1. 快速生成列表
a = [i*i for i in range(1,10)] #列表生成式 list comprehension
b = list(range(10)) # range function wrapped by a call to the list constructor
注意: range()本身并不会生成列表,它只是一个可迭代对象
https://www.kancloud.cn/thinkphp/python-tutorial/37556 
a. 列表生成式(list comprehension)
- 单层的列表生成式:
- []中第一个位置为生成列表的元素,如下所示:
- i**2 即为将要生成的新列表中的元素,i必须与后面for中的迭代变量名字相同
- for循环的最后还可以加上if作为筛选条件
- 两层循环的列表生成式:
- 从第一个for循环中取第一个元素,分别与第二个for中的所有迭代元素按顺序匹配,作为新列表的第一个元素
- 即:第一轮:m先从‘ABC’中取A,n依次从‘XYZ’中取出响应的元素。因此,新列表的前三个元素就应该是:‘AX’,‘AY’,‘AZ’(当后面没有if时)
- leetcode 102用到了这个方法
alist = [i**2 for i in range(10) if i<5]print(alist)b = [m + n for m in 'ABC' for n in 'XYZ' if m >'B']print(b)

参考资料:https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/001431779637539089fd627094a43a8a7c77e6102e3a811000
b. 生成器(generator)
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果可以通过保存的某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器。(这就是所谓的“惰性”)
要创建一个生成器,有很多种方法。
- 第一种方法很简单,只要把一个列表生成式的
[]改成():

- 如果推算的算法比较复杂,用类似列表生成式的
for循环无法实现的时候,还可以用函数来实现。比如,著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数相加得到:
1, 1, 2, 3, 5, 8, 13, 21, 34, …
斐波拉契数列用列表生成式写不出来,但是,用函数把它打印出来却很容易:
def fib(max):n, a, b = 0, 0, 1while n < max:print(b) # yield b,即生成ba, b = b, a + bn = n + 1return 'done'
要把fib函数变成generator,只需要把print(b)改为yield(b)就可以了。yield的括号中,就是我们想要它生成的值。
- 但是,生成器和函数是有区别的,除了它们本身类型不同外,生成器和函数的执行流程不一样。函数是顺序执行,遇到
return语句或者最后一行函数语句就返回。而生成器在没有传参前,它仍然是一个函数,传参后其实才正式称为一个generator:它在每次调用next()的时候执行(或者for的每一次循环),遇到yield语句后暂停,再次执行时从上次的yield语句的下一句继续执行。
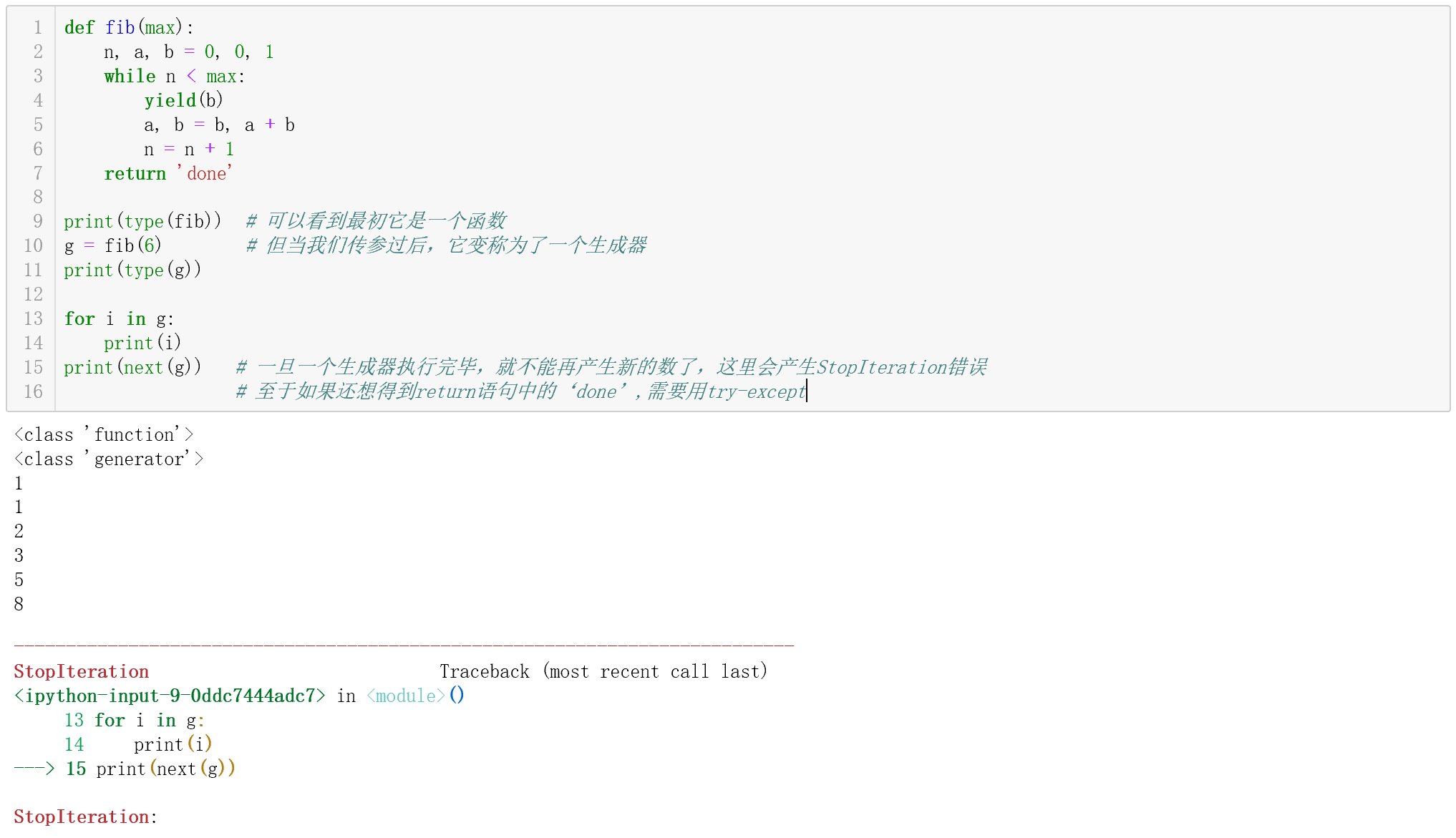
- 我们可以通过next()的方式来一个一个生成我们想要的数,但这个方式太过麻烦,由于生成器本身也是一个可迭代对象,所以我们可以使用for循环来处理这个问题 ```python print(next(g)) # 一次生成一个
for i in g: # g是生成器,是一个可迭代对象,因此可以利用for一次性全部打印出来 print(i)
