- Netty 到 tcp 零拷贝?
* kafka :传输数据量很大、kafka不对数据做修改* netty :传输的数据是用户构造的,每次传输的数据吞吐量不是特别大
- [https://zhuanlan.zhihu.com/p/83398714](https://zhuanlan.zhihu.com/p/83398714)所谓的零拷贝是指将数据直接从磁盘文件复制到网卡设备中,而不需要经由应用程序之手。零拷贝大大提高了应用程序的性能,减少了内核和用户模式之间的上下文切换。对 Linux 操作系统而言,零拷贝技术依赖于底层的 sendfile() 方法实现。对应于 Java 语言,FileChannal.transferTo() 方法的底层实现就是 sendfile() 方法。
- <font style="color:rgb(51, 51, 51);">Netty的零拷贝主要体现在五个方面</font>
1. <font style="color:rgb(51, 51, 51);">Netty的接收和发送ByteBuffer使用</font>**<font style="color:rgb(51, 51, 51);">直接内存</font>**<font style="color:rgb(51, 51, 51);">进行Socket读写,不需要进行字节缓冲区的二次拷贝。如果使用JVM的堆内存进行Socket读写,</font>**<font style="color:rgb(51, 51, 51);">JVM会将堆内存Buffer拷贝一份到直接内存中</font>**<font style="color:rgb(51, 51, 51);">,然后才写入Socket中。相比于使用直接内存,消息在发送过程中多了一次缓冲区的内存拷贝。</font>2. <font style="color:rgb(51, 51, 51);">Netty的文件传输调用FileRegion包装的transferTo方法,可以直接将文件缓冲区的数据发送到目标Channel,避免通过循环write方式导致的内存拷贝问题。