1) 是什么?
1.背景
ClickHouse是俄罗斯Yandex在 2016年6月15日开源的一个用于实时数据分析的基于列存储的数据库,其处理数据的速度比传统方法快100-1000倍。
Clickhouse的性能超过了目前市面上可比的面向列的DBMS,每秒钟每台服务器每秒处理数亿至十多亿行和数十千兆字节的数据。
2.定义
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS),ClickHouse不单单是一个数据库,它是一个数据库管理系统,它允许在运行时创建表和数据库、加载数据和运行查询,而无需重新配置或重启服务。
OLAP(On-Line Analytical Processing)与OLTP(on-line transaction processing);OLTP是传统的关系型数据库,主要操作增删改查,强调事务一致性,比如银行系统、电商系统,关键字“transaction”,OLAP是仓库型数据库,主要是读取数据,做复杂数据分析,侧重技术决策支持,提供直观简单的结果。
列式数据库与行式数据库区别,在传统的行式数据库系统(MySQL、Postgres和MS SQL Server)中,数据按如下顺序存储: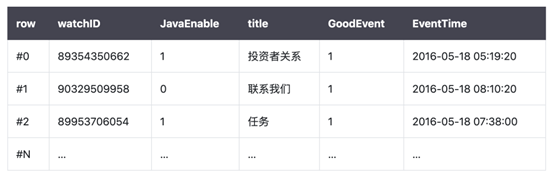
在列式数据库系统中(ClickHouse),数据按如下的顺序存储: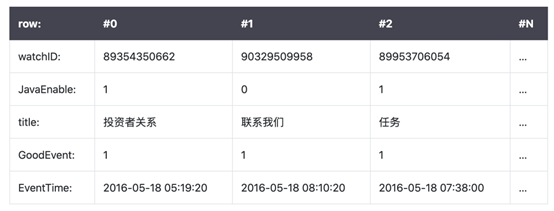
两者在存储方式上对比:
与Mysql查询速度对比(原因:①在查询数据时行式数据库需要逐行扫描全部列,而列式数据库仅需要按照查询的列扫描出列②按照列式存储,数据存储磁盘的压缩率非常高,读取数据对IO时间变少③IO的降低,也将有更多的数据缓存④CPU方面,多核并行针对分区和分析下的索引颗粒index_granularity使用多个CPU处理一部分数据,提供CPU利用率来降低时延):

3.特性
OLAP场景特征,总结来说OLAP数据库去处理分析请求;
(1)读多于写;
(2)大宽表,读取大量“行”但少量“列”,结果集较小;
(3)数据批量写入,并且数据不更新或少更新
(4)无需事务,数据一致性要求低;
(5)灵活多变,不适合预先建模;
ClickHouse的特性可以从存储层和计算层两个方面总结:
(1)ClickHouse存储层
创建表语句:
create tablev_non_motor_vehicle
on cluster perftest_2shards_1replicas (non_motor_vehicle_id String , crt_time UInt64)
engineMergeTree()
primary key non_motor_vehicle_id
partition BYtoYYYYMMDD(FROM_UNIXTIME(crt_time))
ORDER BY(non_motor_vehicle_id,crt_time)
SETTINGSindex_granularity=8192;
①列式存储:
在分析场景下读取大量行数据的少量列,行式数据库所有列数据再在同一个block(存储块,数据库中的最小存储和处理单位),不参与的列需要全部读取,而列式数据库仅读取参与的列,大大降低了IO消耗,加快了查询;同一列中的数据是同一个列项,压缩效果显著,有高达十倍的压缩比例,不仅节约了存储空间和存储成本,而且在高倍的压缩率下数据从磁盘data size和耗时将更短,同时系统cache能缓存更多的数据。
②数据有序存储:
clickhouse支持在建表时,指定数据安装某些列进行排序,保证排序后的数据在磁盘上连续存储,在执行等值或者范围查询时,条件命中的数据紧密存储在同一个block或者连续的block中,而不是任意多个block,大幅度减少了需要IO的block的数量。
③主键索引(primary key xxx):
ClickHouse支持主键索引,它将每列数据按照index granular(索引颗粒,默认8192),每个index granular的开头第一行被称为mark(标记)行,主键索引存储该mark行对应的primary key(主键)的值,当where条件查询遇到主键查询时,通过对主键索引进行二份查找,能够定位到对应的index granular,避免了全表查询;其中clickhouse最先进和常用的引擎MergeTree与Mysql数据库不同,它是不用去重,即是相同主键值也可以在该引擎下存在,去重效果可以选取ReplacingMergeTree等其他引擎。
④稀疏索引(ORDER BY xx):
clickhouse支持对任意列创建任意数量的稀疏索引(不会为所有关键字创建索引,索引记录包含搜索键和指向磁盘上数据的实际指针),在clickhouse中的稀疏索引本质是对一个完整的索引颗粒(index granular=默认8192行)的信息统计(每隔index granular行对主键组的进行采样,形成稀疏索引,每隔index granular行对每一列的压缩数据进行采样,形成数据标记)。现在clickhouse支持索引类型包含:minmax(以inddex granulartiy单位,存储指定表达式的min、max值,适用等值和范围查询,快速跳过不满足要去的块);set(max_rows) (以inddex granulartiy单位,存储指定表达式的不同值集合,用于快速判断等值查询是否命中该块,减少IO)等其他稀疏索引类型。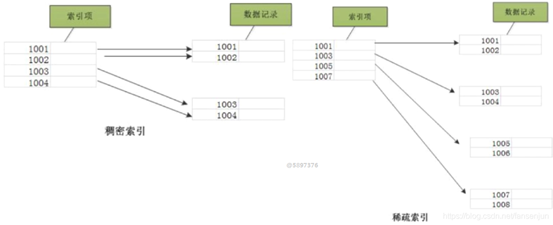
