1. 数据库 DataBase
- 特点
- 持久化存储数据——数据库是文件系统
- 使用统一方式操作数据库,方便管理
- 常用数据库
- Oracle:关系型数据库;收费软件,使用最多
- MySQL:关系型数据库;Oracle公司开源免费数据库
- DB2:IBM的收费数据库,应用于银行系统
- MongoDB:文档型数据库
- SQLite:嵌入式小型数据库,用于移动开发
- MySQL
- 启动方式
- 打开服务界面:cmd窗口中,输入
services.msc指令,手动开启SQL服务 - 使用管理员权限启动 cmd,输入
net start mysql开启服务器服务,输入net stop mysql` 关闭服务器服务
- 打开服务界面:cmd窗口中,输入
- 登录与退出
- 尝试连接服务器
mysql -u用户名 -p密码 - 尝试远程连接
mysql -hIP地址 -u用户名 -p连接目标的密码 - 尝试远程连接
mysql -host=IP地址 -user=用户名 -password=链接目标的密码 - 退出连接:
quit或exit
- 尝试连接服务器
- 启动方式
- SQL
- Structured Query Language 结构化查询语言,定义了所有操作关系型数据库的规则;不同数据库的SQL有“方言”
- 语法
- MySQL数据库的SQL语句不区分大小写,但关键字应该大写
- SQL语句可以单行或多行书写,以分号结尾
- 三种注释:
- 两个横杠,一个空格
-- 注释内容 - 一个井号,无需空格(MySQL独有)
#注释内容 - 多行注释
/* 多行注释 */
- 两个横杠,一个空格
- 不同语句类型
- DDL-definition:操作数据库、表
- DML-manipulation:增删改表中的数据
- DQL-query:查询表中的数据
- DCL-control:进行权限授理、安全访问
2. MySQL 的 SQL语句
2.1 DDL Data Definition Language
- 操作数据库:CRUD
- C-Create:增
- 创建数据库:
create database 数据库名称; - 创建数据库,判断是否有同名数据库存在:
create database if not exists 数据库名称;(exists 不是 exist) - 创建数据库,判断是否有同名数据库存在,并指定字符集:
create database if not exists 数据库名称 character set 字符集名称;
- 创建数据库:
- R-Retrieve:查
- 查询所有数据库名称:
show databases; - 查询创建某个数据库的创建语句、字符集等:
show create database 数据库名称;
- 查询所有数据库名称:
- U-Update:改
- 修改数据库字符集:
alter database 数据库名称 character set 字符集名称;
- 修改数据库字符集:
- D-Delete:删
- 删除数据库:
drop database 数据库名称; - 删除数据库,判断该数据库是否存在:
drop database if exists 数据库名称;
- 删除数据库:
- 使用数据库
- 使用数据库:
use 数据库名称; - 查询当前正在使用的数据库名称:
select database();
- 使用数据库:
- C-Create:增
操作表:CRUD
C-Create
创建表:
java create table 表名称( 列名1 数据类型1, 列名2 数据类型2, ... 列名n 数据类型n )- 整数:int
- 小数:double(总位数, 小数位数)
- 日期(yyyy-MM-dd):date
- 时间(yyyy-MM-dd HH:mm:ss):time
- 时间戳(默认使用系统时间;yyyy-MM-dd HH:mm:ss):timestamp
- 字符串:varchar(最大字符长度)
- 长文本:TEXT
- 二进制文件:BINARY(最大长度)
- 复制表:
create table 目标表名称 like 源表名称;
- R-Retrieve
- 查询表名称:
show tables; - 查询表的结构:
desc 表名称; - 查询表的信息:
show create table 表名称;
- 查询表名称:
- U-Update
- 修改表名称:
alter tabel 表名称 rename to 新表名称; - 修改表的字符集:
alter table 表名称 character set 字符集名称; - 修改列名、类型:
- 只改类型:
alter table 表名称 modify 列名 数据类型; - 只改类型又改名字:
alter table 表名称 change 原列名 新列名 数据类型;
- 只改类型:
- 添加列:
alter table 表名称 add 列名 数据类型; - 删除列:
alter table 表名称 drop 列名;
- 修改表名称:
- D-Delete
- 删除表:
drop table if exists 表名称; - 删除表,再新建一个一样的空表:
truncate table 表名称;
- 删除表:
2.2 DML Data Manipulation Language
- 添加数据
添加部分值:insert into 表名称(列名1, 列名2, ..., 列名n) values(值1, 值2, ..., 值n);- 除了数字类型,varchar、data、time类型的值需要用双引号或单引号括起来
- 当不写列名列表时,默认给所有列添加元素,默认值要手动写
NULL
- 删除数据
- 删除符合条件的记录
delete from 表名称 where 条件 - 先找到符合条件的行,再进行操作。例如:
DELETE FROM student WHERE NAME = "王铁塔"; - 清空表内容
- 删除表,再新建一个一样的空表:
truncate table 表名称; - 低效删除方法:
delete from 表名称;
- 删除表,再新建一个一样的空表:
- 删除符合条件的记录
- 修改数据
update 表名 set 列名1=值1, 列名2=值2, ... where 条件- 多个条件之间用
and连接 - 如果不加条件,会将所有条记录的对应列都修改
- 多个条件之间用
2.3 DQL Data Query Language
- 查询数据
- 查询表中的全部内容:
select * from 表名称; - 按列查询字段:
select 列名1, 列名2, ..., from 表名称; - 去除重复,使用关键字
distinct - 多列计算
- 使用四则运算符号,进行数学计算:加
+,减-,乘*,除/ - 使用
ifnull(表达式1, 表达式2)来避免空值
- 使用四则运算符号,进行数学计算:加
- 起别名:用
as关键字
- 查询表中的全部内容:
- 条件查询
- 格式:
where 条件 - 运算符
- 比较运算符:
<、<=、>、>=、=、<>(与!=一样代表不等于) - 范围:
BETWEEN ... AND ... - 值在列表中:
IN(值1, ..., 值m) - 判断NULL值,
IS NULL,IS NOT NULL - 模糊查询 LIKE:
_代表单个字符%代表任意个字符
- 比较运算符:
- 逻辑运算符:
and、or、not
- 格式:
- 排序查询
select 字段名 from 表名称 order by 排序字段1 排序方式1, 排序字段2, 排序规则2; - 聚合函数:排除了NULL值,对某一列进行统计(不可对多列)
- 计数:
count - 最小值:
min - 最大值:
max - 求和:
sum - 平均值:
avg
- 计数:
- 分组查询
- 格式:
select 分组字段名 聚合函数 from 表名称 group by 分组字段名; - 当条件、排序、分组、聚合函数都存在时,语句的顺序:
- where 分组之前限定,不满足条件不参与分组:
select 分组字段名 聚合函数 from 表名称 where 条件 group by 分组字段名 order by 排序字段名 排序方式 - having 分组之后限定,不满足条件查询不出:
