排序算法:插入、冒泡、选择、希尔、快速、归并、堆排序、计数排序、桶排序、基数排序
查找算法:线性查找、二分查找
线性数据结构:动态数组、链表、栈、队列、哈希表
经典树结构:二分搜索树、堆、AVL、红黑树、B类树
高级数据结构:线段树、并查集、Trie、SQRT分解
字符串算法:KMP、模式匹配
什么是算法:一系列解决问题的、清晰的、可执行的计算机指令
- 有限性
- 确定性:不会产生二义性
- 可行性
- 输入
- 输出
查找算法
线性查找
简单示例,在数组中查找某个数
public static int search(int[] data, int target){for (int i=0; i<data.length; i++) {if (data[i] == target){return i;}}return -1;}
再改进,使用标准的泛型。这里注意细节,使用泛型后比较要调用 `.equals()`方法
public static <E> int search(E[] data, E target){for (int i=0; i<data.length; i++) {if (data[i].equals(target)){return i;}}return -1;}
二分查找
二分查找法只针对有序数列,其时间复杂度为
public class BinarySearch {private BinarySearch(){}public static <E extends Comparable<E>> int search(E[] arr, E target){return search(arr, 0, arr.length-1, target);}public static <E extends Comparable<E>> int search(E[] arr, int l, int r, E target){int half = l + (r-l)/2;if (l>r){return -1;}if (arr[half].compareTo(target) == 0){return half;}if (arr[half].compareTo(target) > 0){return search(arr, l, half-1, target);}return search(arr, half+1, r, target);}}
二分搜索树
二分搜索树(Binary Search Tree)首先是二叉树,二分搜索树每个节点的值大于其左子树所有节点的值小于其右子树的所有节点的值,存储的元素必须具有可比较性
排序算法
排序算法是为了让数据有序,排序算法中蕴含着重要的算法设计思想。
选择排序
先把最小的拿出来,剩下的再把最小的拿出来,以此往复,直至没有剩下的。
上述的说法在排序过程中占用了额外的空间,考虑进行原地排序,即不开辟额外的数组空间。
下面示例直接加上泛型,一步到位
public class SelectSort {private SelectSort() {}public static <E extends Comparable<E>> E[] sort(E[] data) {for (int i = 0; i < data.length; i++) {int tempIndex = i;for (int j = i + 1; j < data.length; j++) {if (data[j].compareTo(data[tempIndex]) < 0) {tempIndex = j;}}E temp = data[tempIndex];data[tempIndex] = data[i];data[i] = temp;}return data;}public static void main(String[] args) {Integer[] data = {12, 3, 6, 2, 3, 7, 53, 24};Integer[] sort = SelectSort.sort(data);for (int value : sort) {System.out.println(value);}}}
比较一个自定义类
public class Student implements Comparable<Student > {private String name;private Integer score;public Student(String name, Integer score){this.name = name;this.score = score;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getScore() {return score;}public void setScore(Integer score) {this.score = score;}@Overridepublic int compareTo(Student stu) {return this.score.compareTo(stu.score);}@Overridepublic int hashCode() {int result = 17;result = 31*result + (name == null ? 0 : name.hashCode());result = 31*result + (score == null ? 0 : score.hashCode());return result;}@Overridepublic boolean equals(Object obj) {if (obj == null){return false;}if (obj.getClass() != Student.class){return false;}Student student = (Student) obj;return this.name.equals(student.name);}@Overridepublic String toString() {return this.name+":"+this.score;}}
