SQL概述
MaxCompute SQL适用于海量数据(GB、TB、EB级别)、离线批量计算的场合。MaxCompute作业提交后会有几十秒到数分钟不等的排队调度,所以适合处理跑批作业,一次作业批量处理海量数据,不适合直接对接需要每秒处理几千至数万笔事务的前台业务系统。
MaxCompute不能等价于一个数据库,它在很多方面并不具备数据库的特征,如事务、主键约束、索引等。
目前在MaxCompute中允许的最大SQL长度是2MB。
关键字
MaxCompute将SQL语句的关键字作为保留字。在对表、列或是分区命名时如若使用关键字,需给关键字加````符号进行转义,否则会报错。保留字不区分大小写。
类型转换说明
MaxCompute SQL允许数据类型之间的转换,类型转换方式包括显式类型转换和隐式类型转换。
Select Transform
Select Transform功能明显简化了对脚本代码的引用,支持Java、Python、Shell、Perl等语言,完全兼容了Hive的语法、功能和行为,包括input/output row format以及reader/writer。Hive上的脚本大部分可以直接运行,部分脚本只需要经过稍微的改动即可运行。
SQL使用限制项
详见表格SQL使用限制项。
与其他SQL语法的差异
详见MaxCompute SQL语法差异对比,包含了DDL/DML/SCRIPTING语法差异对比。
运算符
包含关系运算符、算术运算符、位运算符、逻辑运算符四种,与常见的数据库语法大致相同,详见MaxCompute运算符。
类型转换
类型转换分为显式转换和隐式转换,隐式转换的限制详见隐式转换说明。
ps:这里笔者认为应尽可能少的使用隐式转换避免debug困难,显式转换(TO_DATE/TO_CHAR/TO_NUMBER/CAST等)用起来不香吗?
INSERT语句
更新表数据(INSERT OVERWRITE and INSERT INTO)
语法格式
INSERT OVERWRITE|INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] [(col1,col2 ...)]select_statementFROM from_statement;
- insert into:直接向表或表的分区中追加数据。不支持INSERT INTO到Hash Clustering表。
- insert overwrite:先清空表中的原有数据,再向表或分区中插入数据。目前INSERT OVERWRITE不支持指定插入列的功能,暂时只能用INSERT INTO。
注意事项
- 生产环境中严禁使用INSERT INTO语句,开发环境时进行测试时才可以使用,这是出于ACID语义的考虑。
- 在反复对同一个分区进行INSERT OVERWRITE的时候,通过DESCRIBE查看到的数据分区Size会不同。这是因为从同一个表的同一个分区SELECT出来再INSERT OVERWRITE回相同分区时,文件切分逻辑发生变化,从而导致数据的Size发生变化。数据的总长度在INSERT OVERWRITE前后是不变的。
可以使用INSERT OVERWRITE语句对表/分区数据实现update/delete操作,如
INSERT OVERWRITE <table_name> PARTITION (ds='20200108')select * --do sth.from <table_name>where ds='20200108'
向某个分区插入数据时,分区列不允许出现在select列表中。
- partition的值只能是常量,不可以出现表达式。
多路输出(MULTI INSERT)
MaxCompute SQL支持在一个语句中将数据插入不同的目标表或者分区中实现多路输出。
输出到动态分区(DYNAMIC PARTITION)
语法格式
FROM from_statementINSERT OVERWRITE | INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)]select_statement1 [FROM from_statement][INSERT OVERWRITE | INTO TABLE tablename2 [PARTITION (partcol1=val3, partcol2=val4 ...)]select_statement2 [FROM from_statement]]
示例
--将表sale_detail中的数据插入到表sale_detail_multi。from sale_detailinsert overwrite table sale_detail_multi partition (sale_date='2010', region='china' )select shop_name, customer_id, total_priceinsert overwrite table sale_detail_multi partition (sale_date='2011', region='china' )select shop_name, customer_id, total_price ;
注意事项
- 同一分区不能在partition子句里出现多次
- 不能使用不同的insert语句,即有些使用insert into有些使用insert overwrite
VALUES
命令格式
INSERT INTO TABLE tablename[PARTITION (partcol1=val1, partcol2=val2,...)][(co1name1,colname2,...)][VALUES (col1_value,col2_value,...),(col1_value,col2_value,...),...]
