SQL 映射文件
先建立一个自模块:
增删改
mybatis允许增删改直接定义以下类型返回值:
- Integer
- Long
- Boolean
- void
EmployeeMapper 接口
定义增上改的方法:
public interface EmployeeMapper {void addEmp(Employee employee);Long updateEmp(Employee employee);boolean deleteEmpById(Integer id);}
EmployeeMapper.xml 文件
定义 SQL 语句:
parameterType:参数类型,可以省略。useGeneratedKeys="true":使用自增主键获取主键值策略(mysql支持自增主键,自增主键值的获取,mybatis也是利用statement.getGeneratedKeys();)keyProperty:指定 MyBatis 获取到主键值以后,将这个值封装给 JavaBean 的哪个属性。<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd"><mapper namespace="com.atguigu.mybatis.mapper.EmployeeMapper"><!-- 可以设置获取自增主键的值:--><insert id="addEmp" parameterType="com.atguigu.mybatis.bean.Employee"useGeneratedKeys="true" keyProperty="id">insert into tbl_employee(last_name,gender,email)values (#{lastName}, #{gender}, #{email})</insert><update id="updateEmp">update tbl_employeeset last_name = #{lastName}, gender = #{gender}, email = #{email}where id = #{id}</update><delete id="deleteEmpById">delete from tbl_employee where id = #{id}</delete></mapper>
测试代码:
注意事务需要提交:
sqlSessionFactory.openSession();==> 手动提交数据 ==>sqlSession.commit();sqlSessionFactory.openSession(true);==> 自动提交数据@Test public void test1() { SqlSessionFactory sqlSessionFactory = null; try { sqlSessionFactory = getSqlSessionFactory(); } catch (IOException e) { e.printStackTrace(); } SqlSession sqlSession = sqlSessionFactory.openSession(true); EmployeeMapper mapper = sqlSession.getMapper(EmployeeMapper.class); // Employee employee = new Employee(null, "jerry", "1", "jerry@gmail.com"); // mapper.addEmp(employee); // System.out.println(employee.getId()); // Employee employee = new Employee(1, "jerry", "1", "jerry@gmail.com"); // Long updateEmp = mapper.updateEmp(employee); // System.out.println(updateEmp); boolean isDeleted = mapper.deleteEmpById(3); System.out.println(isDeleted); // sqlSession.commit();// 手动提交数据 sqlSession.close(); }
查询
单个参数
MyBatis 不会做特殊处理, #{参数名/任意名}:取出参数值。
多个参数
MyBatis 会做特殊处理,多个参数会被封装成 一个map:
key:param1…paramN,或者参数的索引也可以。value:传入的参数值。
#{}就是从 map 中获取指定的 key 的值。
【异常】
方法:Employee getEmpByIdAndLastName(Integer id,String lastName);
取值:select * from tbl_employee where id=#{id} and last_name=#{lastName}
报异常:org.apache.ibatis.binding.BindingException: Parameter 'id' not found. Available parameters are [arg1, arg0, param1, param2]
【@Param注解】
明确指定封装参数时 map 的 key,使用 @Param 注解,多个参数会被封装成 一个map,key使用@Param注解指定的值 ,value是参数值。#{指定的key}取出对应的参数值。
比如下面的就不会报错了:Employee getEmpByIdAndLastName(@Param("id") Integer id, @Param("lastName") String lastName);select * from tbl_employee where id=#{id} and last_name=#{lastName}
【Map】
如果多个参数不是业务模型中的数据,没有对应的pojo,不经常使用,为了方便,我们也可以传入map,#{key}取出map中对应的值。
例如:Employee getEmpByMap(Map<String, Object> map);select * from tbl_employee where id=#{id} and last_name=#{lastName}
【POJO】
如果多个参数正好是我们业务逻辑的数据模型,我们就可以直接传入pojo,#{属性名}取出传入的pojo的属性值。
