1. SQL执行流程
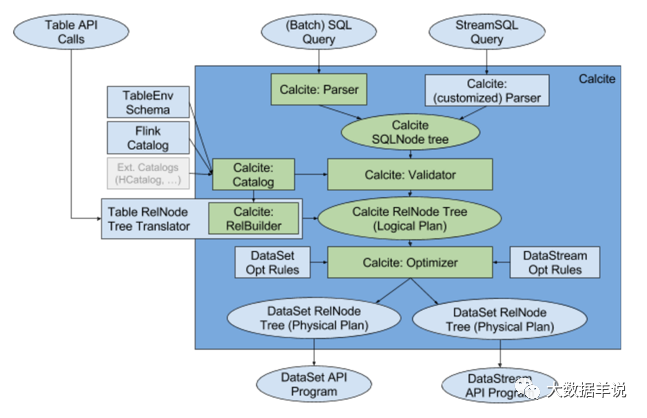
https://zhuanlan.zhihu.com/p/157265381
标准的一条 flink sql 运行起来的流程如下:- sql 解析阶段:calcite parser 解析(sql -> AST,AST 即 SqlNode Tree)
- SqlNode 验证阶段:calcite validator 校验(SqlNode -> SqlNode,语法、表达式、表信息)
- 语义分析阶段:SqlNode 转换为 RelNode,RelNode 即 Logical Plan(SqlNode -> RelNode)
- 优化阶段:calcite optimizer 优化(RelNode -> RelNode,剪枝、谓词下推等)
- Flink源码分析 - Flink SQL中的MiniBatch Aggregation优化 Flink入坑指南 第四章:SQL中的经典操作Group By+Agg-阿里云开发者社区
- 物理计划生成阶段:Logical Plan 转换为 Physical Plan
- 代码生成:生成operator、UDF、表达式,包装为transformation
- 调度执行:transformation -> streamGraph -> JobGraph -> ExecutionGraph -> Task exec
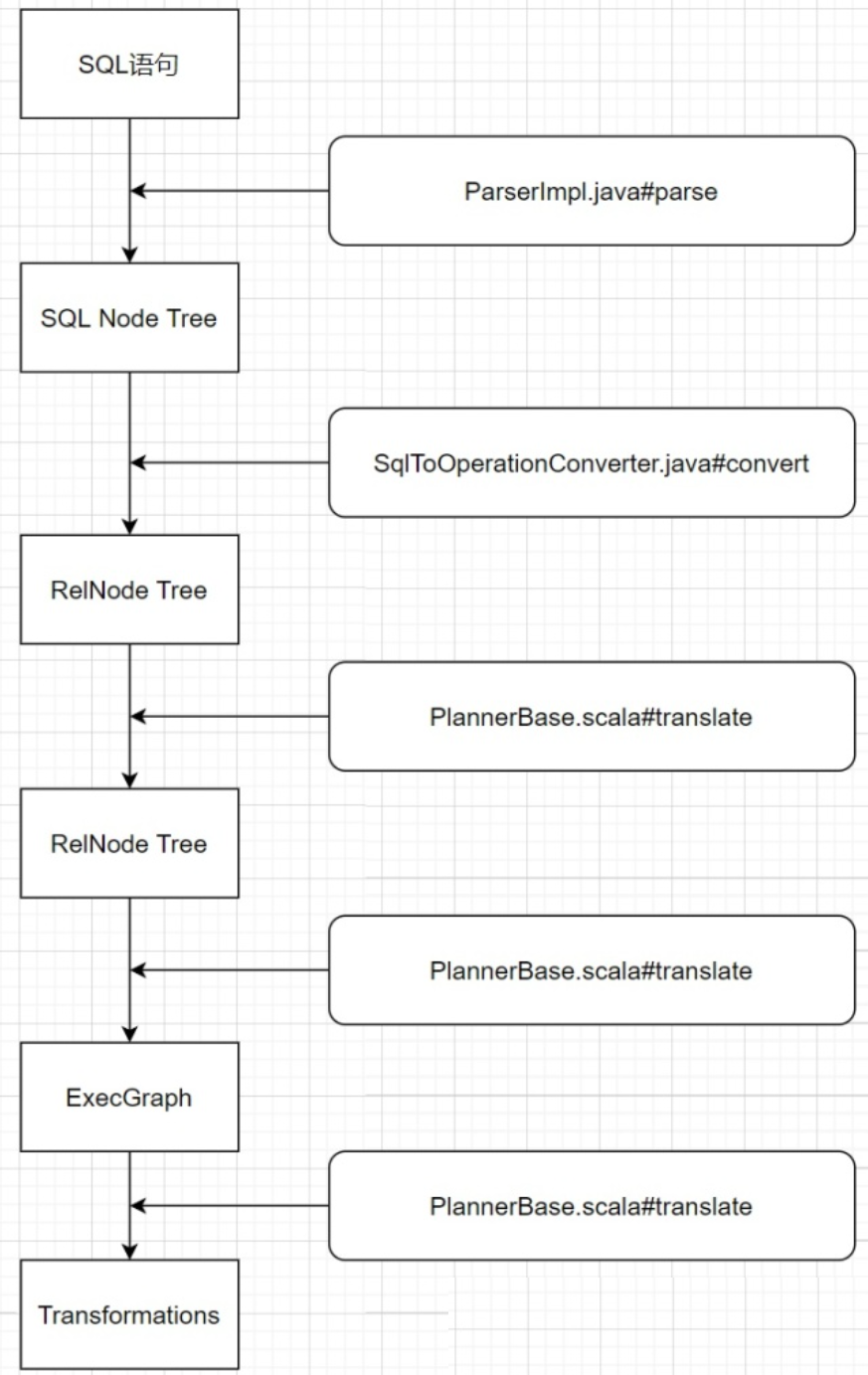
2. 执行计划
== Abstract Syntax Tree ==LogicalSink(table=[default_catalog.default_database.sink_table], fields=[order_id, count_result, sum_result, avg_result, min_result, max_result