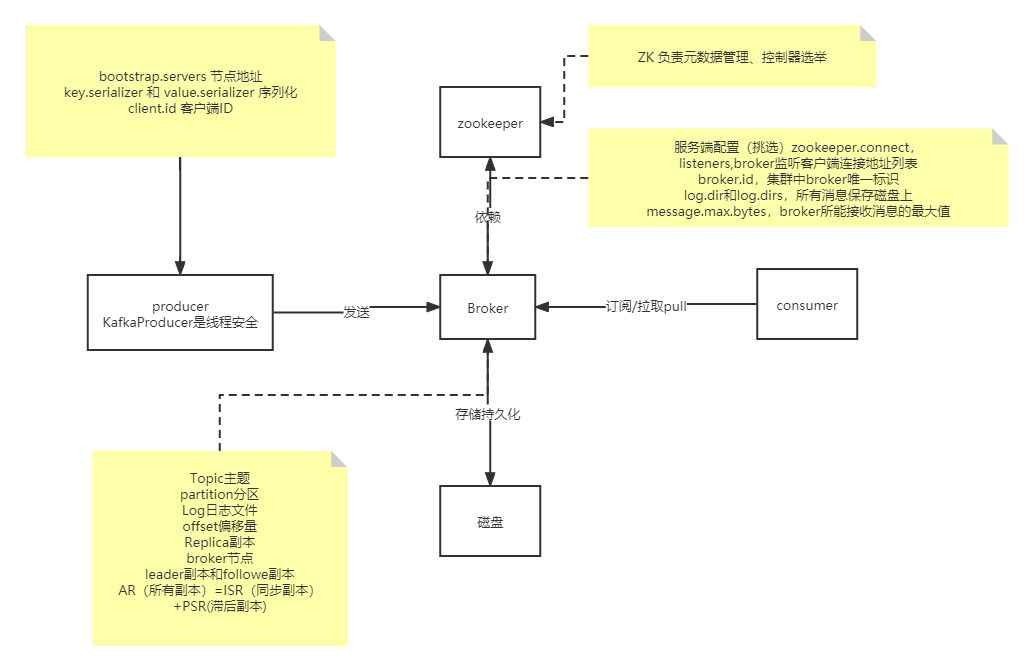
1、基本概念
2、生产者
答:发送消息主要有三种模式:发后即忘(fire-and-forget)、同步(sync)及异步(async);
①发后即忘:KafkaProducer.send();性能最高,但可靠性最差
②同步发送:KafkaProducer.send().get(),send(),得到Future对象使调用方稍后获得发送的结果,send()方法后直接链式调用了get()方法来阻塞等等Kafka响应,直到发送成功或者发生异常,Future
③发送异常:可重试异常和不可重试异常;可重试异常,比如NetworkException 表示网络异常,这个有可能是由于网络瞬时故障而导致的异常,可以通过重试解决;LeaderNotAvailableException表示分区的leader副本不可用,这个异常通常发生在leader副本下线而新的 leader 副本选举完成之前,重试之后可以重新恢复。不可重试的异常,比如RecordTooLargeException异常,暗示了所发送的消息太大,KafkaProducer对此不会进行任何重试,直接抛出异常;retries 参数可配置重试次数,超过重试次数还异常,需要在外层进行异常处理;
④异步发送:异步发送一般是在send()方法里面指定callback回调函数,kafka在响应时调用该函数来实现异步发送的确认。
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);ProducerRecord<String, String> record = new ProducerRecord<>(topic, "hello,world!");try {// 发即消失producer.send(record);// 同步发送RecordMetadata recordMetadata = producer.send(record).get();producer.send(record, new Callback() {@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {// 异步发送回调if (null != e) {e.printStackTrace();} else {// 业务代码System.out.print(recordMetadata.topic() + recordMetadata.partition() + recordMetadata.offset());}}});} catch (Exception ex) {ex.printStackTrace();} finally {// 超时关闭,释放资源,close()会阻塞之前所有发送请求后在关闭;producer.close(100L, TimeUnit.MINUTES);}
⑤序列化(必须):除了自带String字符串序列化,还包含了Double/Integer/Long/ByteArray等其他类型序列化;还支持使用JSON等通用序列化工具和自定义序列化CompanySerializer
Properties properties = new Properties();properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
⑥分区器(非必要,有默认值):消息序列化之后就需要确定它发往的分区,消息ProducerRecord中指定了partition字段,那么就不需要分区器的作用,因为partition代表的就是所要发往的分区号。ProducerRecord如果没有指定发送的partition字段,那么就需要依赖分区器,根据key这个字段来计算partition的值,分区器的作用就是为消息分配分区;默认分区器是DefaultPartitioner实现了Partitioner这个接口定义了partition()计算分区号,返回值为int类型,partition()参数包含主题,键Key,序列化后的Key,值Value,序列化后的值Value,以及集群的元数据信息;close()方法在关闭分区器的时回收资源;Partitioner还有一个父接口Configurable(),接口中方法configure()方法可以获取配置信息和初始化数据;
如果 key 不为 null,那么默认的分区器会对 key 进行哈希(采用MurmurHash2算法,具备高运算性能及低碰撞率),最终根据得到的哈希值来计算分区号,拥有相同key的消息会被写入同一个分区(任意分区)。如果key为null,那么消息将会以轮询的方式发往主题内的各个可用分区;
⑦拦截器(非必要):生产拦截器和消费拦截器,生产拦截器主要用来过滤垃圾数据,修改发送消息,对回调逻辑做数据统计类定制化的工作需求;实现生产拦截器的方法是实现ProducerInterceptor接口,接口当中包含3个方法,其中onSend()方法在消息实现序列化到计算分区之前被调用,它可以执行定制化操作,请求参数RroducerRecord包含topic/key/partition等信息,如果要修改则需要确保对其准确的判断,不易轻易修改,否则可能会影响key分区计算,broker的日志压缩等功能;在消息被应答ack之前或消息发送失败时调用生产拦截器的onAcknowledgment(),优先与Callback之前执行,方法在producer的IO线程中进行,代码逻辑越简单越好,否则会影响发送速度。close()方法主要在关闭拦截器时进行一些资源的清理工作。这三个方法如果发生异常会被捕捉并记录到日志中,不会向上传递(业务代码不会抛出异常);同样有父接口Configurable(),接口中方法configure()方法可以获取配置信息和初始化数据;通过Properties配置 interceptor.classes 参数,指定拦截器,同时支持指定多个拦截器