正常的INSERT VALUES CLAUSE,没啥好说的。
DDL语句
表操作
创建表
语法格式
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name[(col_name data_type [DEFAULT value] [COMMENT col_comment], ...)] --指定列名[COMMENT table_comment] --指定表注释[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] --指定分区字段[CLUSTERED BY (col_name [, col_name, ...]) [SORTED BY (col_name [ASC | DESC] [, col_name [ASC | DESC] ...])] INTO number_of_buckets BUCKETS] -- 用于创建Hash Clustering表时设置表的Shuffle和Sort属性。[STORED BY StorageHandler] -- 仅限外部表。[WITH SERDEPROPERTIES (Options)] -- 仅限外部表。[LOCATION OSSLocation]; -- 仅限外部表。[LIFECYCLE days] --生命周期[AS select_statement]CREATE TABLE [IF NOT EXISTS] table_nameLIKE existing_table_name
注意事项
- 文档的注意事项参考官方文档注意事项,此处就不抄了嗷。
- 禁止使用ctas的写法建表,因为odps会把分区字段认为是普通字段,所建的表也并非分区表。
- ct like建表的方式只会提取表的元数据(即表结构),不包含源表数据,对于分区字段是否会正常复制有待实验。
- 这里重点说一下hash cluster。分区表,即按照数据表的某列或某些列分为多个区,区从形式上可以理解为文件夹;而分桶是相对分区进行更细粒度的划分,即整份数据按照某列属性值的hash值进行区分,如要按照name属性分为3个桶,就是对name属性值的hash值对3取模,按照取模结果,将不同的记录行分到不同的文件中。
查看表信息
desc <table_name>;desc extended <table_name>; --查看外部表信息。
查看建表语句
SHOW CREATE TABLE <table_name>;
删除表
DROP TABLE [IF EXISTS] table_name;
重命名表
ALTER TABLE table_name RENAME TO new_table_name;
修改表Owner
alter table table_name changeowner to 'ALIYUN$xxx@aliyun.com';
修改表的注释
ALTER TABLE table_name SET COMMENT 'tbl comment';
修改表的修改时间
TOUCH表示将修改时间设为当前时间,修改后表的生命周期会重新开始计算。
ALTER TABLE table_name TOUCH;
修改表的Hash Clustering属性
--为表增加Hash Clustering属性ALTER TABLE table_name[CLUSTERED BY (col_name [, col_name, ...]) [SORTED BY (col_name [ASC | DESC] [, col_name [ASC | DESC] ...])] INTO number_of_buckets BUCKETS]--为表去掉Hash Clustering属性ALTER TABLE table_name NOT CLUSTERED;
注意事项
- alter table改变聚集属性,只对于分区表有效,非分区表一旦聚集属性建立就无法改变。
- 由于alter table只影响新分区,所以该语句不可以再指定partition alter table语句适用于存量表,在增加了新的聚集属性之后,新的分区将做Hash Cluster存储。
清空表数据
--对于非分区表TRUNCATE TABLE table_name;--对于分区表,删表重建吧XD--删除分区数据的语句为ALTER TABLE table_name DROP PARTITION (ds='2018-01-01')
生命周期操作
修改表的生命周期
语法格式
ALTER TABLE table_name SET lifecycle days;
- 生命周期按天计算;
- 非分区表按表的最后修改时间进行计算生命周期,分区表则是按各分区最后修改时间独立计算;
- 非分区表超过生命周期后,该表会被drop,而分区表不会;
- 非分区表不支持取消生命周期。
禁止生命周期
可禁止指定分区被生命周期功能回收
ALTER TABLE table_name partition_spec ENABLE|DISABLE LIFECYCLE;ALTER TABLE trans PARTITION(dt='20141111') DISABLE LIFECYCLE; --示例
分区和列操作
添加分区
注意是添加分区,不是添加分区字段
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec;partition_spec:(partition_col1 = partition_col_value1, partition_col2 = partiton_col_value2, ...)
删除分区
ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spec;partition_spec:(partition_col1 = partition_col_value1, partition_col2 = partiton_col_value2, ...)
添加列
--添加列ALTER TABLE table_name ADD COLUMNS (col_name1 type1,col_name2 type2...);--同时添加列和注释ALTER TABLE table_name ADD COLUMNS (col_name1 type1 comment 'XXX',col_name2 type2 comment 'XXX');
修改列名和列注释
--修改列名ALTER TABLE table_name CHANGE COLUMN old_col_name RENAME TO new_col_name;--修改列注释ALTER TABLE table_name CHANGE COLUMN col_name COMMENT comment_string;--同时修改列名和列注释ALTER TABLE table_name CHANGE COLUMN old_col_name new_col_name column_type COMMENT column_comment;
修改表、分区的更新时间
将更新时间设为当前时间。
ALTER TABLE table_name TOUCH PARTITION(partition_col='partition_col_value', ...);
修改分区值
即将某个分区的名字作修改。
ALTER TABLE table_name PARTITION (partition_col1 = partition_col_value1, partition_col2 = partiton_col_value2, ...)RENAME TO PARTITION (partition_col1 = partition_col_newvalue1, partition_col2 = partiton_col_newvalue2, ...);
合并分区
ALTER TABLE <tableName> MERGE [IF EXISTS] PARTITION(<predicate>) [, PARTITION(<predicate2>) ...] OVERWRITE PARTITION(<fullPartitionSpec>) [PURGE];
注意事项
- 如果分区不存在且没有指定IF EXISTS,则报错。
- 如果指定IF EXISTS 后不存在满足MERGE条件的分区,则不生成新分区。
- 如果运行过程中出现源数据被并发修改(包括INSERT,RENAME,DROP)时,即使指定IF EXISTS也会报错。
- 不支持外表,不支持SHARD表,对于CLUSTERED表合并后的分区文件会消除CLUSTERED属性。(SHARD表是啥?)