参考资料:[https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/0014317799226173f45ce40636141b6abc8424e12b5fb27000](https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/0014317799226173f45ce40636141b6abc8424e12b5fb27000)<a name="e05989c1"></a>#### c. 迭代器(iterator)- 可以直接作用于`for`循环的对象统称为**可迭代对象**:`Iterable`- 可以被`next()`函数调用并不断返回下一个值的对象称为**迭代器**:`Iterator`- 我们可以使用`isinstance()`判断一个对象是否是**可迭代对象**还是**迭代器**(这是两个不同的类型)所以,列表,字典,字符串,元组都是可迭代对象,但不是迭代器。但是我们可以利用iter()函数,将它们转化成迭代器。<br /><br />参考资料:[https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/00143178254193589df9c612d2449618ea460e7a672a366000](https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/00143178254193589df9c612d2449618ea460e7a672a366000)<a name="b279e2a7"></a>### 2. Python中的False在Python中 None, False, 空字符串"", 0, 空列表[], 空字典{}, 空元组()都相当于False<br />因此在使用条件语句做判断时务必注意.<br />而对于'if x is not None'和'if not x is None'写法,最好使用前者(谷歌推荐)<a name="0ee1bf09"></a>### 3. 全局变量和局部变量函数内部的变量名如果第一次出现,且出现在=前面,即被视为定义一个局部变量,不管全局域中有没有用到该变量名,函数中使用的将是局部变量<br />函数内部的变量名如果第一次出现,且出现在=后面,且该变量在全局域中已定义,则这里将引用全局变量,如果该变量在全局域中没有定义,当然会出现“变量未定义”的错误。(https://blog.csdn.net/dongtingzhizi/article/details/8973569)<a name="70f65497"></a>### 4. 实例属性和类属性实例属性:在__init__下定义的属性; 类属性:在__init__外定义的属性,实例对象和类对象都可以调用。<br />(类对象:与类同名,但无需经过实例化的对象)<br />由于Python是动态语言,根据类创建的实例可以任意绑定属性。(只不过这个属性仅仅存在于这个实例中)<br />注意:特殊形况:当实例属性与类属性重名时,实例对象用该名字调用属性,类属性被屏蔽掉,实际调用的是实例属性。因为实例属性的优先级高。所以在编程时,千万不要对实例属性和类属性使用相同的名字(例子见下面连接,和对应的测试程序文件)<br />([https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/0014319117128404c7dd0cf0e3c4d88acc8fe4d2c163625000](https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/0014319117128404c7dd0cf0e3c4d88acc8fe4d2c163625000))<a name="90825ac9"></a>### 5. 关于用变量赋值时,引用、内存分配的问题对于数值、字符串等不可变对象(immutable type),python会重新开辟一块新的内存来生成新的对象。<br />对于列表、字典、集合等可变对象(mutable type),为了减少开销,python采用引用的方法来对新变量进行赋值。<br />如上图程序所示,对数字来说,用已有变量对新变量赋值,如果更改其中一个变量的值,另一个并不会变,因为是两个不同的对象;对列表而言,另一个变量则会改变,因为引用到的是同一个对象。<br />所有的变量引用的都是对象,赋值语句(assignment statement)其实都是重新指定了引用的方向。<br />注意:一般来说为了节省内存空间,相同数值在计算机中被分配的内存地址是一样的。但如果这个数值大于256,则对应的内存地址不一样。(称作“small int”机制,可以从python源码中了解:https://www.zhihu.com/question/27026782)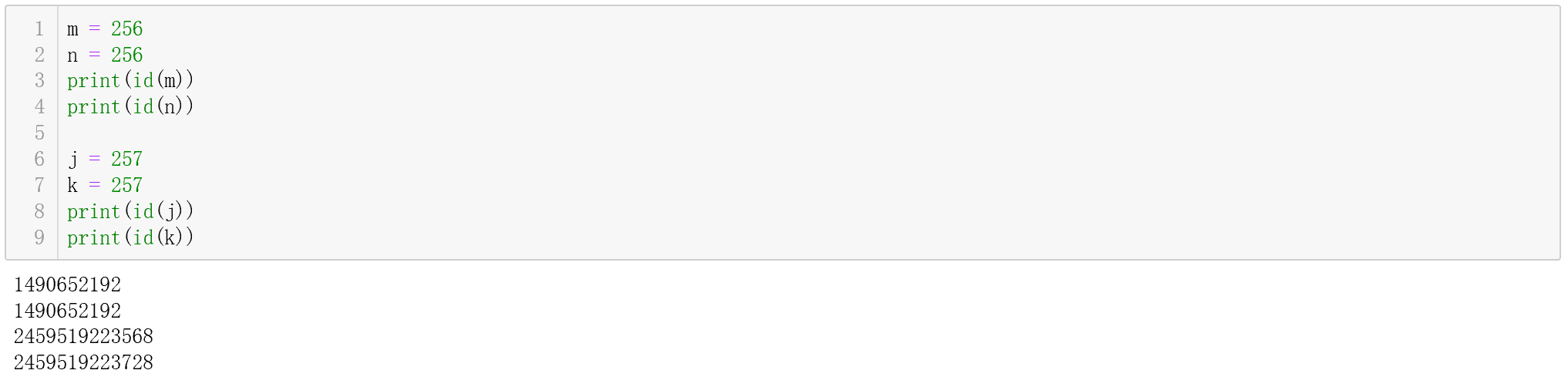<a name="9f209e9b"></a>### 6. 切片语法补充con[start_index]:返回索引值为start_index的对象。start_index为 -len(con)到len(con)-1之间任意整数。