单表查询优化
全值匹配我最爱
可以看到,复合索引都被用到了,并且SQL中查询字段的顺序,跟使用索引中字段的顺序,没有关系。优化器会在不影响 SQL 执行结果的前提下,自动地优化
结论:尽可能使用全值匹配,全值匹配查询的字段按照顺序在索引中都可以匹配到
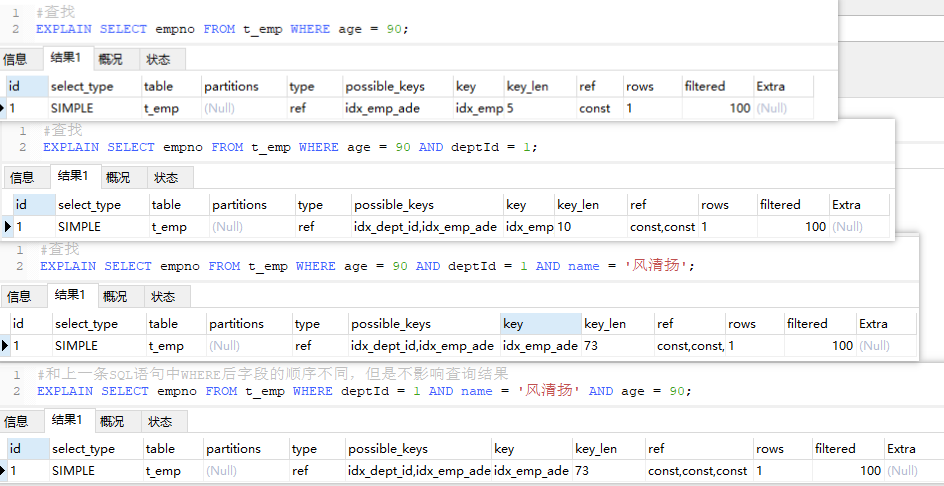
最佳左前缀法则

可以看到,查询字段与索引字段顺序的不同会导致,索引无法充分使用,甚至索引失效
原因:使用复合索引,需要遵循最佳左前缀法则,即如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列
结论:过滤条件要使用索引必须按照索引建立时的顺序,依次满足,一旦跳过某个字段,索引后面的字段都无法被使用
索引列上不计算

不在索引列上做任何操作(计算、函数、(自动 or 手动)类型转换),可能会导致索引失效而转向全表扫描
SQL语句。可以看出,当age字段使用了left函数以后,导致索引完全失效
结论:等号左边无计算
范围之后全失效

可以看出,当对age字段使用范围查询后,使得范围后面的索引失效了
建议:将可能做范围查询的字段的索引顺序放在最后
结论:使用范围查询后,如果范围内的记录过多,会导致索引失效,因为从自定义索引映射到主键索引需要耗费太多的时间,反而不如全表扫描来得快
覆盖索引多使用

结论:使用覆盖索引(Using index)会提高检索效率
使用不等会失效

在使用不等于(!= 或者<>)时,有时会无法使用索引会导致全表扫描
结论:尽量不要使用不等于
使用NULL值要小心

在使用IS NULL或者IS NOT NULL时,可能会导致索引失效,但是如果允许字段为空,则
- IS NULL 不会导致索引失效
- IS NOT NULL 会导致索引失效
模糊查询加右边

要使用模糊查询时,百分号最好加在右边,而且进行模糊查询的字段必须是单值索引
结论:对索引进行模糊查询时,最好在右边加百分号。必须在左边或左右加百分号时,需要用到覆盖索引来提升查询效率
可以加入冗余列(MySQL5.7之后加入了虚拟列,使用虚拟列更合适,思路相同),比如 mobile_reverse,内部存储为 mobile 的倒叙文本,如 mobile为17312345678,那么 mobile_reverse 存储 87654321371,为 mobile_reverse 列建立索引,查询中使用语句 mobile_reverse like reverse(’%5678’) 即可。
reverse 是 MySQL 中的反转函数,这条语句相当于 mobile_reverse like ‘8765%’ ,这种语句是可以使用索引的。
字符串加单引号
当字段为字符串时,查询时必须带上单引号。否则会发生自动的类型转换,从而发生全表扫描
尽量不用or查询

如果使用or,可能导致索引失效。所以要减少or的使用,可以使用 union all 或者 union 来替代:
查询语句的查询条件中只有OR关键字,且OR前后的两个条件中的列都是索引时,查询中才使用索引。否则,查询将不使用索引。
关联查询优化
LEFT JOIN优化

