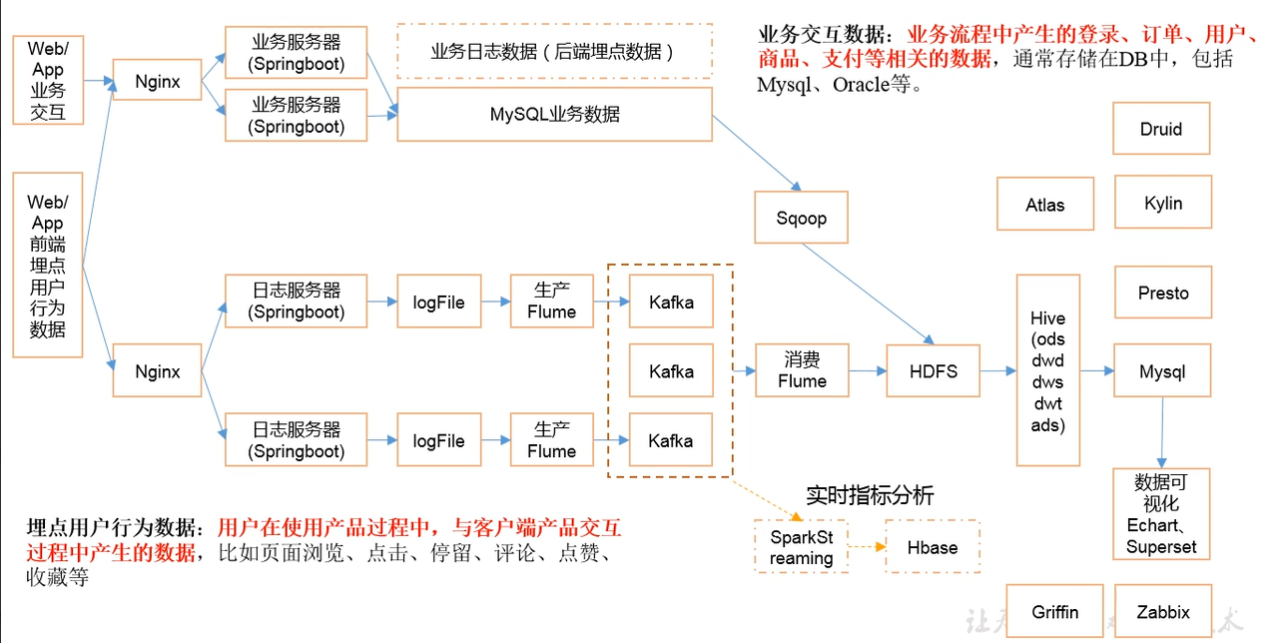
服务器规划
| 服务名称 | 子服务 | hadoop102 | hadoop103 | hadoop104 |
|---|---|---|---|---|
| HDFS | NameNode | + | ||
| HDFS | DataNode | + | + | + |
| HDFS | SecondaryNameNode | + | ||
| Yarn | NodeManager | + | + | + |
| Yarn | ResourceManager | + | ||
| Zookeeper | Zookeeper Server | + | + | + |
| Flume(日志) | Flume | + | + | |
| Kafka | Kafka | + | + | + |
| Flume(消费) | Flume | + | ||
| Hive | Hive | + | ||
| MySQL | MySQL | + | ||
| Sqoop | Sqoop | + | ||
| Presto | Coordinator | + | ||
| Presto | Worker | + | + | |
| Azkaban | Azkaban WebServer | + | ||
| Azkaban | AzkabanExecutorServer | + | ||
| Druid | Druid | + | + | + |
| Kylin | + | |||
| HBase | HMaster | + | ||
| HBase | HRegionServer | + | + | + |
| Superset | + | |||
| Atlas | + | |||
| Solr | Jar | + | ||
| Griffin | + |
准备工作
先搭建好集群,确保hadoop各个模块可以启动。
安装LZO
下载包hadoop-lzo-0.4.20.jar,放在/opt/module/hadoop-2.8.2/share/hadoop/common目录下,然后用脚本分发到103、104 。
[root@hadoop102 common]# xsync hadoop-lzo-0.4.20.jar
core-site.xml 增加配置支持 LZO 压缩
[root@hadoop103 hadoop-2.8.2]# cd etc/hadoop/[root@hadoop103 hadoop]# vim core-site.xml
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>io.compression.codecs</name><value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec,com.hadoop.compression.lzo.LzoCodec,com.hadoop.compression.lzo.LzopCodec</value></property><property><name>io.compression.codec.lzo.class</name><value>com.hadoop.compression.lzo.LzoCodec</value></property></configuration>
分发
[root@hadoop102 hadoop]# xsync core-site.xml
真正使用时还需要对上传文件创建索引
[root@hadoop102 module]# hadoop jar /opt/module/hadoop-2.8.2/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /input/filename.lzo
其中,/input是hdfs中文件所在目录。
参数调优
NameNode 有一个工作线程池,用来处理不同 DataNode 的并发心跳以及客户端并发 的元数据操作。 对于大集群或者有大量客户端的集群来说,通常需要增大参数。
dfs.namenode.handler.count 的默认值10,当参数值为20*math.log(n)时最优,n是机器的台数。
修改hdfs-site.xml
<property><name>dfs.namenode.handler.count</name><value>21</value></property>
安装Zookeeper
详见Zookeeper,这里主要介绍Zookeeper的集群启动脚本,脚本一般存放在102的/root/bin目录下。
脚本如下
#! /bin/bashcase $1 in"start"){for i in hadoop102 hadoop103 hadoop104dossh $i "/opt/module/zookeeper-3.4.10/bin/zkServer.sh start"done};;"stop"){for i in hadoop102 hadoop103 hadoop104dossh $i "/opt/module/zookeeper-3.4.10/bin/zkServer.sh stop"done};;"status"){for i in hadoop102 hadoop103 hadoop104dossh $i "/opt/module/zookeeper-3.4.10/bin/zkServer.sh status"done};;esac
之后给与权限
[root@hadoop102 bin]# chmod 777 zk.sh
日志生成
将日志包log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar拷贝到102和103上。
执行java命令,打印日志到指定文件
[root@hadoop104 module]# java -classpath log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar com.atguigu.appclient.AppMain >/opt/module/test.log
也可以不输出
[root@hadoop102 module]# java -classpath log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar com.atguigu.appclient.AppMain 1>/dev/null 2>/dev/null
这里/dev/null是黑洞,所有进入的内容都会消失。
- 标准输入 0:从键盘获得输入 /proc/self/fd/0
- 标准输出 1:输出到屏幕(即控制台) /proc/self/fd/1