</font>3. <font style="color:rgb(51, 51, 51);">Netty提供CompositeByteBuf类, 可以将多个ByteBuf合并为一个逻辑上的ByteBuf, </font>**<font style="color:rgb(51, 51, 51);">避免了各个ByteBuf之间的拷贝。</font>**4. <font style="color:rgb(51, 51, 51);">通过wrap操作, 我们可以将byte[]数组、ByteBuf、ByteBuffer等包装成一个Netty ByteBuf对象, </font>**<font style="color:rgb(51, 51, 51);">进而避免拷贝操作。</font>**5. <font style="color:rgb(51, 51, 51);">ByteBuf支持slice操作,可以将ByteBuf分解为多个共享同一个存储区域的ByteBuf, </font>**<font style="color:rgb(51, 51, 51);">避免内存的拷贝</font>**<font style="color:rgb(51, 51, 51);">。</font>
- Credit 两个tcp连接?
没找到
- RP buffer IG buffer
ResultPartition:共用一个LocalBufferPool。
InputGate:每个InputChannel在初始化阶段都会分配固定数量的Buffer(**Exclusive Buffer**) ,Exclusive Buffer耗尽时,可以向BufferPool申请剩余的**Floating Buffer**(除了Exclusive Buffer,其他的都是Floating Buffer,备用Buffer)。RemoteInputGate启动时,需要向ResultPartition提交PartitionRequest注册InputChannel信息,此时将Exclusive Buffer队列的大小作为初始credit,写入InitialCtedit对象。
