Order by
Order by后需要增加 limit 限制数量,因为 order by 是全量排序,没有 limit 时执行性能较低,在Dataphin中默认是Limit 10000。
分区裁剪
分区剪裁是指对分区列指定过滤条件,使得SQL执行时只用读取表的部分分区数据,避免全表扫描引起的数据错误及资源浪费。
判断分区裁剪是否生效
通过explain命令查看SQL的执行计划。
- 分区裁剪失效

- 分区裁剪生效

分区裁剪失效的场景分析
- 在where条件中使用了自定义函数导致分区裁剪失效
解决方法:在写UDF的时候加入Annotation,或在SQL前设置Flag,并与SQL语句一同执行,详见UDF分区裁剪失效解决方法。
- 表间关联导致分区裁剪失效
解决方法:由于官方文档有两处都讲到了多表关联分区裁剪的情况,但说法有矛盾,因此本文均不记录。多表关联时,将需要用到的字段,以及分区裁剪的where条件写成子查询的形式,以保证分区裁剪生效。同样在explain出来的执行计划中,在执行计划的Map Task部分可以通过Data Source部分、Join Task的FIL部分判断分区裁剪是否生效。
数据倾斜
产生数据倾斜的根本原因是,有少数Worker处理的数据量远远超过其他Worker处理的数据量,从而导致少数Worker的运行时长远远超过其他Worker的平均运行时长,从而导致整个任务运行时间超长,造成任务延迟。
JOIN长尾优化
判断是否发生数据倾斜
通过LogView
- 复制logview的链接并打开,双击执行Join操作的fuxi job,打开[Long-tails]标签,如果有记录则表示数据已经倾斜了。
- 打开FuxiInstance后的查看图标,查看stdout中Instance读入的数据量。例如:
表示JOIN输入读取的数据量是1389941257行。如果Long-Tails中Instance读取的数据量远超过其它Instance读取的数据量,则表示是因为数据量导致长尾。Read from 0 num:52743413 size:1389941257
经验判断(雾)
SQL执行过程中卡在99%进度半天出不来结果或者进入下一阶段的八成是倾斜了(笑)。
Join的MapReduce过程
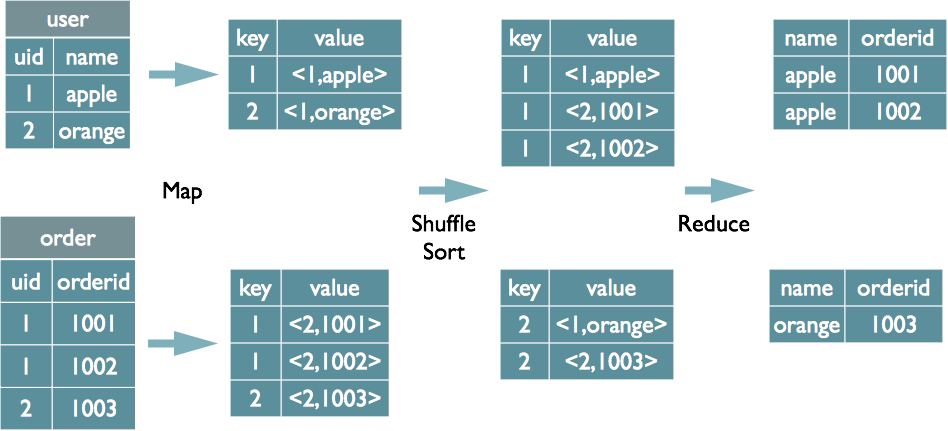
欲谈优化,先谈原理。在Part 9的部分,已经写到了MapReduce的过程,这里再简要描述一下:
- 数据输入:对数据进行分片,每个分片一个Map Worker。
- Map阶段:对分片后的数据进行计算处理,输出的时候需要指定key,用于决定后续分发到哪个Reducer。
- 合并排序:在进入Reduce阶段之前,会对每个Mapper输出的数据按照key进行排序,使得key值相同的数据彼此相邻,如果有Combiner,则也会在这个阶段执行,根据key值对数据进行合并。Combiner的输入、输出参数必需与Reducer保持一致,这个过程被称为Shuffle。
- Reduce阶段:相同key的数据会被传送至同一个Reduce Worker执行计算操作,在这个过程后,key相同的多条数据会被聚合成一条,作为最终输出。
- 结果数据输出。
那Join操作是如何在这个过程中进行的呢?还是在MapReduce的框架中进行思考。
- Map阶段,根据所取的字段,对于每个表的数据会将其变为kv对,key为用于关联的字段的值,value为select语句中需要取的字段的值,但同时在value中为kv对打上tag,标识其来自于哪个表。
- Shuffle阶段,同样的会根据key值进行分组,将相同key的数据放在一起。
- Reduce阶段,每个Reduce Worker获取key对应的value值列表,根据kv对中的来源表tag对数据进行分组,最后执行笛卡尔积进行输出,即在Reduce阶段才是真正的join,因此这种Join也被称为Reduce side Join。
但显而易见的,Shuffle过程的开销太大了,尤其当数据量非常庞大的情况下,根据key来做分组的过程会很消耗算力。