- 错误输出 2:输出到屏幕(即控制台) /proc/self/fd/2
最后,在/tmp/log目录下可以看到日志。
下面写日志集群脚本lg.sh,脚本在/root/bin目录下
for i in hadoop102 hadoop103doecho ---------------$i生成日志---------------ssh $i "java -classpath /opt/module/log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar com.atguigu.appclient.AppMain $1 $2 >/dev/null 2>&1 &"done
授权
[root@hadoop102 bin]# chmod 777 lg.sh
时间同步
时间同步脚本dt.sh
#! /bin/bashfor i in hadoop102 hadoop103 hadoop104doecho ---------------$i同步时间---------------ssh $i "sudo date -s $1"done
授权
[root@hadoop102 bin]# chmod 777 dt.sh
Linux环境变量
Linux有两种Shell,登录式和非登录式(SSH连接)。登录式会自动加载/etc/profile,非登录式会自动加载~/.bashrc
/etc/profile里面的环境变量是对系统内所有用户有效,~/.bashrc只对某一特定用户有效。
所以,要把/etc/profile的环境变量追加到~/.bashrc确保SSH访问时不会出错。
[root@hadoop102 ~]# cat /etc/profile >> ~/.bashrc[root@hadoop103 ~]# cat /etc/profile >> ~/.bashrc[root@hadoop104 ~]# cat /etc/profile >> ~/.bashrc
状态查询脚本
统一查询状态
#! /bin/bashfor i in hadoop102 hadoop103 hadoop104doecho ---------------$i状态查询---------------ssh $i "$*"done
安装Flume(日志)
采集日志的Flume安装在102、103上,104后面安装消费Flume。
安装包解压缩后,修改flume-env.sh.template文件名称为flume-env.sh,文件路径在/opt/module/flume-1.7.0/conf下
[root@hadoop102 conf]# mv flume-env.sh.template flume-env.sh
然后修改flume-env.sh文件的JAVA_HOME。
再同步分发到103、104(这里也要,后面104也要上flume),这样就安装完成。
Flume有两个组件Source、Channel
- Source:包括Taildir Source、Exec Source、Spooling Source,这里使用Taildir Source,Taildir Source可以断点续传、多目录。
- Channel:这里采用Kafka Channel,省去了Sink,提高了效率。
下面是具体配置,配置目录在/opt/module/flume-1.7.0/conf,新建file-flume-kafka.conf文件,名字可以自定义(见名知意即可)。
a1.sources=r1 #组件定义a1.channels=c1 c2#configure sourcea1.sources.r1.type = TAILDIR #taildir方式读数据a1.sources.r1.positionFile = /opt/module/flume-1.7.0/test/log_position.json #记录日志读取位置a1.sources.r1.filegroups = f1a1.sources.r1.filegroups.f1 = /tmp/logs/app.+ #读取日志位置a1.sources.r1.fileHeader = truea1.sources.r1.channels = c1 c2#interceptora1.sources.r1.interceptors = i1 i2a1.sources.r1.interceptors.i1.type = com.hxr.flume.interceptor.LogETLInterceptor$Builder #ETL拦截器a1.sources.r1.interceptors.i2.type = com.hxr.flume.interceptor.LogTypeInterceptor$Builder #日志类型拦截器a1.sources.r1.selector.type=multiplexing #根据日志类型分数据a1.sources.r1.selector.header=topica1.sources.r1.selector.mapping.topic_start=c1a1.sources.r1.selector.mapping.topic_event=c2#configure channela1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannela1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092a1.channels.c1.kafka.topic = topic_start #start类型的发往c1a1.channels.c1.parseAsFlumeEvent=falsea1.channels.c1.kafka.consumer.group.id = flume-consumera1.channels.c2.type = org.apache.flume.channel.kafka.KafkaChannela1.channels.c2.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092a1.channels.c2.kafka.topic = topic_event #event类型的发往c2a1.channels.c2.parseAsFlumeEvent=falsea1.channels.c2.kafka.consumer.group.id = flume-consumer
将配置分发到103、104上。
下面接着实现拦截器,拦截器打包后放在/flume-1.7.0/lib目录下,然后分发到103、104。
在102、103上打开Flume