【TO,Transfer Object】
如果多个参数不是业务模型中的数据,但是经常要使用,推荐来编写一个TO数据传输对象。
【思考】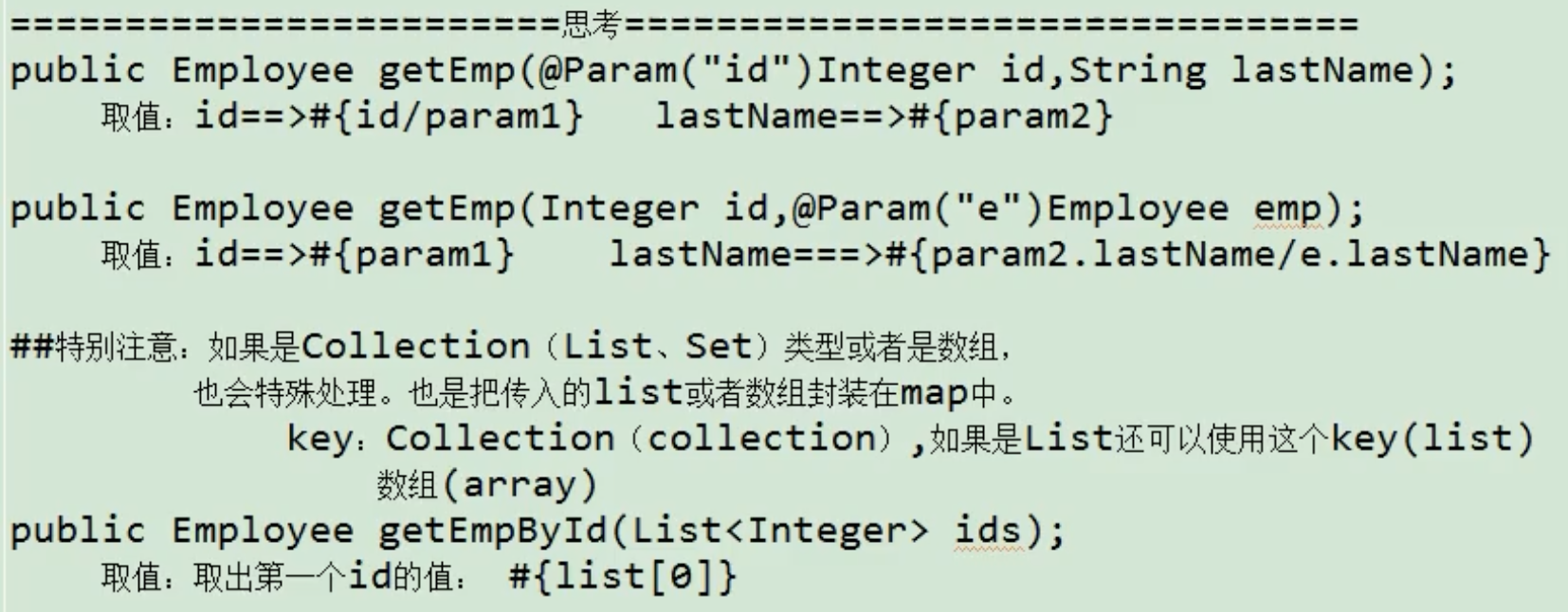
#{} 与 ${} 的比较
它们都可以获取 map 中的值或者 pojo 对象属性的值。
【区别】select * from tbl_employee where id=${id} and last_name=#{lastName}Preparing: select * from tbl_employee where id=2 and last_name=?
#{}:是以预编译的形式将参数设置到 sql 语句中,PreparedStatement,防止sql注入。${}:取出的值直接拼装在 sql 语句中,会有安全问题。
大多情况下,我们取参数的值都应该去使用#{},但是原生jdbc不支持占位符的地方我们需要使用 ${} 进行取值,比如分表、排序、按照年份分表拆分等等。select * from ${year}_salary where xxx; select * from tbl_employee order by ${f_name} ${order}
**#{}**更丰富的用法:
规定参数的一些规则:javaType、 jdbcType、 mode(存储过程)、 numericScale、 resultMap、 typeHandler、 jdbcTypeName等。
jdbcType 通常需要在某种特定的条件下被设置:在我们数据为null的时候,有些数据库可能不能识别 mybatis 对 null 的默认处理,比如Oracle(报错)。
JdbcType OTHER:无效的类型,因为 mybatis 对所有的 null 都映射的是原生 Jdbc的OTHER 类型,mysql可以处理,但是 oracle 不能正确处理。
由于全局配置中:jdbcTypeForNull默认值是OTHER;oracle不支持,两种解决办法:
1、#{email,jdbcType=OTHER};
2、修改全局配置 <setting name="jdbcTypeForNull" value="NULL"/>
返回集合类型 resultType
// 多条记录封装为一个map:键是这条记录的主键,值是封装后的javaBean
// @MapKey:告诉mybatis封装这个map的时候使用哪个属性作为map的key
@MapKey("id")
Map<Integer, Employee> getEmpByLastNameLikeReturnMap(String lastName);
// 返回一条记录的map;key就是列名,值就是对应的值
Map<String, Object> getEmpByIdReturnMap(Integer id);
// 返回List集合
List<Employee> getEmpsByLastNameLike(String lastName);
<select id="getEmpByLastNameLikeReturnMap" resultType="employee">
select * from tbl_employee where last_name like #{lastName}
</select>
<select id="getEmpByIdReturnMap" resultType="map">
select * from tbl_employee where id=#{id}
</select>
<!-- 返回值类型填写集合中元素的类型 -->
<select id="getEmpsByLastNameLike" resultType="employee">
select * from tbl_employee where last_name like #{lastName}
</select>
resultMap
public interface EmployeeMapperPlus {
Employee getEmpById(Integer id);
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.atguigu.mybatis.mapper.EmployeeMapperPlus">
<!--
自定义某个javaBean的封装规则,type:自定义规则的Java类型,id:唯一id方便引用
-->
<resultMap id="MyEmp" type="com.atguigu.mybatis.bean.Employee">
<!--
指定主键列的封装规则,id 定义主键会底层有优化,
column 指定哪一列,property 指定对应的 JavaBean 属性
-->
<id column="id" property="id"/>
<!-- 定义普通列封装规则 -->
<result column="last_name" property="lastName"/>
<!-- 其他不指定的列会自动封装:我们只要写resultMap就把全部的映射规则都写上。 -->
<result column="gender" property="gender"/>
<result column="email" property="email"/>
</resultMap>
<!-- resultMap:自定义结果集映射规则 -->
<select id="getEmpById" resultMap="MyEmp">
select * from tbl_employee where id = #{id}
</select>
</mapper>
联合查询
1、可以使用级联属性封装结果集
2、可以使用association标签指定联合的javaBean对象
CREATE TABLE `tbl_dept` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`dept_name` varchar(255),
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
ALTER TABLE tbl_employee ADD COLUMN d_id INT(11);
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Department {
private Integer id;
private String deptName;
