内存优化
数组
String的优化来自JDK,JDK8前,内部使用char[]占用2个字节,JDK8后使用byte[]占用一个字节,为了减少字符串内存的占用,GC次数也会减少。
char占用2个字节,使用UTF8编码,取值范围0-65535之间。
byte占用1个字节,使用Latin-1和UTF16编码。
编码
String name = “name”;
使用Latin-1编码,char数组占用8个字节, byte数组占用4个字节。
String name = “名字” ;
使用UTF16编码,使用2个字节或者4个字节来存储。
jdk9为何要将String的底层实现由char[]改成了byte[]?
拼接优化
JDK8前,字节码
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder; INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder;
使用字符串拼接,字节码中使用了StringBuilder.append方式拼接字符串
JDK8后,字节码
INVOKEDYNAMIC makeConcatWithConstants(Ljava/lang/String;Ljava/lang/String;)Ljava/lang/String; [ // handle kind 0x6 : INVOKESTATIC java/lang/invoke/StringConcatFactory.makeConcatWithConstants(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/lang/String;[Ljava/lang/Object;)Ljava/lang/invoke/CallSite; // arguments: “\u0001\u0001” ]
缓存池优化
享元模式
String使用享元模式,通过复用对象,达到节省内存的目的。
String s1 = "小争哥";String s2 = "小争哥";String s3 = new String("小争哥");System.out.println(s1 == s2); // trueSystem.out.println(s1 == s3); // false
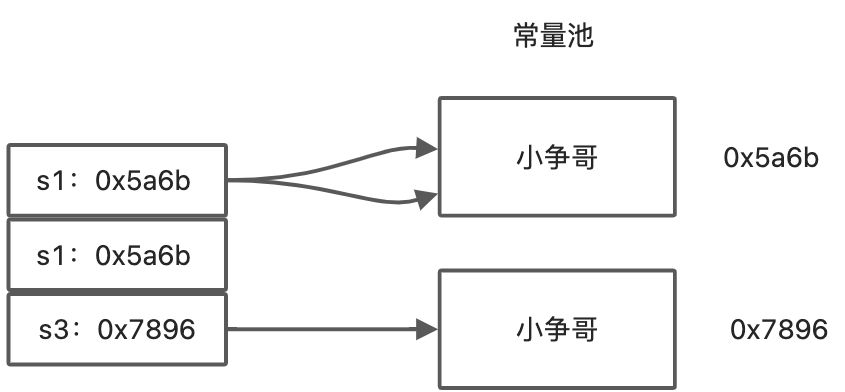
由于没法事先知道字符串内容,也就没法事先创建好,所以在字符串第一次创建时候,缓存到字符串常量池中,
再次使用相同字符串时候,判断缓存池中是否存在,直接从缓存池中取,避免再次创建对象。[

若有收获,就点个赞吧
0 人点赞