[root@hadoop102 flume-1.7.0]# bin/flume-ng agent --name a1 --conf-file conf/file-flume-kafka.conf &[root@hadoop103 flume-1.7.0]# bin/flume-ng agent --name a1 --conf-file conf/file-flume-kafka.conf &
为了快速启动多台服务器,可以使用脚本
#! /bin/bashcase $1 in"start"){for i in hadoop102 hadoop103doecho ---------------启动$i采集flume---------------ssh $i "nohup /opt/module/flume-1.7.0/bin/flume-ng agent --name a1 --conf-file /opt/module/flume-1.7.0/conf/file-flume-kafka.conf-Dflume.root.logger=INFO,LOGFILE >/opt/module/flume-1.7.0/test1 2>1 &"done};;"stop"){for i in hadoop102 hadoop103doecho ---------------停止$i采集flume---------------ssh $i "ps -ef | grep file-flume-kafka | grep -v grep | awk '{print $2}' | xargs kill"done};;esac
安装Kafka
安装包解压后。
创建logs文件夹
[root@hadoop102 kafka_2.11]# mkdir logs
修改配置文件
[root@hadoop102 kafka_2.11]# cd config/[root@hadoop102 config]# vim server.properties
在配置文件里修改broker.id(每台机器不能重复)、log.dirs(日志路径是刚才创建的logs)、Zookeeper连接
broker.id=0delete.topic.enable=true #可以删除,而不是标记删除log.dirs=/opt/module/kafka_2.11/logszookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181
配置环境变量,将kafka安装目录配置到/etc/profile中
#KAFKA_HOMEexport KAFKA_HOME=/opt/module/kafka_2.11export PATH=$PATH:$KAFKA_HOME/bin
执行source命令使其生效
[root@hadoop102 module]# source /etc/profile
然后分发安装好的Kafka和profile。
然后到103、104修改配置文件里面的broker.id。
启动kafka
[root@hadoop102 kafka_2.11]# bin/kafka-server-start.sh config/server.properties &[root@hadoop103 kafka_2.11]# bin/kafka-server-start.sh config/server.properties &[root@hadoop104 kafka_2.11]# bin/kafka-server-start.sh config/server.properties &
停止kafka
bin/kafka-server-stop.sh
使用脚本
#! /bin/bashcase $1 in"start"){for i in hadoop102 hadoop103 hadoop104doecho ---------------$i启动kafka---------------ssh $i "/opt/module/kafka_2.11/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.11/config/server.properties"done};;"stop"){for i in hadoop102 hadoop103 hadoop104doecho ---------------$i停止kafka---------------ssh $i "/opt/module/kafka_2.11/bin/kafka-server-stop.sh"done};;esac
记得给脚本授权。
接着打通kafka的使用通道。
创建kafka topic
[root@hadoop102 kafka_2.11]# bin/kafka-topics.sh --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181 --create --replication-factor 1 --partitions 1 --topic topic_start[root@hadoop102 kafka_2.11]# bin/kafka-topics.sh --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181 --create --replication-factor 1 --partitions 1 --topic topic_event
查看topic列表
[root@hadoop102 kafka_2.11]# bin/kafka-topics.sh --zookeeper hadoop102:2181 --list
需要的话可以通过下面的命令删除
[root@hadoop102 kafka_2.11]# bin/kafka-topics.sh --delete --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181 --topic topic_start[root@hadoop102 kafka_2.11]# bin/kafka-topics.sh --delete --zookeeper hadoop102:2181,hadoop103:2181,hadoop104:2181 --topic topic_event
生产消息
[root@hadoop102 kafka_2.11]# bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic topic_start
消费消息
[root@hadoop102 kafka_2.11]# bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic topic_start
kafka producer压力测试