Networkbuffer
- MemorySegment
MemorySegment,是 **Flink 中最小的内存分配单元,默认大小32KB**。它既可以是堆上内存(Java的byte数组),也可以是堆外内存(基于Netty的DirectByteBuffer),同时提供了对二进制数据进行读取和写入的方法。
- Buffer
Task算子之间在网络层面上传输数据,使用的是Buffer,申请和释放由Flink自行管理,实现类为NetworkBuffer。1个NetworkBuffer包装了1个MemorySegment。同时继承了AbstractReferenceCountedByteBuf,是Netty中的抽象类。
public class NetworkBuffer extends AbstractReferenceCountedByteBuf implements Buffer{ /** The backing {@link MemorySegment} instance. */private final MemorySegment memorySegment;... ...}
- Buffer资源池
BufferPool用来管理Buffer,包含Buffer的申请、释放、销毁、可用Buffer通知等,实现类是LocalBufferPool,每个Task拥有自己的LocalBufferPool。
BufferPoolFactory用来提供BufferPool的创建和销毁,唯一的实现类是NetworkBufferPool,每个TaskManager只有一个NetworkBufferPool。同一个TaskManager上的Task共享NetworkBufferPool,在TaskManager启动的时候创建并分配内存。
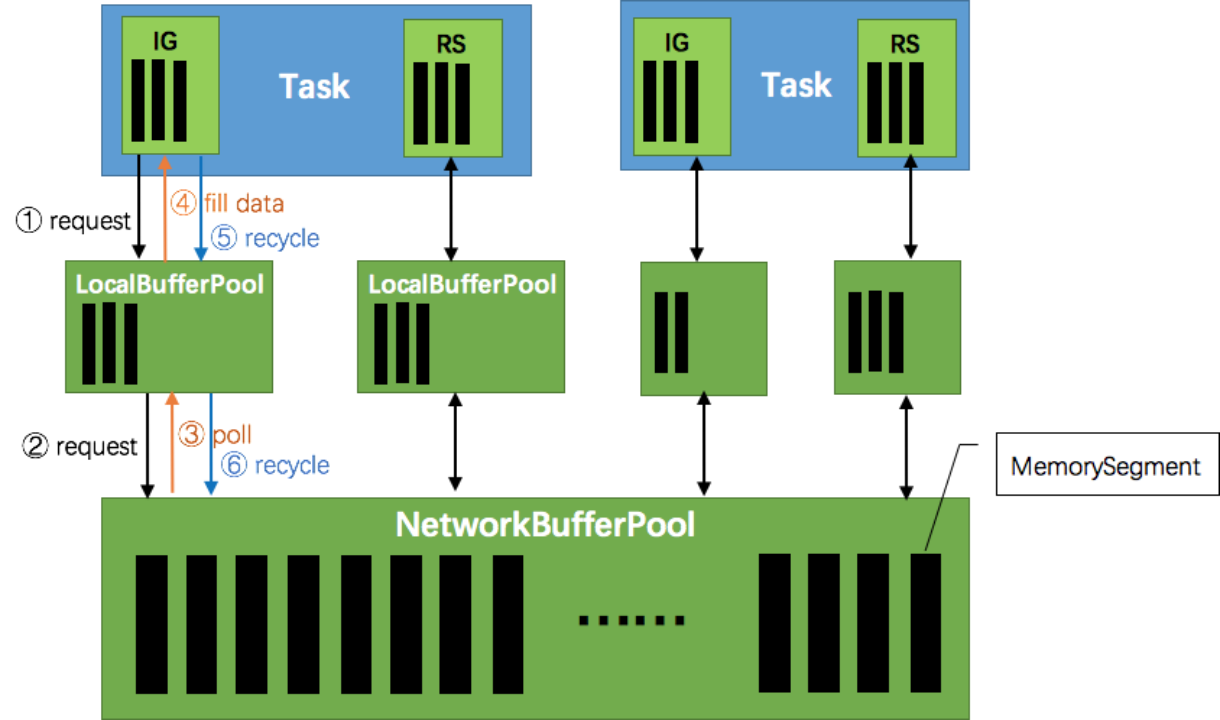
数据交换概览
