1.环境配置
Flink 是一个分布式的流处理框架,所以实际应用一般都需要搭建集群环境。我们在进行 Flink 安装部署的学习时,需要准备 3 台 Linux 机器。具体要求如下:
- 系统环境为 CentOS 7.5 版本。
- 安装 Java 8。
- 安装 Hadoop 集群,Hadoop 建议选择 Hadoop 2.7.5 以上版本。
- 配置集群节点服务器间时间同步以及免密登录,关闭防火墙。
本书中三台服务器的具体设置如下:
- 节点服务器 1,IP 地址为 192.168.10.102,主机名为 hadoop102。
- 节点服务器 2,IP 地址为 192.168.10.103,主机名为 hadoop103。
- 节点服务器 3,IP 地址为 192.168.10.104,主机名为 hadoop104。
2.本地启动
下载安装包
进入 Flink 官网,下载 1.13.0 版本安装包 flink-1.13.0-bin-scala_2.12.tgz,注意此处选用对 应 scala 版本为 scala 2.12 的安装包。
解压
在 hadoop102 节点服务器上创建安装目录/opt/module,将 flink 安装包放在该目录下,并 执行解压命令,解压至当前目录。
$ tar -zxvf flink-1.13.0-bin-scala_2.12.tgz -C /opt/module/
启动
进入解压后的目录,执行启动命令,并查看进程。
cd flink-1.13.0/$ bin/start-cluster.shStarting cluster.Starting standalonesession daemon on host hadoop102.Starting taskexecutor daemon on host hadoop102.$ jps10369 StandaloneSessionClusterEntrypoint10680 TaskManagerRunner10717 Jps
关闭集群
$ bin/stop-cluster.shStopping taskexecutor daemon (pid: 10680) on host hadoop102.Stopping standalonesession daemon (pid: 10369) on host hadoop102.
3.集群启动
可以看到,Flink 本地启动非常简单,直接执行 start-cluster.sh 就可以了。如果我们想要扩 展成集群,其实启动命令是不变的,主要是需要指定节点之间的主从关系。 Flink 是典型的 Master-Slave 架构的分布式数据处理框架,其中 Master 角色对应着 JobManager,Slave 角色则对应 TaskManager。我们对三台节点服务器的角色分配如表 3-1 所示。 
具体安装部署步骤如下:
修改集群配置
进入 conf 目录下,修改 flink-conf.yaml 文件,修改 jobmanager.rpc.address 参数为 hadoop102
$ vi conf/flink-conf.yaml# JobManager 节点地址.jobmanager.rpc.address: hadoop102