select 分组字段名 聚合函数 from 表名称 group by 分组字段名 having 条件 order by 排序字段名 排序方式
- where 分组之前限定,不满足条件不参与分组:
- having v.s. where
- where 先按条件选行、分组,再按语句选列。即使条件字段没被选择,仍然可以计算
- having 先按语句选列,再按条件选行、分组。如果条件字段没被选择,则无法计算条件
- 格式:
- 分页查询
- 语法:
select 字段名称 from 表名称 limit 起始索引, 每页条目数量; %20%5Ctimes%20%E6%AF%8F%E9%A1%B5%E6%9D%A1%E7%9B%AE%E6%95%B0%E9%87%8F#card=math&code=%E8%B5%B7%E5%A7%8B%E7%B4%A2%E5%BC%95%20%3D%20%28%E5%BD%93%E5%89%8D%E9%A1%B5%E7%A0%81%20-%201%29%20%5Ctimes%20%E6%AF%8F%E9%A1%B5%E6%9D%A1%E7%9B%AE%E6%95%B0%E9%87%8F)
- 最后一页不足每页条目数量时,不会报错
- 语法:
- 综合例子```java
/ DDL for databases /
Create
CREATE DATABASE db1; CREATE DATABASE IF NOT EXISTS db2; CREATE DATABASE IF NOT EXISTS db3 CHARACTER SET gbk;
Retrieve
SHOW DATABASES; — 查看全部数据库 SHOW CREATE DATABASE db3; — 查看db3数据库的创建信息
Update
ALTER DATABASE db2 CHARACTER SET utf8;
Delete
DROP DATABASE db1; — 删除数据库 DROP DATABASE IF EXISTS db3; — 判断是否存在,如果存在删除
Use
USE db2; — 使用db2数据库 SELECT DATABASE(); — 显示当前使用的database名字
/ DDL for tables / USE db2; — 使用db2数据库
Create
CREATE TABLE IF NOT EXISTS stu ( — 新建表 id INT, — 编号 NAME VARCHAR(20), — 姓名 age INT, — 年龄 sex VARCHAR(5), — 性别 address VARCHAR(100), — 住址 math INT, — 数学 english INT — 英语 ); CREATE TABLE student LIKE stu; — 复制相同表结构
Retrieve
SHOW TABLES; — 显示该数据库中的所有表 DESC stu; — 显示表格结构 SHOW CREATE TABLE stu; — 显示表格信息
Update
ALTER TABLE student RENAME TO students; — 修改表名称 ALTER TABLE students CHARACTER SET gbk; — 修改字符集 ALTER TABLE students MODIFY id VARCHAR(10); — 修改字段的数据类型 ALTER TABLE students CHANGE sex gender VARCHAR(10); — 修改字段的名称及数据类型 ALTER TABLE students ADD total_score INT; — 添加一列,并指定数据类型 ALTER TABLE students DROP age; — 删除某字段 SELECT * FROM students; — 显示修改后的表students
Delete
DROP TABLE IF EXISTS students; DROP TABLE IF EXISTS stu; SHOW TABLES;
/ DML / USE db2; — 使用db2数据库
Insert Values
INSERT INTO stu(id, NAME, age, sex, address) VALUES(0, “支付宝”, 11, “女”, “西安”); — 添加单条数据 INSERT INTO stu — 添加多条数据 VALUES (1, “码云”, 55, “男”, “杭州”, 67, 86), (2, “github”, 42, “男”, “驻马店”, 53, 99), (3, “微博”, 43, “女”, “西安”, 45, 74), (4, “推特”, 22, “男”, “上海”, 71, NULL), — null值占位 (5, “知乎”, 12, “女”, “上海”, 57, 22), (6, “微信”, 31, “男”, “石家庄”, 97, 14), (7, “pornhub”, 39, “女”, “驻马店”, 84, 78), (8, “pornhub”, 50, “男”, “西安”, 44, 58), (9, “网易云”, 5, “男”, “驻马店”, 98, 99), (10, “易信”, 5, “女”, “驻马店”, 56, 79), (11, “Pycharm”, 85, “女”, “北京”, 44, 14), (12, “Pycharm”, 15, “男”, “北京”, 98, 99), (13, “Pycharm”, 15, “男”, “北京”, 56, 54) ; CREATE TABLE IF NOT EXISTS temp1 LIKE stu; — 复制相同表结构 CREATE TABLE IF NOT EXISTS temp2 LIKE stu; — 复制相同表结构
Delete Data
DELETE FROM stu WHERE NAME=”Pycharm” AND sex=”女”; DELETE FROM stu WHERE address=”北京”; DELETE FROM temp1; — 清空表 TRUNCATE TABLE temp2; — 清空表
Update Data
UPDATE stu SET math=12, english=98 WHERE NAME=”支付宝”; UPDATE stu SET NAME=”Chrome”, english=NULL WHERE NAME=”Pornhub” AND sex=”女”;
UPDATE stu SET NAME=”学习强国”; — 不加条件将改变所有数据的某字段
/ DQL /
Retrieve
SELECT * FROM stu; — 全字段查询 SELECT — 多字段查询 NAME, — 姓名 age — 年龄 FROM stu; — stu表 SELECT DISTINCT address FROM stu; — 去重 SELECT NAME, math, english, math + english FROM stu; — 计算 SELECT NAME, math, english, math + IFNULL(english, 0) FROM stu; — 计算, 防止出现NULL导致结果异常 SELECT NAME, math, english, math + IFNULL(english, 0) AS total FROM stu; — 起别名
Conditioned Retrieve
SELECT FROM stu WHERE age<= 20; SELECT FROM stu WHERE age BETWEEN 20 AND 50; — 查询数值在某个范围中 SELECT FROM stu WHERE age>=20 AND age<=50; — 与上面语句等价 SELECT FROM stu WHERE age IN(42, 43); — 查询数值等于某些特定值的数据 SELECT FROM stu WHERE age=42 OR age=43; — 与上面语句等价 SELECT FROM stu WHERE english IS NULL; SELECT FROM stu WHERE NAME LIKE “微_”; — 模糊查询:微字开头的 SELECT FROM stu WHERE NAME LIKE “_“; — 模糊查询:三个字的 SELECT * FROM stu WHERE NAME LIKE “%易%”; — 模糊查询:含有易字的