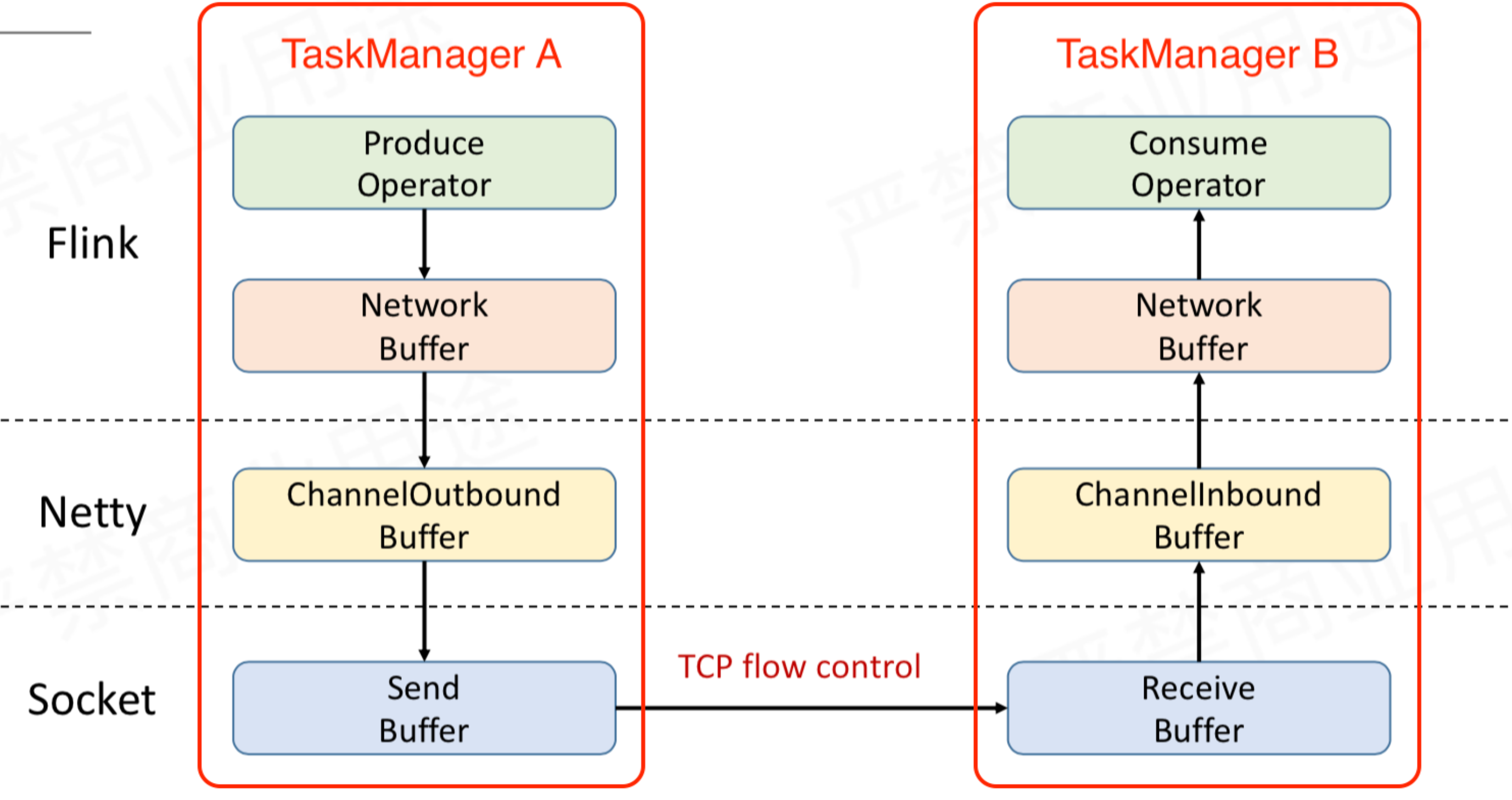
TaskManager A 给 TaskManager B 发送数据,TaskManager A 做为 Producer,TaskManager B 做为 Consumer。Producer 端的 Operator 实例会产生数据,最后通过网络发送给 Consumer 端的 Operator 实例。Producer 端 Operator 实例生产的数据首先缓存到 TaskManager 内部的 NetWork Buffer。NetWork 依赖 Netty 来做通信,Producer 端的 Netty 内部有 ChannelOutbound Buffer,Consumer 端的 Netty 内部有 ChannelInbound Buffer。Netty 最终还是要通过 Socket 发送网络请求,Socket 这一层也会有 Buffer,Producer 端有 Send Buffer,Consumer 端有 Receive Buffer。
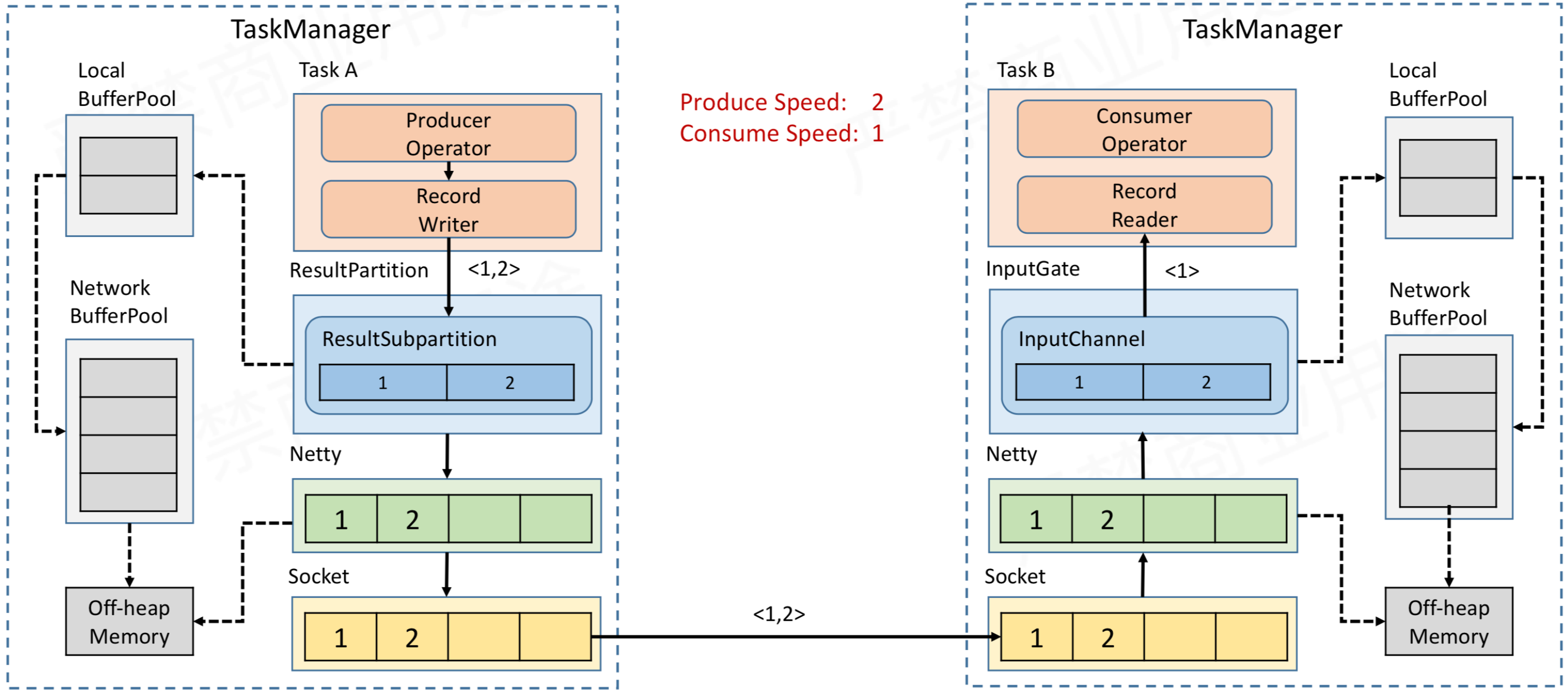
- Task A的Operator 处理数据后,会通过RecordWriter写出,转换为Buffer二进制数据,然后将buffer缓存到ResultSubPartition 中。
- ResultSubPartition中的数据会传输到 Task B 对应的的 InputChannel中
- Task B的RecordReader从InputChannel中拉取数据,交给Operator 处理
- ResultSubPartition 和 InputChannel 都是向 LocalBufferPool 申请 Buffer 空间,然后 LocalBufferPool 再向 NetWork BufferPool 申请内存空间。
flink流控
3.1 flink1.5前的反压策略
基于tcp自带的反压实现flink的反压机制