修改 workers 文件,将另外两台节点服务器添加为本 Flink 集群的 TaskManager 节点
$ vim workershadoop103hadoop104
另外,在 flink-conf.yaml 文件中还可以对集群中的 JobManager 和 TaskManager 组件 进行优化配置,主要配置项如下:
- jobmanager.memory.process.size:对 JobManager 进程可使用到的全部内存进行配置, 包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。
- taskmanager.memory.process.size:对 TaskManager 进程可使用到的全部内存进行配置, 包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。
- taskmanager.numberOfTaskSlots:对每个 TaskManager 能够分配的 Slot 数量进行配置, 默认为 1,可根据 TaskManager 所在的机器能够提供给 Flink 的 CPU 数量决定。所谓 Slot 就是 TaskManager 中具体运行一个任务所分配的计算资源。
- parallelism.default:Flink 任务执行的默认并行度,优先级低于代码中进行的并行度配 置和任务提交时使用参数指定的并行度数量。
分发安装目录
配置修改完毕后,将 Flink 安装目录发给另外两个节点服务器。
$ xsync /opt/module/flink-1.13.0
启动集群
在 hadoop102 节点服务器上执行 start-cluster.sh 启动 Flink 集群
$ bin/start-cluster.sh
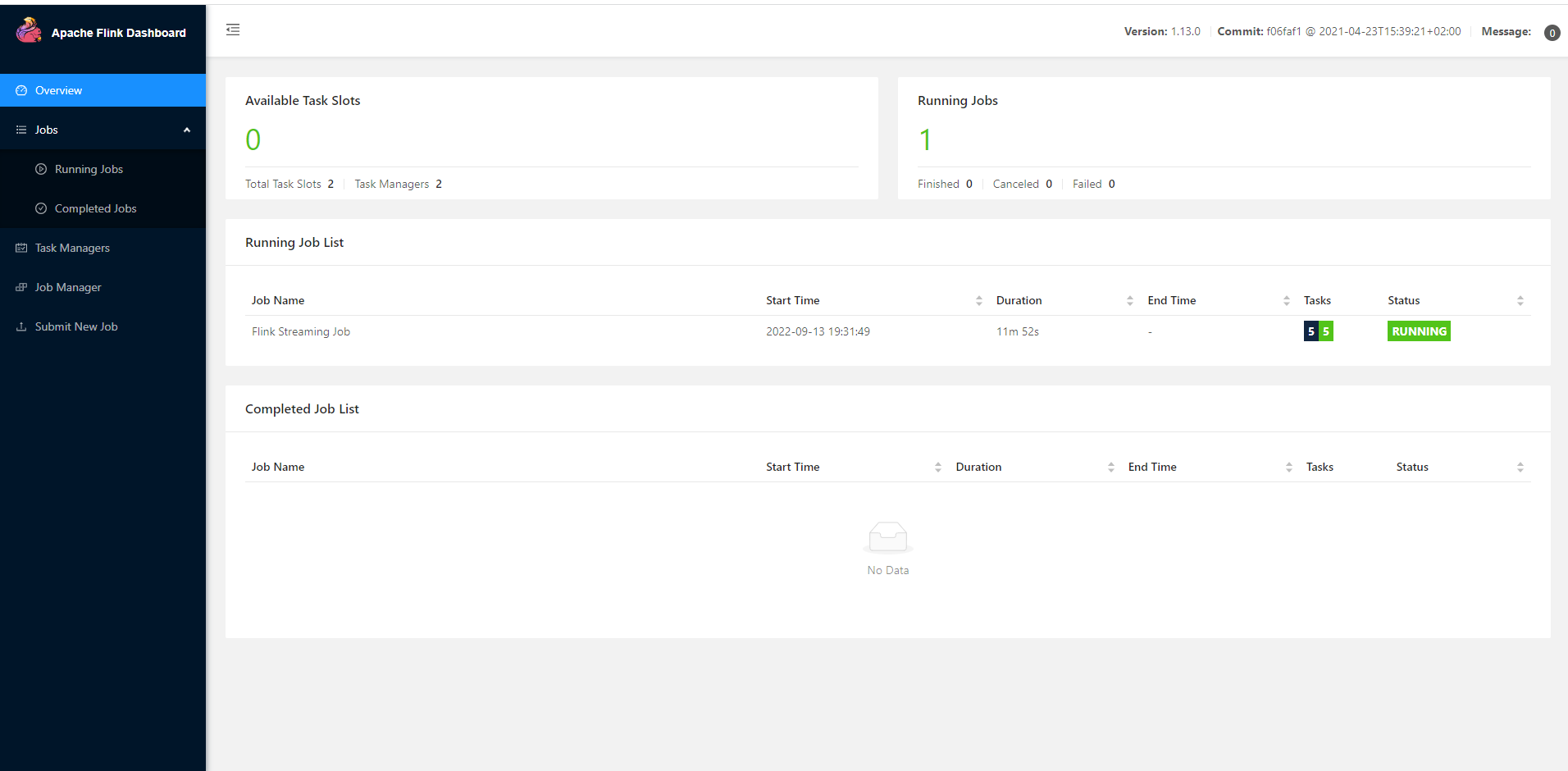
访问 Web UI
启动成功后,同样可以访问 http://hadoop102:8081 对 flink 集群和任务进行监控管理
4.提交作业
程序打包
为方便自定义结构和定制依赖,我们可以引入插件 maven-assembly-plugin 进行打包。 在 FlinkTutorial 项目的 pom.xml 文件中添加打包插件的配置,具体如下:
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.0.0</version><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>
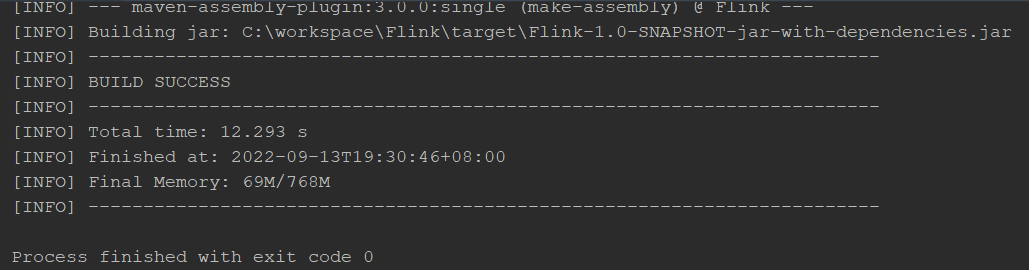
插件配置完毕后,可以使用 IDEA 的 Maven 工具执行 package 命令,出现如下提示即 表示打包成功。
webUI提交作业
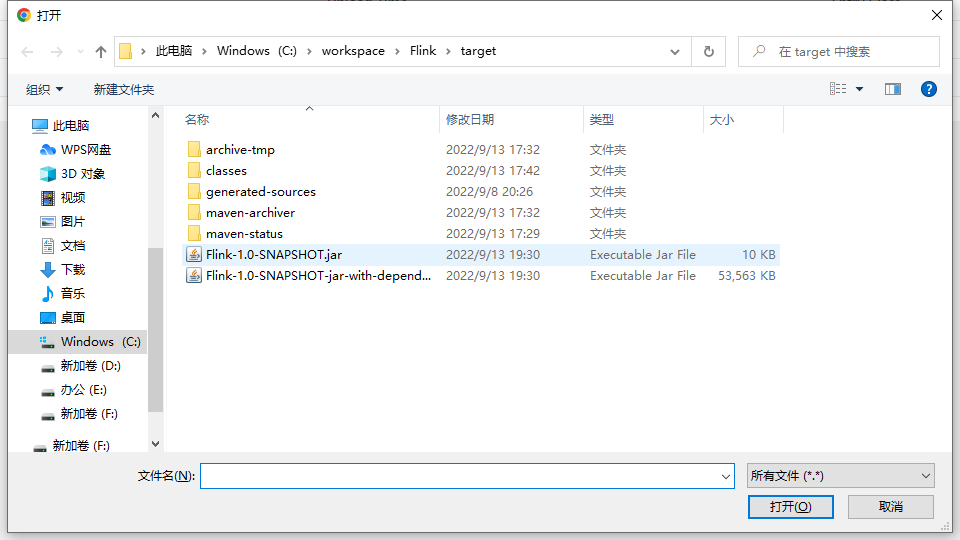
任务打包完成后,我们打开 Flink 的 WEB UI 页面,在右侧导航栏点击“Submit New Job”,然后点击按钮“+ Add New”,选择要上传运行的 JAR 包