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Employee {
private Integer id;
private String lastName;
private String gender;
private String email;
private Department dept;
}
<!-- 联合查询:级联属性封装结果集 -->
<!--方法1-->
<resultMap id="myEmp2" type="employee">
<id column="id" property="id"/>
<result column="last_name" property="lastName"/>
<result column="gender" property="gender"/>
<result column="email" property="email"/>
<result column="did" property="dept.id"/>
<result column="dept_name" property="dept.deptName"/>
</resultMap>
<!--方法2-->
<resultMap id="myEmp3" type="employee">
<id column="id" property="id"/>
<result column="last_name" property="lastName"/>
<result column="gender" property="gender"/>
<result column="email" property="email"/>
<association property="dept" javaType="department">
<id column="did" property="id"/>
<result column="dept_name" property="deptName"/>
</association>
</resultMap>
<select id="getEmpAndDept" resultMap="myEmp3">
select e.id id, e.last_name last_name, e.gender gender,
e.email email, d.id did, d.dept_name dept_name
from tbl_employee e, tbl_dept d
where e.d_id=d.id and e.id=#{id}
</select>
3、也可以使用 association 标签进行分步查询
public interface DepartmentMapper {
Department getDepartmentById(Integer id);
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.atguigu.mybatis.mapper.DepartmentMapper">
<select id="getDepartmentById" resultType="department">
select id, dept_name deptName from tbl_dept where id=#{id}
</select>
</mapper>
<!--
分步查询:
1、先按照员工id查询员工信息
2、根据查询员工信息中的d_id值去部门表查出部门信息
3、部门设置到员工中;
-->
<resultMap id="myEmpByStep" type="employee">
<id column="id" property="id"/>
<result column="last_name" property="lastName"/>
<result column="gender" property="gender"/>
<result column="email" property="email"/>
<association property="dept"
select="com.atguigu.mybatis.mapper.DepartmentMapper.getDepartmentById"
column="d_id"/>
</resultMap>
<select id="getEmpByIdStep" resultMap="myEmpByStep">
select * from tbl_employee where id=#{id}
</select>
关于延迟加载
可以在全局配置文件 mybatis-config.xml 中进行如下设置:
<settings>
<!--开启驼峰命名映射-->
<setting name="mapUnderscoreToCamelCase" value="true"/>
<!--默认值是OTHER,Oracle需要下面的设置,MySQL不需要-->
<setting name="jdbcTypeForNull" value="NULL"/>
<!--延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。 -->
<setting name="lazyLoadingEnabled" value="true"/>
<!--开启时,任一方法的调用都会加载该对象的所有延迟加载属性。
否则,每个延迟加载属性会按需加载-->
<setting name="aggressiveLazyLoading" value="false"/>
</settings>
4、Colletion 标签可以定义关联集合类型的属性的封装
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Department {
private Integer id;
private String deptName;
private List<Employee> emps;
}
public interface DepartmentMapper {
Department getDepartmentById(Integer id);
Department getDeptByIdPlus(Integer id);
}
<mapper namespace="com.atguigu.mybatis.mapper.DepartmentMapper">
<select id="getDepartmentById" resultType="department">