- 一次性合并分区数量限制:4000个。
视图操作
创建视图
语法格式
CREATE [OR REPLACE] VIEW [IF NOT EXISTS] view_name[(col_name [COMMENT col_comment], ...)][COMMENT view_comment][AS select_statement]
注意事项
- 创建视图时,必须有对视图所引用表的读权限。
- 视图可以引用其它视图,但不能引用自己,也不能循环引用。
- 不允许向视图写入数据,例如使用insert into或者insert overwrite操作视图。
删除视图
DROP VIEW [IF EXISTS] view_name;
重命名视图
ALTER VIEW view_name RENAME TO new_view_name;
SELECT语句
SELECT语法
这里只记录MaxCompute独有的语法及限制。
- select支持正则表达式,举例如下:
- SELECT
abc.*FROM t;选出t表中所有列名以abc开头的列。 - SELECT
(ds)?+.+FROM t;选出t表中列名不为ds的所有列。 - SELECT
(ds|pt)?+.+FROM t;选出t表中排除ds和pt两列的其它列。 - SELECT
(d.*)?+.+FROM t;选出t表中排除列名以d开头的其它列。
- SELECT
UDF支持分区裁剪,意思即在进行分区裁剪时使用了UDF对字段进行处理。支持的方式是将UDF语句先当做一个小作业执行,再将执行的结果替换到原来UDF出现的位置 。实现的方式有以下两种:
在编写UDF的时候,UDF类上加入Annotation。
@com.aliyun.odps.udf.annotation.UdfProperty(isDeterministic=true)
说明com.aliyun.odps.udf.annotation.UdfProperty定义在odps-sdk-udf.jar文件中。您需要把引用的odps-sdk-udf版本提高到0.30.x或以上。- 在SQL语句前设置Flag:
set odps.sql.udf.ppr.deterministic = true;,此时SQL中所有的UDF均被视为deterministic。该操作执行的原理是做执行结果回填,但是结果回填最多回填1000个Partition。因此,如果UDF类加入Annotation,则可能会导致出现超过1000个回填结果的报错。此时您如果需要忽视此错误,可以通过设置Flag:set odps.sql.udf.ppr.to.subquery = false;全局关闭此功能。关闭后,UDF分区裁剪也会失效。
- order by、sort by、distribute by的作用与区别
- order by 会对数据进行全局排序,等同于rdbms中的order by,底层的实现是将所有的数据放在一个reducer里处理,因此可以保证全局有序,但也是因为同样的原因,当数据量特别大的时候效率非常低。
- distribute by 控制相同key的记录被划分到一个Reducer中,该clause可以指定多个字段。
- sort by用于控制每个Reducer中的数据按key进行排序,同样可以指定多个字段,一般会与distribute by一起使用,类似于开窗函数的写法。
SELECT执行语序
1、from2、join on或lateral view explode3、where4、group by5、聚合函数6、having7、select8、distinct/distribute by9、order by/sort by
子查询
in与left semi join的等价性
select * from mytable1 where id in (select id from mytable2);--等效于以下语句。select * from mytable1 a left semi join mytable2 b on a.id = b.id;
not in与left anti join的等价性
select * from mytable1 where id not in (select id from mytable2);--如果mytable2中的所有id都不为NULL,则等效于以下语句。select * from mytable1 a left anti join mytable2 b on a.id = b.id;
exists与left semi join的等价性
SELECT * from mytable1 where exists (select * from mytable2 where id = mytable1.id);--等效于以下语句。SELECT * from mytable1 a left semi join mytable2 b on a.id = b.id;
not exists与left anti join的等价性
select * from mytable1 where not exists (select * from mytable2 where id = mytable1.id);--等效于以下语句。select * from mytable1 a left anti join mytable2 b on a.id = b.id;
子查询的结果集为单行单列时,可以视为标量
- Correlated Subqueries(关联子查询)的使用可以参考Correlated Subqueries 相关子查询,写的较为详细。
交集、并集和补集
| 集合运算 | 对应子句 | 作用 |
|---|---|---|
| 并集 | UNION | 返回两个数据集的并集,并去掉重复的记录 |
| UNION ALL | 返回两个数据集的所有记录 | |
| 备注:UNION后如果有CLUSTER BY、DISTRIBUTE BY、SORT BY、ORDER BY或者LIMIT子句,当设置set odps.sql.type.system.odps2=false;时,其作用于UNION的最后一个select_statement;当set odps.sql.type.system.odps2=true;时,作用于前面所有UNION的结果。 | ||
| 交集 | INTERSECT | 返回两个数据集的交集,并去掉重复的记录 |
| INTERSECT ALL | 返回两个数据集的交集,如有重复记录也会保留 | |