使用MapJoin解决大小表关联
上面讲到了普通的Join真正做关联的部分是都放在了Reduce的部分来做,但在大表join小表的场景下,我们能否将关联提前到Map端呢?因此就有了MapJoin,即将小表加入缓存,广播传递到所有的Join Task Instance上面,然后直接和大表做Hash Join,简单的说就是将join操作提前到map端,每一个Mapper上都有一份小表,因此也就省去了Shuffle的过程。
MapJoin使用也非常简单,只需要在SELECT后加上/+ MAPJOIN(B) /这个hints,括号里填写小表的表名即可,详见Part 8。
无效值导致的长尾
当关联字段大部分都为无效值(空值或0)时,在进行大表关联时,想想Shuffle后会发生啥?但目前MaxCompute已经对NULL值做了特殊处理,因此空值不会产生数据倾斜,但其余的情况依然值得讨论。
- 解法1:业务层面如果已经知道无效值是不会关联出结果的,就可以使用分而治之的方法,限制关联字段的值来进行关联,再union无效值的部分即可。
- 解法2:随机值打散,即通过if语句等对关联字段做判断,如果为无效值,则用随机值替换。
Group by导致的长尾
Group by的原理是Shuffle中按照group by的字段作为key值来进行分组,在Reduce端进行聚合,因此也会出现倾斜问题。一种通用的解法如下
SELECT Key,COUNT(*) AS Cnt FROM TableName GROUP BY Key;-- 假设长尾的Key已经找到是KEY001。SELECT a.Key, SUM(a.Cnt) AS CntFROM (SELECT Key, COUNT(*) AS CntFROM TableNameGROUP BY Key,CASEWHEN Key = 'KEY001' THEN Hash(Random()) % 50ELSE 0END) aGROUP BY a.Key;
但有的时候人为的增加了Reduce的过程,反而可能会变慢,而后文会有提到使用相关参数的调优。
Distinct导致的长尾
distinct的原理是,把要去重的字段做key,在Reduce端根据key只输出一条记录,再进行后续的各种运算,比如count。
--原始SQL,不考虑Uid为空。
SELECT COUNT(uid) AS Pv
, COUNT(DISTINCT uid) AS Uv
FROM UserLog;
--改写成
SELECT SUM(PV) AS Pv
, COUNT(*) AS UV
FROM (
SELECT COUNT(*) AS Pv
, uid
FROM UserLog
GROUP BY uid
) a;
--原始SQL
select distinct a from t;
--可改写成
select a
from t
group by a;
通过Combiner解决长尾
对于MapRedcuce作业,使用Combine是一种常见的长尾优化策略。通过Combiner,减少Mapper Shuffle往Reducer的数据,可以大大减少网络传输的开销。对于MaxCompute SQL,这种优化会由系统自动完成。
通过系统优化解决长尾
当系统识别出长尾后,即任务运行了99%,只剩下一个Reducer没有进度,系统将自动启动了一个新的Reducer,运行一样的数据,然后取运行结束较早的数据归并到最后的结果集里。
数据倾斜相关优化参数
set odps.sql.skewjoin=true # 开启倾斜优化
set odps.sql.skewinfo=skewed_src:(skewed_key) [("skewed_value")] # 设置数据倾斜的列和值
set odps.sql.groupby.skewindata=true # 适用于group by
其实解决数据倾斜的最好方式就是从业务层面入手,再分解成MapReduce的过程进行解读。

若有收获,就点个赞吧
0 人点赞