⑤数据Sharding(分片)(**on cluster xxx**):
Clickhouse支持单机模式也支持集群模式(集群依赖zookeeper),在集群模式下,clickhouse将数据分为多片,分别存储在不同的节点上;同时clickhouse也支持不同的分片模式,例如random随机分片(随机写入某个集群节点上)constant固定分片(写入指定节点上)column value(按照某一列的值进行hash分片)自定义表达式分片(指定合法表达式,根据表达式计算后的值进行分片),支持多样化的分片功能,可以适用于不同SQL模式和业务场景;分片机制可以支持横向扩展,大规模集群可以处理海量的数据。
⑥数据Partitioning(分区)(partition BY xxx):
Clickhouse在创建表时可以指定任意合法表达式进行数据分区操作,比如可以通过toYYYYMM()进行按月分区,toMonday()将数据安装周几进行分区等等;数据分区可以让查询仅查询到必要分区数据,提高查询速度,而且可以对分区进行TTL管理,淘汰删除过期分区的数据。
⑦数据TTL(数据生存值):
分析场景下,数据价值随着时间而不断下降,有的业务可能只会保留最近几个月数据,clickhouse通过TTL提供了数据生命周期管理能力。其中,clickhouse支持几种不同颗粒的TTL:列级别TTL:当一列的部分数据过期后,会被替换成默认值;当全列数据过期后会被删除该列;行级别TTL:当某行过期,会支持删除该行;分区级别TTL:当分区过期后,会直接删除该分区。
⑧高吞吐写入能力:
Clickhouse采用类LSM Tree的结构,数据写入后定期在后台Compaction(compaction的主要作用是数据的gc和归并排序)通过类LSM tree的结构,ClickHouse在数据导入时全部是顺序append写,写入后数据段不可更改,在后台compaction时也是多个段merge sort后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞吐能力,即便在HDD上也有着优异的写入性能。
⑨有限支持delete、update:
在分析场景中删除和更新不是核心操作,clickhouse不支持delete和update操作,而是变相支持mutaition(突变)操作,更新和删除属于异步操作,需要后台compation之后才生效。语法:alter table delete where filter_expr,alter table update col=val where filter_expr。
⑩主备同步:
高可用,主备复制,可以设置副本个数,默认配置下任何副本都是active模式,可以对外提供查询服务;不同的分片可以配置不提供副本个数,用于解决单个分片的查询热点问题。
(2)ClickHouse计算层:提供硬件使用率,“吃”服务器性能,提供查询效率
①多核并行
Clickhouse将数据进行多个分区,多个分区又进一步分成多个索引颗粒,然后通过多个CPU核心分别处理其中一部分数据来实现并行处理数据。在这设计下,clickhouse高效使用CPU且默认单查询使用CPU核数为服务器核数的一半,极致并行处理,降低查询时延。
②分布式计算
集群模式,将查询任务拆分为多个任务下发到集群的不同节点,同时进行并行处理,最后把查询结果汇聚到一起。Clickhouse支持集群横向扩展,分布式计算能力呈线性关系。在分布式多副本情况下,clickhouse提供了多种下发策略:随机下发(多个副本中选择一个)最近节点原则(选择与当前下发机器最近的hostname节点,来降低网络时延)in order(按照特定顺序逐个尝试下发,当第一个不可用,下发到下一个)first or random(防止在in oder模式下,第一个节点不可用,所有请求都到第二个节点时,导致积压负载不均匀;clickhouse会将顺序到第二节点的请求,随机选择一个副本进行下发)
③向量化执行与SIMD
④动态代码生成Runtime Codegen
⑤近似值计算
近似计算以损失一定结果精度为代价,极大地提升查询性能,ClickHouse实现了多种近似计算功能:近似估算distinct values、中位数,分位数等多种聚合函数;建表DDL支持SAMPLE BY子句,支持对于数据进行抽样处理。
4.缺点
①不支持事务,对应数据一致性不保证;
②不直接支持删除和更新,突变,异步操作执行,删除更新无法立即返回条数;
③不支持高并发,官方建议QPS为100,具体看服务器是否足够好。原因是clickhouse采用了并行处理机制,即使是一个查询也会使用服务器核数一半,安装时会自动识别服务器核数,100链接数和该配置参数都是通过配置文件进行配置;
④插入数据,建议做1000行以上批量插入,因为clickhouse的插入、删除、更新操作,会涉及clickhouse底层会不断异步执行数据合并操作,会影响查询性能;
2) 有什么用?