| 补集 | EXCEPT/MINUS | 返回第二个数据集在第一个数据集中的补集,即输出第一个数据集包含而第二个数据集不包含的记录,并去掉重复的记录 |
| EXCEPT ALL/MINUS ALL | 返回第二个数据集在第一个数据集中的补集,即输出第一个数据集包含而第二个数据集不包含的记录,如有重复记录也会保留 |
注意事项
- 集合操作的结果可能是无序的,需要有序的话要加order by。
- 进行集合运算时,列的个数必须一致。
- MaxCompute最多允许256个分支的集合操作,超出个数将报错。(ps:一般也没这么多XD)
JOIN
单纯的join的使用并不需要多说,这里只记录使用时的key point,调优的部分会在后续补充。
- MaxCompute不支持CROSS JOIN笛卡尔积。
- 分区裁剪在文档中的撰写有两处且不一致,实践且保证可用的做法是:需要关联的每一个表,均用where语句进行分区裁剪,且只取出所需的字段(因为底层为列式存储的缘故)以保证性能。
- 如果右边值不唯一,建议不要连续使用过多left join,以免在join的过程中产生数据膨胀,导致作业停滞,但在做事实表的时候通常会考虑用主表来left join其它表,数据膨胀难以避免的情况下,需要保证其合理性(即非笛卡尔积)。
SEMI JOIN 半连接
LEFT SEMI JOIN
当join条件成立时,返回左表中的数据。如果mytable1中某行的id在mytable2的所有id中出现过,则此行保留在结果集中(ps:没错,就是前文cue的exists/in)。示例如下:
SELECT * from mytable1 a LEFT SEMI JOIN mytable2 b on a.id=b.id;
LEFT ANTI JOIN
当join条件不成立时,返回左表中的数据。如果mytable1中某行的id在mytable2的所有id中没有出现过,则此行保留在结果集中。(ps:没错,就是前文cue的not exists/in)。示例如下:
SELECT * from mytable1 a LEFT ANTI JOIN mytable2 b on a.id=b.id;
MAPJOIN HINT
大表JOIN小表可以使用MAPJOIN提升性能。
MAPJOIN的基本原理:在小数据量的场景中,SQL会将您指定的小表全部加载到执行JOIN操作的程序的内存中,从而加快JOIN的执行速度。
MaxCompute SQL不支持在普通JOIN的ON条件中使用不等值表达式、OR逻辑等复杂的JOIN条件,但是在MAPJOIN中可以进行上述操作。
select /*+ mapjoin(a) */a.total_price,b.total_pricefrom shop a join sale_detail bon a.total_price < b.total_price or a.total_price + b.total_price < 500;
注意事项
- LEFT OUTER JOIN的左表必须是大表,RIGHT OUTER JOIN的右表必须是大表,INNER JOIN的左表或右表均可以作为大表,FULL OUTER JOIN不能使用MAPJOIN。
- MAPJOIN支持小表为子查询。
- 使用MAPJOIN时,在引用小表或是子查询时,需要引用别名。
- 在MAPJOIN中,可以使用不等值连接或者使用OR连接多个条件。您可以通过不写ON语句或通过mapjoin on 1 = 1的形式,实现笛卡尔乘积的计算,例如select / + mapjoin(a) / a.id from shop a join table_name b on 1=1,但这样可能带来数据量膨胀问题。
- 目前,MaxCompute在MAPJOIN中最多支持指定128张小表,否则报语法错误。MAPJOIN HINT中多个小表用逗号隔开,例如/+mapjoin(a,b,c)/。
- 如果使用MAPJOIN,则小表占用的总内存不得超过640MB。由于MaxCompute是压缩存储,因此小表在被加载到内存后,数据大小会急剧膨胀。此处的640MB限制是加载到内存后的空间大小。但是也可以通过添加全局flag来增大这个限制,最多为2g。
set odps.sql.mapjoin.memory.max=2048
Lateral View
Lateral View和split,explode等UDTF一起使用,它能够将一行数据拆成多行数据,并在此基础上对拆分后的数据进行聚合。以下例子详见官方文档Lateral View,此处只记录笔者理解。
单个Lateral View语句
语法格式
lateralView: LATERAL VIEW [OUTER] udtf(expression) tableAlias AS columnAlias (',' columnAlias) * fromClause: FROM baseTable (lateralView)*
Lateral view outer:当table function不输出任何一行时,对应的输入行在Lateral view结果中依然保留,且所有table function输出列为null。
示例1:拆分adid_list字段,该字段为用逗号切分的多个值
SELECT pageid, adidFROM pageAds LATERAL VIEW explode(adid_list) adTable AS adid;
示例2:对adid_list字段中的值进行分组统计
SELECT adid, count(1)FROM pageAds LATERAL VIEW explode(adid_list) adTable AS adidGROUP BY adid;
多个Lateral View语句
一个from语句后可以跟多个Lateral View语句,后面的Lateral View语句能够引用它前面的所有表和列名。
示例1:先将col1字段进行拆分,然后作为结果集与col2一起输出。
SELECT myCol1, col2 FROM baseTableLATERAL VIEW explode(col1) myTable1 AS myCol1;
示例2:将col1与col2均进行拆分后一起输出。
SELECT myCol1, myCol2 FROM baseTableLATERAL VIEW explode(col1) myTable1 AS myCol1LATERAL VIEW explode(col2) myTable2 AS myCol2;
