如何配置大小
默认配置是128MB,太小,如果是16核32G机器,可以配置:
innodb_buffer_pool_size=2147483648
数据页/缓存页
mysql对数据抽象出来一个数据页的概念,把很多行数据放到一个数据页里,磁盘中是一个个的数据页,而把数据拉到缓存池中,就叫缓存页,磁盘中的数据页大小是一页16kb,一个缓存页的大小和数据页大小是以一一对应。每个缓存页有个描述信息:数据页所属表空间,数据页的编号,缓存页在buffer pool中的地址,每个描述信息也是一块数据,描述数据在前,缓存页在后。
注意:buffer pool中的描述数据大概是缓存页大小的5%左右,每个描述数据大概800个字节左右大小,如果buffer pool大小是128MB,实际上buffer pool大小可能有130多MB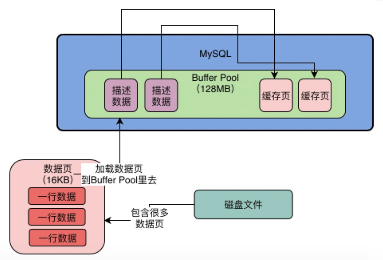
free链表
一个双向链表结构,每个节点就是一个空闲的缓存页的描述数据块的地址,本身就有buffer pool里的描述数据块组成,除了基础节点:40字节大小,存放free链表的头节点地址,尾节点地址,当前有多少节点。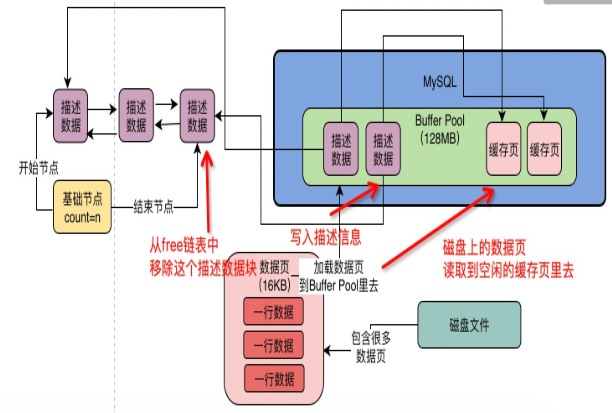
数据如何从磁盘读到buffer pool
数据库有个hash表结构,表空间号+数据页号=key,缓存页的地址=value,使用数据页时先用key查询,有则表示缓存里有。
flush链表
被修改过的缓存页的描述数据块,双向链表
伪代码:
Block{block_id=block01free_pre=nullfree_next=nullflush_pre=nullflush_next=block02}Block{block_id=block02free_pre=nullfree_next=nullflush_pre=block01flush_next=null}BaseNode{start=block01en=block02count=2}
LRU链表
当缓存页满了或者轮询机制把不常用的数据刷入磁盘时,lru起到关键作用。
预读取导致数据刷入磁盘
触发了预读取后,会把一大片数据加载到缓存,有一种情况是预读取加载进的数据并不是经常访问,但把一些在lru中经常访问的顶到后面去了。导致后面的数据被刷入磁盘
什么情况出发预读取?
- innodb_read_ahead_threshold,他的默认值是56,如果顺序的访问了一个区里的多个数据页,访问的数据页的数量超过了这个阈值,此时就会触发预读机制,把下一个相邻区中的所有数据页都加载到缓存
- innodb_random_read_ahead,默认是OFF,如果buffer_pool里缓存了一个区里的13个连续数据页,并且数据页会比较频繁被访问,会直接触发预读取,把区里的其他数据页加载到缓存
全表扫描导致数据刷入磁盘
select * from user,一下子把表的数据都加载出来放入缓存中,并把lru已经存在的数据顶到后面。基于冷热数据分离设计

innodb_old_blocks_pct默认37,冷数据占比37%
数据页第一次加入到缓存时,放入到冷数据区域的链表头部
innodb_old_blocks_time参数,默认值1000,也就是1000毫秒,在1s之后(1s内访问是不会动的),访问这个缓存页,它才会挪动到热数据区域热数据区的优化
只有热数据区域的后3/4部分的缓存页被访问时,才会移动到链表头,而前1/4被访问,是不会移动的动态运行效果
后台在不繁忙的时候,找个时间把flush链表中的缓存页刷入到磁盘中,缓存页就会在flush链表和lru链表中删除,加入到free链表中。
不停的加载数据到缓存页中,不停的查询和修改缓存数据,free链表缓存页不停的减少,flush链表不停的增加,lru链表不停的增加和移动,另一边,后台线程不停的把lru链表的冷数据区域的缓存页以及flush链表的缓存页,刷入磁盘来清空缓存页
实在是没有空闲页,free链表都被使用,flush链表有一大堆修改过的数据,lru链表一大堆缓存页,这时候要把lru冷数据尾端刷入磁盘,因为它是最不常用的。生产优化经验
多个buffer pool
mysql默认规则,如果分给buffer pool的内存小于1G,则最多只跟一个buffer pool