Select by Order
SELECT FROM stu ORDER BY age; — 默认升序 SELECT FROM stu ORDER BY age ASC, math ASC; — 升序 Ascending SELECT * FROM stu ORDER BY age DESC; — 降序 Descending
Group Function
SELECT COUNT(id) FROM stu; SELECT SUM(age) FROM stu; SELECT MAX(math) FROM stu; SELECT MIN(english) FROM stu; — 刨除了NULL值 SELECT AVG(english) FROM stu;
Retrieve by Group
SELECT sex, AVG(age) FROM stu GROUP BY sex; — 男女的平均年龄 SELECT address, AVG(math), COUNT(id) FROM stu GROUP BY address; — 地区的平均数学成绩和地区人数 SELECT address, AVG(math), COUNT(id) FROM stu GROUP BY address ORDER BY COUNT(id); — 地区的平均数学成绩和地区人数,并按照地区人数从小到大排序 SELECT address, AVG(math), COUNT(id) FROM stu WHERE sex=”男” GROUP BY address ORDER BY COUNT(id); — 地区男性的平均数学成绩和地区男性人数,并按照地区男性人数从小到大排序 SELECT address, AVG(math), COUNT(id) FROM stu GROUP BY address HAVING COUNT(id)>1 ORDER BY COUNT(id); — 地区的平均数学成绩和地区人数,并按照地区人数从小到大排序
Retrieve by Pages
SELECT FROM stu LIMIT 0, 3; SELECT FROM stu LIMIT 3, 3; SELECT FROM stu LIMIT 6, 3; SELECT FROM stu LIMIT 9, 3;
TRUNCATE TABLE stu; — 清空表中的所有数据
<a name="ab5f2f8d"></a>### 2.4 DCL Data Control Language1. 管理用户```javaUSE mysql; -- 使用mysql数据库# create user '用户名'@'主机名' identified '密码'; -- 添加用户CREATE USER 'lausen'@'%' IDENTIFIED BY 'lausen'; -- 添加用户CREATE USER 'xxxo'@'localhost' IDENTIFIED BY 'xxxo'; -- 添加用户DROP USER "xxxo"@"localhost"; -- 删除用户SELECT * FROM USER; -- 查询用户# 修改密码的两种方式UPDATE USER SET PASSWORD = PASSWORD('senlau') WHERE USER='lausen'@'%';SET PASSWORD FOR 'lausen'@'%' = PASSWORD('lausen'); -- 使用 PASSWORD(*) 函数进行加密
忘记root用户的密码
- 停止 mysql 服务:用管理员身份运行cmd,
net stop mysql - 无验证方式启动 mysql 服务:
mysqls --skip-grant-tables 在 cmd 中修改密码
> mysql > use mysql; > SET PASSWORD FOR "root"@"%" = PASSWORD("新密码");关闭 cmd 窗口,在任务管理器中手动关闭 mysqld 服务
- 停止 mysql 服务:用管理员身份运行cmd,
- 权限管理
java SHOW GRANT FOR 'lausen'@'%'; -- 查看权限 GRANT SELECT, DELETE, UPDATE ON blogs.users TO 'lausen'@'%'; -- 授予权限 GRANT ALL ON *.* TO 'lausen'@'%'; -- 授予全部权限 REVOKE SELECT, DELETE, UPDATE ON blogs.users FROM 'lausen'@'%'; -- 撤销权限 GRANT ALL ON *.* FROM 'lausen'@'%'; -- 撤销全部权限
3. MySQL 的约束
约束:对表中的数据进行限定,保证数据的正确性、完整新、合法性
- 主键约束:
- 创建时添加主键约束:
primary key - 创建完之后添加主键约束:
alter table 表名称 modify 字段名 数据类型 primary key; - 创建完之后删除主键约束:
alter table 表名称 drop primary keyl;(无须指定主键名)
- 联合主键:
primary key(主键1, 主键2),两个主键的组合不可重复 - 一张表只能有一个字段为主键,代表表中记录的唯一标识,非空且唯一
- 自动增长
auto_increment:用insert into语句插入条目时,当主键的值为NULL,会自动加1
- 创建时添加主键约束:
- 非空约束
- 创建时添加非空约束:
not null - 创建完之后添加非空约束:
alter table 表名称 modify 字段名 数据类型 not null; - 创建完之后删除非空约束:
alter table 表名称 modify 字段名 数据类型;
- 创建时添加非空约束:
- 唯一约束
- 创建时添加非空约束:
unique - 创建完之后添加非空约束:
alter table 表名称 modify 字段名 数据类型 unique; - 创建完之后删除非空约束:
alter table 表名称 drop index 字段名;
- 创建时添加非空约束:
外键约束:foreign key
- 两个表产生关系,从而保证表的正确性
创建表时添加外键:
mysql create table 表名称( 字段名称 数据类型, ..., 外键字段名 数据类型, constraint 外键名称 foreign key 外键字段名 references 主表名称(主表字段名) );- 创建表之后添加外键:
alter table 表名 drop foreign key 外键名称; - 创建表之后删除外键:
alter table 表名称 add constraint 外键名称 foreign key (外键字段名) references 主表名称(主表主键名);
- 创建表之后添加外键:
- 外键字段与所关联的主表字段的数据类型必须相同,否则无法成功添加。
- 不能清空被关联的主表;
- 只有删除了定义外键的表后,才能删除被关联的主表。
- 主键约束:
- 级联
- 语法:级联更新
on update cascade或 级联删除on delete cascade - 在主表改被引用的字段的值时,定义外键的表中的数据也会随之改变
- 使用SQL语句添加时,非空约束的字段如果是数字类型的会被映射为0,其他类型的会被映射为
""空字符串。所以通过SQL语句添加条目时,主键可以输入NULL(但多个NULL会被判别为重复),非空约束也可以输入NULL。但是使用SQLyog终端添加时NULL就是NULL
- 语法:级联更新
- 约束案例