[root@hadoop102 kafka_2.11]# bin/kafka-producer-perf-test.sh --topic test --record-size 100 --num-records 100000 --throughput -1 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
kafak consumer压力测试
[root@hadoop102 kafka_2.11]# bin/kafka-consumer-perf-test.sh --zookeeper hadoop102:2181 --topic test --fetch-size 10000 --messages 10000000 --threads 1
Flume消费
在104的/opt/module/flume-1.7.0/conf目录下创建kafka-flume-hdfs.conf文件,内容如下
## 组件a1.sources=r1 r2a1.channels=c1 c2a1.sinks=k1 k2## source1a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSourcea1.sources.r1.batchSize = 5000a1.sources.r1.batchDurationMillis = 2000a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092a1.sources.r1.kafka.topics=topic_start## source2a1.sources.r2.type = org.apache.flume.source.kafka.KafkaSourcea1.sources.r2.batchSize = 5000a1.sources.r2.batchDurationMillis = 2000a1.sources.r2.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092a1.sources.r2.kafka.topics=topic_event## channel1a1.channels.c1.type = filea1.channels.c1.checkpointDir = /opt/module/flume-1.7.0/checkpoint/behavior1a1.channels.c1.dataDirs = /opt/module/flume-1.7.0/data/behavior1/a1.channels.c1.keep-alive = 6## channel2a1.channels.c2.type = filea1.channels.c2.checkpointDir = /opt/module/flume-1.7.0/checkpoint/behavior2a1.channels.c2.dataDirs = /opt/module/flume-1.7.0/data/behavior2/a1.channels.c2.keep-alive = 6## sink1a1.sinks.k1.type = hdfsa1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_start/%Y-%m-%da1.sinks.k1.hdfs.filePrefix = logstart-##sink2a1.sinks.k2.type = hdfsa1.sinks.k2.hdfs.path = /origin_data/gmall/log/topic_event/%Y-%m-%da1.sinks.k2.hdfs.filePrefix = logevent-## 不要产生大量小文件,生产环境 rollInterval 配置为 3600a1.sinks.k1.hdfs.rollInterval = 10a1.sinks.k1.hdfs.rollSize = 134217728a1.sinks.k1.hdfs.rollCount = 0a1.sinks.k2.hdfs.rollInterval = 10a1.sinks.k2.hdfs.rollSize = 134217728a1.sinks.k2.hdfs.rollCount = 0## 控制输出文件是原生文件a1.sinks.k1.hdfs.fileType = CompressedStreama1.sinks.k2.hdfs.fileType = CompressedStreama1.sinks.k1.hdfs.codeC = lzopa1.sinks.k2.hdfs.codeC = lzop## 拼装a1.sources.r1.channels = c1a1.sinks.k1.channel= c1a1.sources.r2.channels = c2a1.sinks.k2.channel= c2
写启动脚本f2.sh
#! /bin/bashcase $1 in"start"){for i in hadoop104doecho ---------------启动$i消费flume---------------ssh $i "nohup /opt/module/flume-1.7.0/bin/flume-ng agent --conf-file /opt/module/flume-1.7.0/conf/kafka-flume-hdfs.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume-1.7.0/log.txt 2>&1 &"done};;"stop"){for i in hadoop104doecho ---------------停止$i消费flume---------------ssh $i "ps -ef | grep kafka-flume-hdfs | grep -v grep |awk '{print $2}' | xargs kill"done};;esac
脚本授权chmod 777 f2.sh。
集群启动与停止
编写cluster.sh脚本,可以一键启动与停止所有程序,包括hdfs、yarn、Zookeeper、flume、kafka。
#! /bin/bashcase $1 in"start"){echo ---------------启动集群---------------/opt/module/hadoop-2.8.2/sbin/start-dfs.shssh hadoop103 "/opt/module/hadoop-2.8.2/sbin/start-yarn.sh"zk.sh startsleep 4sf1.sh startkf.sh startsleep 6sf2.sh start};;"stop"){echo ---------------停止集群---------------f2.sh stopkf.sh stopf1.sh stopzk.sh stopssh hadoop103 "/opt/module/hadoop-2.8.2/sbin/stop-yarn.sh"/opt/module/hadoop-2.8.2/sbin/stop-dfs.sh};;esac