public static void main(String[] args) {//Integer[] data = {12, 3, 6, 2, 3, 7, 53, 24};//Integer[] sort = SelectSort.sort(data);//for (int value : sort) {// System.out.println(value);//}Student[] students = {new Student("Jack",12),new Student("Bob",23),new Student("DuoBi",18),new Student("Nancy",3),new Student("Rose",9)};Student[] sortStu = SelectSort.sort(students);for (Student stu : sortStu) {System.out.println(stu.toString());}}
选择排序的时间复杂度是
插入排序
实现示例
public static <E extends Comparable<E>> E[] sort(E[] data) {int length = data.length;for (int i = 0; i < length; i++) {for (int j = i; j > 1; j--) {if (data[j].compareTo(data[j - 1])<0) {E temp = data[j];data[j] = data[j - 1];data[j - 1] = temp;}}}return data;}
时间复杂度是<br />上述的例子可以再优化一下,减少一下时间
public static <E extends Comparable<E>> E[] sort(E[] data) {int length = data.length;for (int i = 0; i < length; i++) {E temp = data[i];int j;for (j = i; j >= 1 && temp.compareTo(data[j - 1])<0; j--) {data[j] = data[j - 1];}data[j] = temp;}return data;}
对于插入排序,如果目标数组已经有序了,则时间复杂度只有;相比于选择排序,选择排序的复杂度永远是
归并排序
是复杂的递归算法,时间复杂度为
将数组化为两个子数组,对每个子数组进行排序,子数组再化为子数组排序,以此类推…
重点在于归并的过程,即merge(arr, l, mid, r),归并的过程无法原地进行
public static <E extends Comparable<E>> void sort(E[] arr) {sort(arr, 0, arr.length - 1);}private static <E extends Comparable<E>> void sort(E[] arr, int l, int r) {if (l >= r) {return;}int mid = l + (r - l) / 2;sort(arr, l, mid);sort(arr, mid + 1, r);merge(arr, l, mid, r);}/*** 合并两个有序区间 arr[l,mid]和 arr[mid+1,l]*/private static <E extends Comparable<E>> void merge(E[] arr, int l, int mid, int r) {E[] temp = Arrays.copyOfRange(arr, l, r + 1);int i = l;int j = mid + 1;for (int k = l; k <= r; k++) {if (i > mid) {arr[k] = temp[j - l];j++;} else if (j > r) {arr[k] = temp[i - l];i++;} else if (temp[i-l].compareTo(temp[j-l]) >= 0) {arr[k] = temp[j - l];j++;} else {arr[k] = temp[i - l];i++;}}}
对于复杂度的分析<br />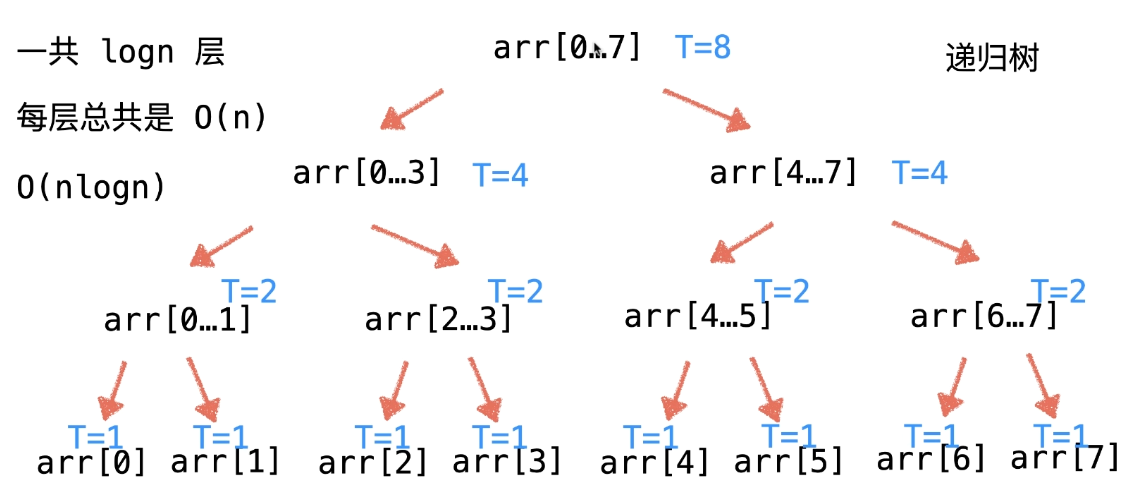
对上述代码的优化
public static <E extends Comparable<E>> void sort(E[] arr) {E[] temp = Arrays.copyOf(arr, arr.length);sort(arr, 0, arr.length - 1, temp);}private static <E extends Comparable<E>> void sort(E[] arr, int l, int r, E[] temp) {if (l >= r) {return;}int mid = l + (r - l) / 2;sort(arr, l, mid, temp);sort(arr, mid + 1, r, temp);if (arr[mid].compareTo(arr[mid+1])>0){merge(arr, l, mid, r, temp);}}/*** 合并两个有序区间 arr[l,mid]和 arr[mid+1,l]*/private static <E extends Comparable<E>> void merge(E[] arr, int l, int mid, int r, E[] temp) {System.arraycopy(arr, l, temp, 0, r-l+1);int i = l;int j = mid + 1;for (int k = l; k <= r; k++) {if (i > mid) {arr[k] = temp[j - l];j++;} else if (j > r) {arr[k] = temp[i - l];i++;} else if (temp[i-l].compareTo(temp[j-l]) >= 0) {arr[k] = temp[j - l];j++;} else {arr[k] = temp[i - l];i++;}}}