- 设置约束```java DROP TABLE IF EXISTS brands; CREATE TABLE IF NOT EXISTS brands( id INT PRIMARY KEY AUTO_INCREMENT, — 主键必然not null 且 unique NAME VARCHAR(20) NOT NULL, — 非空字符串 age INT NOT NULL, — 非空数值 phone VARCHAR(20) UNIQUE — 唯一约束 );
ALTER TABLE brean DROP PRIMARY KEY; — 删除主键约束 ALTER TABLE brand MODIFY id INT; — 删除自动增长 ALTER TABLE brean MODIFY age INT; — 删除非空约束 ALTER TABLE brean DROP INDEX phone; — 删除唯一约束 ALTER TABLE brean MODIFY id INT PRIMARY KEY; — 添加主键约束 ALTER TABLE brand MODIFY id INT AUTO_INCREMENT; — 添加自动增长 ALTER TABLE brean MODIFY age INT NOT NULL; — 添加非空约束 ALTER TABLE brean MODIFY id INT UNIQUE; — 添加唯一约束
TRUNCATE TABLE brands; INSERT INTO brands VALUES (1, “当当”, 11, “13600001111”), (2, “京东”, 21, “13600001112”), (3, “阿里”, 43, “13600001113”),
(4, “阿里巴巴”, 65, 600001113”), — phone字段有唯一约束,不可重复
(NULL, “阿里巴巴”, 51, “13600001114”), — 主键给空值默认为0,主键不可重复
(NULL, “阿里妈妈”, 43, “13600001115”), — 两个主键默认设为0,导致重复
(5, NULL, NULL, “13600001115”) — 非空的位置插入空值仍然可以成功添加,默认为空 ;
2. 设置级联更新和级联删除```java
USE db2;
DROP TABLE IF EXISTS curriculums;
DROP TABLE IF EXISTS staffs; -- 只有先删除包含外键约束的表,才能删除被索引的表
CREATE TABLE IF NOT EXISTS staffs( -- 要先创建主表
id INT PRIMARY KEY AUTO_INCREMENT, -- 自增
teacher VARCHAR(20) UNIQUE,
school VARCHAR(100)
);
CREATE TABLE IF NOT EXISTS curriculums(
id INT PRIMARY KEY AUTO_INCREMENT,
course_code VARCHAR(100) UNIQUE,
course VARCHAR(100) NOT NULL,
teacher_id INT,
CONSTRAINT teacher_id_fk FOREIGN KEY (teacher_id) REFERENCES staffs(id) -- 添加外键
ON UPDATE CASCADE ON DELETE CASCADE -- 设置外键的级联更新和级联删除
);
TRUNCATE TABLE curriculums;
# truncate table stuffs; -- 无法清空被索引的表
INSERT INTO staffs
VALUES
(NULL, "刘森", "自动化"),
(NULL, "刘方", "自动化"),
(NULL, "刘航", "网安"),
(NULL, "刘韩", "自动化")
;
INSERT INTO curriculums
VALUES
(NULL, "000000", "空气动力学", 4),
(NULL, "111111", "密码学", 3),
(NULL, "222222", "数据库", 3),
(NULL, "333333", "PID控制", 2),
(NULL, "444444", "MatLab仿真", 1),
(NULL, "555555", "Python大数据", 2),
(NULL, "666666", "算法与数据结构", 3)
;
ALTER TABLE curriculums DROP FOREIGN KEY teacher_id_fk; -- 删除外键
ALTER TABLE curriculums
ADD CONSTRAINT teacher_id_fk
FOREIGN KEY (teacher_id) REFERENCES staffs(id) -- 添加外键
ON UPDATE CASCADE ON DELETE CASCADE -- 设置外键的级联更新和级联删除
; -- 添加外键,并设置级联操作
UPDATE staffs SET school="网络空间安全" WHERE school="网安"; -- 修改主表中没被引用的字段
UPDATE staffs SET id=0 WHERE id=4; -- 修改主表中被引用的字段
DELETE FROM staffs WHERE id=2; -- 删除主表中被引用的字段,设置外键的表中对应数据也被删除
SELECT * FROM curriculums;
SELECT * FROM staffs;
- 多表关系
- 一对一:直接用一张表实现;在任意一方添加外键指向另一方的主键,并且指定外键唯一
- 一对多 / 多对一:在“多”方添加外键指向“一”方的主键
- 多对多:需要借助一张中间表,该表包含两个字段为外键,分别指向两张表的主键
- 多表关系举例
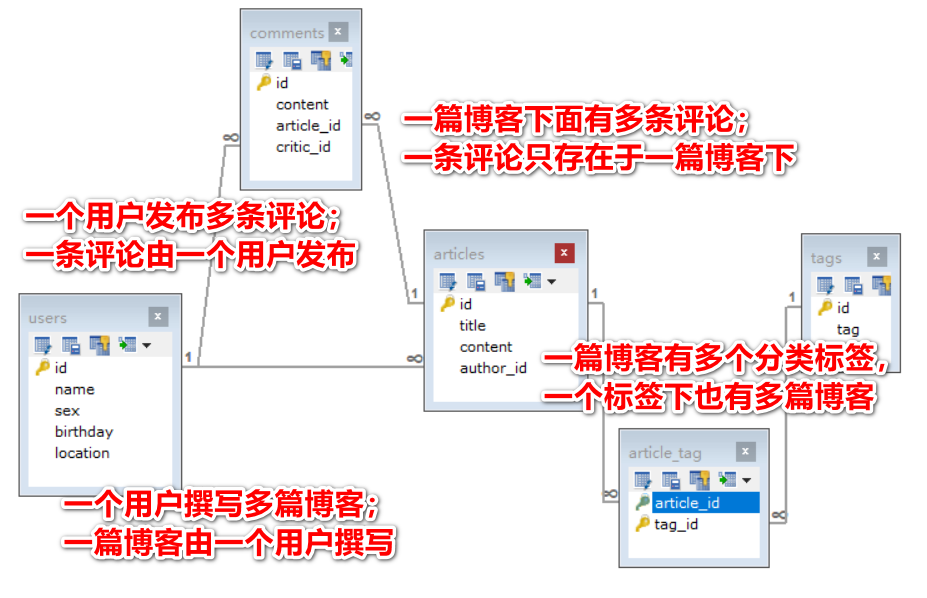
- 用户与博客之间是一对多的关系,用外键链接
- 评论与用户、博客是多对一的关系,分别用外键链接
- 博客与标签是多对多的关系,需要引入另外的表来表示对应关系
- 数据库设计范式
- 1NF:不合并复合列
- 2NF:在INF的基础上,非主属性必须依赖与主属性
- 函数依赖:通过A属性(属性组)的值可以确定唯一B属性的值,B依赖于A
- 部分函数依赖:B属性依赖于A属性组中的部分属性值
- 完全函数依赖:B属性依赖于A属性组中的全部属性值
- 传递函数依赖:A —> B,B —> C
- 码:被其他所有属性完全依赖的一个属性(属性组)
- 主属性:码属性组中的其他属性
- 非主属性:除主属性外的其他属性
- 函数依赖:通过A属性(属性组)的值可以确定唯一B属性的值,B依赖于A
- 3NF:在2NF的基础上,消除传递依赖
- 数据库的备份与还原
- 备份为
.sql文件mysqldump -uroot -ppassword 待备份数据库名 > 保存地址(不以分号结尾) - 还原
- 打开数据库
mysql -uroot -ppassword - 创建新数据库
create database if not exists 数据库名; - 使用新数据库
use 数据库名; - 读取备份数据
source 备份地址(不以分号结尾)
- 打开数据库
- 备份为
4. MySQL 的多表查询与事务
- 笛卡尔积
- 格式:
select * from 表1名称, 表2名称; - 两个集合的所有组成情况
- 要完成多表查询,需要消除无用的数据条目
- 格式:
内连接
隐式内连接
java select 字段列表 from 表1名称, 表2名称 where 条件 ;显式内连接
java select 字段列表 from 表1名称 inner join 表2名称 on 条件 where 条件 ;内连接查询:从哪些表中查询数据;条件是什么;查哪些字段
外连接
左外查询:查询左表中所有数据,以及其交集部分
java select 字段列表 from 表1名称 left outer join 表2名称 on 条件 where 条件 ;右外查询:查询右表中所有数据,以及其交集部分
java select 字段列表 from 表1名称 right outer join 表2名称 on 条件 where 条件 ;
