参考链接:
- https://blog.csdn.net/sarracode/article/details/109060358#1.chinese_L-12_H-768_A-12
- https://towardsdatascience.com/how-to-use-bert-from-the-hugging-face-transformer-library-d373a22b0209
1. 安装
可以运行的环境:
| 环境 | 版本 |
|---|---|
| Python | 3.9.7 |
| PyTorch | 1.11.0 |
| TensorFlow | 2.9.1 |
| Transformers | 4.20.1 |
| NumPy | 1.23.1 |
BERT官网下载中文Base预训练集,Link:https://github.com/google-research/bert;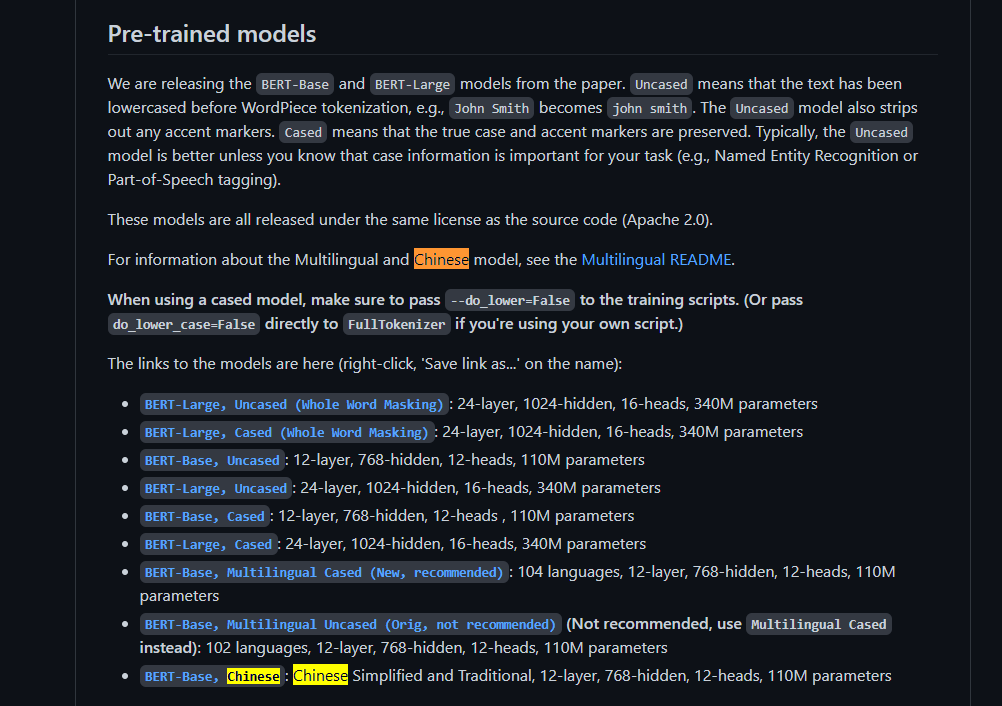
解压后修改将bert_config.json复制粘贴重命名为config.json(可能涉及到Pytorch版本的后续调用,目前原因未知);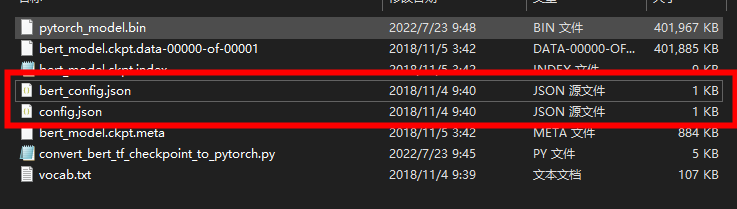
BERT for tensorflow 通过.py脚本转换成BERT for pytorch;convert_bert_tf_checkpoint_to_pytorch.py
python convert_bert_tf_checkpoint_to_pytorch.py --tf_checkpoint_path=d:/chinese_L-12_H-768_A-12/bert_model.ckpt --bert_config_file=d:/chinese_L-12_H-768_A-12/config.json --pytorch_dump_path=d:/chinese_L-12_H-768_A-12/pytorch_model.bin
2. 使用
import torch,warningsfrom torch.utils.data import DataLoader, ConcatDatasetfrom torch.nn.utils.rnn import pad_sequencefrom transformers import BertTokenizer,BertModelwarnings.filterwarnings("ignore")tokenizer = BertTokenizer.from_pretrained('d:/chinese_L-12_H-768_A-12')model = BertModel.from_pretrained('d:/chinese_L-12_H-768_A-12',output_hidden_states = True)#output_hidden_states=True,显示Bert训练中的所有层,共计12层。
# BERT训练前,需要分词并标注(tokenizer+IDs),每个词的ID不同。此外需要添加[CLS]和[SEP]。text_befort="可可热牛奶"input_ids=tokenizer.encode(text_befort, return_tensors = "pt",pad_to_max_length=True,max_length = 7) # 设置的batch_size为7print(input_ids)# 返回pytorch的tensor,101和102分别为首尾的ID;# max_length : batch_size;# pad_to_max_length=True :添加padding的ID,即为0;# 与上面同样的效果# torch.tensor(tokenizer.encode(text_befort),pad_to_max_length=True,max_length = 64).unsqueeze(0)
# 建模outputs=model(input_ids)# last_hidden_state : 最后层;# hidden_states : 所有embedding层;# pooler_output : 池化后向量。# 池化向量,with size of (batch_size,768)outputs.pooler_output
为了与BERT-server保持输出一致,BERT-server中有两个参数需要被认知:-pooling_layer,默认是[-2],取的是倒数第二层的embedding并池化。-pooling_strategy,默认是REDUCE_MEAN的pooler
hidden_states=outputs.hidden_statessecond_to_last_layer = hidden_states[-2]# 只有一个句子,因此脱掉外面的维度,并调用REDUCE_MEAN的poolertoken_vecs = second_to_last_layer[0]sentence_embedding = torch.mean(token_vecs, dim=0)

若有收获,就点个赞吧
0 人点赞