- 在优化关联查询时,只有在被驱动表上建立索引才有效
- left join 时,左侧的为驱动表,右侧为被驱动表
INNER JOIN优化

结论:inner join 时,mysql 会把小结果集的表选为驱动表(小表驱动大表) 所以最好把索引建立在大表(数据较多的表)上
RIGHT JOIN优化
优化类型和LEFT JOIN类似,只不过被驱动表变成了左表
子查询优化
结论: 在范围判断时,尽量不要使用not in 和not exists,使用left join on xxx is null 代替。 NOT IN、NOT EXISTS导致索引失效
排序分组优化

在查询中难免会对查询结果进行排序操作。进行排序操作时要避免出现 Using filesort,应使用索引给排序带来的方便
ORDER BY 优化
以下查询都是在索引覆盖的条件下进行的
要想在排序时使用索引,避免 Using filesort,首先需要发生索引覆盖,其次
- ORDER BY 后面字段的顺序要和复合索引的顺序完全一致
- ORDER BY 后面的索引必须按照顺序出现,排在后面的可以不出现
- 要进行升序或者降序时,字段的排序顺序必须一致。不能一部分升序,一部分降序,可以都升序或者都降序
- 如果复合索引前面的字段作为常量出现在过滤条件中,排序字段可以为紧跟其后的字段