子查询:在查询中嵌套查询
- 子查询结果单行单列:作为条件,用比较运算符
- 子查询结果多行单列:作为条件,用
IN - 子查询结果多行多列:不可以作为条件,可以作为一张虚拟表参与查询
java select 字段列表 from 表1名称, (select 字段列表 from 表2名称 where 条件) where 条件 ;
综合案例:优化后的博客管理系统
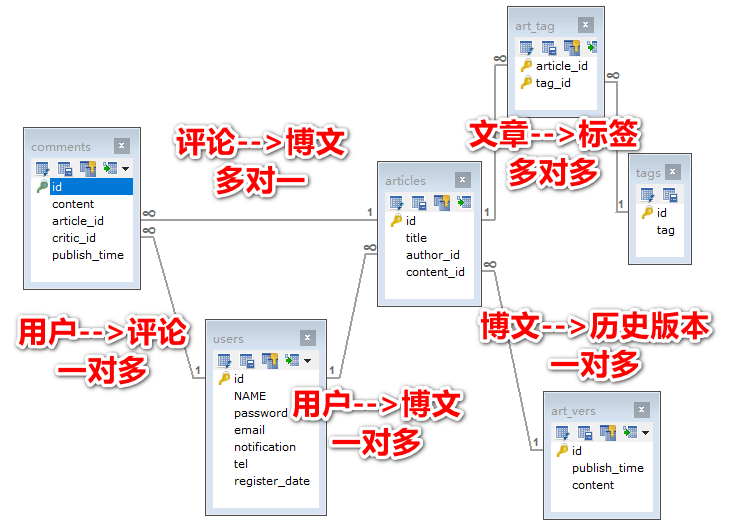
- 建库建表```java DROP DATABASE blogs; CREATE DATABASE IF NOT EXISTS blogs; USE blogs;
CREATE TABLE IF NOT EXISTS users( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(20) NOT NULL, PASSWORD VARCHAR(50) NOT NULL, email VARCHAR(20), — 注册邮箱 tel VARCHAR(20), — 验证手机号 notification BOOL, — 是否开启邮件提醒功能 register_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP — 用户注册时间 );
CREATE TABLE IF NOT EXISTS articles( id INT PRIMARY KEY AUTO_INCREMENT, author_id INT, — 博文作者 FOREIGN KEY (author_id) REFERENCES users(id) ON UPDATE CASCADE );
CREATE TABLE IF NOT EXISTS art_vers( id INT PRIMARY KEY AUTO_INCREMENT, publish_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP, — 文章发布时间 title VARCHAR(100) NOT NULL, content VARCHAR(500), — 记录文章的历史版本, article_id INT, FOREIGN KEY (article_id) REFERENCES articles(id) ON UPDATE CASCADE );
CREATE TABLE IF NOT EXISTS comments( id INT PRIMARY KEY AUTO_INCREMENT, content VARCHAR(100), — 评价内容 article_id INT, — 评论到那篇文章 critic_id INT, — 发出评论的用户 publish_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP, — 评论发出时间 FOREIGN KEY (article_id) REFERENCES articles(id) ON UPDATE CASCADE, FOREIGN KEY (critic_id) REFERENCES users(id) ON UPDATE CASCADE );
CREATE TABLE IF NOT EXISTS tags( id INT PRIMARY KEY AUTO_INCREMENT, tag VARCHAR(10) — 博文分类标签 ); CREATE TABLE IF NOT EXISTS art_tags( article_id INT, tag_id INT, PRIMARY KEY(article_id, tag_id), — 标题和标签的组合不能重复,不可为空 FOREIGN KEY (article_id) REFERENCES articles(id) ON UPDATE CASCADE, FOREIGN KEY (tag_id) REFERENCES tags(id) ON UPDATE CASCADE );
2. 添加数据```java
/* 注册用户
前端输入个人信息进行注册,
将信息保存到user表中,并自动分配 user id
*/
INSERT INTO
users(NAME, PASSWORD, email, tel) -- 必填信息
VALUES
("加鲁鲁兽", "jialulu", "jialulu@smbb.com", NULL),
("迦楼达兽", "jialouda", "jialouda@smbb.com", NULL),
("暴龙兽", "baolongshou", NULL, "12306")
;
/* 用户登录
提供用户名和密码,如果对应则可成功登陆
*/
SELECT id FROM users WHERE NAME="迦楼达兽" AND PASSWORD="jialouda";
/* 修改信息
修改用户名(保证用户名没有被占用)、邮箱、电话、提醒设置等
*/
SELECT id FROM users WHERE NAME="天女兽"; -- 查询是否已有同名用户
UPDATE users SET NAME="天女兽" WHERE NAME="暴龙兽"; -- 在系统内部应该是拿着用户id走,而不是用户名
/* 撰写博文
分配博文id,填写作者id
并将博文填入历史版本库中
给博文添加分类标签
*/
# 作者3写了一篇博文,有三个历史版本
INSERT INTO articles(author_id) VALUES (3); -- 获取当前文章对应的序号为1
INSERT INTO art_vers(title, content, article_id)
VALUES
("如何评价《小时代》?",
"今天我们大家之所以欢聚在这里,是为我们从小到大的好朋友顾里,庆祝她的生日。今天,我要敬我的好姐妹,感谢她,分享我的悲惨人生。我也发自内心地祝愿她,从此以后,和我的人生一样,开始发烂,发臭!",
1
), -- 每篇文章的历史版本对应同一个号码
("《小时代》的经典台词",
"你别跟我讲友情!你现在这么歇斯底里是在跟我讲友情吗?不是,林萧。你是为了个男人!你以为你还是个十几岁大的小女孩啊?一个男人比天大!没有男人你就活不了啦?你就活该被男人折磨!被男人甩!",
1
), -- 每篇文章的历史版本对应同一个号码
("《小时代》的经典台词",
"别幼稚了行吗?你几岁啊?你真的以为这些东西不值钱啊?我告诉你,没有物质的爱情只是一盘沙,都不用风吹,走两步路就散了。如果今天我只是个领补助金的学生,你顾源会爱我吗!",
1) -- 每篇文章的历史版本对应同一个号码
;
# 新标签需要先在tags表中录入
INSERT INTO tags(tag) VALUE("青春伤痛文学"), ("矫情"), ("电视剧");
INSERT INTO art_tags
VALUES -- 子查询
(1, 1),
(1, 2),
(1, 3)
;
# 作者1写了两篇博文,有两个历史版本
INSERT INTO articles(author_id) VALUES (1); -- 获取当前文章对应的序号为2
INSERT INTO art_vers(title, content, article_id)
VALUES
("如何评价《破产姐妹》?",
"Listen, everybody's broke in their 20s, and everybody hides form stuff, you run into freezers, I practice ignorance and blackout drinking.",
2
);
INSERT INTO tags(tag) VALUE("喜剧"), ("美剧");
INSERT INTO art_tags
VALUES -- 子查询
(2, 3),
(2, 4),
(2, 5)
;
INSERT INTO articles(author_id) VALUES (1); -- 获取当前文章对应的序号为3
INSERT INTO art_vers(title, content, article_id)
VALUES
("《甄嬛传》的经典台词",