注意,官方文档中的例子是基于字段为array数据类型而写的语句,如果字段本身为字符串或json等数据类型,需要使用split或udf函数先对字段进行切分,然后作为explode的传入参数。
HAVING子句
用于过滤分组(group by)后的结果集。
GROUPING SETS
对于经常需要对数据进行多维度的聚合分析的场景,您既需要对a列做聚合,也要对b列做聚合,同时要按照a、b两列同时做聚合,因此需要多次使用UNION ALL,但使用GROUPING SETS可以快速解决此类问题,即在同一个结果中展现不同维度的汇总。
MaxCompute中的GROUPING SETS是对SELECT语句中GROUP BY子句的扩展,允许采用多种方式对结果分组,而不必使用多个SELECT语句来实现这一目的,这样能够使MaxCompute的引擎给出更有效的执行计划,从而提高执行性能。
以下两份代码是等价的
SELECT NULL, NULL, NULL, COUNT(*)FROM requestsUNION ALLSELECT os, device, NULL, COUNT(*)FROM requests GROUP BY os, deviceUNION ALLSELECT null, null, city, COUNT(*)FROM requests GROUP BY city;SELECT os,device, city ,COUNT(*)FROM requestsGROUP BY os, device, city GROUPING SETS((os, device), (city), ());
执行结果如下
+----+--------+------+------------+| os | device | city | cnt |+----+--------+------+------------+| NULL | NULL | NULL | 7 || NULL | NULL | Beijing | 4 || NULL | NULL | Shijiazhuang | 3 || ios | Phone | NULL | 1 || linux | PC | NULL | 1 || linux | Phone | NULL | 1 || windows | PC | NULL | 3 || windows | Phone | NULL | 1 |+----+--------+------+------------+
GROUPING和GROUPING_ID函数
GROUPING SETS结果中使用NULL充当占位符,会无法区分占位符NULL与数据中真正的NULL。因此,MaxCompute为您提供了GROUPING函数。GROUPING函数接受一个列名作为参数,如果结果对应行使用了参数列做聚合,返回0,此时意味着NULL来自输入数据。否则返回1,此时意味着NULL是GROUPING SETS的占位符。
MaxCompute还提供了GROUPING_ID函数,此函数接受一个或多个列名作为参数。结果是将参数列的GROUPING结果按照BitMap的方式组成整数。(ps:不得不说bitmap转id的想法是真的骚)。
样例详见grouping和grouping_id函数使用样例。
CUBE和ROLLUP函数
cube用于展现所选列的所有层次,rollup用于按层级展开。所用到的表如下
显然,我们可以用group byO_NAME,O_CLASS,O_ITEM进行分组,查看粒度为小类的价格合计,但如果还想在结果集中看按粒度为大类的价格合计,粒度为名称的价格合计,只用group by是不能满足的,除非多个group by的结果做union,或用grouping sets。btw,使用rollup也是可以满足需求的。
select o_name,o_class,o_item,sum(o_price)from tgroup by rollup (o_name,o_class,o_item)order by o_name,o_class,o_item
执行结果如图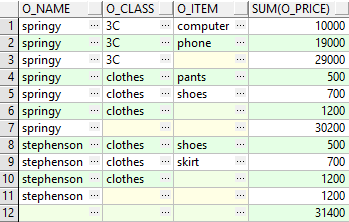
select o_name,o_class,o_item,sum(o_price)
from t
group by cube (o_name,o_class,o_item)
order by o_name,o_class,o_item
执行结果如下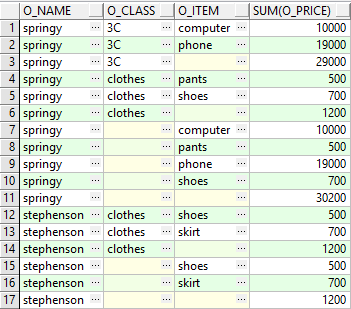
可以看出cube和rollup的区别,cube会把group by列进行全组合,即N个列会产生2^N种组合及对应的记录行,而rollup只是按照层级逐层展开。
此外,以黄色标注的均为空格,为了输出结果更加清晰,我们可以对group by列使用grouping函数,及case when,根据grouping函数的返回值判断该行是否为合计/小计。
此段参考group by、rollup、cube的用法以及区别。
SELECT TRANSFORM语法
SELECT TRANSFORM功能允许您指定启动一个子进程,将输入数据按照一定的格式通过stdin输入子进程,并且通过parse子进程的stdout输出获取输出数据,无需编写UDF,便可以实现MaxCompute SQL不具备的功能(人话就是,适用于实现odps中没有自带的功能,而且又懒的写udf的情况)。
语法格式
SELECT TRANSFORM(arg1, arg2 ...)
(ROW FORMAT DELIMITED (FIELDS TERMINATED BY field_delimiter (ESCAPED BY character_escape)?)?
(LINES SEPARATED BY line_separator)?
(NULL DEFINED AS null_value)?)?
USING 'unix_command_line'
(RESOURCES 'res_name' (',' 'res_name')*)?
( AS col1, col2 ...)?
(ROW FORMAT DELIMITED (FIELDS TERMINATED BY field_delimiter (ESCAPED BY character_escape)?)?
(LINES SEPARATED BY line_separator)? (NULL DEFINED AS null_value)?)?