此时,对归并的时候进行了优化。优化后,如果数组是有序的,则排序的时间复杂度为;并且不用每次归并之时都创建一个新的数组,节省了空间
此外,上述可以看出是自顶向下的归并,我们还可以用自底向上的归并
/*** 自底向上的归并*/public static <E extends Comparable<E>> void sortBU(E[] arr) {int n = arr.length;E[] temp = Arrays.copyOf(arr, n);for (int sz = 1; sz < n; sz += sz) {for (int i = 0; i + sz < n; i += sz + sz) {if (arr[i + sz - 1].compareTo(arr[i + sz])>0){merge(arr, i, i + sz - 1, Math.min(i + 2 * sz - 1, n - 1), temp);}}}}/*** 合并两个有序区间 arr[l,mid]和 arr[mid+1,l]*/private static <E extends Comparable<E>> void merge(E[] arr, int l, int mid, int r, E[] temp) {System.arraycopy(arr, l, temp, 0, r - l + 1);int i = l;int j = mid + 1;for (int k = l; k <= r; k++) {if (i > mid) {arr[k] = temp[j - l];j++;} else if (j > r) {arr[k] = temp[i - l];i++;} else if (temp[i-l].compareTo(temp[j-l]) >= 0) {arr[k] = temp[j - l];j++;} else {arr[k] = temp[i - l];i++;}}}
快速排序
快速排序就和它的名字一样很快,它的核心是选取一个数然后使得左边的数都比它小右边的数都比它大,然后对左右重复这个操作
public static <E extends Comparable<E>> void sort(E[] arr) {sort(arr, 0, arr.length - 1);}private static <E extends Comparable<E>> void sort(E[] arr, int l, int r) {if (l >= r) {return;}int partition = partition(arr, l, r);sort(arr, l, partition);sort(arr, partition + 1, r);}private static <E extends Comparable<E>> int partition(E[] arr, int l, int r) {int j = l;for (int i = l + 1; i <= r; i++) {if (arr[i].compareTo(arr[l]) < 0) {j++;swap(arr, i, j);}}swap(arr, l, j);return j;}private static <E extends Comparable<E>> void swap(E[] arr, int i, int j) {E temp = arr[i];arr[i] = arr[j];arr[j] = temp;}
这种写法有一个问题,当数组本身就是有序的时,该算法的时间复杂度是,会非常慢;而且递归深度是,容易造成栈溢出<br />可以从数组中随机一个数出来,把随机数和第一个数交换(即随机数为第一个元素),其他操作都不变
public class QuickSort {private QuickSort() {}private static Random random = new Random();public static <E extends Comparable<E>> void sort(E[] arr) {sort(arr, 0, arr.length - 1);}private static <E extends Comparable<E>> void sort(E[] arr, int l, int r) {if (l >= r) {return;}int partition = partition(arr, l, r);sort(arr, l, partition);sort(arr, partition + 1, r);}private static <E extends Comparable<E>> int partition(E[] arr, int l, int r) {//生成一个[l,r]间的随机索引int randomIndex = random.nextInt(r - l + 1) + l;swap(arr, l, randomIndex);int j = l;for (int i = l + 1; i <= r; i++) {if (arr[i].compareTo(arr[l]) < 0) {j++;swap(arr, i, j);}}swap(arr, l, j);return j;}private static <E extends Comparable<E>> void swap(E[] arr, int i, int j) {E temp = arr[i];arr[i] = arr[j];arr[j] = temp;}}