"其实这后宫里头啊,从来就只有一棵树,只是乱花渐欲迷人眼罢了,只要你看得清,哪棵是树哪朵是花就好了。",
3),
("如何评价《甄嬛传》?",
"太后行事一向有分寸,后宫的事她从不多管,但只要管了,必定是她看不过眼的大事。此番严惩,就是要告诉后宫,不要再这样乌烟瘴气。",
3)
;
INSERT INTO art_tags
VALUES -- 子查询
(3, 3)
;
/* 发表评论
用户(user id)对文章(article id)下发表评论
分配评论id,以及记录评论时间
*/
INSERT INTO comments(content, article_id, critic_id)
VALUES
("今天是顾里的生日吗?", 1, 3),
("这电影拍得太尴尬了!", 1, 2),
("一点都不好看,不喜勿喷。", 1, 2),
("现在是钮祜禄氏,甄嬛!", 2, 3),
("老子写的,爱看看不爱看滚!", 2, 2),
("这片子可没《小时代》好看。", 3, 1),
("楼上的,捧一踩一给爷滚!", 3, 2)
;
SELECT * FROM users;
SELECT * FROM articles;
SELECT * FROM art_vers;
SELECT * FROM comments;
- 查询数据```java / 查询某个作者的全部博文 使用 user id 进行查询 /
SELECT u.NAME, v.title, v.content, v.publish_time FROM users AS u RIGHT OUTER JOIN — 右外连接 articles AS a ON a.author_id=u.id RIGHT OUTER JOIN — 右外连接 art_vers AS v ON v.article_id=a.id WHERE u.id = 1 ;
/ 查询某个标签下的全部博文
使用tag id
用中间过渡表进行查询
/
SELECT
t.tag, a_v.title, a_v.publish_time
FROM — 要把中间表放到 from 语句部分
(art_tags AS a_t, art_vers AS a_v) — 要把联合的表括起来
RIGHT OUTER JOIN
articles AS a ON a.id = a_t.article_id AND a.id=a_v.article_id
RIGHT OUTER JOIN
tags AS t ON t.id = a_t.tag_id
WHERE
t.id = 3
;
/ 显示某篇文章的全部tags 给定文章的id 使用从中间表,进行子查询获取全部标签 / SELECT tag FROM tags WHERE id IN ( SELECT tag_id FROM art_tags WHERE article_id=1 );
/ 查询评论 给定用户id,获取该用户发出的全部评论 并且使用模糊匹配,检测敏感词/关键词等 / SELECT users.NAME, content, publish_time FROM comments INNER JOIN users ON users.id=2 WHERE critic_id=2 AND content LIKE “%滚%” ;
6. 事务
1. 概念:开启事务的操作,如果出现异常会回滚,否则提交事务;被事务管理的操作,要么全部失败,要么全部成功```mysql
START TRANSACTION; -- 开启事务
/*
具体数据库操作
*/
ROLLBACK; -- 回滚事务
COMMIT; -- 提交事务
1. 查询事务提交方式 `SELECT @@autocommit;` ,结果为1代表自动提交,0代表手动提交
2. 修改事务提交方式 `SET @@autocommit = 0;`
- 事务四大特征【面试常考】
- 原子性:是不可分割的最小操作单位,要么同时成功,要么同时失败
- 持久性:当事务提交后或回滚后,数据库会持久化的保存数据
- 隔离性:多个事务之间,相互独立
- 一致性:事务操作前后,数据的总量不变
5. JDBC Java数据库连接
- JDBC Java Data Base Connectivity
- Sun定义类一套操作所有关系型数据库的规则,即接口
- 各个公司的SQL不同,会实现对应的接口实现类,提供数据库驱动 jar 包
- 使用多态定义接口实现类,真正执行的是驱动 jar 包中实现类中的方法
DriverManager 驱动管理
注册驱动:
Class.forName("com.mysql.cj.jdbc.Driver");
在com\\mysql\\cj\\jdbc\\Driver.java文件中,使用了静态代码块,在导入包的时候就执行static void registerDriver(Driver driver),注册驱动管理对象java static { try { DriverManager.registerDriver(new Driver()); } catch (SQLException var1) { throw new RuntimeException("Can't register driver!"); } }获取链接
格式:static Connection getConnection(String url, String user, String password)URL:连接路径
- 格式:
jdbc:mysql://ip地址(域名):端口号/数据库名称 - 可能需要设置时区:
java conn = DriverManager.getConnection( "jdbc:mysql://localhost:3306/blogs?serverTimezone=UTC", // 设置时区 "root", "mysql");
- 格式:
user:用户名
- password:密码
- Connection 数据库连接
- 获取执行 sql 的对象
Statement createStatement()PreparedStatement PreparedStatement(String sql)
- 管理事务对象
- 开启事务:
void setAutoCommit(boonlean autoCommit)设置参数为 false,开启事务手动提交 - 提交事务:
commit() - 回滚事务:
rollback()
- 开启事务:
- 获取执行 sql 的对象
- Statement 执行 sql 的对象
boolean execute(String sql)int executeUpdate(String sql)可执行DDL(通常用SQL直接创建库和表,而不通过java程序写)、DML语句;返回值为影响的行数ResultSet executeQuery(String sql)执行DQL查询语句,返回封装了封装了查询结果的ResultSet对象
- ResultSet
boolean next()光标移向下一行(光标最初位于表头)- 判断有数据返回 true
- 判断无数据返回 false
Xxx getXxx(参数)获取某一行的某一列数据- Xxx 是所需要获取的数据类型
- 方法重载中的两种参数列表
- int 类型:columnIndex,从1索引
- String 类型:columnLable
- PreparedStatement
- SQL 注入问题:在拼接sql语句时,一些特殊关键字参与字符串拼接,可能造成安全性问题
- 预编译SQL:参数使用
?作为占位符 - 使用方法
- 用
?作为参数占位符来定义 sql 语句:String sql = "select * from user where username = ? and password = ?;"; - 在定义 PreparedStatement 的时候就要传入 sql语句:
PreparedStatement pstmt = Connection.prepareStatement(sql); - 为参数赋值
SetXxx(int parameterIndex, Xxx x)其中 Xxx 代表数据类型,而 parameterIndex 代表参数的序号,从1开始索引 - 执行 sql