public class ProducerIntercetorPrefix implements ProducerInterceptor<String, String> {public static int SUCCESS_NUM = 1;@Overridepublic ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {String value = record.value() + "-test";return new ProducerRecord(record.topic(),record.partition(), record.timestamp(), record.key(), value, record.headers());}@Overridepublic void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {if (null == e) {SUCCESS_NUM++;}}@Overridepublic void close() {// 打印发送成功数量}@Overridepublic void configure(Map<String, ?> map) {System.out.println(map);}}
⑧实现原理
1.注意参数配置,消息累加器RecordAccumulator的缓存大小buffer.memory默认32MB,且可批量发送消息,减少网络传输,提高性能,调大参数,可以增加整体的吞吐量;
2.当生产空间不足时,KafkaProducer的send()方法调用会被阻塞,通过max.block.ms默认60000,阻塞60秒时候抛出异常;
3.batch.size参数,默认16KB,对特定的ByteBuffer缓存进BufferPool中,可以减少消息内存的频繁创建和释放,减少资源消耗;在新建ProducerBatch时评估这条消息的大小是否超过batch.size参数的大小,如果不超过,那么就以 batch.size 参数的大小来创建 ProducerBatch,这样在使用完这段内存区域之后,可以通过BufferPool 的管理来进行复用;如果超过,那么就以评估的大小来创建ProducerBatch,这段内存区域不会被复用。
4.Sender 从 RecordAccumulator 中获取缓存的消息之后,会进一步将原本<分区,Deque<ProducerBatch>>的保存形式转变成<Node,List< ProducerBatch>的形式,其中Node表示Kafka集群的broker节点,同时会进一步封装成
5.InFlightRequests保存对象的具体信息是Map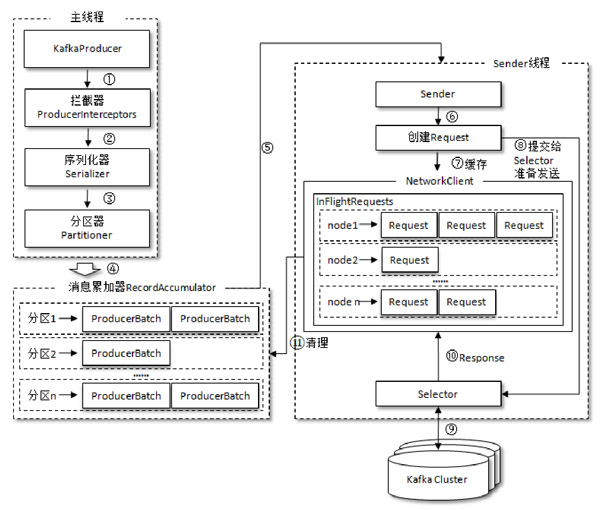
6.元数据,KafkaProducer要将此消息追加到指定主题的某个分区所对应的leader副本之前,首先需要知道主题的分区数量,然后经过计算得出(或者直接指定)目标分区,之后KafkaProducer需要知道目标分区的leader副本所在的broker节点的地址、端口等信息才能建立连接,最终才能将消息发送到 Kafka,在这一过程中所需要的信息都属于元数据信息;
⑨重要的生产者参数:
1.acks 指定分区中必须多个副本确认收到这条消息才算写入成功,默认acks=1,保证消息传输的可靠性;acks=0生产者发送消息之后不需要等待任何服务端的响应,无法保证可靠性,但是可以达到最大吞吐量;acks=-1或acks=all生产者在消息发送之后,需要等待ISR中所有的副本都成功写入消息之后才能够收到来自服务端的成功响应,理论上达到了最大可靠性,但是不一定消息就一定可靠,因为ISR可能只有leader副本,这样就退化成acks=1的情况,要达到最大可靠性需要配合min.insync.replicas等参数;
2.max.request.size 参数用来限制生产者客户端能发送的消息最大值,默认1MB,涉及其他参数联动,比如服务端message.max.bytes不轻易修改;
3.retries 生产者重试次数,默认0,注意不是所有异常都可以重试,如当消息太大超过max.reuqest.szie值时,无法进行;retry.backoff.ms默认值为100,它用来设定两次重试之前的时间间隔,避免无效的频繁重试;建议max.in.flight.requests.per.connection配置为1保证消息顺序;
4.compression.type 压缩方式,默认node,其他取值gzip/snappy/lz4,对消息进行压缩减少网络IO;
5.connections.max.idle.ms 用来指定多久之后关闭限制的连接,默认9分钟;