MySQL的排序算法
当发生 Using filesort 时,MySQL会根据自己的算法对查询结果进行排序
- 双路排序
- MySQL 4.1 之前是使用双路排序,字面意思就是两次扫描磁盘,最终得到数据,读取行指针和 order by 列,对他们进行排序,然后扫描已经排序好的列表,按照列表中的值重新从列表中读取对应的数据输出
- 从磁盘取排序字段,在 buffer 进行排序,再从磁盘取其他字段
- 简单来说,取一批数据,要对磁盘进行了两次扫描,众所周知,I\O 是很耗时的,所以在 mysql4.1 之后,出现了第二种改进的算法,就是单路排序
- 单路排序
- 从磁盘读取查询需要的所有列,按照 order by 列在 buffer 对它们进行排序,然后扫描排序后的列表进行输出, 它的效率更快一些,避免了第二次读取数据。并且把随机 IO 变成了顺序 IO,但是它会使用更多的空间, 因为它把每一行都保存在内存中了
- 存在的问题:在 sort_buffer 中,方法 B 比方法 A 要多占用很多空间,因为方法 B 是把所有字段都取出, 所以有可能取出的数据的总大小超出了 sort_buffer 的容量,导致每次只能取 sort_buffer 容量大小的数据,进行排序(创建 tmp 文件,多 路合并),排完再取取 sort_buffer 容量大小,再排……从而多次 I/O。也就是本来想省一次 I/O 操作,反而导致了大量的 I/O 操作,反而得不偿失
- 优化Using filesort
- 增大 sort_butter_size 参数的设置
- 不管用哪种算法,提高这个参数都会提高效率,当然,要根据系统的能力去提高,因为这个参数是针对每个进程的 1M-8M 之间调整
- 增大 max_length_for_sort_data 参数的设置
- mysql 使用单路排序的前提是排序的字段大小要小于 max_length_for_sort_data
- 提高这个参数,会增加用改进算法的概率。但是如果设的太高,数据总容量超出 sort_buffer_size 的概率就增大, 明显症状是高的磁盘 I/O 活动和低的处理器使用率。(1024-8192 之间调整)
- 减少 select 后面的查询的字段
- 查询的字段减少了,缓冲里就能容纳更多的内容了,间接增大了sort_buffer_size
- 增大 sort_butter_size 参数的设置
GROUP BY 优化
优化方式和 ORDER BY 类似,参考ORDER BY 的优化方式即可
WHERE和HAVING的区别
- WHERE是一个约束声明,使用WHERE约束来自数据库的数据,WHERE是在结果返回之前起作用的,WHERE中不能使用聚合函数。
- HAVING是一个过滤声明,是在查询返回结果集以后对查询结果进行的过滤操作,在HAVING中可以使用聚合函数。另一方面,HAVING子句中不能使用除了分组字段和聚合函数之外的其他字段。
从性能的角度来说,HAVING子句中如果使用了分组字段作为过滤条件,应该替换成WHERE子句。因为WHERE可以在执行分组操作和计算聚合函数之前过滤掉不需要的数据,性能会更好。
Limit 分页优化
在偏移量非常大的时候,例如 LIMIT 10000,20 这样的查询,这时MySQL需要查询10020条记录然后只返回最后20条,前面的10000条记录都将被抛弃,这样的代价是非常高的。如果所有的页面被访问的频率都相同,那么这样的查询平均需要访问半个表的数据。要优化这种查询,要么是在页面中限制分页的数量,要么是优化大偏移量的性能。
SELECT film_id,description FROM sakila.film ORDER BY title LIMIT 50,5;
优化此类分页查询的一个最简单的办法就是尽可能地使用索引覆盖扫描,而不是查询所有的列,然后根据需要做一次关联操作再返回所需的列。对于偏移量很大的时候,这样做的效率会提升非常大。考虑下面的查询
SELECT film.film_id,film.description FROM sakila.film INNER JOIN ( SELECT film_id FROM sakila.film ORDER BY title LIMIT 50,5 ) AS lim USING(film_id);有时候也可以将LIMIT查询转换为已知位置的查询,让MySQL通过范围扫描获得对应的结果。例如,如果在一个位置列上有索引,并且预先计算出了边界值,上面的查询就可以改写为:
SELECT film_id,description FROM skila.film WHERE position BETWEEN 50 AND 54 ORDER BY position;LIMIT和OFFSET的问题,其实是OFFSET的问题,它会导致MySQL扫描大量不需要的行然后再抛弃掉。如果可以使用书签记录上次取数的位置,那么下次就可以直接从该书签记录的位置开始扫描,这样就可以避免使用OFFSET。
截取查询分析
慢日志查询
概念
- MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阈值的语句,具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中
- 具体指运行时间超过long_query_time值的SQL,则会被记录到慢查询日志中。long_query_time的默认值为 10,意思是运行10秒以上的语句
- 由他来查看哪些SQL超出了我们的最大忍耐时间值,比如一条sql执行超过5秒钟,我们就算慢SQL,希望能收集超过5秒的sql,结合之前explain进行全面分析
使用
默认情况下,MySQL 数据库没有开启慢查询日志,需要我们手动来设置这个参数
如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。 慢查询日志支持将日志记录写入文件
| SQL 语句 | 描述 | 备注 |
|---|---|---|
| SHOW VARIABLES LIKE ‘’%slow_query_log%’ | 查看慢查询日志是否开启 | 默认情况下 slow_query_log 的值为 OFF |
| set global slow_query_log=1 | 开启慢查询日志 | |
| SHOW VARIABLES LIKE ‘long_query_time%’ | 查看慢查询设定阈值 | 单位:秒 |
| set long_query_time=1 | 设定慢查询阈值 | 单位:秒 |
配置文件
如永久生效需要修改配置文件my.cnf 中[mysqld]下配置
slow_query_log=1
slow_query_log_file=/var/lib/mysql/atguigu-slow.log
long_query_time=3
log_output=FILE
运行查询时间长的 sql,可以打开慢查询日志查看
SHOW PROFILE分析
概念
在MySQL数据库中,可以通过配置profiling参数来启用SQL剖析。该参数可以在全局和session级别来设置。对于全局级别则作用于整个MySQL实例,而session级别紧影响当前session。该参数开启后,后续执行的SQL语句都将记录其资源开销,诸如IO,上下文切换,CPU,Memory等等
使用
默认情况下,MySQL 数据库没有开启PROFILE,需要我们手动来设置这个参数
#查看profile状态
SHOW VARIABLES LIKE 'profiling';
#开启profile
set profiling = 1;
#运行要分析的SQL之后
#查看记录
SHOW PROFILES;
#诊断SQL
SHOW PROFILE CPU,BLOG IO FOR QUERT 190 #数字对应QUERYID



显示信息
type:
ALL --显示所有的开销信息
| BLOCK IO --显示块IO相关开销
| CONTEXT SWITCHES --上下文切换相关开销
| CPU --显示CPU相关开销信息
| IPC --显示发送和接收相关开销信息
| MEMORY --显示内存相关开销信息
| PAGE FAULTS --显示页面错误相关开销信息
| SOURCE --显示和Source_function,Source_file,Source_line相关的开销信息
| SWAPS --显示交换次数相关开销的信息
注意
需要注意如下几点
- converting HEAP to MyISAM:查询结果太大,内存不够用往磁盘上搬了
- Creating tmp table:创建临时表
- Copying to temp table on disk:把内存中的临时表复制到磁盘

若有收获,就点个赞吧
0 人点赞