安装MySQL
安装包导入后,解压
[root@hadoop102 software]# unzip mysql-libs.zip
解压得到client、server和connector,这里主要用到connector。
解压connector,完成。
接着安装client和server。这里是要root权限的。
查看102上是否已经安装了MySQL
[root@hadoop102 mysql-libs]# rpm -qa|grep mysql
如果有,需要先删
[root@hadoop102 mysql-libs]# rpm -e --nodeps mysql名称
这里有坑,centos7自带的有一个mariadb-lib的包,会和server包的内容冲突,因此要先删掉自带的mariadb-lib
[root@hadoop102 mysql-libs]# yum remove mariadb-libs-5.5.65-1.el7.x86_64之后还有问题,需要装个autoconf库
[root@hadoop102 mysql-libs]# yum -y install autoconf
确保机器上没有MySQL就可以安装了。
[root@hadoop102 mysql-libs]# rpm -ivh MySQL-server-5.6.24-1.el6.x86_64.rpm
安装client
[root@hadoop102 mysql-libs]# rpm -ivh MySQL-client-5.6.24-1.el6.x86_64.rpm
解压connector
[root@hadoop102 mysql-libs]# tar -zxvf mysql-connector-java-5.1.27.tar.gz
启动mysql-server
[root@hadoop102 mysql-libs]# service mysql start
查看状态
[root@hadoop102 mysql-libs]# service mysql status
查看进程和3306端口
[root@hadoop102 mysql-libs]# ps -ef|grep mysql[root@hadoop102 mysql-libs]# netstat -anop|grep 3306
然后好像可以直接无密码登录,进去后修改密码,再重新登录
[root@hadoop102 mysql-libs]# mysqlmysql> set password=password('123456');[root@hadoop102 mysql-libs]# mysql -uroot -p123456
进去之后设置,
可以查看数据库
mysql> show databases;
进入mysql表,修改user信息
mysql> use mysql;mysql> select user,host,password from user;
设置所有可访问
mysql> update user set host='%' where host='localhost';
然后把其他多余的删除,只留下%
mysql> delete from user where Host='hadoop102 ';mysql> delete from user where Host='127.0.0.1 ';mysql> delete from user where Host='::1';
退出
mysql> quit;
现在MySQL就可以使用了。
安装sqoop
安装包解压后,重命名配置文件,在/opt/module/sqoop-1.4.6/conf目录下
[root@hadoop102 conf]# mv sqoop-env-template.sh sqoop-env.sh
在sqoop-env.sh文件中增加下面内容
export HADOOP_COMMON_HOME=/opt/module/hadoop-2.8.2export HADOOP_MAPRED_HOME=/opt/module/hadoop-2.8.2
需要什么环境就加什么,这里加了hadoop。
拷贝JDBC驱动,即安装mysql时的connector
[root@hadoop102 mysql-connector-java-5.1.27]# cp mysql-connector-java-5.1.27-bin.jar /opt/module/sqoop-1.4.6/lib/
验证配置是否正确
[root@hadoop102 sqoop-1.4.6]# bin/sqoop help
测试是否能连接数据库
[root@hadoop102 sqoop-1.4.6]# bin/sqoop list-databases --connect jdbc:mysql://hadoop102:3306/ --username root --password 123456
同步策略
- 全量同步策略
- 增量同步策略
- 新增及变化策略
- 特殊策略
将MySQL中的数据传输到hdfs,通过mysqlTohdfs.sh脚本
#!/bin/bashsqoop=/opt/module/sqoop-1.4.6/bin/sqoopif [ -n "$2" ] ;thendo_date=$2elsedo_date=`date -d '-1 day' +%F`fi#编写通用数据导入指令,通过第一个参数传入表名,第二个参数传入查询语句,对导入数据使用LZO压缩#格式,并对LZO压缩文件创建索引import_data(){$sqoop import \--connect jdbc:mysql://hadoop102:3306/gmall \--username root \--password 123456 \--target-dir /origin_data/gmall/db/$1/$do_date \--delete-target-dir \--query "$2 and \$CONDITIONS" \--num-mappers 1 \--fields-terminated-by '\t' \--compress \--compression-codec lzop \--null-string '\\N' \--null-non-string '\\N'hadoop jar /opt/module/hadoop-2.8.2/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer/origin_data/gmall/db/$1/$do_date}#针对不同表格分别调用通用数据导入指令,全量导入数据的表格的查询条件为where 