- 执行更新:
Int excuteUpdate() - 执行查询:
ResultSet excuteQuery()
- 执行更新:
- 使用完之后,也需要释放 PreparedStatement 对象
- 用
实例三则
使用Java创建表,增、删、改、查表```java public static void main(String[] args) { Statement stmt = null; Connection conn = null;
try { Class.forName(“com.mysql.cj.jdbc.Driver”); // 注册驱动 conn = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/blogs?serverTimezone=UTC", "root", "mysql"); // 获取数据库连接stmt = conn.createStatement(); // 获取执行 sql 的对象
// 创建 String sql0 = “create table if not exists temp(id int primary key auto_increment, tag varchar(100));”; int count0 = stmt.executeUpdate(sql0); // 插入 String sql1 = “insert into temp(tag) values(‘KongFu’), (‘SciFic’);”; int count1 = stmt.executeUpdate(sql1); // 更新 String sql2 = “update temp set tag=’功夫’ where tag=’KongFu’;”; int count2 = stmt.executeUpdate(sql2); // 删除 String sql3 = “delete from temp where tag in(‘功夫’, ‘SciFic’);”; int count3 = stmt.executeUpdate(sql3); // 删表 String sql4 = “drop table if exists temp;”; int count4 = stmt.executeUpdate(sql4);
} catch (ClassNotFoundException e) { e.printStackTrace(); } catch (SQLException e) { e.printStackTrace(); } finally { // 释放资源 if (stmt != null) {
try { stmt.close(); } catch (SQLException throwables) { throwables.printStackTrace(); }} if (conn != null){
try { conn.close(); } catch (SQLException throwables) { throwables.printStackTrace(); }} } } ```
使用Java查询表。将表中的字段作为类的属性,每条数据创建为类的实例,用方法承载```mysql public static LinkedList
findAll() { Connection conn = null; Statement stmt = null; ResultSet rs = null; LinkedList users = null; try { Class.forName(“com.mysql.cj.jdbc.Driver”); conn = DriverManager.getConnection(
"jdbc:mysql://localhost:3306/blogs?serverTimezone=UTC", "root", "mysql");stmt = conn.createStatement();
String sql = “select * from users;”; rs = stmt.executeQuery(sql);
users = new LinkedList<>(); while(rs.next()) {
users.add(new User( rs.getInt("id"), rs.getString("name"), rs.getString("password"), rs.getString("email"), rs.getInt("tel"), // 数据中的NULL,getString得到"null",getInt得到 0 rs.getString("register_date") ));} } catch (ClassNotFoundException e) { e.printStackTrace(); } catch (SQLException e) { e.printStackTrace(); } finally { if (stmt != null) {
try { stmt.close(); } catch (SQLException e) { e.printStackTrace(); }} if (conn != null) {
try { conn.close(); } catch (SQLException e) { e.printStackTrace(); }} if (rs != null) {
try { rs.close(); } catch (SQLException e) { e.printStackTrace(); }} } return users; } ```
事务管理:使用 Connection 对象来管理事务```java public static void main(String[] args) { Connection conn = null; PreparedStatement pstmt1 = null; PreparedStatement pstmt2 = null; PreparedStatement pstmt3 = null; PreparedStatement pstmt4 = null;
try { conn = JDBCUtils.getConnection(); // 开启事务
conn.setAutoCommit(false); // 关闭自动提交,设置手动提交 String sql1 = “create table if not exists temp(id int primary key auto_increment, tag varchar(10));”; // String sql2 = “insert into temp(tag) values(‘?’), (‘?’), (‘?’), (‘?’);”; 里面的问号占位符不能带引号 String sql2 = “insert into temp(tag) values(?), (?), (?), (?);”; String sql3 = “update temp set tag=? where id=?;”; String sql4 = “drop table if exists temp;”;
pstmt1 = conn.prepareStatement(sql1); pstmt2 = conn.prepareStatement(sql2); pstmt3 = conn.prepareStatement(sql3); pstmt4 = conn.prepareStatement(sql4);
pstmt2.setString(1, “java”); pstmt2.setString(2, “python”); pstmt2.setString(3, “c++”); pstmt2.setString(4, “golang”); pstmt3.setString(1, “c#”); pstmt3.setInt(2, 3);
pstmt1.executeUpdate(); pstmt2.executeUpdate(); pstmt3.executeUpdate(); pstmt4.executeUpdate();