6.linger.ms 用来指定生产者发送ProducerBatch之前等待更多消息RroducerRecord加入ProducerBatch的时间,默认值0,生产者客户端会在ProducerBatch被填满或等待时间超过linger.ms值时发送出去;
7.receive.buffer.bytes 用来设置Socket接收消息缓冲区的大小默认32KB,如果设置-1则使用操作系统的默认值,当生产者和服务端处于不同机房可以调大这个参数;
8.send.buffer.bytes 用来设置Socket发送消息缓冲区的大小默认128KB,如果设置-1则使用操作系统的默认值;
9.request.timeout.ms 用来配置Producer等待请求响应的最长时间,默认值为30000(ms),这个参数需要比broker端eplica.lag.time.max.ms的值大,避免引起重试造成的消息重复概率;
3、消费者和消费组
答:消费者Consumer负责订阅kafka中的主题Topic,并且从订阅的主题上拉取消息;在kafka中消费理念中有一层消费组Consumer Group的概念,每个消费者都有一个对应的消费组,当消息发送到主题后,只会被投递给订阅它的每个消费组中一个消息者;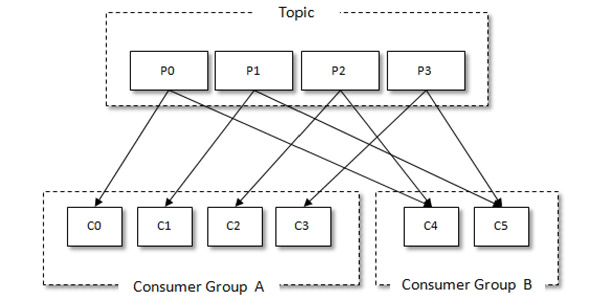
默认情况下是均匀分区分配策略,可以通过修改消费者客户端参数partition.assignment.strategy 来设置消费者和订阅主题之间分区分配策略;注意消费者数量不要大于分区数量,否则会有消费者过多资源浪费的情况出现;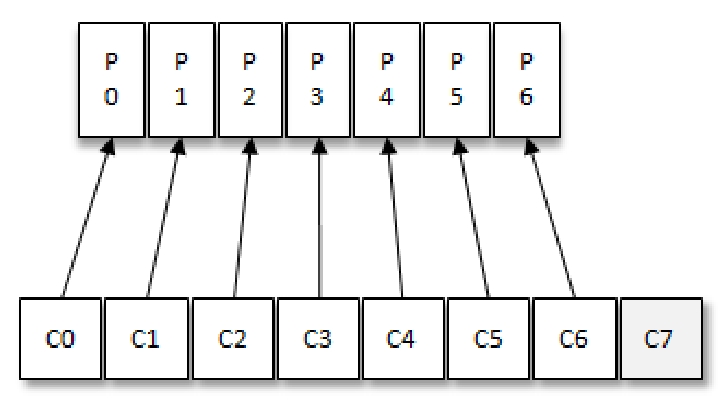
消息投递模式一般来说MQ都有P2P点对点和Pub/Sub发布订阅模式,在kafka中同时支持两种消息投递模式,当所有消费者隶属于同一个消费组的话,那么所有消息都会被均匀投递给每一个消费者,即每条消息只会被一个消息者处理,这就相当于与点对点模式的应用。如果所有的消费者都隶属于不同消费组,那么所有消息都会广播给所有的消费者,这样就是发布订阅模式;消费者在消费消息需要通过group.id指定消费组名称,默认是空字符串;
①实例
public class KafkaConsumerAnalysis {public static final String brokerList = "localhost:9092";public static final String topic = "topic-demo";public static final String groupId = "group.demo";public static final AtomicBoolean isRuning = new AtomicBoolean(true);public static Properties initConfig(){Properties properties = new Properties();properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.put("bootstrap.servers", brokerList);properties.put("group.id",groupId);properties.put("client.id","consumer.client.id.demo");return properties;}public static void main(String[] args) {Properties properties = initConfig();KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(properties);consumer.subscribe(Arrays.asList(topic));try {while (isRuning.get()){ConsumerRecords<String,String> consumerRecords = consumer.poll(Duration.ofMillis(1000));consumerRecords.forEach(item->{System.out.println(item.topic() + item.partition());});}}catch (Exception e){e.printStackTrace();}finally {consumer.close();}}}
②必要参数
1.bootstrap.servers 指定连接kafka集群所需要的broker地址清单,可以设置一个也可以设置多个,设置多个的话,当其中一个宕机还可以继续连接kafka集群;
2.group.id 消费者隶属的消费组名称,默认为””,如果设置为空,会出现异常;
3.key.deserializer 和 value.deserializer 消费者从broker端获取的消息格式都是字节数组,需要反序列化成原有的对象格式;
4.client.id 设定kafkaCosume对应的客户端id,默认值也为””,如果客户端不设置kafkaConsumer会自动生产一个非空字符串,内容形式为consumer-1;
③订阅主题和分区