1=1 ,增量导入数#据的表格的查询条件为当天日期import_order_info(){import_data order_info "selectid,final_total_amount,order_status,user_id,out_trade_no,create_time,operate_time,province_id,benefit_reduce_amount,original_total_amount,feight_feefrom order_infowhere (date_format(create_time,'%Y-%m-%d')='$do_date'or date_format(operate_time,'%Y-%m-%d')='$do_date')"}import_coupon_use(){import_data coupon_use "selectid,coupon_id,user_id,order_id,coupon_status,get_time,using_time,used_timefrom coupon_usewhere (date_format(get_time,'%Y-%m-%d')='$do_date'or date_format(using_time,'%Y-%m-%d')='$do_date'or date_format(used_time,'%Y-%m-%d')='$do_date')"}import_order_status_log(){import_data order_status_log "selectid,order_id,order_status,operate_timefrom order_status_logwhere date_format(operate_time,'%Y-%m-%d')='$do_date'"}import_activity_order(){import_data activity_order "selectid,activity_id,order_id,create_timefrom activity_orderwhere date_format(create_time,'%Y-%m-%d')='$do_date'"}import_user_info(){import_data "user_info" "selectid,name,birthday,gender,email,user_level,create_time,operate_timefrom user_infowhere (DATE_FORMAT(create_time,'%Y-%m-%d')='$do_date'or DATE_FORMAT(operate_time,'%Y-%m-%d')='$do_date')"}import_order_detail(){import_data order_detail "selectod.id,order_id,user_id,sku_id,sku_name,order_price,sku_num,od.create_timefrom order_detail odjoin order_info oion od.order_id=oi.idwhere DATE_FORMAT(od.create_time,'%Y-%m-%d')='$do_date'"}import_payment_info(){import_data "payment_info" "selectid,out_trade_no,order_id,user_id,alipay_trade_no,total_amount,subject,payment_type,payment_timefrom payment_infowhere DATE_FORMAT(payment_time,'%Y-%m-%d')='$do_date'"}import_comment_info(){import_data comment_info "selectid,user_id,sku_id,spu_id,order_id,appraise,comment_txt,create_timefrom comment_infowhere date_format(create_time,'%Y-%m-%d')='$do_date'"}import_order_refund_info(){import_data order_refund_info "selectid,user_id,order_id,sku_id,refund_type,refund_num,refund_amount,refund_reason_type,create_timefrom order_refund_infowhere date_format(create_time,'%Y-%m-%d')='$do_date'"}import_sku_info(){import_data sku_info "selectid,spu_id,price,sku_name,sku_desc,weight,tm_id,category3_id,create_timefrom sku_info where 1=1"}import_base_category1(){import_data "base_category1" "selectid,namefrom base_category1 where 1=1"}import_base_category2(){import_data "base_category2" "selectid,name,category1_idfrom base_category2 where 1=1"}import_base_category3(){import_data "base_category3" "selectid,name,category2_idfrom base_category3 where 1=1"}import_base_province(){import_data base_province "selectid,name,region_id,area_code,iso_codefrom base_provincewhere 1=1"}import_base_region(){import_data base_region "selectid,region_namefrom base_regionwhere 1=1"}import_base_trademark(){import_data base_trademark "selecttm_id,tm_namefrom base_trademarkwhere 1=1"}import_spu_info(){import_data spu_info "selectid,spu_name,category3_id,tm_idfrom spu_infowhere 