说明:
- SELECT TRANSFORM关键字可以用MAP或REDUCE关键字替换,无论使用哪个关键字,语义是完全一样的。为使语法更清晰,推荐您使用SELECT TRANSFORM。
- arg1,arg2…是transform的参数,其格式和select子句的Item类似。默认格式下,参数的各个表达式的结果会在隐式转换成STRING后,用\t拼起来,输入到子进程中(该格式可以进行配置,详情请参见下文对ROW FORMAT的说明)。
- USING:指定要启动的子进程的命令。
Using中的格式和Shell的语法非常类似,但并非真的启动Shell来执行,而是直接根据命令的内容来创建了子进程。因此,很多Shell的功能不能使用,例如输入输出重定向、管道、循环等。若有需要,Shell本身也可以作为子进程命令来使用。
- RESOURCES子句:允许指定子进程能够访问的资源,支持以下两种方式指定资源。
- 支持使用resources子句,例如using ‘sh foo.sh bar.txt’ resources ‘foo.sh’,’bar.txt’。
- 支持在SQL语句前使用set odps.sql.session.resources=foo.sh,bar.txt;来指定。注意这种配置是全局的,意味着整个SQL中所有的select transform都可以访问这个设置配置的资源。
- ROW FORMAT子句:允许自定义输入输出的格式。
- 语法中有两个Row Format子句,第一个子句指定输入的格式,第二个指定输出的格式。 默认情况下使用\t来作为列的分隔符,\n作为行的分隔符,使用\N(注意是两个字符,反斜杠字符和字符N)表示NULL。
- field_delimiter、character_escape和line_separator只接受一个字符。如果指定的是字符串,则以第一个字符为准。
- MaxCompute支持Hive指定格式的语法,例如inputRecordReader、outputRecordReader、SerDe等,但您需要打开Hive兼容模式才能使用。打开方式为在SQL语句前加set语句set odps.sql.hive.compatible=true;。如果使用Hive的inputRecordReader、outputRecordReader等自定义类,可能会降低执行性能。
- AS子句:指定输出列。
- 输出列可以不指定类型,默认为STRING类型,例如as(col1, col2)。您也可以指定类型,例如as(col1:bigint, col2:boolean)。
- 由于输出实际是parse子进程stdout获取的,如果指定的类型不是STRING,系统会隐式调用cast函数,而cast有可能出现Runtime Exception。
- 输出列类型不支持部分指定部分不指定,例如as(col1, col2:bigint)。
- as可以省略,此时默认stdout的输出中第一个\t之前的字段为Key,后面的部分全部为Value,相当于as(key, value)。
调用Shell脚本示例
通过Shell脚本生成50行数据,值是从1到50,data字段输出如下:
SELECT TRANSFORM(script) USING 'sh' AS (data)
FROM (
SELECT 'for i in `seq 1 50`; do echo $i; done' AS script
) t
;
调用Python脚本示例
Python脚本如下,作用是按行读入记录,按\t进行切分,对空值进行判断后将其相加并返回结果,保存脚本名为myplus.py
#!/usr/bin/env python
import sys
line = sys.stdin.readline()
while line:
token = line.split('\t')
if (token[0] == '\\N') or (token[1] == '\\N'):
print '\\N'
else:
print int(token[0]) + int(token[1])
line = sys.stdin.readline()
将该Python脚本文件添加为MaxCompute资源(Resource),有Dataphin或DataWorks的可以直接添加资源。
add py ./myplus.py -f;
使用select transform调用资源
Create table testdata(c1 bigint,c2 bigint); --创建测试表。
insert into Table testdata values (1,4),(2,5),(3,6); --测试表中插入测试数据。
--接下来执行select transform。
SELECT
TRANSFORM (testdata.c1, testdata.c2)
USING 'python myplus.py'resources 'myplus.py'
AS (result bigint)
FROM testdata;
--或执行以下语句。
set odps.sql.session.resources=myplus.py;
SELECT TRANSFORM (testdata.c1, testdata.c2)
USING 'python myplus.py'
AS (result bigint)
FROM testdata;
--执行结果
+-----+
| cnt |
+-----+
| 5 |
| 7 |
| 9 |
+-----+
MaxCompute也支持直接将Python命令作为transform数据输入,但这里需要注意maxcompute支持的python版本,文档中的python2的语法。
SELECT TRANSFORM('for i in xrange(1, 50): print i;') USING 'python' AS (data);
调用Java脚本示例
与Python示例中的脚本同样的作用,唯一不同的就是Java需要打包,然后作为资源上传至MaxCompute
package com.aliyun.odps.test;
import java.util.Scanner
public class Sum {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
while (sc.hasNext()) {
String s = sc.nextLine();
String[] tokens = s.split("\t");
if (tokens.length < 2) {
throw new RuntimeException("illegal input");
}
if (tokens[0].equals("\\N") || tokens[1].equals("\\N")) {
System.out.println("\\N");
}
System.out.println(Long.parseLong(tokens[0]) + Long.parseLong(tokens[1]));
}
}
}
使用select transform调用资源
Create table testdata(c1 bigint,c2 bigint); --创建测试表。
insert into Table testdata values (1,4),(2,5),(3,6); --测试表中插入测试数据。
--接下来执行Select Transform。
SELECT TRANSFORM(testdata.c1, testdata.c2) USING 'java -cp Sum.jar com.aliyun.odps.test.Sum' resources 'Sum.jar' from testdata;
--或执行以下语句。
set odps.sql.session.resources=Sum.jar;
SELECT TRANSFORM(testdata.c1, testdata.c2) USING 'java -cp Sum.jar com.aliyun.odps.test.Sum' FROM testdata;
