在视频中帧一共由三种类型的帧,我们看到的视频并不是一张张的图片组成的,为了减小视频的体积,视频是由一些关键帧和非关键帧组成。关键帧包含了一副完整的图像,而非关键帧只是关键帧的变化的部分。
调试工具
学习视频最好的就是使用分析工具进行查看。
- 安装 ffmpeg,可以使用
brew install ffmpeg也可以下载命令行 - h264的分析工具 h264bitstream,也可使用
brew install h264bitstream - MediaInfo 的地址,mac 地址链接 密码: mnto,其他平台可以在官网下载到
- 调试用视频testmov.zip
视频帧
I 帧
I 帧有很多的称呼比如(可参考帧,关键帧,帧内编码),它是一个完整的图片可以直接渲染。视频的第一帧需要是 I 帧否则无法解析出图像。所以在直播的时候拿到最近的 I帧才能出现画面。I 帧是一个图像的压缩。
P 帧
P 帧参考之前的I 帧或 P 帧(这个 P 帧也需要 I 帧才能解出,更适合的是已经解码的 P 帧),通过之前已经编码的冗余信息来压缩传输的数据量的编码图像,也叫前向预测帧。解码时通过计算与前一帧的引用和插值就能重建该帧。
B 帧
双向预测帧,根据前后的已经编码的图像可以进一步减少时间冗余信息。
如下图是 I帧,B 帧和 P 帧的关系图。
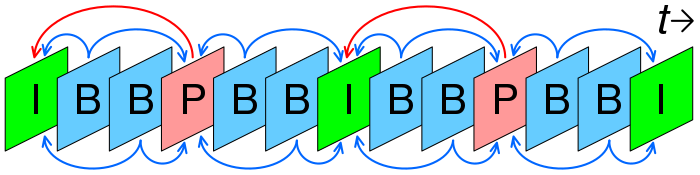
问题:看起来增加 B 帧和 P 帧可以减少视频体积,那我们在视频和直播中增加 B 帧和 P 帧是否可以换来更好的用户体验呢?
答:并非如此。增加 B 帧和 P 帧确实可以增加视频的质量,但是用户直播时需要从第一个 I 帧开始播,如果过多的 P 帧和 B 帧用户会出现长时间的黑屏等待。如果是视频用户做 seek (滑动进度)将需要很长时间。另一方面如果出现一个 I 帧的质量比较差,紧接着的 B 帧和 P 帧质量都会比较差,只能等下一个 I 帧的时候恢复。系统稳定性不好。最后 B 帧和 P 帧过多势必会降低复杂度,导致编码效率降低。
帧内预测和帧间预测可以参考这一小节。
GOP(Group of picture)
一个 GOP 画面组由 I 帧+B 帧+P 帧组成。
使用下面命令查看以下视频中的帧的分布
$ ffprobe -show_frames test.mov | grep pict_type
可以看到输出中1个 I 帧,29个 P 帧。
pict_type=Ipict_type=Ppict_type=Ppict_type=Ppict_type=Ppict_type=Ppict_type=Ppict_type=Ppict_type=Ppict_type=Ppict_type=Ppict_type=Ppict_type=P...
用 MediaInfo 查看。
使用 MediaInfo 的正确姿势,在 Videw 中选 Text,在Debug 中选 Detail。重新将视频拖入 MediaInfo 。
在 MediaInfo 中通过 slice_type 可以查看到是 I 帧还是 P 帧。
slice_layer_without_partitioning (IDR) - 0 - Frame 0 - slice_type I - frame_num 0 - pic_order_cnt_lsb 0 (65576 bytes)000056 Header (5 bytes)000056 size: 65572 (0x00010024)00005A nal_ref_idc: 1 (0x1) - (2 bits)00005A nal_unit_type: 5 (0x05) - (5 bits)00005B slice_header (4 bytes)00005B first_mb_in_slice: 0 (0x0)00005B slice_type: 2 (0x2) - I00005B pic_parameter_set_id: 0 (0x0)00005B frame_num: 0 (0x0)00005C idr_pic_id: 0 (0x0)00005C pic_order_cnt_lsb: 0 (0x000)00005D no_output_of_prior_pics_flag: No00005D long_term_reference_flag: No00005D slice_qp_delta: -1 (0xFFFFFFFF)00005E disable_deblocking_filter_idc: 0 (0x0)00005E slice_alpha_c0_offset_div2: -1 (0xFFFFFFFF)00005E slice_beta_offset_div2: -1 (0xFFFFFFFF)00005F slice_data (65571 bytes)00005F (ToDo): (Data)01007E 1 (75 bytes)01007E slice_layer_without_partitioning (non-IDR) - 2 - Frame 1 - slice_type P - frame_num 1 - pic_order_cnt_lsb 2 (75 bytes)01007E Header (5 bytes)01007E size: 71 (0x00000047)010082 nal_ref_idc: 1 (0x1) - (2 bits)010082 nal_unit_type: 1 (0x01) - (5 bits)010083 slice_header (3 bytes)010083 first_mb_in_slice: 0 (0x0)010083 slice_type: 0 (0x0) - P010083 pic_parameter_set_id: 0 (0x0)010083 frame_num: 1 (0x1)010083 pic_order_cnt_lsb: 2 (0x002)010085 num_ref_idx_active_override_flag: No010085 ref_pic_list_modification_flag_l0: No010085 adaptive_ref_pic_marking_mode_flag: No010085 cabac_init_idc: 1 (0x1)010086 slice_qp_delta: 0 (0x0)010086 disable_deblocking_filter_idc: 0 (0x0)010086 slice_alpha_c0_offset_div2: -1 (0xFFFFFFFF)010086 slice_beta_offset_div2: -1 (0xFFFFFFFF)010086 slice_data (50 bytes)010086 (ToDo): (Data)0100C9 1 (72 bytes)
视频压缩
简单来说视频在经过采集时减少采样量,通过压缩帧内预测和帧间预测减小视频单帧的大小,在单帧的基础采用熵变码的方式进一步减少单帧的大小。视频才有了这么高的压缩比。
条带和宏块
对视频中的一个图像还对其进行了分割。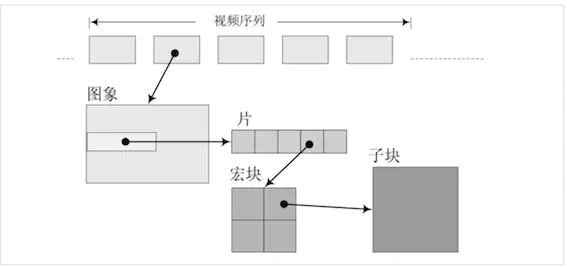
引用图
每个图像分成多个片(slice),每个片由多个宏(macro)块组成,一个宏块由多个子块组成。一个子块是由多个像素组成比如4x4,16x16,64x64。切片也有 I 切片,B 切片,I 宏块,B 宏块。
看一下分区效果如下,可以看到图片是由大小不一的图片组成。
- 问题8个 16x16 的宏块,子采样格式为4:2:0,那么这个宏块里有多少个 Y 采样,多少个 Cb Cr 采样?
答:有16x16个 Y 采样,8x8个 Cb Cr 采样。
视频的采集-颜色模型和采样
本文很多内容参考了这篇 Github 的文章。

若有收获,就点个赞吧
0 人点赞