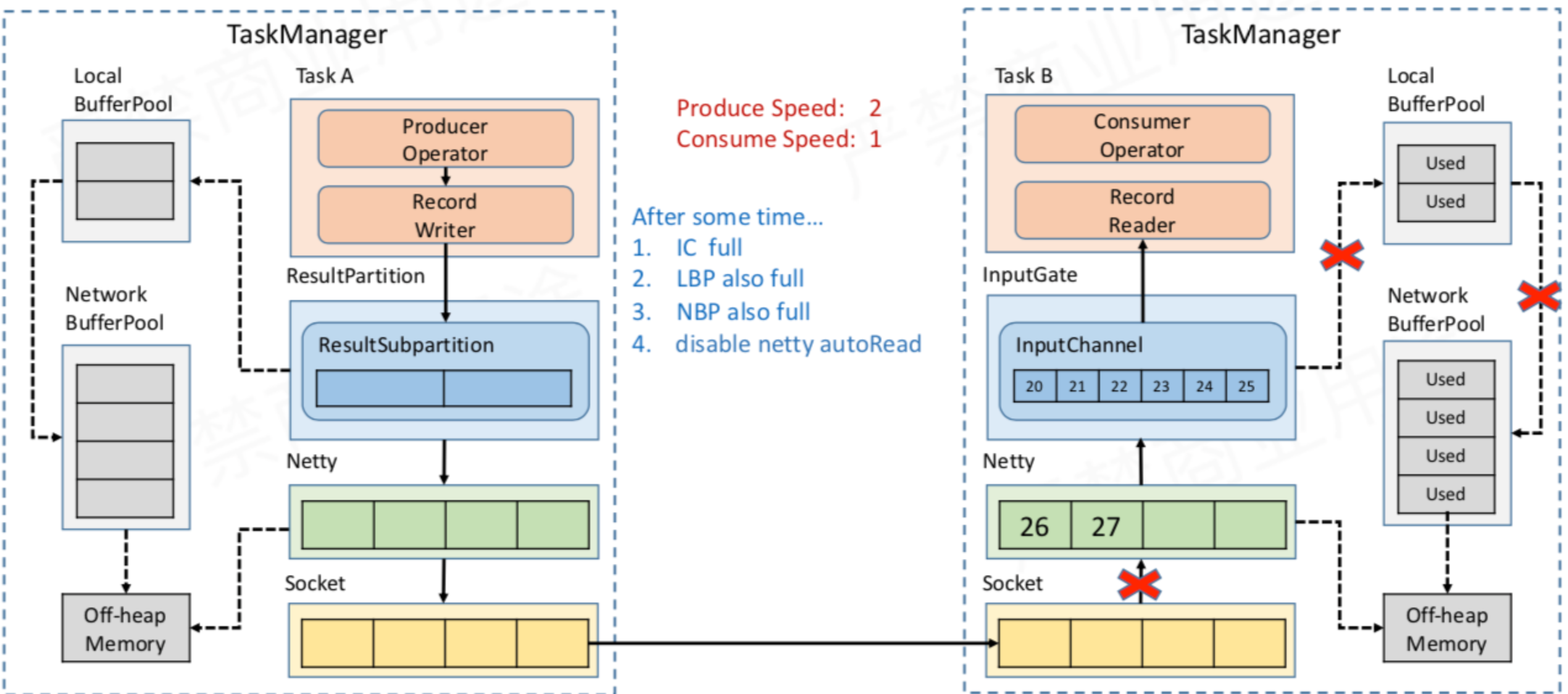
- TaskA发送,TaskB接受 。 Task B 消费比较慢,导致 InputChannel 被占满
- InputChannel 重复向 LocalBufferPool 申请 Buffer 空间
- LocalBufferPool 向 NetWork BufferPool 申请 Buffer 空间
- Task B 把自己可以使用的 InputChannel 、 LocalBufferPool 和 NetWork BufferPool 都用完了
- Netty 无法将把数据写入到 InputChannel,Netty 不会再从 Socket 中去读消息。
- Socket 的 Receive Buffer 就会变满,TCP** 的 Socket 通信有动态反馈的流控机制,会把容量为0的消息反馈给上游发送端,所以上游的 Socket 就不会往下游**再发送数据 。
- Task A 持续生产数据,发送端 Socket 的 Send Buffer 很快被打满,所以 Task A 端的 Netty 也会停止往 Socket 写数据。
- 数据会在 Netty 的 Buffer 中缓存数据,但 Netty 的 Buffer 是无界的。但设置 Netty 的高水位,检测 Netty 是否已经到达高水位,如果达到高水位就不会再往 Netty 中写数据,防止 Netty 的 Buffer 无限制的增长。
- 数据会在 Task A 的 ResultSubPartition 中累积,ResultSubPartition 满了后,会向 LocalBufferPool 申请新的 Buffer 空间,LocalBufferPool 再向 NetWork BufferPool 申请 Buffer,最终都用完了
- Task A 已经申请不到任何的 Buffer 了,Task A 的 Record Writer 输出就被 wait ,Task A 不再生产数据。