1. 常用场景
①适合数据分析类OLAP场景,如客户流量分析、web和app数据分析等需要对数据进行反复的遍历;
②电信行业用于存储数据和统计数据;
③新浪微博用于用户行为数据记录和分析工作;
④用于广告网络和RTB,电子商务的用户行为分析;
⑤信息安全里面的日志分析;
⑥检测和遥感信息的数据挖掘;
⑦商业智能;
⑧网络游戏以及物联网的数据处理和价值数据分析;
2.实战场景
总的来说适用于大数据方面的数据分析和数据挖掘,数据偏向于历史数据,读取数据比修改插入大得多,而且事务和数据一致性要求低。<br /> 项目使用过保存每日摄像头抓拍数据。之前数据存储仅结合kafka批量其实不够准确,同时应该也springboot的批处理或者flink结合处理,与文件系统配合尽力每秒批量插入一次数据或者数据达到阈值进行插入,且在数据的分区方面除了根据日期进行分区,根据实际业务也可以根据摄像头编码进行分区,便于支持数据的TTL管理(分区级别的TTL,分区过期则删除数据)<br />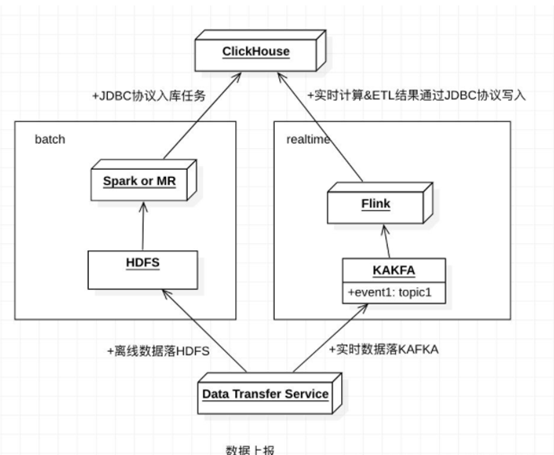
3.常用引擎介绍
①MergeTree(合并树家族)
Clickhouse中最强大的表引擎当属 MergeTree(合并树)引擎及该系列(* MergeTree)中的其他引擎。
MergeTree 系列的引擎被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。
主要特点:数据存储按主键排序;支持数据分区;支持数据副本;支持数据采样;
②ReplacingMergeTree
在MergeTree的基础上,增加了“处理重复数据”的功能,和MergeTree的不同之处在于他会删除具有相同主键的重复项,数据的去重只会在合并的过程中出现,合并会在未知的时间在后台进行,所以你无法预先做出计划,有一些数据可能仍未被处理,适用于在后台清除重复的数据以节省空间,但是不保证没有重复的数据出现。
③AggregatingMergeTree
该引擎继承自 MergeTree,并改变了数据片段的合并逻辑。ClickHouse 会将一个数据片段内所有具有相同主键(准确的说是 排序键)的行替换成一行,这一行会存储一系列聚合函数的状态。可以使用 AggregatingMergeTree 表来做增量数据的聚合统计,包括物化视图的数据聚合。
CREATE MATERIALIZED VIEW test.basic
ENGINE = AggregatingMergeTree() PARTITION BY toYYYYMM(StartDate) ORDER BY(CounterID, StartDate)
AS SELECT
CounterID,
StartDate,
sumState(Sign) AS Visits,
uniqState(UserID) AS Users
FROM test.visits
GROUP BYCounterID, StartDate;
④更多,查看官网等..**
3) 怎么用?