例如现有配置:
innodb_buffer_pool_size = 8589934592
innodb_buffer_pool_instances = 4
buffer pool设置了8G内存,4个实例,则每个buffer pool有2GBchunk机制
一个buffer pool是由多个chunk构成,由innodb_buffer_pool_chunk_size控制,默认值128M
动态调整buffer pool大小只需要增加chunk数量即可合理设置大小
buffer pool总大小=(chunk大小 buffer pool数量)的倍数
比如默认的chunk是128M,此时机器是32G,buffer pool总大小20G左右,假如buffer pool数量16个,chunk大小buffer pool数量=16*128MB=2048M,20G是2048的10倍,没问题。show engine innodb status
redo log
日志大致的格式是:对表空间XX中的数据页XX中偏移量为XXX的地方更新了数据XXX
疑问:事务提交时把缓存页都写入磁盘和用redo log写入磁盘都是落盘,有什么区别?
回答: 一个缓存页是16kb,一口气写入16kb的数据耗时是很大的,并且缓存页输入磁盘是随机写,性能差,随机的位置意味着可能会跑很远,例如45336这个地方。而redo log的刷入,第一个一行可能就占几十个字节,并且redo log是顺序写入,永远追加到磁盘文件末尾,速度很快
日志类型:修改了数据页里的几个字节的值,redo log分为不同的类型,MLOG_1BYTE类型日志就是修改了1个字节,MLOG_2BYTE就是修改了2个字节,以此类推;如果修改了一大串的值,类型就是MLOG_WRITE_STRING,代表一下子在数据页的某个偏移量的位置插入或者修改了一大串的值
日志结构:日志类型,表空间id,数据页号,数据页中的偏移量,修改数据的长度(MLOG_WRITE_STRING才会用上),具体修改的数据redo log block
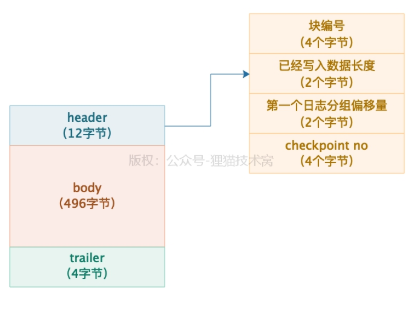
redo log不是单行单行写入日志文件,是用block来存放多个单行日志。一个block是512字节,分为3个部分,一个是12字节的header块头,一个是496字节的body体,一个是4字节的trailer块尾。
12字节的header头又分为4个部分:
- 4个字节的block no,块唯一编号
- 2字节的data length,bolock里写入了多少字节的数据
- 2字节的first record group,每个事务会有多个redo log,是一个group,即一组redo log。在这个block里的第一组redo log偏移量,就是2字节存储
- 4个字节的checkpoint on
redo log buffer
mysql在启动的时候,会跟操作系统要一块连续的内存空间,里面划分出了多个空的redo log block,用来缓冲redo log写入
设置innodb_log_buffer_size可以指定redo log buffer的大小,默认的值是16M
redo log 如何写入磁盘中
当一个事务处理时,把redo log写入到redo block(它是在内存里)中,当redo block满后(512字节),才会把redo block数据落盘
redo block在磁盘中是多块的,如果当前是提交了多个事务,可能一个block是不够写的,会写到多个block中
或者当前一个事务有多个增删改查,一口气有很多个redo log,所有redo log会先写成一个组group,等都写完了再把group提交到block中去
如果group比较小,有可能是多个group提交到一个block里
redo log block哪些时候刷入到磁盘中:
- 如果buffer容量已经占据一半,超过8MB在缓冲里
- 根据设置,有一种不进os cache,当一个事务提交的时候,必须把他的redo log所在的block都刷入到磁盘文件中去
- 后台线程定时刷新,有一个后台线程每隔1秒会把buffer里的block刷到磁盘文件里去
- mysql关闭的时候

若有收获,就点个赞吧
0 人点赞
