工具
tenacity 是一个通用的 retry 库,用于简化向任何任务加入重试的功能。
import randomfrom tenacity import retry@retrydef do_something_unreliable():if random.randint(0, 10) > 1:raise IOError("Broken sauce, everything is hosed!!!111one")else:return "Awesome sauce!"print(do_something_unreliable())
JWT
ORM
Tortoise ORM
日志
loguru
from loguru import loggerlogger.debug("That's it, beautiful and simple logging!")
Logbook
Structlog
消息队列
Celery
RQ
相比 Celery 使用更简单
进程管理
supervisor
调试
PySnooper
import pysnooper@pysnooper.snoop()def number_to_bits(number):if number:bits = []while number:number, remainder = divmod(number, 2)bits.insert(0, remainder)return bitselse:return [0]number_to_bits(6)
Starting var:.. number = 621:14:32.099769 call 3 @pysnooper.snoop()21:14:32.099769 line 5 if number:21:14:32.099769 line 6 bits = []New var:....... bits = []21:14:32.099769 line 7 while number:21:14:32.099769 line 8 number, remainder = divmod(number, 2)New var:....... remainder = 0Modified var:.. number = 321:14:32.099769 line 9 bits.insert(0, remainder)Modified var:.. bits = [0]21:14:32.099769 line 7 while number:21:14:32.099769 line 8 number, remainder = divmod(number, 2)Modified var:.. number = 1Modified var:.. remainder = 121:14:32.099769 line 9 bits.insert(0, remainder)Modified var:.. bits = [1, 0]21:14:32.099769 line 7 while number:21:14:32.099769 line 8 number, remainder = divmod(number, 2)Modified var:.. number = 021:14:32.099769 line 9 bits.insert(0, remainder)Modified var:.. bits = [1, 1, 0]21:14:32.099769 line 7 while number:21:14:32.099769 line 10 return bits21:14:32.099769 return 10 return bits
科学计算
numpy
pandas
CuPy
CuPy 一个开源的基于 NVIDIA CUDA 的矩阵计算加速库。CuPy的接口与NumPy的高度兼容; 在大多数情况下,它可以作为一个简易替换。 所有你需要做的只是在你的 Python 代码将 numpy 更换为 cupy 。它支持各种方法,索引,数据类型,广播等等。
>>> import cupy as cp>>> x = cp.arange(6).reshape(2, 3).astype('f')>>> xarray([[ 0., 1., 2.],[ 3., 4., 5.]], dtype=float32)>>> x.sum(axis=1)array([ 3., 12.], dtype=float32)
Numba
Numba 是一个用于编译 Python 数组和数值计算函数的编译器,这个编译器能够大幅提高直接使用Python编写的函数的运算速度。Numba 使用LLVM编译器架构将纯Python代码生成优化过的机器码,通过一些添加简单的注解,将面向数组和使用大量数学的 Python代码优化到与 C,C++和 Fortran 类似的性能,而无需改变Python的解释器。Numba的主要特性:
- 动态代码生成 (在用户偏爱的导入期和运行期)
- 为CPU(默认)和GPU硬件生成原生的代码
- 集成Python的科学软件栈(Numpy)
下面是使用 Numba优化的函数方法,将Numpy数组作为参数:
from numba import jitimport random@jit(nopython=True)def monte_carlo_pi(nsamples):acc = 0for i in range(nsamples):x = random.random()y = random.random()if (x ** 2 + y ** 2) < 1.0:acc += 1return 4.0 * acc / nsamples
Streamlit
Streamlit 构建自定义ML工具的最快方法。
import streamlit as stx = st.slider('Select a value')st.write(x, 'squared is', x * x)
Metaflow
Metaflow 是和上面介绍的科学计算的库不同,它服务于数据科学家,目标是减轻非技术型数据科学家学习技术的负担,比如如何利用计算资源、怎么实现并行运算、架构设计、版本控制等,帮助提高数据科学家的生产率。
看下面的例子:借助 Metaflow 我们可以实现 Spark 中经典的 DAGs 计算流: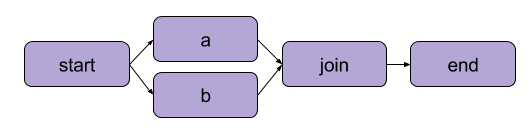
from metaflow import FlowSpec, stepclass BranchFlow(FlowSpec):@stepdef start(self):self.next(self.a, self.b)@stepdef a(self):self.x = 1self.next(self.join)@stepdef b(self):self.x = 2self.next(self.join)@stepdef join(self, inputs):print('a is %s' % inputs.a.x)print('b is %s' % inputs.b.x)print('total is %d' % sum(input.x for input in inputs))self.next(self.end)@stepdef end(self):passif __name__ == '__main__':BranchFlow()
爬虫
HTTPX
httpx 是高性能异步 HTTP 库,支持 HTTP/2 和 HTTP/1.1。API 设计参考 requests,简单易用。
>>> import httpx>>> r = await httpx.get('https://httpbin.org/get')>>> r<Response [200 OK]>>>> r = await httpx.post('https://httpbin.org/post', data={'key': 'value'})>>> r = await httpx.put('https://httpbin.org/put', data={'key': 'value'})>>> r = await httpx.delete('https://httpbin.org/delete')>>> r = await httpx.head('https://httpbin.org/get')>>> r = await httpx.options('https://httpbin.org/get')
高性能
immutables 用于Python的高性能不可变映射类型。
import immutablesmap = immutables.Map(a=1, b=2)print(map['a'])# will print '1'print(map.get('z', 100))# will print '100'print('z' in map)# will print 'False'
性能分析
memory_profiler
memory_profiler - 监视Python代码的内存使用情况。
$ pip install -U memory_profiler$ python -m memory_profiler example.pyLine # Mem usage Increment Occurences Line Contents============================================================3 38.816 MiB 38.816 MiB 1 @profile4 def my_func():5 46.492 MiB 7.676 MiB 1 a = [1] * (10 ** 6)6 199.117 MiB 152.625 MiB 1 b = [2] * (2 * 10 ** 7)7 46.629 MiB -152.488 MiB 1 del b8 46.629 MiB 0.000 MiB 1 return a

若有收获,就点个赞吧
0 人点赞