conn.commit(); // 提交任务 } catch (SQLException e) { if (conn != null) {
try { conn.rollback(); } catch (SQLException throwables) { throwables.printStackTrace(); }} e.printStackTrace(); } finally { try {
if (conn != null) conn.rollback();} catch (SQLException throwables) {
throwables.printStackTrace();} JDBCUtils.close(pstmt1, conn); JDBCUtils.close(pstmt2, null); JDBCUtils.close(pstmt3, null); JDBCUtils.close(pstmt4, null); } } ```
抽取JDBC工具类:JBDCUtils
- 将关闭资源的功能(代码太长,并且每次连接都要写)抽取出
- 将注册驱动、创建连接的功能抽取出;为了方便在不同场景下改变参数,使用配置文件(而不使用硬编码),用 Properties 类来读取参数 ```java public class JDBCUtils { // 在静态代码块中读取配置 private static String url; private static String name; private static String password; private static String driver;
static { try {
Properties pro = new Properties(); pro.load(new FileReader("200809\\src\\jdbc.properties")); url = pro.getProperty("url"); name = pro.getProperty("name"); driver = pro.getProperty("driver"); password = pro.getProperty("password"); Class.forName(driver); // 注册驱动} catch (ClassNotFoundException e) {
e.printStackTrace();} catch (IOException e) {
e.printStackTrace();} }
// 连接数据库 public static Connection getConnection() throws SQLException { return DriverManager.getConnection(
"jdbc:mysql://localhost:3306/blogs?serverTimezone=UTC", "root", "mysql");}
// 关闭连接、Sql执行资源 public static void close(Statement stmt, Connection conn) { if (stmt != null) {
try { stmt.close(); } catch (SQLException e) { e.printStackTrace(); }} if (stmt != null) {
try { stmt.close(); } catch (SQLException e) { e.printStackTrace(); }} }
// 重载,增加需要关闭的ResultSet资源 public static void close(Statement stmt, Connection conn, ResultSet rs) { if (stmt != null) {
try { stmt.close(); } catch (SQLException e) { e.printStackTrace(); }} if (stmt != null) {
try { stmt.close(); } catch (SQLException e) { e.printStackTrace(); }} if (rs != null) {
try { rs.close(); } catch (SQLException e) { e.printStackTrace(); }6. 数据库连接池
数据库连接池接口
javax.sql包下的 DataSource 接口- 获取连接:
getConnection() - 归还连接:如果连接对象 Connection 是从连接池中获取,则
Connection.close()方法不再关闭连接,而是归还连接
- 数据库连接池技术:C3P0
- 导入 c3p0 的 jar 包,以及其所依赖的 jar 包
- 定义配置文件
- 文件名:
c3p0-config.xml或c3p0.properties - 放在 src 目录文件
- 文件名:
- 创建数据库连接池对象
DataSource ds = new ComboPooledDataSource(); - 获取连接
Connection getConnection()
数据库连接池技术:Druid(阿里巴巴)
java public static void main(String[] args) throws Exception { // 1. 导入jar包到当前module // 2. 定义配置文件 druid.properties // 3. 加载配置文件 Properties pro = new Properties(); // DemoDruid.class.getClassLoader()获得当前资源路径 InputStream is = Demo023.DemoDruid.class.getClassLoader().getResourceAsStream("druid.properties"); pro.load(is); // 加载配置文件,并保存到 properties 对象 // 4. 获取连接池对象 DataSource ds = DruidDataSourceFactory.createDataSource(pro); // 5. 获取连接 Connection conn = ds.getConnection(); System.out.println(conn); }Spring 对 JDBC 进行封装,简化开发
- 使用流程
- 导入 jar 包
- 创建 JdbcTemplate 对象,依赖于数据源 DataSource 对象
JdbcTemplate template = new JdbcTemplate(ds)
可以将DataSource static getDataSource()实现在 JDBCUtils 工具类中 - 调用 JdbcTemplate 的方法实现 CRUD 操作
int update(String sql, Object... args)执行DML语句,增、删、改表;如果sql语句中有?占位符,需要传入第二个参数Map<String,Object> queryForMap(String sql, Object... args)将查询一条结果封装为Map集合;字段的名为key,字段的值为value<T> List<T> queryForList(String sql, Object[] args, Class<T> elementType)将查询多条结果封装为List集合List<User> list = template.query(sql, new BeanPropertyRowMapper<User>(User.class));其中 User是自定义的类,其中的属性为表中的字段;其中最后一个参数User.class代表了 User 类,如果是 Long 类型就写Long.Class<T> T queryForObject(String sql, Class<T> requiredType)将查询结果封装为Object对象

若有收获,就点个赞吧
0 人点赞