对于上述的修改,虽然解决了数组本身就有序这种情况所造成的影响,但是如果数组所有的元素都一样时,排序的效率依然很低下。针对这个问题,引入双路快速排序算法
之前的做法,对于关键字v,我们把大于和小于v的都放在一边,下面我们考虑把大于和小于v的部分分别放在两边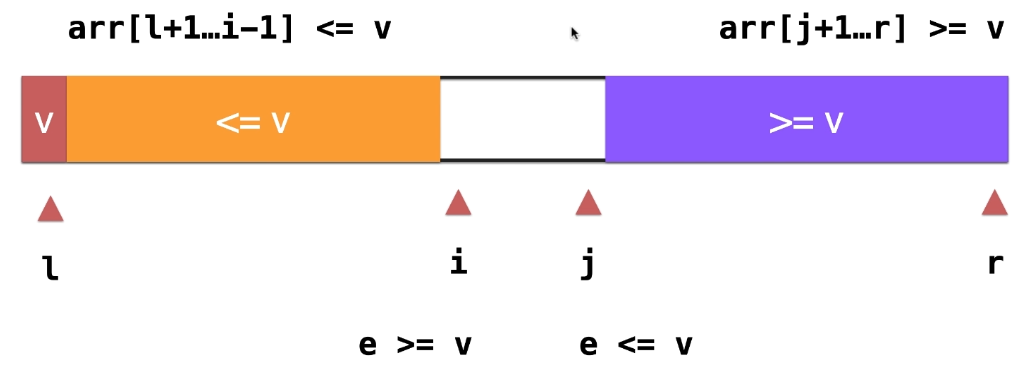
在代码层面,就是partition方法要做修改
public class QuickSort {private QuickSort() {}private static Random random = new Random();public static <E extends Comparable<E>> void sort(E[] arr) {sort(arr, 0, arr.length - 1);}private static <E extends Comparable<E>> void sort(E[] arr, int l, int r) {if (l >= r) {return;}int partition = partition(arr, l, r);sort(arr, l, partition);sort(arr, partition + 1, r);}private static <E extends Comparable<E>> int partition(E[] arr, int l, int r) {//生成一个[l,r]间的随机索引int randomIndex = random.nextInt(r - l + 1) + l;swap(arr, l, randomIndex);int i=l+1;int j=r;while (true) {while (arr[i].compareTo(arr[l])<0 && i<=j){i++;}while (arr[j].compareTo(arr[l])>0 && i<=j){j--;}if (i>=j){break;}swap(arr, i, j);i++;j--;}swap(arr, l, j);return j;}private static <E extends Comparable<E>> void swap(E[] arr, int i, int j) {E temp = arr[i];arr[i] = arr[j];arr[j] = temp;}}
上述代码中,虽然 `partition`方法中看似有两重循环,但是实际上数组每个元素只遍历了一遍,`partition`方法的复杂度只有<br />如果数组的元素全都重复的话,我们其实只用一次`partition`方法就行了,为此我们进一步优化,引入**三路快速排序算法**。即对于关键字v,大于v小于v和等于v的这三路<br />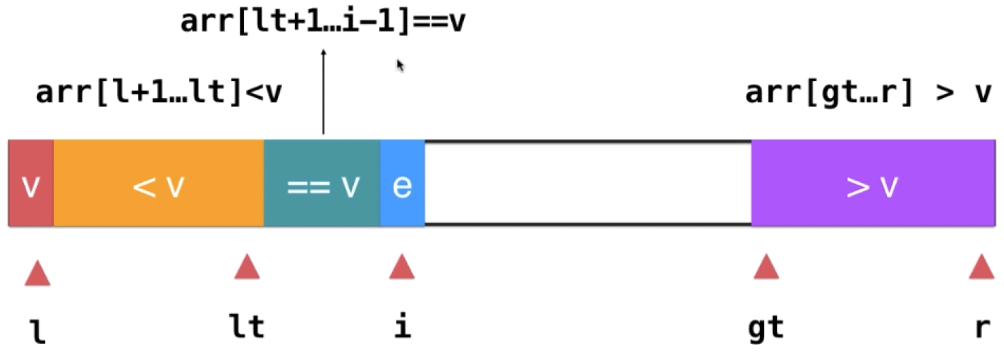<br />对于三路快速排序算法,如果数组中所有的元素都相同,则时间复杂度为
public class QuickSort {private QuickSort() {}private static Random random = new Random();public static <E extends Comparable<E>> void sort(E[] arr) {sort(arr, 0, arr.length - 1);}private static <E extends Comparable<E>> void sort(E[] arr, int l, int r) {if (l >= r) {return;}//生成一个[l,r]间的随机索引int randomIndex = random.nextInt(r - l + 1) + l;swap(arr, l, randomIndex);// arr[l+1,lt]<v, arr[lt+1,i-1]==v, arr[gt,r]>vint lt = l;int i=l+1;int gt = r+1;while (i<gt){if (arr[i].compareTo(arr[l])<0){lt++;swap(arr, i, lt);i++;}else if (arr[i].compareTo(arr[l])>0){gt--;swap(arr, i, gt);}else {i++;}}swap(arr, l, lt);sort(arr, l, lt-1);sort(arr, gt, r);}private static <E extends Comparable<E>> void swap(E[] arr, int i, int j) {E temp = arr[i];arr[i] = arr[j];arr[j] = temp;}}
堆排序
先实现一个最大堆
/*** 基于数组实现的最大堆*/public class MaxHeap<E extends Comparable<E>> {private Array<E> data;public MaxHeap(int capacity){data = new Array<>(capacity);}public MaxHeap(){data = new Array<>();}/*** 返回堆中元素的个数*/public int size(){return data.getSize();}/*** 堆是否为空*/public boolean isEmpty(){return data.isEmpty();}/*** 返回索引处元素的父节点的索引*/private int parent(int index){if (index == 0){throw new IllegalArgumentException("根节点没有父节点");}return (index-1)/2;}/*** 返回索引处元素的左孩子的索引*/private int leftChild(int index){return