1. 链接工具
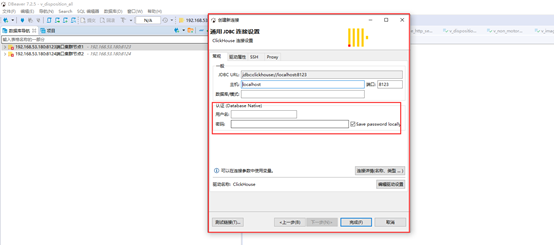
2. 部署
① Docker单机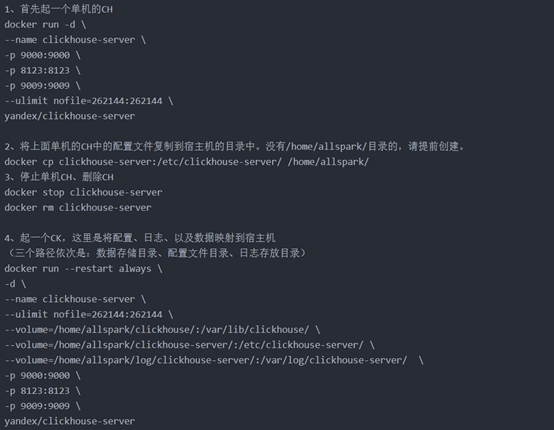
② Docker集群部署,依赖zookeeper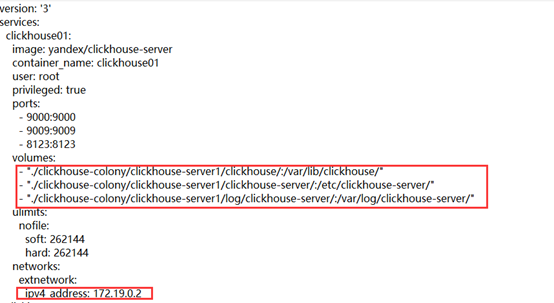
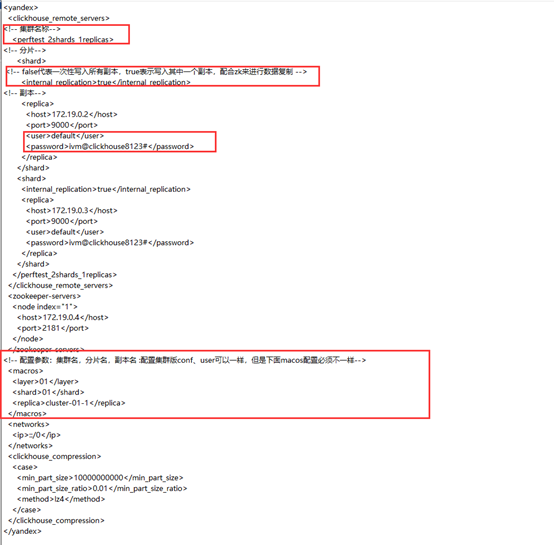
同时在每个clickhouse /et/clickhouse文件下存放metrika.xml集群配置文件且config.xml配置文件最后引入集群配置。配置文件中包含分片配置、副本配置、zk集群信息配置;
Config.xml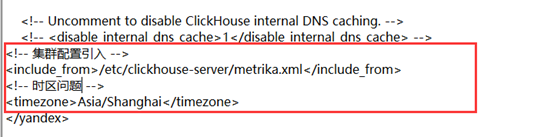
**
3. 配置文件
路径:/etc/clickhouse-server/…
① config.xml 服务器配置参数
注意启动需要把节点interserver_http_host,修改为本机IP 或者 0.0.0.0
② user.xml用户配置文件详解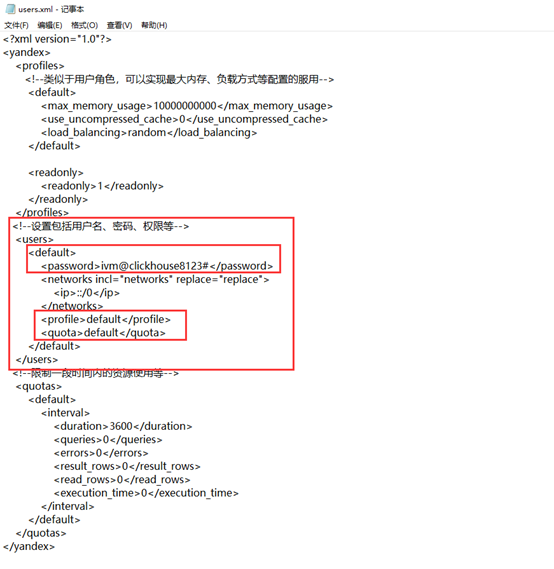
③ metrika.xml集群配置
4.脚本语言

5.理解与使用
①大量数据插入一定要走批量插入,默认配置链接数目为100qps;
②不适合高并发场景!没有事务性!数据一致性不保证!
4) 最后
1.官方文档
https://clickhouse.tech/docs/zh/
2.社区

若有收获,就点个赞吧
0 人点赞