<br />con[start_index: end_index]:返回索引值为start_index到end_index-1之间的连续对象。<br />con[start_index: end_index : step]:返回索引值为start_index到end_index-1之间,并且索引值与start_index之差可以被step整除的连续对象。con[start_index: ]:缺省end_index,表示从start_index开始到序列中最后一个对象。<br />con[: end_index]:缺省start_index,表示从序列中第一个对象到end_index-1之间的片段。<br />con[:]:缺省start_index和end_index,表示从第一个对象到最后一个对象的完整片段。<br />con[::step]:缺省start_index和end_index,表示对整个序列按照索引可以被step整除的规则取值。[注意]对于序列结构数据来说,索引和步长都具有正负两个值,分别表示左右两个方向取值。索引的正方向从左往右取值,起始位置为0;负方向从右往左取值,起始位置为-1。因此任意一个序列结构数据的索引范围为 - len(consequence) 到 len(consequence)-1 范围内的连续整数。<br />(而且切片操作同样适用于元组tuple和字符串)<a name="afbc4516"></a>### 7. 字符串大小比较单个字符比较是根据ASCII码的大小比的;<br />字符串的比较是从左到右,对每个位置上的元素一一比较,如果相等则继续比较下一位,如果不等则直接得出结果。<br />eg. ab > ac 返回值为False<br />ab < abc 返回值为Ture (前两位相同,但ab没有第三位了,相当于第三位比较时是“”与c比,空的ASCII码为0,比c的ASCII码小)<a name="f6cc928d"></a>### 8. 交换变量/对象的值a, b = b, a 这是一种省略写法<a name="7577f627"></a>### 9. 常见的字符串内置函数总结<a name="12c3fd8e"></a>#### a. join函数用于将列表中的所有元素连接成一个字符串<br />语法: str.join(sequence)<br />str为每个列表元素之间的连接符,通常用空字符'',这样就能构成一个正常的字符串。sequence则是列表。<br /><a name="afd04f99"></a>#### b. count()函数统计字符串中某一字符出现的次数<br />语法:str.count(sub, start, end)<br />sub 为搜索的字符, start和end分别对应搜索的起始位置和终止位置的索引(类似列表);终止位置即使超出字符串长度,也能正常显示。<br />(注意:负数索引同样有效,不过注意start对应的位,应该在end对应的位的前面,否则根本没有搜索区间,返回值必然为0)<br /><a name="5c8d58f9"></a>#### c. replace()函数- 语法:str.replace(old, new, max)- old是要被替换的字符,new是要替换成的字符,max参数可选,指的是最多替换次数(即有可能被替换字符在字符串中多次出现),默认全部替换。- 不改变原字符串,而是返回一个新字符串!<a name="915c8cd4"></a>#### d. split()函数**str.split()** 通过指定分隔符对字符串进行分割,将分割结果放在列表中返回- 语法:split(symbol, num)- symbol指分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等- num是分割的次数,默认为-1,即全部分割<a name="fb441eb4"></a>#### e. 修改字符串大小写的函数title/upper/lower- title():首字母大写- upper():全部字母大写- lower():全部字母小写<a name="9c4c1d37"></a>#### f. 删除字符串空白的函数strip/lstrip/rstrip- 这些方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列- 但是只能删除开头或是结尾的字符,不能删除中间部分的字符- 不会对原字符串改动,而是返回新的更改后的字符串<a name="c77f6ac0"></a>#### g. 