一个消费者可以订阅一个或者多个主题,subscribe()方法既支持集合形式订阅多个主题,也支持以正则表达式的形式订阅特定模式的主题,当消费者前后订阅了不同的主题,那么消费者以最后一次为准,当消费通过正则表达式的方式订阅,在之后过程中有人创建了新的主题,且主题符合正则表达式,那么消费者也会添加这个主题的消息进行消费;同时KafkaConsumer.subscribe()方法订阅主题,还可以直接订阅某些主题的特定分区;
取消订阅通过KafkaConsumer中的unsubscribe()方法取消主题的订阅,这个方法可以取消通过集合、正则、分区、assign实现的订阅;也可以通过subscribe()设置空值来覆盖之前的订阅,达到取消订阅功能;
通过subscribe()方法进行订阅的消费者具有自动再均衡功能,在多个消费者的情况下,根据分区分配策略来分配各个消费者与分区的关系,当消费者减少也会对应分区分配关系进行自动调整;而通过assign()方法订阅分区时,是不具备负载均衡及故障自动转移;
④反序列化
kafkaConsumer提供StringDeserializer、ByteBufferDeserializer等反序列化器对应kafkaProducer的序列化器;
⑤消息消费
kafka消费是基于拉模式,不断轮询poll拉取消息进行消费;poll()方法还有一个超时时间timeout(Java8 Duration),用来空值poll()方法阻塞时间,在消费者的缓冲区没有可用数据时,会发生阻塞。消费者每条消息类型为ConsumerRecord,主题、分区、偏移量、时间戳、timestampType类型CreateTime和LogAppendTime,分别表示时间戳和消息追加到日志的时间戳,headers表示消息头部信息,key/value表示消息键和消息的值,在业务使用读取value的值;serializedKeySize和serializedValueSize表示KV序列化后大小;poll()方法的返回值类型是 ConsumerRecords,一次拉取操作所获取的消息集;
⑥位移提交
对于消息在分区中的位置,称为偏移量;对于消费者消费到的位置称为位移;每次poll消息需要记录上次消费时的消费位移,并且需要做到持久化,而不是仅仅保存在内存中;2.0之前旧消费者客户端时,消费位移是存储在ZK中的,而新客户端中,消费位移存储在kafka内部主题_consumer_offsets中。把消费位移存储起来的持久化过程称为“提交”,消费者在消费完消息之后需要执行消费位移(x+1)的提交,即下次消费拉取消息的位置;position=committedoffset=lastConsumedOffset+1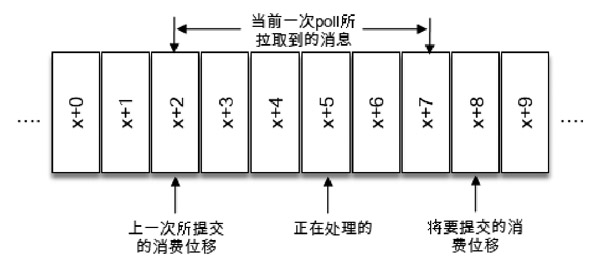
kafka中默认消费位移的提交方式是自动提交,参数enable.auto.commit=true,且自动提交是通过定期提交(默认5秒),通过参数auto.commit.interval.ms可以进行修改;自动提交的动作是poll()方法的逻辑里完成的,在每次真正向服务端发起拉取请求之前会检查是否可以进行位移提交;自动位移提交的方式在正常情况下不会发送消息丢失和消息重复消费的现象,但是在实际业务开发无可避免出现异常等情况,而且自动位移提交无法做到精确位移管理;
开启手动提交功能,enable.auto.commit=false,手动提交分为同步提交和异步提交,对应KafkaConsumer中的comitSync和commitAsync两种类型的方法;批量拉取到消息后,进行业务逐条消息处理,后做整个消息集的同步批量提交,在业务处理完毕到提交之间发送宕机会造成消息重复消费;commitSync()方法会根据poll()方法拉取的最新位移来进行提交,只要没有发生不可恢复的错误,它就会阻塞消费者线程直到位移提交完成。对于采用无参的commitSync()方法而言,它提交消费位移的频率和拉取批次消息、处理批次消息的频率是一样的,另外一个更精确的提交是使用含参offsets参数的commitSync(),用来提交指定分区的位移等。commitAsync()在执行的时候消费者线程不会阻塞,可能在提交消费位移的结果还未返回之前旧开始了新一轮的拉取操作。commitAsync()有三个方法,无参方法、含offsets参数方法、含offsets参数和回调onComplete()两个参数的方法;
⑦控制和关闭消费
KafkaConsumer 提供了对消费速度进行控制的方法,在有些应用场景下我们可能需要暂停某些分区的消费而先消费其他分区,当达到一定条件时再恢复这些分区的消费。KafkaConsumer中使用pause()和resume()方法来分别实现暂停某些分区在拉取操作时返回数据给客户端和恢复某些分区向客户端返回数据的操作;
⑧指定位移消费
当一个新的消费组建立的时候,它根本没有可以查找的消费位移,或者消费组内的一个消费者订阅了一个新的主题,它也没有可以查找的消费位移,当_consumer_offsets主题中有关这个消费组的位移信息过期而被删除后,它也没有可以查找的消费位移;
在Kafaka中每当消费者查找不到所记录的消费位移时,就会根据消费者客户端参数auto.offset.rest的配置来决定从何处开始进行消费,这个参数的默认值是lasest,表示从分区末尾开始消费消息,如果将auto.offsets.reset参数配置为earliest,那么消费者从起始处,也就是0开始消费;auto.offset.reset参数还有一个可配置的值none,配置为此值就意味着出现查到不到消息的消息位移的时候,既不从最新的消息位置处开始消费,也不从最早的消息位置处开始消费,此时会报出NoOffsetForPartitionException异常,如果能够找到消费位移,那么配置为none不会出现任何异常,如果配置都不是latest/earliest/none则会报出ConfigException异常;
