一、Hive概念
(1)概念
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
(2)自定义函数
Hive设计的初衷是:对于大量的数据,使得数据汇总,查询和分析更加简单。它提供了SQL,允许用户更加简单地进行查询,汇总和数据分析。同时,Hive的SQL给予了用户多种方式来集成自己的功能,然后做定制化的查询,例如用户自定义函数(User Defined Functions,UDF、UDAF、UDTF).
- UDF:操作单个数据行,产生单个数据行;
- UDAF:操作多个数据行,产生一个数据行。
- UDTF:操作一个数据行,产生多个数据行一个表作为输出。
(3)适用场景
Hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。
因此,Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
(4)设计特征
Hive 在加载数据过程中不会对数据进行任何的修改,只是将数据移动到HDFS 中Hive 设定的目录下,因此,Hive 不支持对数据的改写和添加,所有的数据都是在加载的时候确定的。Hive 的设计特点如下。
- 支持创建索引,优化数据查询。
- 不同的存储类型,例如,纯文本文件、HBase 中的文件。
- 将元数据保存在关系数据库中,大大减少了在查询过程中执行语义检查的时间。
- 可以直接使用存储在Hadoop 文件系统中的数据。
- 内置大量用户函数UDF 来操作时间、字符串和其他的数据挖掘工具,支持用户扩展UDF 函数来完成内置函数无法实现的操作。
- 类SQL 的查询方式,将SQL 查询转换为MapReduce 的job 在Hadoop集群上执行。
二、Hive架构
该组件图包含不同的单元。下表详细的描述每个单元:
| 单元名称 | 操作 |
|---|---|
| 用户接口/界面 | Hive是一个数据仓库基础工具软件,可以创建用户和HDFS之间互动。用户界面,Hive支持是Hive的Web UI,Hive命令行,HiveHD洞察(在Windows服务器)。 |
| 元存储 | Hive选择各自的数据库服务器,用以储存表,数据库,列模式或元数据表,它们的数据类型和HDFS映射。 |
| HiveQL处理引擎 | HiveQL类似于SQL的查询上Metastore模式信息。这是传统的方式进行MapReduce程序的替代品之一。相反,使用Java编写的MapReduce程序,可以编写为MapReduce工作,并处理它的查询。 |
| 执行引擎 | HiveQL处理引擎和MapReduce的结合部分是由Hive执行引擎。执行引擎处理查询并产生结果和MapReduce的结果一样。它采用MapReduce方法。 |
| HDFS 或 HBASE | Hadoop的分布式文件系统或者HBASE数据存储技术是用于将数据存储到文件系统。 |
三、Hive工作原理
下图描述了Hive 和Hadoop之间的工作流程。
下表定义Hive和Hadoop框架的交互方式:
| 步骤 | 操作 |
|---|---|
| 1 | Hive接口,如命令行或Web UI发送查询驱动程序(任何数据库驱动程序,如JDBC,ODBC等)来执行。 |
| 2 | 在驱动程序帮助下查询编译器,分析查询检查语法和查询计划或查询的要求。 |
| 3 | 编译器发送元数据请求到Metastore(任何数据库)。 |
| 4 | Metastore发送元数据,以编译器的响应。 |
| 5 | 编译器检查要求,并重新发送计划给驱动程序。到此为止,查询解析和编译完成。 |
| 6 | 驱动程序发送的执行计划到执行引擎。 |
| 7 | 在内部,执行作业的过程是一个MapReduce工作。执行引擎发送作业给JobTracker,在名称节点并把它分配作业到TaskTracker,这是在数据节点。在这里,查询执行MapReduce工作。 |
| 7.1 | 与此同时,在执行时,执行引擎可以通过Metastore执行元数据操作。 |
| 8 | 执行引擎接收来自数据节点的结果。 |
| 9 | 执行引擎发送这些结果值给驱动程序。 |
| 10 | 驱动程序将结果发送给Hive接口。 |
四、Hive安装
1、准备阶段
hadoop、mysql、mysql驱动包(mysql-connector-java-5.1.27.jar),
hive的安装包(apache-hive-2.3.5-bin.tar.gz):下载地址http://mirror.bit.edu.cn/apache/hive/
apache-hive-2.3.5-bin.tar.gz:安装包
apache-hive-2.3.5-src.tar.gz:可视化web包
2、创建目录并解压
mkdir -p /usr/local/hive-2.3.5
tar -zxvf apache-hive-2.3.5-bin.tar.gz -C /usr/local/hive-2.3.5
ln -s /usr/local/hive-2.3.5 /usr/local/hive
3、配置环境变量
vim /etc/profileexport HIVE_HOME=/usr/local/hiveexport PATH=$PATH:$HIVE_HOME/binsource /etc/profile #使环境变量生效
4、设置配置文件
cd /usr/local/hive/conf
cp hive-default.xml.template hive-site.xml #原conf下是没有hive-site.xml文件
vim hive-site.xml #主要是mysql的连接信息