1=1"}import_favor_info(){import_data favor_info "selectid,user_id,sku_id,spu_id,is_cancel,create_time,cancel_timefrom favor_infowhere 1=1"}import_cart_info(){import_data cart_info "selectid,user_id,sku_id,cart_price,sku_num,sku_name,create_time,operate_time,is_ordered,order_timefrom cart_infowhere 1=1"}import_coupon_info(){import_data coupon_info "selectid,coupon_name,coupon_type,condition_amount,condition_num,activity_id,benefit_amount,benefit_discount,create_time,range_type,spu_id,tm_id,category3_id,limit_num,operate_time,expire_timefrom coupon_infowhere 1=1"}import_activity_info(){import_data activity_info "selectid,activity_name,activity_type,start_time,end_time,create_timefrom activity_infowhere 1=1"}import_activity_rule(){import_data activity_rule "selectid,activity_id,condition_amount,condition_num,benefit_amount,benefit_discount,benefit_levelfrom activity_rulewhere 1=1"}import_base_dic(){import_data base_dic "selectdic_code,dic_name,parent_code,create_time,operate_timefrom base_dicwhere 1=1"}import_activity_sku(){import_data activity_sku "selectid,activity_id,sku_id,create_timefrom activity_skuwhere 1=1"}#对传入的第一个参数进行判断,根据传入参数的不同决定导入哪种表数据,传入first,表示初次执行脚#本,导入所有表数据;传入all,则导入除地区外的所有表数据case $1 in"order_info")import_order_info;;"base_category1")import_base_category1;;"base_category2")import_base_category2;;"base_category3")import_base_category3;;"order_detail")import_order_detail;;"sku_info")import_sku_info;;"user_info")import_user_info;;"payment_info")import_payment_info;;"base_province")import_base_province;;"base_region")import_base_region;;"base_trademark")import_base_trademark;;"activity_info")import_activity_info;;"activity_order")import_activity_order;;"cart_info")import_cart_info;;"comment_info")import_comment_info;;"coupon_info")import_coupon_info;;"coupon_use")import_coupon_use;;"favor_info")import_favor_info;;"order_refund_info")import_order_refund_info;;"order_status_log")import_order_status_log;;"spu_info")import_spu_info;;"activity_rule")import_activity_rule;;"base_dic")import_base_dic;;"activity_sku")import_activity_sku;;"first")import_base_category1import_base_category2import_base_category3import_order_infoimport_order_detailimport_sku_infoimport_user_infoimport_payment_infoimport_base_provinceimport_base_regionimport_base_trademarkimport_activity_infoimport_activity_orderimport_cart_infoimport_comment_infoimport_coupon_useimport_coupon_infoimport_favor_infoimport_order_refund_infoimport_order_status_logimport_spu_infoimport_activity_ruleimport_base_dicimport_activity_sku;;"all")import_base_category1import_base_category2import_base_category3import_order_infoimport_order_detailimport_sku_infoimport_user_infoimport_payment_infoimport_base_trademarkimport_activity_infoimport_activity_orderimport_cart_infoimport_comment_infoimport_coupon_useimport_coupon_infoimport_favor_infoimport_order_refund_infoimport_order_status_logimport_spu_infoimport_activity_ruleimport_base_dicimport_activity_sku;;esac
脚本要授权。
安装Hive