对于需要更细粒度从特定的位移拉取消息,KafkaConsumer中的seek()方法正好提供了这个功能,让我们得以追前消费或回溯消费;seek(TopicPartiition partition,long offset),方法参数partition表示指定那个分区,offsets参数指定从分区哪里开始消费;seek方法只能重置消费者分配到的分区的消费位置,而分区的分配是在poll方法的调用过程中实现的,而分区的分配是在poll方法的调用过程中实现的,也就是说,在执行seek方法之前需要执行一次poll方法等到分配到分区之后才可以重置消费位置;
当poll参数设置为0,此方法会立刻返回,那么poll方法内部进行分区分配的逻辑就会来不及实施,也就是说,消费者此时并未分配到任何分区,assignment方法获取到的分区信息为空就无法重置分区消费位移,所有需要注意判断poll之后分区信息是否为空!endOffsets方法用来获取指定分区的末尾的消息位置,是将要写入最新消息的位置,方法参数中partitions参数表示分区集合,而timeout参数用来设置等待获取的超时时间,如果没有指定timeout参数的值,那么endOffsets方法的等待时间由客户端参数request.timeout.ms的设置,默认3000;beginningOffsets方法,分区的起始位置起初是0,但并不表示每时每刻都为0,因为日志清理的动作会清理旧的数据,所有分区的起始位置会自然而然地增加;还有其他seekToBeginning、seekToEnd、offesetForTimes等方法来指定起始消费位移;
⑨再均衡
再均衡是指分区的所属权从一个消费者转移到另外一个消费者,它为消费者具备高可用和伸缩性提供了保障,使我们可以既方便又安全地删除消费组内的消费者或往消费组内添加消费者。不过在再均衡发生期间,消费组内的消费者无法读取消息的。也就是说,在再均衡发生期间的一小段时间内,消费者会变得不可用,另外当一个分区被重新分配给另外一个消费者时,消费者当前的状态也会丢失。比如消费者消费完某个分区中的一部分消息时还没有来得及提交消费位移就发生了再均衡操作,之后这个分区又被分配给了消费组的另一个消费者,原来被消费完的那部分消息又被重新消费一遍,也就发生了重复消费,一般情况下,应尽量避免不必要的再均衡的发生;再均衡监听器ConsumerRebalanceListener用来设定发生再均衡动作前后的一些准备或收尾的动作,其中包含两个方法,onPartitionRevoked(Collection
消费者拦截器
消费者拦截器对应生产者拦截器,消费者拦截器主要在消费到消息或在提交消费位移时进行一些定制化的操作;拦截器ConsumerIntercepter中包含3个方法:
A:onConsume(ConsumerRecords);在poll方法返回之前调用,来对消息进行相应的定制化操作,比如修改返回的消息内容、按照某种规则过滤消息,减少返回消息个数,如果方法中抛出异常,会被捕捉并记录到日志中,但是异常不会再向上传递;
B:onCommit(Map
C:close();释放资源
TTL,Time to Live 过期时间,在拦截器中可以获取消息的timestamep字段,可以通过该字段判断消息是否过期,没达到消息的消费时间标准则选择过滤;在实现自定义拦截器之后,需要再消费配置中指定这个拦截器,interceptor.classes参数实现;同时需要注意,在多个拦截器情况下,存在拦截链顺序消息消费;
多线程实现
KafkaProducer是线程安全的,而KafkaConsumer是非线程安全的,KafkaConsumer中定义了一个acquire()方法,用来检测当前是否只有一个线程在操作,若有其他线程正在操作则会抛出ConcurentModifcationException异常,KafkaConsumer中的每个公用方法都会在方法执行所哟啊执行的动作之前都会调用这个acquire方法,只有wakeup方法是个例外;
acquire()方法和我们通常所说的锁synchronized、Lock等不同,它不会造成阻塞等待,我们可以将其看作一个轻量级锁,它仅通过线程操作计算标记的方法检测是否发生了并发操作,以此保证只有一个线程在操作;
acquire()与方法release()方法成对出现,表示相应的加锁和解锁操作;
kafkaConsumer非线程安全并不意味着只能单线程的方式消费消息,多线程的实现方式有多种,第一种是线程封闭,每个线程都实例化一个KafkaConsumer对象,一个线程对应一个kafkaConsumer实例,称为消费线程,一个消费线程可以消费一个或者多个分区中的消息,所有的消费线程都隶属于同一个消费组,但这种实现方式受限于分区实际个数;第二种是多个消费线程同时消费一个分区,这个通过assign()、seek()等方法实现,这样可以打破原有的消费线程的个数不能超过分区数的限制,进一步提高了消费的能力,不过在实际应用场景非常复杂,不推荐使用。一般而言,分区是消费线程的最小划分单位;第三种实现方式,将处理消息模块改成多线程实现方式,就是将具体解析消息的业务方法改成多线程方式实现,但是又会引起消息位移提交的情况问题,需要引入一个共享变量offsets来参与提交,在每次消息处理完毕后消费位移保存到共享变量offsets(滑动窗口实现方式);