index*2+1;}/*** 返回索引处元素的右孩子的索引*/private int rightChild(int index){return (index+1)*2;}/*** 交换元素*/private void swap(int i, int j){E temp = data.get(i);data.set(i, data.get(j));data.set(j, temp);}/*** 向堆中插入元素*/public void add(E e){data.addLast(e);//进行堆的上浮int size = data.getSize();if (size >1){int index = size -1;while (index >0 && e.compareTo(data.get(parent(index))) > 0){swap(index, parent(index));index = parent(index);}}}/*** 返回堆中最大元素*/public E findMax(){if (data.isEmpty()){throw new IllegalArgumentException("当前堆为空");}return data.get(0);}/*** 取出堆中的最大元素*/public E extractMax(){E ret = findMax();swap(0, data.getSize()-1);data.removeLast();siftDown(0);return ret;}/*** 下沉操作*/private void siftDown(int k){while (leftChild(k) < data.getSize()){int j = leftChild(k);//data[j]是leftChild和rightChild中的最大值if ((j+1)<data.getSize() && data.get(j+1).compareTo(data.get(j))>0){j = rightChild(k);}if (data.get(k).compareTo(data.get(j))>=0){break;}//如果data[k]比data[j]小,则继续下沉swap(k, j);k = j;}}@Overridepublic String toString(){StringBuilder stringBuilder = new StringBuilder();for (int i=0;i<data.getSize();i++){stringBuilder.append(data.get(i)).append(" ");}return stringBuilder.toString();}}
然后进行堆排序
/*** 堆排序*/public class HeapSort {private HeapSort(){}public static <E extends Comparable<E>> void sort(E[] data){MaxHeap<E> maxHeap = new MaxHeap<>();for (E e : data) {maxHeap.add(e);}for (int i=0;i<data.length;i++){data[data.length-i-1] = maxHeap.extractMax();}}}
此外,堆还有heapify方法,该方法可以将任意数组转化为堆。以堆的构造方法写出
public MaxHeap(E[] arr) {data = new Array<>();for (E e : arr) {data.addLast(e);}//从最后一个非叶子节点开始进行下沉操作for (int i = parent(arr.length - 1); i >= 0; i--) {siftDown(i);}}
堆的replace方法
/*** 取出堆中最大元素,并且替换成元素e*/public E replace(E e) {E ret = findMax();data.set(0, e);siftDown(0);return ret;}
上述的堆排序算法创建了额外的空间,现在对上述的堆排序算法进行改进,进行原地堆排序算法
public static <E extends Comparable<E>> void siteSort(E[] data) {if (data.length == 1) {return;}for (int i = data.length / 2 - 1; i >= 0; i--) {siftDown(data, i, data.length);}for (int i=data.length-1;i>=0;i--){swap(data,0,i);siftDown(data,0,i);}}/*** 对data[0,n)所形成的最大堆中,索引k的元素,执行siftDown下沉操作*/private static <E extends Comparable<E>> void siftDown(E[] data, int k, int n) {while (2 * k + 1 < n) {int j = 2 * k + 1;//data[j]是leftChild和rightChild中的最大值if ((j + 1) < n && data[j + 1].compareTo(data[j]) > 0) {j = 2 * k + 2;}if (data[k].compareTo(data[j]) >= 0) {break;}//如果data[k]比data[j]小,则继续下沉swap(data, k, j);k = j;}}private static <E extends Comparable<E>> void swap(E[] data, int i, int j) {E temp = data[i];data[i] = data[j];data[j] = temp;}

若有收获,就点个赞吧
0 人点赞