调用其他脚本语言
目前只支持awk和perl(ps:perl竟然还有人用系列)
SELECT TRANSFORM(*) USING "awk '//{print $2}'" as (data) from testdata;
SELECT TRANSFORM (testdata.c1, testdata.c2) USING "perl -e 'while($input = <STDIN>){print $input;}'" FROM testdata;
串联使用示例
即如子查询一般嵌套使用,略。
SELECT TRANSFORM性能介绍
select transform与UDTF在不同场景下性能不同。经过多种场景对比测试,数据量较小时,大多数场景下select transform有优势,而数据量大时UDTF有优势。因为select transform的开发更加简便,所以select transform更适合做Ad Hoc(即席查询)的数据分析。
详细的性能对比可参考性能对比,但笔者认为在项目中使用应统一使用一类写法,使代码便于维护,select transform大部分人应该用的较少,而且在使用SQL和UDF的情况下,相当于是对MapReduce过程做了一层封装,再去使用map和reduce关键字会降低可读性。
脚本模式
脚本模式SQL即Script Mode SQL,适用于改写本来要用层层嵌套子查询的单个语句,或者因为脚本复杂性而不得不拆成多个语句的脚本。
脚本模式语法示例
create table if not exists dest(key string , value bigint) partitioned by (d string);
create table if not exists dest2(key string,value bigint) partitioned by (d string);
@a := select * from src where value >0;
@b := select * from src2 where key is not null;
@c := select * from src3 where value is not null;
@d := select a.key,b.value from @a left outer join @b on a.key=b.key and b.value>0;
@e := select a.key,c.value from @a inner join @c on a.key=c.key;
@f := select * from @d union select * from @e union select * from @a;
insert overwrite table dest partition (d='20171111') select * from @f;
@g := select e.key,c.value from @e join @c on e.key=c.key;
insert overwrite table dest2 partition (d='20171111') SELECT * from @g;
注意事项
- 脚本模式支持SET语句、部分DDL语句(不支持结果为屏显类型的语句如desc、show)、DML语句。
- 一个脚本的完整形式是SET、DDL、DML语句按先后顺序排列。每种语句都可以包含0到多个具体的SQL语句,且不同类型的语句不能交错。
- 使用
@声明变量。 - 一个脚本最多支持一个屏显结果的语句(如单独的SELECT语句),否则会发生报错。不建议在脚本中执行屏显的SELECT语句。
- 一个脚本最多支持一个CREATE TABLE AS语句并且必须是最后一句。推荐您将建表语句与INSERT语句分开写。
- 脚本模式下,一旦有一个语句失败,整个脚本的语句都不会执行成功。
- 脚本模式下,只有当所有输入的数据都准备好并到达,才会生成一个作业进行数据处理。
- 脚本模式下,如果一个表先被写再被读,则会发生报错。
使用方式
- 使用MaxCompute Studio的脚本模式
通过客户端(odpscmd)提交脚本,命令格式如下:(.mxql文件?)
odpscmd -s myscript.mxql;在DataWorks中建立脚本模式的节点(ODPS Script)
CTE
语法格式
WITH cte_name AS ( cte_query ) [,cte_name2 AS ( cte_query2 ) ,……]注意:MaxCompute本身支持CTE,但并不代表底层使用MaxCompute的所有产品都支持。
EXPLAIN
ps:学会看执行计划是做优化的基本功。
语法格式
EXPLAIN <DML query>;
执行结果包含:
- 对应于该DML语句的所有Task的依赖结构。
- Task中所有Task的依赖结构。
- Task中所有Operator的依赖结构。
explain的输出结果会有以下三个部分:
- 首先是Job间的依赖关系:job0 is root job。因为该Query只需要一个Job(job0),所以只需要一行信息。
- 其次是Task间的依赖关系:
job0包含三个Task。M1_Stg1和M2_Stg1这两个Task会先执行,执行完成后,再执行J3_1_2_Stg1。In Job job0: root Tasks: M1_Stg1, M2_Stg1 J3_1_2_Stg1 depends on: M1_Stg1, M2_Stg1
Task的命名规则如下:
- 在MaxCompute中,共有四种Task类型:MapTask、ReduceTask、JoinTask和LocalWork。
- Task名称的第一个字母表示了当前Task的类型,例如M2Stg1就是一个MapTask。
- 紧跟着第一个字母后的数字,代表了当前Task的ID。这个ID在所有对应当前Query的Task中是唯一的。
- 用下划线分隔的数字代表当前Task的直接依赖,例如J3_1_2_Stg1表示当前Task(ID为3)依赖ID为1、2的两个Task。
第三部分即Task中的Operator结构,Operator串描述了一个Task的执行语义。
In Task M1_Stg1:
Data source: yudi_2.src # "Data source"描述了当前Task的输入内容。
TS: alias: a # TableScanOperator
RS: order: + # ReduceSinkOperator
keys:
a.value
values:
a.key
partitions:
a.value
In Task J3_1_2_Stg1:
JOIN: a INNER JOIN b # JoinOperator
SEL: Abs(UDFToDouble(a._col0)), b._col5 # SelectOperator
FS: output: None # FileSinkOperator
In Task M2_Stg1:
Data source: yudi_2.src1
TS: alias: b
RS: order: +
keys:
b.value
values:
b.value
partitions:
b.value
各Operator的含义如下:
- TableScanOperator:描述了Query语句中的FROM语句块的逻辑。EXPLAIN结果中会显示输入表的名称(Alias)。
- SelectOperator:描述了Query语句中的SELECT语句块的逻辑。EXPLAIN结果中会显示向下一个Operator传递的列,多个列由逗号分隔。
- 如果是列的引用,则显示成< alias >.< column_name >。
- 如果是表达式的结果,则显示函数的形式,例如func1(arg1_1, arg1_2, func2(arg2_1, arg2_2))。
- 如果是常量,则直接显示值内容。