重要的消费者参数
1、fetch.min.bytes,consumer一次拉取请求poll中能从kafka中拉取到的最小数据量,默认值1B,当consumer发送给kafka拉取请求,kafka服务端返回给consumer的数据量小于这个最小数据量,就会进行等待,直到数据量满足这个参数的配置大小;
2、fetch.max.bytes,consumer一次拉取请求中从kafka中拉取的最大数据量,默认值为50MB,如果这个参数设置的值比任何一条写入kafka中的消息要小,也不会造成消息无法消费的问题,会正常消费(一条条消费);而且,Kafka中所能接收的最大消息的大小是通过服务器参数message.max.bytes来设置;
3、fetch.max.wait.ms,这个参数与fetch.min.bytes参数有关,当kafka因fetch.min.bytes参数的要求,可能会一直阻塞等待而无法响应给consumer,而此参数用于指定kafka的等待时间,默认为500ms;而且参数的设值与consumer与kafka之间的延迟有关系,如果业务应用对延迟敏感,那么可以适当调小这个参数;
4、max.partition.fetch.bytes,这个参数用来配置从每个分区里返回给Consumer的最大数据量,默认值1MB。这个参数与 fetch.max.bytes 参数相似,只不过前者用来限制一次拉取中每个分区的消息大小,而后者用来限制一次拉取中整体消息的大小。同样,如果这个参数设定的值比消息的大小要小,那么也不会造成无法消费;
5、max.poll.records,这个参数用来配置Consumer在一次拉取请求中拉取的最大消息数,默认值为500(条)。如果消息的大小都比较小,则可以适当调大这个参数值来提升一定的消费速度;
6、connections.max.idle.ms,这个参数用来指定在多久之后关闭限制的连接,默认值是540000(ms),即9分钟;
7、exclude.internal.topics,Kafka中有两个内部的主题:consumer_offsets和transaction_state。exclude.internal.topics用来指定Kafka中的内部主题是否可以向消费者公开,默认值为true。如果设置为true,那么只能使用subscribe(Collection)的方式而不能使用subscribe(Pattern)的方式来订阅内部主题,设置为false则没有这个限制;
8、receive.buffer.bytes,这个参数用来设置Socket接收消息缓冲区(SO_RECBUF)的大小,默认值为65536(B),即64KB。如果设置为-1,则使用操作系统的默认值。如果Consumer与Kafka处于不同的机房,则可以适当调大这个参数值;
9、send.buffer.bytes,这个参数用来设置Socket发送消息缓冲区(SO_SNDBUF)的大小,默认值为131072(B),即128KB。与receive.buffer.bytes参数一样,如果设置为-1,则使用操作系统的默认值;
10、request.timeout.ms,这个参数用来配置Consumer等待请求响应的最长时间,默认值为30000(ms);
11、metadata.max.age.ms,这个参数用来配置元数据的过期时间,默认值5分钟。如果元数据在此参数所限定的时间范围内没有进行更新,则会被强制更新,即使没有任何分区变化或有新的broker加入;
12、reconnect.backoff.ms,这个参数用来配置尝试重新连接指定主机之前的等待时间(也称为退避时间),避免频繁地连接主机,默认值为50(ms)。这种机制适用于消费者向broker发送的所有请求;
13、retry.backoff.ms,这个参数用来配置尝试重新发送失败的请求到指定的主题分区之前的等待(退避)时间,避免在某些故障情况下频繁地重复发送,默认值为100(ms)。
14、isolation.level,这个参数用来配置消费者的事务隔离级别。字符串类型,有效值为“read_uncommitted”和“read_committed”,表示消费者所消费到的位置,如果设置为“read_committed”,那么消费者就会忽略事务未提交的消息,即只能消费到LSO(LastStableOffset)的位置,默认情况下为“read_uncommitted”,即可以消费到HW(High Watermark)处的位置;
4、主题和分区
主题作为消息的归类,可以再细分为一个或者多个分区,分区也可以看做对消息的二次分类,分区的划分不仅为Kafka提供了可伸缩性、水平扩展的功能,还通过副本机制来为kafka提供数据冗余以提高数据可靠性。从kafka的底层实现来说,主题和分区都是逻辑上的概念,分区可以有一个或多个副本,每个副本对应一个日志文件,每个日志文件对应一个或者多个日志分段LogSegment,每个日志分段还可以细分为索引文件、日志存储文件和快照文件等;