字符串的内容判断函数- [string.isalnum()](http://www.runoob.com/python/att-string-isalnum.html) 判断是否是alphanumeric的(只包含字母和数字)- string.isalpha() 判断是否只有字母- 判断只有数字的函数有多个,区别见:[http://www.runoob.com/python/att-string-isnumeric.html](http://www.runoob.com/python/att-string-isnumeric.html)<a name="17be844d"></a>### 10. 集合与set()函数s = {a, b, c} #用{}直接创建集合<br />set()函数:创建一个无序,且不含重复元素的集合(相当于只有key,但没有value的字典,它的输出也是用大括号括起来的{})<br />语法: set(iterable) 参数iterable指的是可迭代的对象:字符串、列表、字典<br />可以通过add(key), remove(key)来增加和删除元素<a name="6f89d3cf"></a>### 11. 三目运算符语法:为真时的结果 if 判定条件 else 为假时的结果 (与C++中的a ?b:c完全不同)<br />eg. a = 100 if 1<0 else 50 如果1小于0为真,则返回值为100,如果为假,则返回值为50,再将最后的返回值赋给变量a<a name="9abab887"></a>### 12. 布尔型和整型的关系True == 1, False == 0<br />因为Python中布尔型是整型的子类(subclass),且分别被定义为1和0<br />因此,利用这一性质,可以取得数字的符号位(leetcode 7)<br />eg. sign = [1,-1][x < 0]<a name="c83960bd"></a>### 13. 字符串转换为整型时,前面多余的0会自动去掉eg. int("0001") == 1<br />注意:字符串中不能有小数点,否则报错<a name="19205ffd"></a>### 14. 函数定义与调用的先后关系一般情况下,必须先定义函数,再进行调用。<br /> 但如果函数A中嵌套了一个函数B, 则函数B的定义可以放在函数A的定义之后。<a name="2255bd82"></a>### 15. 类的魔法方法:__getitem__与__setitem__- 若想要通过索引的形式得到值,则可定义__getitem__这个方法。实例对象(假定为p),可以用p[key] 取值。- 该方法中一定包含return语句!- 若想要通过索引的形式设置值,则可定义__setitem__这个方法。Reference:[http://funhacks.net/explore-python/Class/magic_method.html](http://funhacks.net/explore-python/Class/magic_method.html)- 类似的,__contains__ 用于重载in操作:例如通过in判断字典中是否存在某一个键,返回True或False<a name="20d0be8a"></a>### 16. 正负无穷float(‘inf’) 正无穷<br /> float(‘-inf’) 负无穷<br /> 注意:正负无穷与0相乘,得到的结果是nan,即“not a number”。<a name="f7d020e9"></a>### 17. return如果函数定义中的return出现在循环体中,则触发return语句之后,跳出整个循环体,且不再执行之后的所有语句,回到函数被调用的地方。<a name="8f57fd73"></a>### 18. 按位取反运算符的特殊用法~x == -x-1 (这种特性刚好可以用来表示列表中首对尾称位置的元素) 负索引性质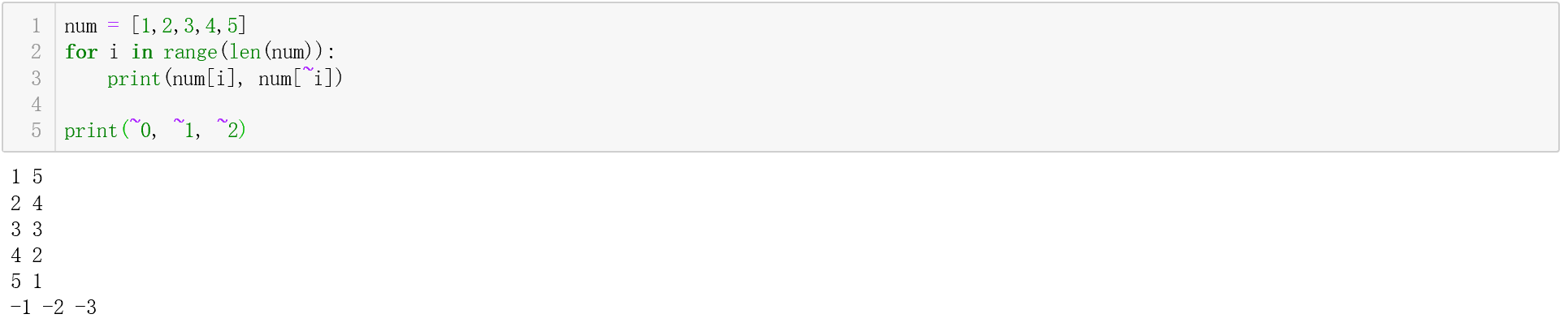<br /> 在计算机中,所有数都用补码表示(补码 = 原码按位取反 +1)。<br /> 例如:0011 1100(60)按位取反得到:1100 0011(-61),最高位为符号位。(这里的数其实都是补码)补充:原码,反码,补码(都是二进制表示,第一位是符号位)<br />- 正数:- 原码:即是将十进制转换成二进制,符号为是0- 原码、反码、补码都相同- 负数:- 原码:将十进制数的绝对值转换成二进制,符号位置1- 反码:原码的符号位不变,其余位取反- 补码:原码的符号位不变,其余位取反,再加1- 补码转原码:依然是符号位不变,其余位取反,再加1(这就是为什么“不需要额外的硬件电路”)(正常逻辑是减1,符号位不变,其余取反。