- Task A 的下游所有 Buffer 都占满了,那么 Task A 的 Record Writer 会被 block,Task A 的 Record Reader、Operator、Record Writer 都属于同一个**线程**,所以 Task A 的 Record Reader 也会被 block。
- 以此类推,TaskA将将压力传输到 Task A 的上游。
3.2 基于TCP反压存在的问题
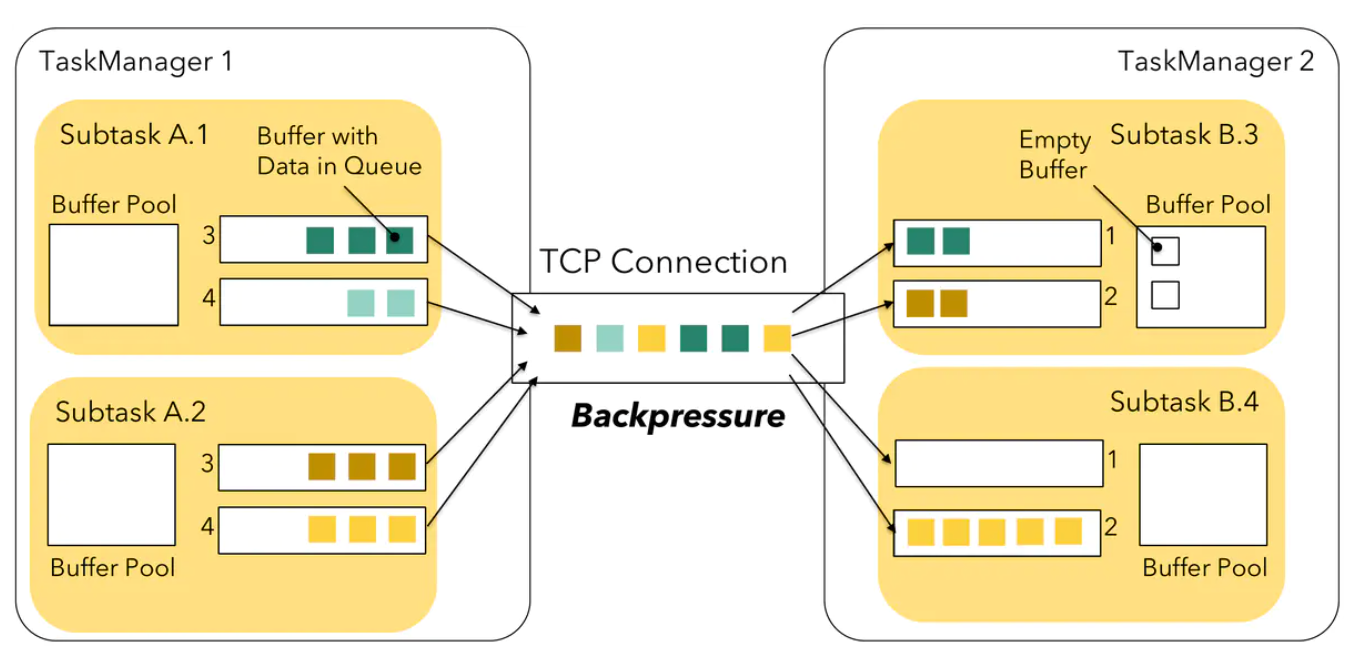
同一个TaskManager的Task子任务多路复用并共享一个**TCP**信道以减少资源使用。 A.1 -> B.3、A.1 -> B.4、A.2 -> B.3、A.2 -> B.4 这四条将会多路复用共享一个 TCP 信道。
当上图中 SubTask A.2 与 SubTask B.4 产生反压时,会把 TaskManager1 端该任务对应 Socket 的 Send Buffer 和 TaskManager2 端该任务对应 Socket 的 Receive Buffer 占满,多路复用的 TCP 通道已经被占住了,会导致 SubTask A.1 和 SubTask A.2 要发送给 SubTask B.3 的数据全被阻塞了,从而导致本来没有压力的 SubTask B.3 现在接收不到数据了。Flink 1.5 版之前的反压机制会存在当一个 Task 出现反压时,可能导致其他正常的 Task 接收不到数据。
- 下游某个Task处理能力不足产生反压会阻塞整条**TCP**通道,导致TaskManager所有Task都无法传输buffer数据,即使还有额外的buffer空间。
- 上游只能通过**TCP**通道的状态被动的感知下游的处理能力,不能主动调整发送速度
3.3 Credit反压策略
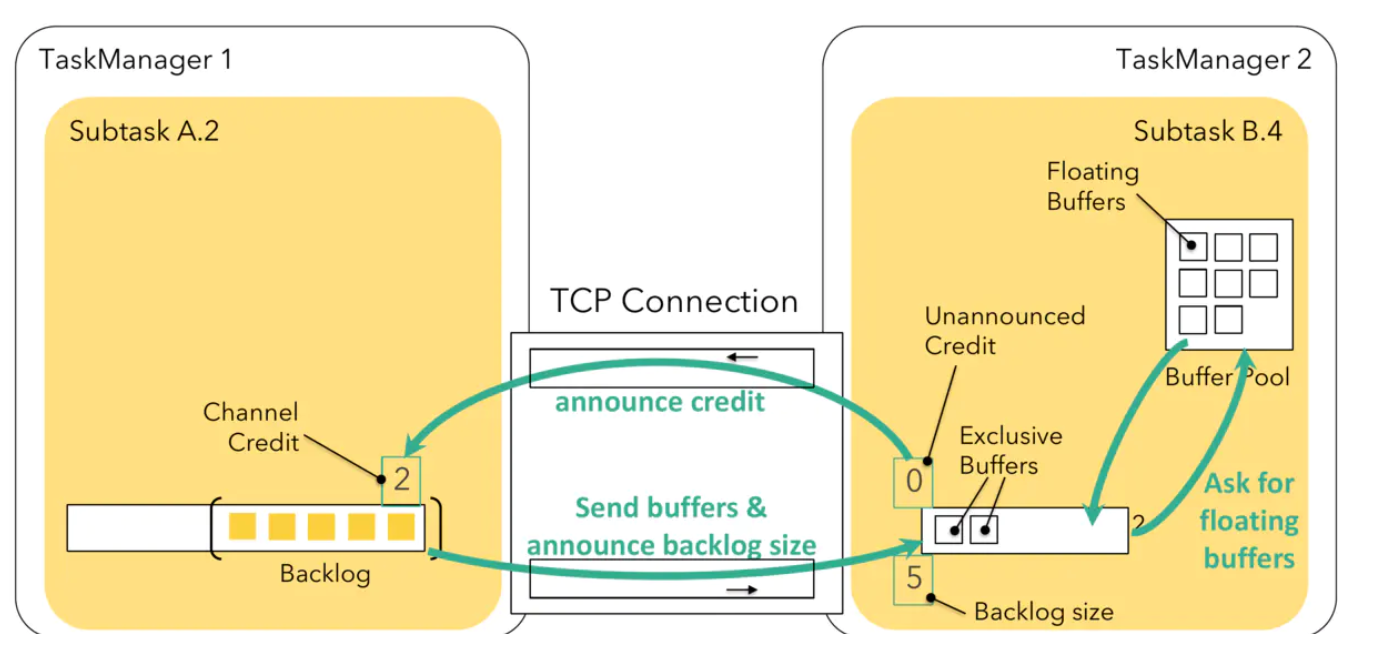
引入基于 Credit 的**反压机制**:
反压机制作用于 Flink 的应用层,即在 ResultSubPartition 和 InputChannel 这一层引入了反压机制。每次上游 SubTask A.2 给下游 SubTask B.4 发送数据时,会把 Buffer 中的数据和上游 ResultSubPartition 堆积的数据量 Backlog size发给下游,下游会接收上游发来的数据,并向上游反馈目前下游现在的 Credit 值,Credit 值表示目前下游可以接收上游的 Buffer 量,1 个Buffer 等价于 1 个 Credit 。
下游的 InputChannel 没有可用的缓冲区时,会向上游反馈 credit = 0,然后上游就不会发送数据到 Netty,也就不会导致 Netty 和 Socket 的数据积压。
上游会定期地仅发送 backlog size 给下游,直到下游反馈 credit > 0 时,上游就会继续发送真正的数据到下游了。
通过这种反馈策略,保证了不会在公用的 Netty 和 **TCP** 这一层数据堆积而影响其他 SubTask 通信。
3.4 吞吐量与延迟
Task 输出的数据并不是直接输出到下游,而是在 ResultSubPartition 中有一个 Buffer 用来缓存一批数据后,再 Flush 到 Netty 发送到下游 SubTask。
- buffer 写满了
- buffer 超时了
- 遇到特殊的 Event,例如:Checkpoint barrier
通过 execution.buffer-timeout: 100ms 可以设置超时时间
大并发任务如果使用 keyBy 或者 rebalance,则 buffer 的攒批效果会下降,每个 buffer 里存放一条数据,导致整体资源消耗变大。可以调大 bufferTimeout 将 buffer 中数据变多,提高攒批效果,从而优化资源消耗。