通过脚本kafka-topics.sh脚本可以新增主题,①可以指定分区数和副本因子②同一个分区中的多个副本必须分布在不同的broker中,这样才能提供有效的数据冗余③主题的名称必须由大小写、数字、点号.、连接线-、下划线_组成,不能为空,不能只有点号.,也不能只有双点号..,且长度不能超过249;修改主题,可以添加分区数,但不支持减少分区数(删除分区会引起消息可靠性和顺序消费的问题),也可以通过kafka-topics.sh脚本的alter指令来变更主题的配置,注意在未来版本中变更配置功能已过时,推荐使用kafka-config.sh脚本来实现;删除主题,删除主题必须将broker端参数delete.topic.enable配置为true,删除主题topic-delete分三个步骤,第一步和第二部可以顺序可交换,第一步,删除ZooKeeper中的节点/config/topics/topic-delete,第二步,删除ZooKeeper中节点/brokers/topics/topic-delete及其子节点,第三步,删除集群中所有与主题topic-delete有关的文件(rm -rf /xx/kafka-logs/topic-delete-),需要注意删除主题时一个不可逆的操作,一旦删除之后,与其相关的所有数据全部都会被删除;
分区副本的分配,生产者的分区分配的指为每条消息指定其所要发往的分区,消费者中的分区分配的指为消费者指定其可以消费消息的分区,在主题中分区分配是指为集群制定创建主题时的分区副本分配方案,即在哪个broker中创建那些分区的副本;broker.rack=RACK1集群是否指定了机架信息和是否使用replicaassignment参数相关;
kafka-config.sh脚本是专门用来对配置进行操作的,这里的操作是指在运行状态下修改原有的配置,如此可以达到动态变更的目的,增删改行为都支持;
主题端参数,注意与主题相关的所有配置参数在broker层面都有对应参数,比如主题端参数cleanup.policy对应broker层面的log.cleanup.policy,如果没有修改过主题的任何配置参数,那么就会使用broker端的对应参数作为默认值。如:①cleanuo.policy,日志压缩策略,默认值为delete,对应broker参数log.cleanuo.policy;②compression.type,消息的压缩类型,默认值producer,表示保留生产者所使用的原始压缩类型,还可以配置为uncompressed/snappy/lz4/gzip,对应broker参数compression.type;③delete.retention.ms,被标记位删除的数据能够保留多久,默认值为8640000,1天,对应broker参数log.cleaner.delete.retention.ms;④file.delete.delay.ms,清理文件之前可以等待多长时间,默认值为60000,对应broker参数log.segment.delete.delay.ms等等;
KafkaAdminClient,可以将主题管理功能集成到系统中,打造管理、监控、运维、告警为一体的生态平台,以程序调用API去的方式实现;如,createTopics创建主题,deleteTopics删除主题,listTopics列出所有主题,describeTopics查看主题信息,describeConfigs查询配置信息,alterConfigs修改配置信息,createPartitions增加分区。KafkaAdminClient内部使用Kafka的一套自定义二进制协议来实现诸如创建主题的管理功能,①客户端根据方法的调用创建相应的协议请求,比如创建主题的createTopics方法,其内部就是发送CreateTopicRequest请求。②客户端将请求发送至服务端。③服务端处理相应的请求并返回响应,比如这个与CreateTopicRequest请求对应的就是CreateTopicResponse。④客户端接收相应的响应并进行解析处理。
主题合法性验证,broker端参数:create.topic.policy.class.name,默认值为null,提供一个入口用来验证主题创建的合法性,用来规范通过KafkaAdminClient创建的主题;使用方法很简单,只需要*自定义实现org.apache.kafka.server.policy.createTopicPolicy接口,然后将实现类配置到该参数下;
优先副本的选举,分区使用多副本机制来提升可靠性,但只有leader副本对外提供读写服务,而follower副本只负责在内部进行消息的同步。当某个分区的leader副本不可用,那么就是意味着整个分区不可用,需要kafka从剩余的follower副本中挑选一个新的leader副本来继续对外提供服务。虽然不够严谨,但从某种程度来说,broker节点中leader副本个数的多少决定了这个节点负载的高低。针对同一个分区来说,同一个broker节点中不可能出现它的多个副本,即kafka集群的一个broker中最多只能有它的一个副本,我们可以将leader副本所在的broker节点叫作分区的leader节点,而follower副本所在的broker节点叫做分区的follower节点;所谓的副本优先副本的选举是指通过一定的方式促使优先副本选举为leader副本,以此来促进集群的负载均衡,这一行为也称为“分区平衡”,注意分区平衡不是kafka集群的负载均衡,有些leader副本的负载很高,而有些leader副本只需要承载个位数的负荷。