虽然两种方法都行,但ALU执行计算的时候是按上面的方法。所以用补码进行计算,很大程度上简化了ALU的设计)<br />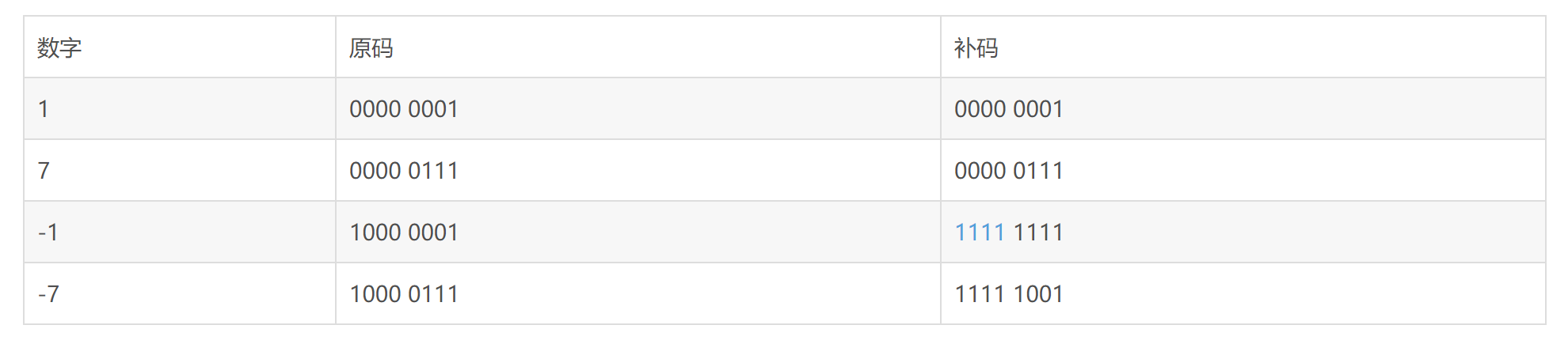<a name="126b7790"></a>### 19. sort与sorted的区别sort()是列表中的方法,只能对列表中的元素排序,即用list.sort(),直接对原列表排序<br /> sorted(iterable)用于可迭代对象,并且返回一个排序后的新列表,旧对象依然不变。因此,sorted还能给单个字符串排序,将所有字符排序后返回一个新的列表,如下所示。sorted补充:以可迭代对象中元素的某个参数或某个部分为依据进行排序<br />语法:sorted(iterable, key, reverse)<br /><br />reverse如果不指定,默认为False,按升序排列。如果reverse=True则按降序排列。(Leetcode 56)<a name="b062d65c"></a>### 20. 关于字典的键(keys)的设置字典的key必须是immutable type的对象!!!<br />int、float、str、tuple:是hashable的;list、set、dict:是unhashable的。所以当想用list作为key的时候,会出现错误:unhashable type 'list'。这个时候可以转换成字典替代。(leetcode 49)<a name="b1e4d757"></a>### 21. 关于字典的一些内置方法d.keys(),d.values(),d.items() 返回的都是视图对象(view),可以进行迭代操作,与迭代器类似。可以通过list()方法将它们列表化。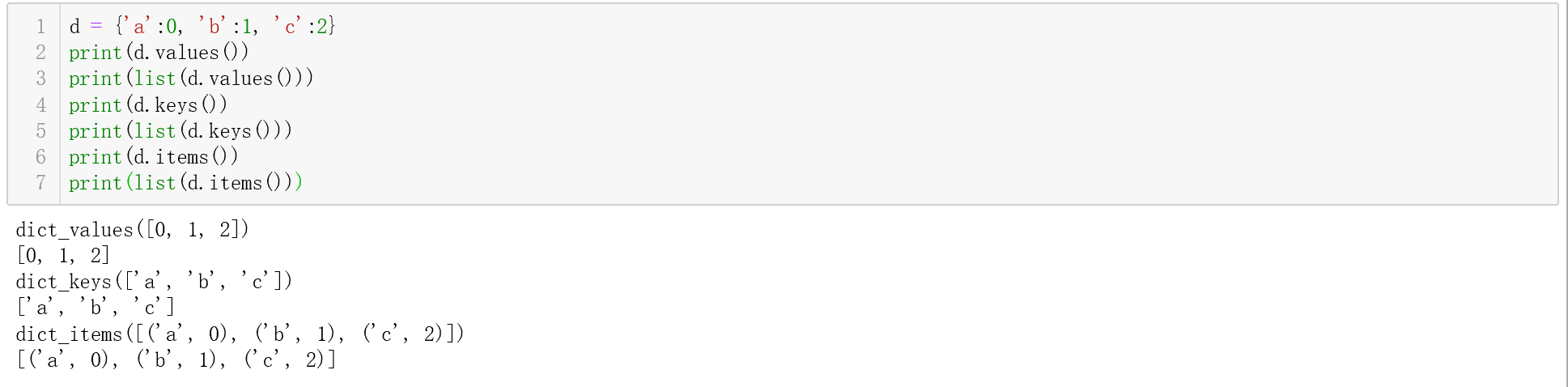<br /> d.get(key, default=None) 返回指定键对应的值,如果key不在字典中返回default值。(leetcode 49)<a name="23dcc1d3"></a>### 22. 成段的修改原列表成段的修改原有列表,且不再利用额外存储空间的方法(空间复杂度低):(leetcode 189)<br />nums[:]并非一个新的变量,它就是原有的nums,但通过这种方法,可以直接成段或整体替换原有列表。<a name="573e445f"></a>### 23. Python逻辑运算符and和or的实质在Python中,None、任何数值类型中的0、空字符串“”、空元组()、空列表[]、空字典{}都被当作False,还有自定义类型,如果实现了 __ nonzero __ () 或 __ len __ () 方法且方法返回 0 或False,则其实例也被当作False,其他对象均为True。 [https://www.cnblogs.com/an9wer/p/5475551.html](https://www.cnblogs.com/an9wer/p/5475551.html)<br />对于逻辑运算符and和or,它们并非像C++那样返回一个布尔型的值,而是返回比较双方实际值的其中之一。<br />当从左到右演算逻辑表达式的值时,使用and的话,如果表达式中的所有值都为真,那么 and 返回最后一个值;如果表达式中的某个值为假,则 and 返回第一个假值<br /> 使用or的话, 从左往右如果有一个值为真,or 立刻返回该值;如果所有的值都为假,or 返回最后一个假值<br />实际应用:leetcode21(当两个输入的链表其中有一个为空,或二者都为空时,应该返回的值)除此之外,还应该注意逻辑运算符and和or的短路问题(对于逻辑表达式,系统是从左到右执行的):- 如果and表达式中,出现了一个False,则后面的语句就不会被执行了,因为我们已经可以确定最终结果了- e.g. A and B and C,如果A是True,B是False,则C是不会被执行的- 如果or表达式中,出现了一个True,后面的就也不会被执行了- e.g. A or B or C, 如果A是False,B是True,则C是不会被执行的- 实际例子:对于链表中的循环条件判断```pythonwhile fast and fast.next:fast = fast.next.next# 如果fast恰好移到了接地处(None),再判断循环条件时,当发现第一个条件就不满足时,就跳出了循环# 所以,尽管此时fast.next是不符合逻辑的(None不是个节点),但因为程序根本不会执行这句,所以不会报错