- FilterOperator:描述了Query语句中的WHERE语句块的逻辑。EXPLAIN结果中会显示一个WHERE条件表达式,形式类似SelectOperator的显示规则。
- JoinOperator:描述了Query语句中的JOIN语句块的逻辑。EXPLAIN结果中会显示哪些表用哪种方式Join在一起。
- GroupByOperator:描述了聚合操作的逻辑。如果Query中使用了聚合函数,就会出现该结构,EXPLAIN结果中会显示聚合函数的内容。
- ReduceSinkOperator:描述了Task间数据分发操作的逻辑。如果当前Task的结果会传递给另一个Task,则必然需要在当前Task的最后,使用ReduceSinkOperator执行数据分发操作。EXPLAIN的结果中会显示输出结果的排序方式、分发的Key、Value以及用来求Hash值的列。
- FileSinkOperator:描述了最终数据的存储操作。如果Query中有INSERT语句块,EXPLAIN结果中会显示目标表名称。
- LimitOperator:描述了Query语句中的LIMIT语句块的逻辑。EXPLAIN结果中会显示LIMIT数。
- MapjoinOperator:类似JoinOperator,描述了大表的JOIN操作。
如果Query足够复杂,EXPLAIN的结果太多,则会触发API的限制,无法得到完整的EXPLAIN结果。此时您可以拆分Query,对各部分分别进行EXPLAIN操作,以了解Job的结构。
参数化视图
传统的视图中,调用者可以像读普通表一样调用视图,无需关心底层的实现,但是传统的视图并不接受调用者传递的任何参数(例如调用者无法对视图读取的底层表进行数据过滤或传递其他参数),导致代码重用能力低下,因此MaxCompute提供了参数化视图,但请注意,仅适用于脚本模式(ps:能用上的时候应该很少,能用到的情况都能通过将表物理化+报表工具处理,因此此处只做简单说明,个人觉得复杂且不好用,后续也许会update,who knows~)。
语法格式
create view if not exists pv1(@a table (k string,v bigint), @b string)
as
select srcp.key,srcp.value from srcp join @a on srcp.key=a.k and srcp.p=@b;
语法说明
ps:写累了,详见参数化视图。
UDT
UDT即User Defined Type,用户自定义类型,即允许在SQL中直接调用第三方语言的类使用其方法、或直接使用第三方对象获取其数据内容(ps:花里胡哨?有具体应用场景的话此段会update),详见UDT概述。
内建函数
UDF
UDF全称为User Defined Function,即用户自定义函数。MaxCompute提供多种内建函数来满足您的计算需求,同时您还可以通过创建自定义函数来满足不同的计算需求。
MaxCompute支持的UDF有三种,如下表所示。
| UDF 分类 | 描述 |
|---|---|
| UDF(User Defined Scalar Function) | 用户自定义标量值函数(User Defined Scalar Function)。其输入与输出是一对一的关系,即读入一行数据,写一条输出值 。 |
| UDTF(User Defined Table Valued Function) | 自定义表值函数。用来解决一次函数调用输出多行数据场景。它是唯一能够返回多个字段的自定义函数。 |
| UDAF(User Defined Aggregation Function) | 自定义聚合函数。其输入与输出是多对一的关系, 即将多条输入记录聚合成一条输出值。它可以与SQL中的GROUP BY语句联用。 |
具体的编写方法参见MaxCompute UDF,内含Java/Python两种语言的实现方法且对应示例。
UDJ
基于MaxCompute 2.0计算引擎,MaxCompute在UDF框架中新近引入一种新扩展机制UDJ(User Defined Join),来实现灵活的跨表、多表自定义操作,同时减少通过MapReduce等方式对分布式系统底层细节的操作,详见MaxCompute UDJ。
文中所举例子在MySQL实验是可以用标准SQL写出的,后续会在MaxCompute上验证,UDJ同样需要应用场景来验证是否需要花费时间研究。
附SQL:
--build schema
create table payment (
user_id varchar(200),
times varchar(200),
pay_info varchar(200)
);
insert into payment values ('2656199','2018-02-13 22:30:00','gZhvdySOQb');
insert into payment values ('8881237','2018-02-13 08:30:00','pYvotuLDIT');
insert into payment values ('8881237','2018-02-13 10:32:00','KBuMzRpsko');
create table user_client_log (
user_id varchar(200),
times varchar(200),
content varchar(200)
);
insert into user_client_log values ('8881237','2018-02-13 00:30:00','click MpkvilgWSmhUuPn');
insert into user_client_log values ('8881237','2018-02-13 06:14:00','click OkTYNUHMqZzlDyL');
insert into user_client_log values ('8881237','2018-02-13 10:30:00','click OkTYNUHMqZzlDyL');
--process
--MySQL实现,思路是两表关联时,在关联条件中先根据主键做关联,然后取时间最小的一条出来
select a.user_id
,a.times
,concat_ws(',pay ',a.content,c.pay_info) as content
from user_client_log as a
join payment as c
on (select min(times)
from payment as b
where a.user_id=b.user_id
and a.times<=b.times) = c.times;
--Oracle实现,思路是两表根据主键关联,然后计算时间差最小的一条,使用开窗函数取出,
select * from (
select t.*,row_number() over(partition by t.user_id_a,t.times_a order by t.itv) rn
from (
select a.user_id user_id_a
,b.user_id user_id_b
,a.times times_a
,b.times times_b
,abs(ceil((to_date(a.times,'yyyy-mm-dd hh24:mi:ss')
- to_date(b.times,'yyyy-mm-dd hh24:mi:ss'))* 24*60*60)) itv
from user_client_log a
left join payment b
on a.user_id = b.user_id ) t) t1
where t1.rn=1
附录
参见附录,包含了转义字符说明、LIKE字符匹配符、正则表达式规范(ps:这份东西2019.12.23才出,在此之前全靠自行摸索的我眼泪流下来QAQ,因为MaxCompute的正则跟普通的写法会有些许不同,会导致语句报错)、保留字与关键字和数据类型映射表(需要将数据同步到RDS等数据库时会很有用)。

若有收获,就点个赞吧
0 人点赞