])+- LogicalProject(order_id=[$0], count_result=[CAST($1):BIGINT], sum_result=[$2], avg_result=[CAST($3):DOUBLE], min_result=[$4], max_result=[$5])+- LogicalAggregate(group=[{0}], count_result=[COUNT()], sum_result=[SUM($1)], avg_result=[AVG($1)], min_result=[MIN($1)], max_result=[MAX($1)])+- LogicalTableScan(table=[[default_catalog, default_database, source_table]])== Optimized Physical Plan ==Sink(table=[default_catalog.default_database.sink_table], fields=[order_id, count_result, sum_result, avg_result, min_result, max_result])+- Calc(select=[order_id, CAST(count_result) AS count_result, sum_result, CAST(avg_result) AS avg_result, min_result, max_result])+- GroupAggregate(groupBy=[order_id], select=[order_id, COUNT(*) AS count_result, SUM(price) AS sum_result, AVG(price) AS avg_result, MIN(price) AS min_result, MAX(price) AS max_result])+- Exchange(distribution=[hash[order_id]])+- TableSourceScan(table=[[default_catalog, default_database, source_table]], fields=[order_id, price])== Optimized Execution Plan ==Sink(table=[default_catalog.default_database.sink_table], fields=[order_id, count_result, sum_result, avg_result, min_result, max_result])+- Calc(select=[order_id, CAST(count_result) AS count_result, sum_result, CAST(avg_result) AS avg_result, min_result, max_result])+- GroupAggregate(groupBy=[order_id], select=[order_id, COUNT(*) AS count_result, SUM(price) AS sum_result, AVG(price) AS avg_result, MIN(price) AS min_result, MAX(price) AS max_result])+- Exchange(distribution=[hash[order_id]])+- TableSourceScan(table=[[default_catalog, default_database, source_table]], fields=[order_id, price])
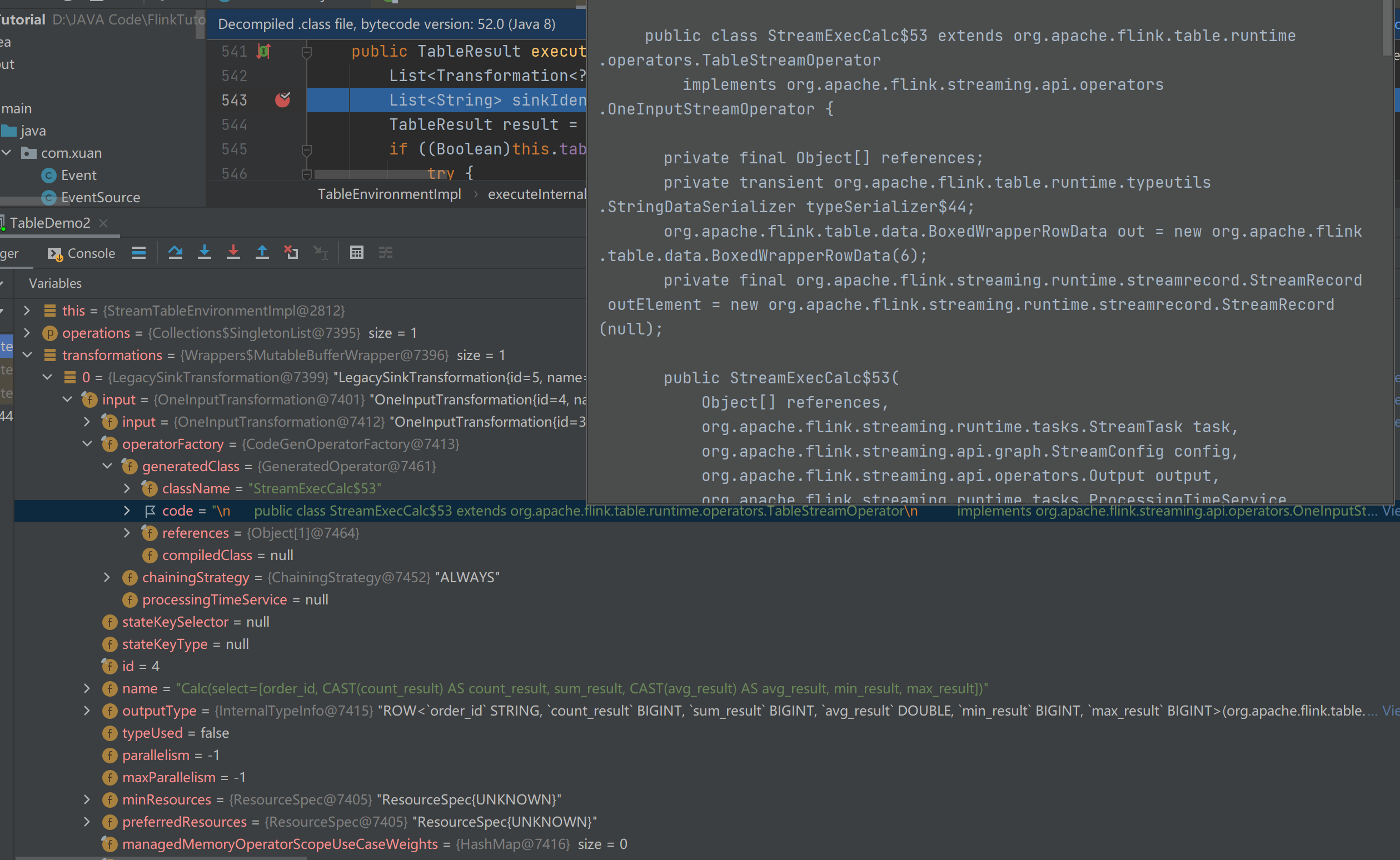
3. 查看生成的代码


若有收获,就点个赞吧
0 人点赞