24. 快速存储列表/元组元素到新变量中
注意:左侧变量个数,必须与列表/元组的长度相等
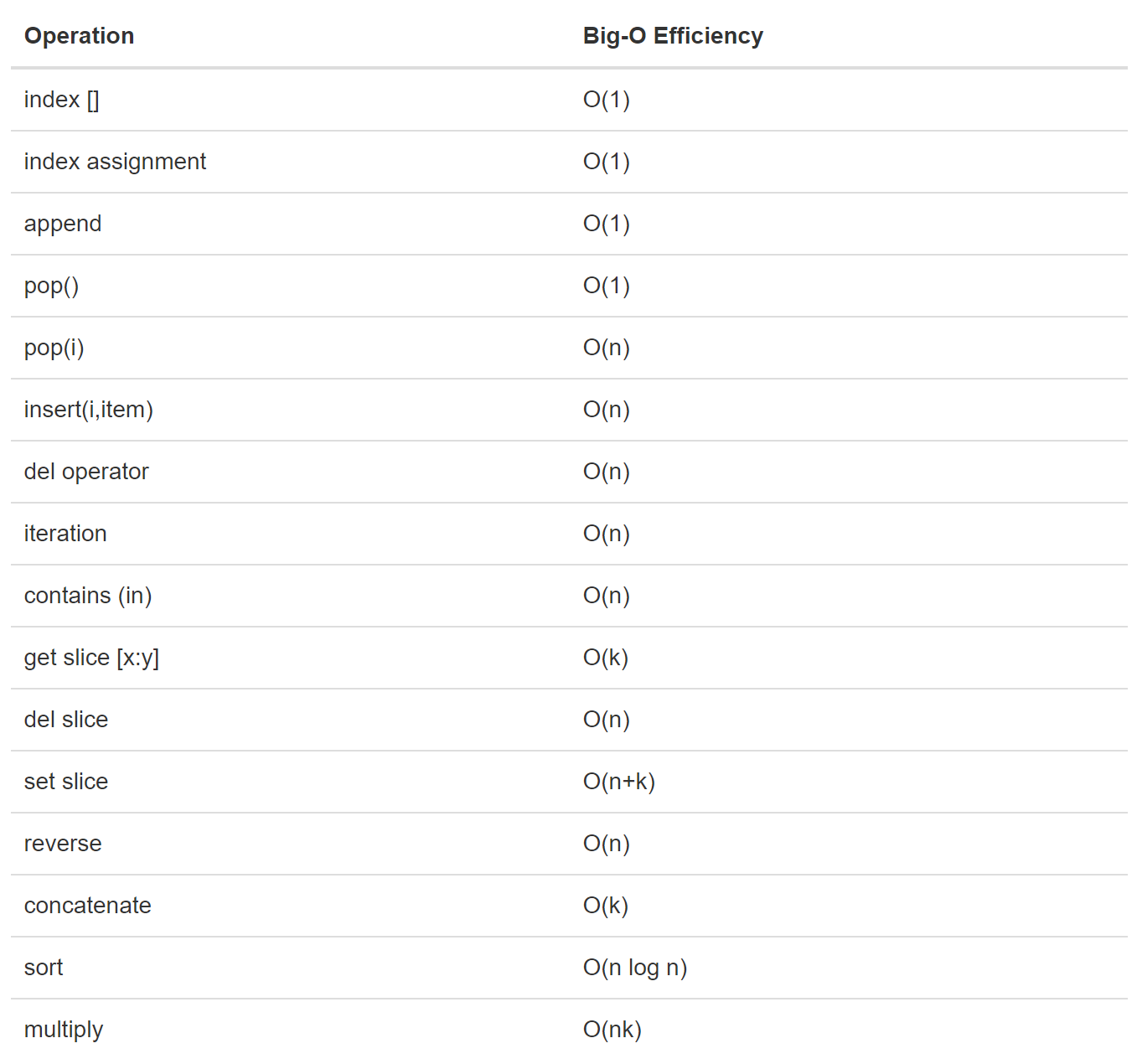
25. 各种数据结构的复杂度总结
- 列表
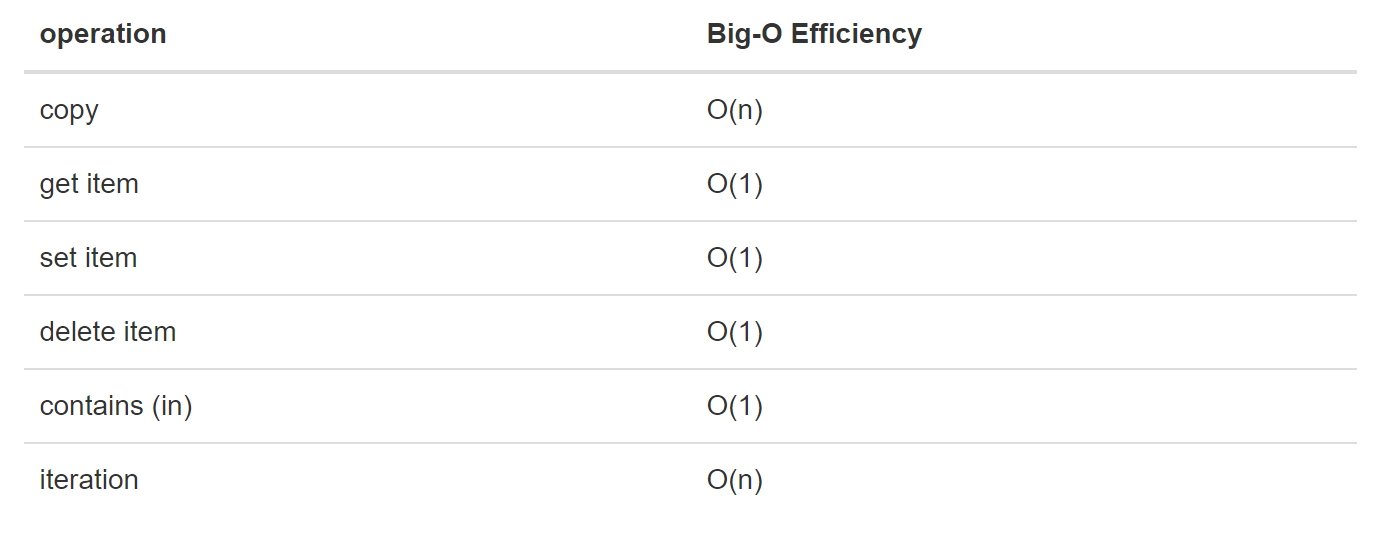
- 字典
26. is和==的区别
is在pyhton中是身份运算符,判断两个变量是不是引用自同一个对象:
- x is y 相当于判断 id(x) == id(y) ( id() 函数用于获取对象内存地址)
==判断两个变量的内容是否相等
27. Python类定义中的各种“下划线”命名
- 默认情况下,Python中的成员函数和成员变量都是公开的(public),在python中没有类似public,private等关键词来修饰成员函数和成员变量。
但是,却存在保护变量,私有变量。
其实,Python并没有真正的私有化支持,但可用下划线得到伪私有。
因此,尽量避免定义以下划线开头的变量!!!!!!!!!!!!!!!
python中的私有变量和私有方法仍然是可以访问的;访问方法如下:
- 私有变量:实例.类名_变量名
私有方法:实例.类名_方法名()
(1)xxx “单下划线 “ 开始的成员变量叫做保护变量,意思是只有类实例和子类实例能访问到这些变量,
需通过类提供的接口进行访问;不能用’from module import *’导入
(2)xxx 类中的私有变量/方法名 (Python的函数也是对象,所以成员方法称为成员变量也行得通。),
“ 双下划线 “ 开始的是私有成员,意思是只有类对象自己能访问,连子类对象也不能访问到这个数据。
(3)xxx 系统定义名字,前后均有一个“双下划线” 代表python里特殊方法/魔法方法专用的标识,如 init_()代表类的构造函数。
——————————-
原文: https://blog.csdn.net/sxingming/article/details/52875125
28. Python的垃圾回收机制(garbage collection)
1. 引用计数(reference counting)
当一个对象的引用被创建或者复制时,对象的引用计数加1;当一个对象的引用被销毁时,对象的引用计数减1;当对象的引用计数减少为0时,就意味着对象已经没有被任何人使用了,可以将其所占用的内存释放了。
引用计数+1的情况
1、对象被创建时,例如 mark="帅哥"2、对象被copy引用时,例如 mark2=mark,此时mark引用计数+13、对象被作为参数,传入到一个函数中时4、对象作为一个子元素,存储到容器中时,例如 list=[mark,mark2]
引用计数-1的情况
1、对象别名被显示销毁,例如 del mark2、对象引用被赋予新的对象,例如mark2=mark3,此时mark引用计数-1(对照引用计数+1的情况下的第二点来看)3、一个函数离开他的作用域,例如函数执行完成,它的引用参数的引用计数-14、对象所在容器被销毁,或者从容器中删除。
优点:1. 简单;2. 实时性
缺点:1. 需要额外的空间维护引用计数;2. 无法解决“循环引用”(致命缺点,例子如下)
a = { } #对象A的引用计数为 1b = { } #对象B的引用计数为 1a['b'] = b #B的引用计数增1b['a'] = a #A的引用计数增1del a #A的引用减 1,最后A对象的引用为 1del b #B的引用减 1, 最后B对象的引用为 1
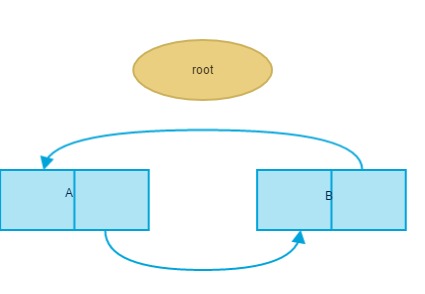在这个例子中程序执行完`del`语句后,A、B对象已经没有任何引用指向这两个对象,但是这两个对象各包含一个对方对象的引用,虽然最后两个对象都无法通过其它变量来引用这两个对象了,这对GC来说就是两个非活动对象或者说是垃圾对象,但是他们的引用计数并没有减少到零。因此如果是使用引用计数法来管理这两对象的话,他们并不会被回收,它会一直驻留在内存中,就会造成了内存泄漏(内存空间在使用完毕后未释放)。为了解决对象的循环引用问题,Python引入了标记-清除和分代回收两种GC机制。
2. 标记-清除(mark and sweep)
『标记清除(Mark—Sweep)』算法是一种基于追踪回收(tracing GC)技术实现的垃圾回收算法。它分为两个阶段:第一阶段是标记阶段,GC会把所有的『活动对象』打上标记,第二阶段是把那些没有标记的对象『非活动对象』进行回收。那么GC又是如何判断哪些是活动对象哪些是非活动对象的呢?