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>(mysql地址localhost)
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>(mysql的驱动)
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>(用户名)
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>(密码)
<value>123456</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
</configuration>
5、将mysql驱动放在lib下
cp mysql-connector-java-5.1.27.jar /usr/local/hive/lib
6、初始化数据库
schematool -dbType mysql -initSchema
7、进入hive客户端
hive #输出hive就可以直接进入hive客户端进行操作
五、hive可视化图形页面(hwi)
1、下载安装包:http://mirror.bit.edu.cn/apache/hive/hive-2.3.5/
apache-hive-2.3.5-src.tar.gz
2、解压并打成war包
tar -zxvf apache-hive-2.3.5-src.tar.gz -C /usr/local/hive
cd /usr/local/hive/hwi #hwi文件中的web就是我们需要的文件
jar cvfM0 hive-hwi-2.3.5.war -C web/ . #-C指定要打包的目录
3、将包放在lib下:
cp hive-hwi-2.3.5.war /usr/local/hive/lib
cp tools.jar /usr/local/hive/lib #tools.jar为jdk的包,否则会出500错误
4、修改配置文件hive-site.xml
<property>
<name>hive.hwi.listen.host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>hive.hwi.listen.port</name>
<value>9999</value>
</property>
<property>
<name>hive.hwi.war.file</name>
<value>/lib/hive-hwi-2.3.5.war</value>
</property>
5、启动服务:
hive —service hwi
6、访问web ui:
http://ip:9999/hwi/
六、Hive基本操作
1、Hive的数据类型
| 基本数据类型 | ||
|---|---|---|
| 类型 | 描述 | 示例 |
| TINYINT | 1个字节(8位)有符号整数 | 1 |
| SMALLINT | 2字节(16位)有符号整数 | 1 |
| INT | 4字节(32位)有符号整数 | 1 |
| BIGINT | 8字节(64位)有符号整数 | 1 |
| FLOAT | 4字节(32位)单精度浮点数 | 1.0 |
| DOUBLE | 8字节(64位)双精度浮点数 | 1.0 |
| BOOLEAN | true/false | true |
| STRING | 字符串 | ‘xia’,”xia” |
| 复杂数据类型 | ||
|---|---|---|
| 类型 | 描述 | 示例 |
| ARRAY | 一组有序字段。字段的类型必须相同 | Array(1,2) |
| MAP | 一组无序的键/值对。键的类型必须是原子的,值可以是任何类型,同一个映射的键的类型必须相同,值得类型也必须相同 | Map(‘a’,1,’b’,2) |
| STRUCT | 一组命名的字段。字段类型可以不同 | Struct(‘a’,1,1,0) |
2、内部表与外部表
(1)创建外部表(关键字external):
create external table exter_table(
id int,
name string,
age int,
tel string)
location ‘/home/wyp/external’;
这里需要指定外部表存放数据的路径(当然,你也可以不指定外部表的存放路径,这样Hive将在HDFS上的/user/hive/warehouse/文件夹下以外部表的表名创建一个文件夹,并将属于这个表的数据存放在这里)
(2)Hive中内部表与外部表的区别:
1、加载数据
1)hive内部表,上传数据时:
如果数据是hdfs的文件,那么会将hdfs的文件移动到hive所在的hdfs路径下
如果数据是linux的文件,那么是拷贝到hive所在的hdfs路径下
2) hive外部表,上传数据时:
数据是hdfs的文件,那么仅仅是针对hdfs的文件创建一个快捷链接而已,
如果数据是linux的文件,那么是拷贝到hive外表所在的hdfs路径下
3)加载数据的时候,普通表不会检查数据的格式(如果格式不正确,就会存储为null),而外部表会检查源数据的格式(如果格式不正确,加载失败)。
那么,应该如何选择使用哪种表呢?在大多数情况没有太多的区别,因此选择只是个人喜好的问题。但是作为一个经验,如果所有处理都需要由Hive完成,那么你应该创建内部表,否则使用外部表。原文链接:http://blog.csdn.net/sunlei1980/article/details/46572679
2、在删除表的时候,Hive将会把属于内部表的元数据和数据全部删掉;而删除外部表的时候,Hive仅仅删除外部表的元数据,数据是不会删除的!