- 主要配置程序入口主类的全类名,任务运行的并行度,任务运行所需的配置参数和保存点 路径等,如图 3-6 所示,配置完成后,即可点击按钮“Submit”,将任务提交到集群运行。

- 任务提交成功之后,可点击左侧导航栏的“Running Jobs”查看程序运行列表情况

- 点击该任务,可以查看任务运行的具体情况,也可以通过点击“Cancel Job”结束任务运行

命令行提交
除了通过 WEB UI 界面提交任务之外,也可以直接通过命令行来提交任务。这里为方便 起见,我们可以先把 jar 包直接上传到目录 flink-1.13.0 下
(1)首先需要启动集群。 $ bin/start-cluster.sh
(2)在 hadoop102 中执行以下命令启动 netcat。 $ nc -lk 7777
(3)进入到 Flink 的安装路径下,在命令行使用 flink run 命令提交作业。
$ bin/flink run -m hadoop102:8081 -c com.atguigu.wc.StreamWordCount ./FlinkTutorial-1.0-SNAPSHOT.jar
这里的参数 –m 指定了提交到的 JobManager,-c 指定了入口类。
(4)在浏览器中打开 Web UI,http://hadoop102:8081 查看应用执行情况 .
(5)在 log 日志中,也可以查看执行结果,需要找到执行该数据任务的 TaskManager 节点 查看日志。

若有收获,就点个赞吧
0 人点赞