对象之间通过引用(指针)连在一起,构成一个有向图,对象构成这个有向图的节点,而引用关系构成这个有向图的边。从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象。根对象就是全局变量、调用栈、寄存器。

在上图中,我们把小黑圈视为全局变量,也就是把它作为root object,从小黑圈出发,对象1可直达,那么它将被标记,对象2、3可间接到达也会被标记,而4和5不可达,那么1、2、3就是活动对象,4和5是非活动对象会被GC回收。
标记清除算法作为Python的辅助垃圾收集技术主要处理的是一些容器对象,比如list、dict、tuple,instance等,因为对于字符串、数值对象是不可能造成循环引用问题。Python使用一个双向链表将这些容器对象组织起来。不过,这种简单粗暴的标记清除算法也有明显的缺点:清除非活动的对象前它必须顺序扫描整个堆内存,哪怕只剩下小部分活动对象也要扫描所有对象。
(本质:遍历以对象为节点、以引用为边构成的图,把所有可以访问到的对象打上标记,然后清扫一遍内存空间,把所有没标记的对象释放)
3. 分代回收(generation collection)
了解分类回收,首先要了解一下,GC的阈值,所谓阈值就是一个临界点的值。随着你的程序运行,Python解释器保持对新创建的对象,以及因为引用计数为零而被释放掉的对象的追踪。从理论上说,创建==释放数量应该是这样子。但是如果存在循环引用的话,肯定是创建>释放数量,当创建数与释放数量的差值达到规定的阈值的时候,当当当当~分代回收机制就登场啦。
垃圾回收=垃圾检测+释放。
分代回收思想将对象分为三代(generation 0,1,2),0代表幼年对象,1代表青年对象,2代表老年对象。根据弱代假说(越年轻的对象越容易死掉,老的对象通常会存活更久。) 新生的对象被放入0代,如果该对象在第0代的一次gc垃圾回收中活了下来,那么它就被放到第1代里面(它就升级了)。如果第1代里面的对象在第1代的一次gc垃圾回收中活了下来,它就被放到第2代里面。gc.set_threshold(threshold0[,threshold1[,threshold2]])设置gc每一代垃圾回收所触发的阈值。从上一次第0代gc后,如果分配对象的个数减去释放对象的个数大于threshold0,那么就会对第0代中的对象进行gc垃圾回收检查。 从上一次第1代gc后,如过第0代被gc垃圾回收的次数大于threshold1,那么就会对第1代中的对象进行gc垃圾回收检查。同样,从上一次第2代gc后,如过第1代被gc垃圾回收的次数大于threshold2,那么就会对第2代中的对象进行gc垃圾回收检查。
另一个解释:
分代回收是一种以空间换时间的操作方式,Python将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,Python将内存分为了3“代”,分别为年轻代(第0代)、中年代(第1代)、老年代(第2代),他们对应的是3个链表,它们的垃圾收集频率与对象的存活时间的增大而减小。新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。同时,分代回收是建立在标记清除技术基础之上。分代回收同样作为Python的辅助垃圾收集技术处理那些容器对象
参考资料:
- https://foofish.net/python-gc.html
- https://juejin.im/post/5b34b117f265da59a50b2fbe
- https://segmentfault.com/a/1190000016078708
29. 装饰器
装饰器本质上是一个Python函数,它可以让其它函数在不做任何代码变动的前提下,增加额外功能,装饰器的返回值也是一个函数对象。它经常用于有切面需求的场景:比如:插入日志、性能测试、事务处理、权限校验、缓存等。装饰器是这类问题的绝佳设计,有了装饰器,我们就可以抽离出大量与函数本身的功能无关的雷同代码,并重复使用。概括地讲,装饰器的作用就是为已经存在的函数对象添加额外的功能。
- 为了更好的理解装饰器的作用,可以参考下面的例子
现在有一个新的需求,希望可以记录下函数的执行日志,于是在代码中添加日志代码:def foo():print('i am foo')
def foo():print('i am foo')logging.info('foo is running')

但是这样存在一个问题:按照逻辑,我们本来可以直接调用我们想要执行的函数就可以了,但现在我们必须将这个函数作为一个参数传递给use_logging,即现在是use_logging(bar)而不是bar(),与逻辑不符。这个时候,我们就需要利用“装饰器”。

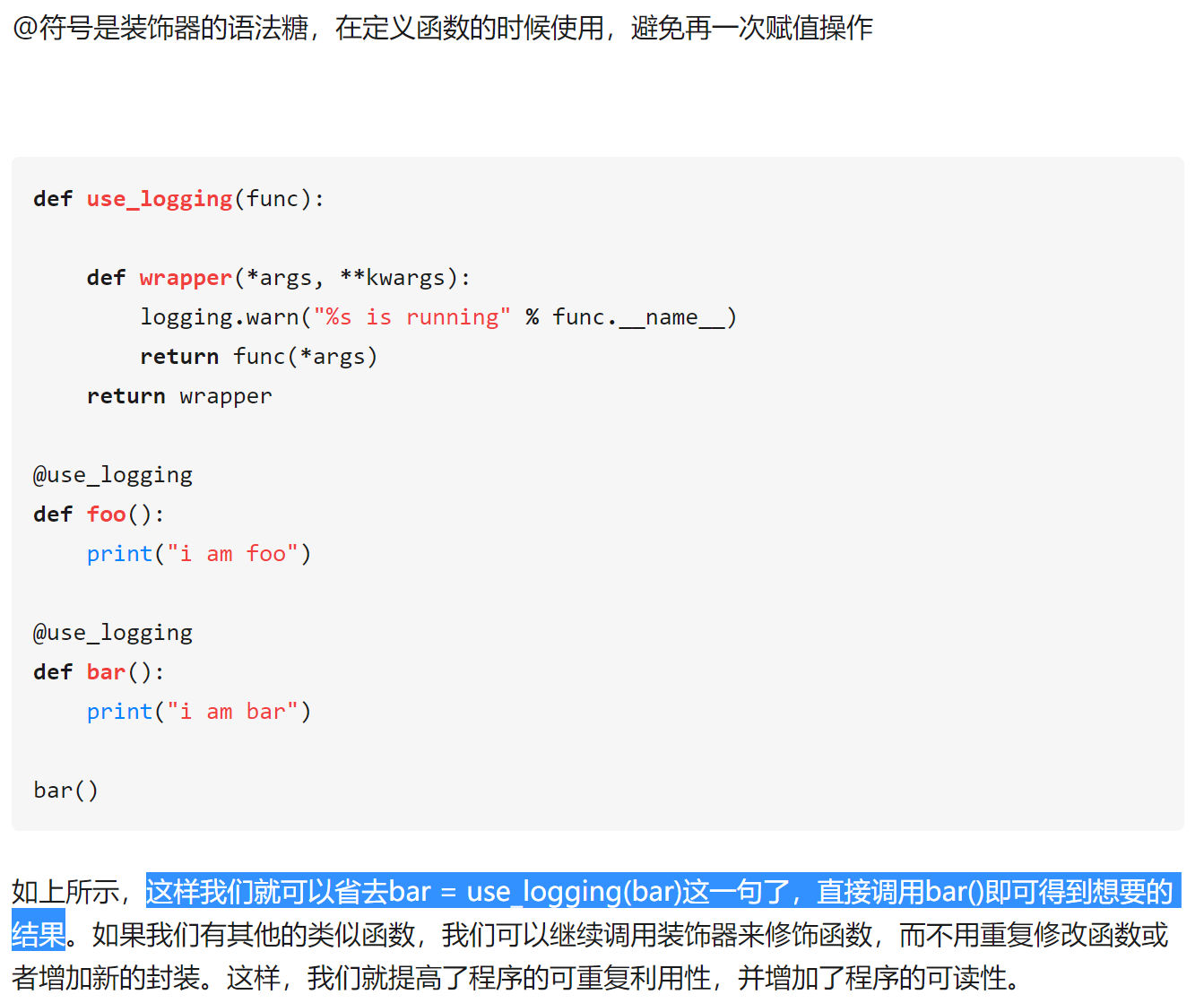
