概述
MVCC (Multi-Version Concurrency Control) 是一种基于多版本的并发控制协议,只有在InnoDB引擎下存在。MVCC是为了实现事务的隔离性,通过版本号,避免同一数据在不同事务间的竞争,你可以把它当成基于多版本号的一种乐观锁。
当然,这种乐观锁只在事务级别未提交锁和已提交锁时才会生效。MVCC最大的好处:读不加锁,读写不冲突。在读多写少的应用中,读写不冲突是非常重要的,极大的增加了系统的并发性能。
注:与MVCC相对的,是基于锁的并发控制,Lock-Based Concurrency Control LBCC
MVCC只在 READ COMMITTED 和 REPEATABLE READ 两个隔离级别下工作。其他两个隔离级别和MVCC不兼容,因为 READ UNCOMMITTED 总是读取最新的数据行,而不是符合当前事务版本的数据行。而 SERIALIZABLE 则会对所有读取的行都加锁。
实现机制
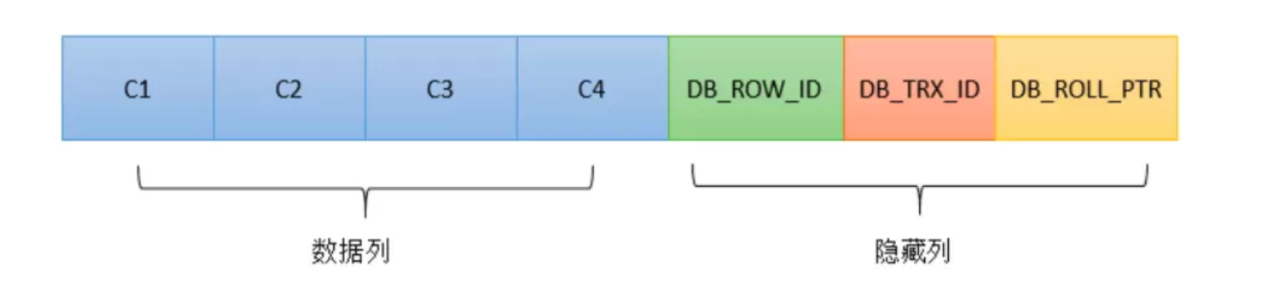
InnoDB在每行数据都增加三个隐藏字段,一个唯一行号(用于无主键时),一个记录创建的版本号,一个记录回滚的版本号。
- 6字节的DB_ROW_ID字段:包含一个随着新行插入而单调递增的行ID,当由innodb自动产生聚集索引时,聚集索引会包括这个行ID的值,否则这个行ID不会出现在任何索引中。
- 6字节的事务ID(DB_TRX_ID)字段:用来标识最近一次对本行记录做修改(insert|update)的事务的标识符,即最后一次修改(insert|update)本行记录的事务id。至于delete操作,在innodb看来也不过是一次update操作,更新行中的一个特殊位将行表示为deleted,并非真正删除。
- 7字节的回滚指针(DB_ROLL_PTR)字段:指写入回滚段(rollback segment)的 undo log record (撤销日志记录记录)。如果一行记录被更新, 则 undo log record 包含 ‘重建该行记录被更新之前内容’ 所必须的信息。
在多版本并发控制中,为了保证数据操作在多线程过程中,保证事务隔离的机制,降低锁竞争的压力,保证较高的并发量。在每开启一个事务时,会生成一个事务的版本号,被操作的数据会生成一条新的数据行(临时),但是在提交前对其他事务是不可见的,对于数据的更新(包括增删改)操作成功,会将这个版本号更新到数据的行中,事务提交成功,将新的版本号更新到此数据行中,这样保证了每个事务操作的数据,都是互不影响的,也不存在锁的问题。
- 插入数据
- InnoDB为这个新行记录当前的事务版本号。
- 删除数据
- InnoDB将当前的系统版本号设置为这一行的删除ID。
- 更新数据
- InnoDB会写一个这行数据的新拷贝,这个拷贝的版本为当前的系统版本号。它同时也会将这个版本号写到旧行的删除版本里。
- 查询数据
- 当隔离级别是REPEATABLE READ时select操作,InnoDB必须每行数据来保证它符合两个条件:
- 1)InnoDB必须找到一个行的版本,它至少要和事务的版本一样老(也即它的版本号不大于事务的版本号)。这保证了不管是事务开始之前,或者事务创建时,或者修改了这行数据的时候,这行数据是存在的。
- 2)这行数据的删除版本必须是未定义的或者比事务版本要大。这可以保证在事务开始之前这行数据没有被删除。
- 符合这两个条件的行可能会被当作查询结果而返回。
- 当隔离级别是REPEATABLE READ时select操作,InnoDB必须每行数据来保证它符合两个条件:
应用
MySQL的默认隔离级别是Read Repeatable,就是可重复读。是通过MVCC机制来实现的
当我们使用innodb存储引擎,会在每行数据的最后加两个隐藏列,一个保存行的创建时间,一个保存行的删除时间,但是这儿存放的不是时间,而是事务id,事务id是mysql自己维护的自增的,全局唯一。
事务id,在mysql内部是全局唯一递增的
- 事务id=121的事务,查询id=1的这一行的时候,一定会找到创建事务id <= 当前事务id的那一行select * from table where id=1,就可以查到上面那一行
- 事务id=122的事务,将id=1的这一行给删除了,此时就会将id=1的行的删除事务id设置成122
- 事务id=121的事务,再次查询id=1的那一行,能查到吗?能查到,要求创建事务id <= 当前事务id,当前事务id < 删除事务id
- 事务id=121的事务,查询id=2的那一行,查到name=李四
- 事务id=122的事务,将id=2的那一行的name修改成name=小李四事务id=121的事务,查询id=2的那一行,答案是:李四,创建事务id <= 当前事务id,当前事务id < 删除事务id
在一个事务内查询的时候,mysql只会查询创建时间的事务id小于等于当前事务id的行,这样可以确保这个行是在当前事务中创建,或者是之前创建的;
同时一个行的删除时间的事务id要么没有定义(就是没删除),要么是必当前事务id大(在事务开启之后才被删除);满足这两个条件的数据都会被查出来。
那么如果某个事务执行期间,别的事务更新了一条数据呢?这个很关键的一个实现,其实就是在innodb中,是插入了一行记录,然后将新插入的记录的创建时间设置为新的事务的id,同时将这条记录之前的那个版本的删除时间设置为新的事务的id。
总结
这种额外的记录所带来的结果就是对于大多数查询来说根本就不需要获得一个锁。他们只是简单地以最快的速度来读取数据,确保只选择符合条件的行。这个方案的缺点在于存储引擎必须为每一行存储更多的数据,做更多的检查工作,处理更多的善后操作。
MVCC只工作在REPEATABLE READ和READ COMMITED隔离级别下。READ UNCOMMITED不是MVCC兼容的,因为查询不能找到适合他们事务版本的行版本;它们每次都只能读到最新的版本。SERIABLABLE也不与MVCC兼容,因为读操作会锁定他们返回的每一行数据。

若有收获,就点个赞吧
0 人点赞