3、排序order by 和 sort by
1)order by为全局排序,只有一个reduce的输出
select from baidu_click order by click desc;
2)sort by局部排序,常和distribute by搭配使用:被distribute by设定的字段为KEY,数据会被HASH分发到不同的reducer机器上,然后sort by会对同一个reducer机器上的每组数据进行局部排序。
select from baidu_click distribute by product_line sort by click desc;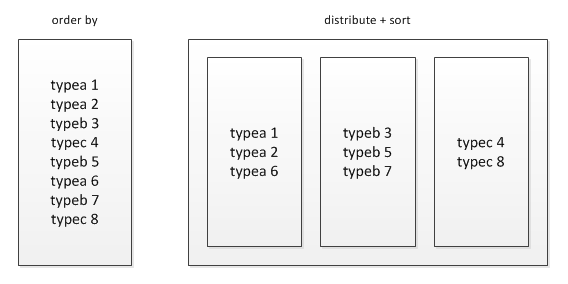
3)文章地址:http://www.crazyant.net/1456.html
4、hive计算的三种引擎(可以在客户端直接设置)
—使用mapreduce计算
set hive.execution.engine=mr;
—使用spark计算
set hive.execution.engine=spark;
—使用tez计算引擎
set hive.execution.engine=tez;
(Tez+Hive)仍采用MapReduce计算框架,但对DAG(有向无环图)的作业依赖关系进行了裁剪,并将多个小作业合并成一个大作业,这样,不仅计算量减少,而且写HDFS次数也会大大减少。
5、hive非交互式模式运行的命令参数:
- hive -f test.sql # -f 可以运行脚本文件
- hive -e “select * from testTable” # -e 运行简短的hql命令
- hive -S -e “select * from testTable” # -S 强制不显示执行过程,只输出结果
【注意】
(1)、Hive的行级更新和删除
Hive从0.14版本开始支持事务和行级更新,但缺省是不支持的,需要一些附加的配置。要想支持行级insert、update、delete,需要配置Hive支持事务。配置hive-site.xml文件
如果一个表要实现update和delete功能,该表就必须支持ACID,而支持ACID,就必须满足以下条件:
1、表的存储格式必须是ORC(STORED AS ORC);
2、表必须进行分桶(CLUSTERED BY (col_name, col_name, …) INTO num_buckets BUCKETS);
3、Table property中参数transactional必须设定为True(tblproperties(‘transactional’=’true’));
创建满足条件表的样例:
create table if not exists tablename (
id bigint,
sex tinyint COMMENT '性别',
name String COMMENT '姓名'
) COMMENT '用户表'
partitioned by (year string)
clustered by (id) into 2 buckets
row format delimited fields terminated by '\t'
stored as orc TBLPROPERTIES('transactional'='true');
4、以下配置项必须被设定(hive-site.xml):
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.enforce.bucketing</name>
<value>true</value>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property>
<property>
<name>hive.compactor.worker.threads</name>
<value>1</value>
</property>
<property>
<name>hive.in.test</name>
<value>true</value>
</property>
修改表样例:
-- 修改数据
INSERT INTO TABLE t2 PARTITION (country, state) VALUES (5,'刘','DD','DD');
UPDATE t2 SET name='张' WHERE id=1;
DELETE FROM t2 WHERE name='李四';
(2)在mysql中配置hive连接的密码
**
#hive连接mysql,在mysql中的操作
给mysql设置密码:mysqladmin -u root password 'mysql'
create user 'hive' identified by 'mysql';
grant all privileges on *.* to 'hive'@'%' with grant option;
grant all privileges on *.* to 'hive'@'%' identified by 'mysql';
grant all privileges on *.* to 'hive'@'jun110' identified by 'mysql';
grant all privileges on *.* to 'hive'@'localhost' identified by 'mysql';
flush privileges;

若有收获,就点个赞吧
0 人点赞