也就是说,就算集群中的分区分配均衡,leader分配均衡,也并不能确保整个集群的负载就算均衡的,还需要其他一些硬性指标来进一步衡量;broker端参数是auto.leader.rebalance.enable,默认是true开启(生产环境不建议设置成true,因为这可能引擎不负面的性能问题,造成客户端阻塞等),Kafka中kafka-perferred-replica-election.sh脚本提供了对分区leader副本进行重新平衡的功能,手动执行分区平衡。在实际生产环境中,一般使用 path-to-json-file 参数来分批、手动地执行优先副本的选举操作。尤其是在应对大规模的Kafka 集群时,理应杜绝采用非 path-to-json-file参数的选举操作方式。同时,优先副本的选举操作也要注意避开业务高峰期,以免带来性能方面的负面影响;
分区重分配,当要对集群中的一个节点进行有计划的下线操作时,为了保证分区及副本的合理分配,我们也希望通过某种方式能够将该节点上的分区副本迁移到其他的可用节点上,当集群中新增broker节点时,只有新创建的主题分区才有可能被分配到这个节点上,而之前的主题分区并不会自动分配到新加入的节点中,因为在它们被创建时还没有这个新节点,这样新节点的负载和原先节点的负载之间严重不均衡。为了解决上述问题,需要让分区副本再次进行合理的分配,也就是所谓的分区重分配。Kafka提供了 kafka-reassign-partitions.sh 脚本来执行分区重分配的工作,它可以在集群扩容、broker节点失效的场景下对分区进行迁移;分区重分配的基本原理是先通过控制器为每个分区添加新副本(增加副本因子),新的副本将从分区的leader副本那里复制所有的数据。还需要注意的是,如果要将某个broker下线,那么在执行分区重分配动作之前最好先关闭或重启broker。这样这个broker就不再是任何分区的leader节点了,它的分区就可以被分配给集群中的其他broker。这样可以减少broker间的流量复制,以此提升重分配的性能,以及减少对集群的影响。
复制限流,分区重分配本质在于数据复制,先增加新的副本,然后进行数据同步,最后删除旧的副本来达到最终的目的。如果集群中某个主题或某个分区的流量在某段时间内特别大,那么只靠减小粒度是不足以应对的,这时就需要有一个限流的机制,可以对副本间的复制流量加以限制来保证重分配期间整体服务不会受太大的影响。副本间的复制限流有两种实现方式:kafka-config.sh脚本和kafka-reassign-partitions.sh脚本。broker级别有两个与复制限流相关的配置参数:follower.replication.throttled.rate和leader.replication.throttled.rate,前者用于设置follower副本复制的速度,后者用于设置leader副本传输的速度,它们的单位都是B/s。通常情况下,两者的配置值是相同的。
如何选择合适的分区数?问题没有固定的答案,只能从某些角度来做具体的分析,最终还是要根据实际的业务场景、软件条件、硬件条件、负载情况等来做具体的考量;性能测试工具是 Kafka 本身提供的用于生产者性能测试的 kafka-producer-perf-test.sh和用于消费者性能测试的kafka-consumer-perf-test.sh;分区是Kafka 中最小的并行操作单元,对生产者而言,每一个分区的数据写入是完全可以并行化的;对消费者而言,Kafka只允许单个分区中的消息被一个消费者线程消费,一个消费组的消费并行度完全依赖于所消费的分区数。并不是分区数越多吞吐量也越大。这里的分区数临界阈值针对不同的测试环境也会表现出不同的结果,实际应用中可以通过类似的测试案例(比如复制生产流量以便进行测试回放)来找到一个合理的临界值区间。分区数上限,java.io.IOException:Too many open files!对于一个高并发、高性能的应用来说,1024 或 4096 的文件描述符限制未免太少(服务器参数),可以适当调大这个参数。比如使用 ulimit-n 65535 命令将上限提高到65535,这样足以应对大多数的应用情况,再高也完全没有必要了;从吞吐量方面考虑,增加合适的分区数可以在一定程度上提升整体吞吐量,但超过对应的阈值之后吞吐量不升反降。如果应用对吞吐量有一定程度上的要求,则建议在投入生产环境之前对同款硬件资源做一个完备的吞吐量相关的测试,以找到合适的分区数阈值区间,当分区数太大,某个节点宕机,那么就会有大量的分区需要同时进行leader角色切换,这个切换的过程会耗费一笔可观的时间,并且在这个时间窗口内这些分区也会变得不可用。分区数越多也会让Kafka的正常启动和关闭的耗时变得越长,与此同时,主题的分区数越多不仅会增加日志清理的耗时,而且在被删除时也会耗费更多的时间;如何选择合适的分区数?从某种意思来说,考验的是决策者的实战经验,更透彻地说,是对Kafka本身、业务应用、硬件资源、环境配置等多方面的考量而做出的选择。在设定完分区数,或者更确切地说是创建主题之后,还要对其追踪、监控、调优以求更好地利用它。如果一定要给一个准则,则建议将分区数设定为集群中broker的倍数,即假定集群中有3个broker节点,可以设定分区数为3、6、9等,至于倍数的选定可以参考预估的吞吐量。

若有收获,就点个赞吧
0 人点赞