@use_logging # 这里相当于 bar = use_logging(bar) 这就是@的作用def bar():print("i am bar")
装饰器能在Python中如此方便的使用,是因为Python的函数本身也是对象,能像对象一样作为参数传递给其它函数,可以被赋值给其它变量,可以作为返回值,也可以定义在另一个函数内。
参考资料:https://www.zhihu.com/question/26930016
30. 类中的init和new方法的区别
Python的新类允许用户重载__new__和__init__方法,且这两个方法具有不同的作用。
__new__作为构造器,起创建一个类实例的作用。- 而
__init__作为初始化器,起初始化一个已被创建的实例的属性作用。

创建类实例并初始化的过程中__new__和__init__被调用的顺序也能从上面代码的输出结果中看出:__new__函数首先被调用,构造了一个newStyleClass的实例,接着__init__函数在__new__函数返回一个实例的时候被调用,并且这个实例作为self参数被传入了__init__函数。
这里需要注意的是,如果__new__函数返回一个已经存在的实例(不论是哪个类的),__init__不会被调用。
小结:
__new__是一个类方法,而__init__是一个实例方法.- 创建实例并初始化的过程中,new先被调用,用来创建实例,然后init才被调用来初始化实例属性
- init不能有返回值
- 只有在new返回一个新创建属于该类的实例时当前类的init才会被调用
参考资料:https://www.jianshu.com/p/14b8ebf93b73
31. 索引/范围异常
- 对于列表a = [1,2,3,4,5],如果想找a[10],此时会报错:超出索引范围
- 但是对于切片,如a[7:10],就算超出范围,也不会报错,返回值是[]而已
- 如果取a[:10],依然能正常返回存在的数,即[1,2,3,4,5]
- for循环中对于range(4, 2),虽然逻辑上有错,但是程序不会报错,而是直接跳出循环
32. 用*创建包含重复元素的列表的坑
通常我们可以用*来创建包含多个重复元素的列表:
alist = [0]*5# [0,0,0,0,0]
但是,在创建二维列表时出现了问题:
问题在于:其实实现的是对引用的复制,类似于一个“浅拷贝”,所以对dp[0][0]赋值时,每一行的第一个元素都发生了改变。
根本原因:得看元素是不是“不可变对象”,创建二维列表时出现问题,根本原因在于,我们想要复制的元素是列表(可变对象),所以得到的是引用;而创建一维列表时,元素是int型的数字,所以直接不会出现问题。
解决办法:*列表生成式
jupyter: leetcode 63
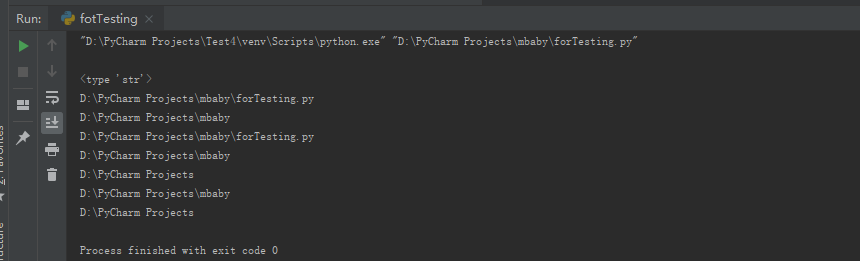
33. Python os.path路径
- os.path.dirname返回当前文件所在目录的完整路径
- os.path.abspath返回当前文件的绝对路径
- file本身返回的是一个str类型的字符串,代表文件的路径
- os.path.abspath(“.”)返回当前文件目录的绝对路径(.标识当前目录,..表示上一级目录)
- os.path.abspath(“..”)返回当前文件所在目录的上一级目录的绝对路径
- os.path.join()讲一个或多个字符串,组合成路径
Note: 需要注意的是之前出现过这些路径的斜杠方向有所不同,不知道是如何产生的(abspath和dirname返回的路径斜杠方向不同,前者是想windows一样的\,后者是Linux一样的/。不清楚会对程序造成什么样的影响,之后补充)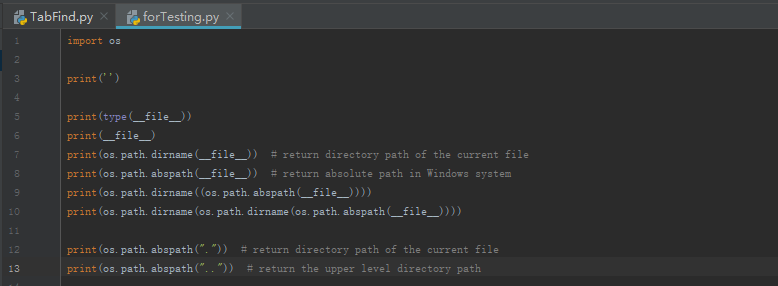
34. os.path和sys.path的区别
- os.path本质是一个module,我们调用的是里面的methods
- sys.path返回的是一个list,主要对import产生影响:返回解释器相关的目录列表、环境变量、注册表等初始化信息。可以利用append添加新的目录到sys.path里,这样import时也会检查这个新添加的目录
Reference: https://blog.csdn.net/l_b_yuan/article/details/52260646
35. 在不同目录下导入模块的方法
Reference:https://blog.csdn.net/zhili8866/article/details/52980924
36. 元组的特殊运算(乘法复制)
元组虽然不可以修改,但也可以像列表那样使用乘法来复制(注意,元组中如果只有1个值,需要加逗号)
print((4,) * len([1, 2, 3]))print([4] * 3)>>> (4, 4, 4)>>> [4, 4, 4]

若有收获,就点个赞吧
0 人点赞