eg:设 bufferTimeout = 100ms ,意味着 100ms 必须将 buffer 中的数据发送到下游 Task。假设 SubtaskA0 每秒处理 1 万条数据,则 100ms 要处理 1000 条数据。若有1000个下游, 1000 条数据要发送给 1000 个 resultSubPartition,所以平均一个 resultSubPartition 中只会有 1 条数据,每个 resultSubPartition 有自己独立的 buffer,也就是说每个 buffer 其实只缓存了 1 条数据。跟没有 buffer 没什么区别。。。
4 反压监控
4.1 flink web UI
在 Flink Web UI 中有 BackPressure 的页面,通过该页面可以查看任务中 subtask
的反压状态
4.2 grafana
input pool uasge output pool uasge
- Flink** 1.9 及更新版本:**outPoolUsage、inPoolUsage、floatingBuffersUsage、exclusiveBuffersUsage
- 它们是对各个本地缓冲池中已用缓存与可用缓存的比率估计。从 Flink 1.9 开始,inPoolUsage 是 floatingBuffersUsage 和 exclusiveBuffersUsage 的总和。
4.3 反压算子定位
如果一个 Subtask 的 outPoolUsage 是高,通常是被下游 Task 所影响,所以可以排查它本身是反压根源的可能性。如果一个 Subtask 的 outPoolUsage 是低,但其 inPoolUsage 是高,则表明它有可能是反压的根源。因为通常反压会传导至其上游,导致上游某些 Subtask 的 outPoolUsage 为高,我们可以根据这点来进一步判断。值得注意的是,反压有时是短暂的且影响不大,比如来自某个 Channel 的短暂网络延迟或者 TaskManager 的正常 GC,这种情况下我们可以不用处理。4.4 反压原因
- 系统资源不足: CPU 网络 磁盘
- GC
- 数据倾斜
- 外部并发设置不合理 source sink
- 维表 匹配
- 上游数据问题

若有收获,就点个赞吧
0 人点赞