安装包解压后,将mysql里面的connector放到Hive安装目录中的lib下
[root@hadoop102 mysql-connector-java-5.1.27]# cp mysql-connector-java-5.1.27-bin.jar /opt/module/hive-3.1.2/lib/
在Hive的conf目录下创建hive-site.xml
[root@hadoop102 hive-3.1.2]# pwd/opt/module/hive-3.1.2[root@hadoop102 hive-3.1.2]# cd conf/[root@hadoop102 conf]# vim hive-site.xml
添加如下内容
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop102:3306/hadoop102?createDatabaseIfN otExist=true</value><description>JDBC connect string for a JDBC </description></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value><description>Driver class name for a JDBC </description></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value><description>username to use against database</description></property><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value><description>password to use against database</description></property><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value><description>location of default database for the warehouse</description></property><property><name>hive.cli.print.header</name><value>true</value></property><property><name>hive.cli.print.current.db</name><value>true</value></property><property><name>hive.metastore.schema.verification</name><value>false</value></property><property><name>datanucleus.schema.autoCreateAll</name><value>true</value></property><property><name>hive.metastore.uris</name><value>thrift://hadoop102:9083</value></property></configuration>
启动服务
[root@hadoop102 hive-3.1.2]# nohup bin/hive --service metastore &
nohup bin/hive --service metastore >/dev/null 2>&1 &
然后正常启动Hive
[root@hadoop102 hive-3.1.2]# bin/hive
集成Tez引擎
将tez压缩包上传一份到hdfs上,再解压一份在本地
[root@hadoop102 software]# hadoop fs -mkdir /tez[root@hadoop102 software]# hadoop fs -put apache-tez-0.9.1-bin.tar.gz /tez/[root@hadoop102 software]# tar -zxvf apache-tez-0.9.1-bin.tar.gz -C /opt/module/
在hive安装目录/opt/module/hive-3.1.2/conf下创建tez-site.xml文件
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>tez.lib.uris</name><value>${fs.defaultFS}/tez/apache-tez-0.9.1-bin.tar.gz</value></property><property><name>tez.use.cluster.hadoop-libs</name><value>true</value></property><property><name>tez.history.logging.service.class</name><value>org.apache.tez.dag.history.logging.ats.ATSHistoryLoggin gService</value></property></configuration>
修改文件名
[root@hadoop102 conf]# mv hive-env.sh.template hive-env.sh
修改hive-env.sh文件,增加下面内容
export TEZ_HOME=/opt/module/tez-0.9.1 #是你的 tez 的解压目录export TEZ_JARS=""for jar in `ls $TEZ_HOME |grep jar`; doexport TEZ_JARS=$TEZ_JARS:$TEZ_HOME/$jardonefor jar in `ls $TEZ_HOME/lib`; doexport TEZ_JARS=$TEZ_JARS:$TEZ_HOME/lib/$jardoneexport HIVE_AUX_JARS_PATH=/opt/module/hadoop-2.8.2/share/hadoop/common/hadoop-lzo-0.4.20.jar$TEZ_JARS
在Hive配置/opt/module/hive-3.1.2/conf中的hive-site.xml文件添加下面配置,更改引擎
<property><name>hive.execution.engine</name><value>tez</value></property>
到这里理论上就没问题了,但是一般情况下会遇到运行 Tez 时检查到用过多内存而被 NodeManager 杀死进程问题,解决方法是关掉虚拟内存检查,修改 yarn-site.xml
分发到其他机器,重新启动集群。

若有收获,就点个赞吧
0 人点赞