select id, dept_name deptName from tbl_dept where id=#{id}
</select>
<resultMap id="myDept" type="department">
<id column="did" property="id"/>
<result column="dept_name" property="deptName"/>
<!--
collection 定义关联集合类型的属性的封装
ofType 指定集合里面元素的类型
-->
<collection property="emps" ofType="employee">
<!--然后,定义这个集合中元素的封装规则-->
<id column="eid" property="id"/>
<result column="last_name" property="lastName"/>
<result column="gender" property="gender"/>
<result column="email" property="email"/>
</collection>
</resultMap>
<select id="getDeptByIdPlus" resultMap="myDept">
select d.id did, d.dept_name dept_name, e.id eid,
e.last_name last_name, e.gender gender, e.email email
from tbl_dept d
left join tbl_employee e
on d.id=e.d_id
where d.id=#{id}
</select>
</mapper>
5、Colletion 标签也可以用于分步查询
public interface EmployeeMapperPlus {
Employee getEmpById(Integer id);
Employee getEmpAndDept(Integer id);
Employee getEmpByIdStep(Integer id);
List<Employee> getEmpsByDeptId(Integer deptId);
}
<!--按照部门id查询所有员工-->
<select id="getEmpsByDeptId" resultType="employee">
select * from tbl_employee where d_id=#{deptId}
</select>
public interface DepartmentMapper {
Department getDepartmentById(Integer id);
Department getDeptByIdPlus(Integer id);
Department getDeptByIdStep(Integer id);
}
<!--collection 也可以分步查询-->
<!--
column 传输多列的值可以封装成 map,column="{key1=column1,key2=column2}"
fetchType 的值为"lazy"表示使用延迟加载,"eager"表示立即
-->
<resultMap id="myDeptStep" type="department">
<id column="id" property="id"/>
<result column="dept_name" property="deptName"/>
<collection property="emps"
select="com.atguigu.mybatis.mapper.EmployeeMapperPlus.getEmpsByDeptId"
column="{deptId=id}"
fetchType="eager"/>
</resultMap>
<select id="getDeptByIdStep" resultMap="myDeptStep">
select id, dept_name from tbl_dept where id=#{id}
</select>
6、关于 discriminator 鉴别器的使用(了解即可)
<!-- <discriminator javaType=""></discriminator>
鉴别器:mybatis可以使用discriminator判断某列的值,然后根据某列的值改变封装行为
封装Employee:
如果查出的是女生:就把部门信息查询出来,否则不查询;
如果是男生,把last_name这一列的值赋值给email;
-->
<resultMap type="com.atguigu.mybatis.bean.Employee" id="MyEmpDis">
<id column="id" property="id"/>
<result column="last_name" property="lastName"/>
<result column="email" property="email"/>
<result column="gender" property="gender"/>
<!--
column:指定判定的列名
javaType:列值对应的java类型 -->
<discriminator javaType="string" column="gender">
<!--女生 resultType:指定封装的结果类型;不能缺少。/resultMap-->
<case value="0" resultType="com.atguigu.mybatis.bean.Employee">
<association property="dept"
select="com.atguigu.mybatis.dao.DepartmentMapper.getDeptById"
column="d_id">
</association>
</case>
<!--男生 ;如果是男生,把last_name这一列的值赋值给email; -->
<case value="1" resultType="com.atguigu.mybatis.bean.Employee">
<id column="id" property="id"/>
<result column="last_name" property="lastName"/>
<result column="last_name" property="email"/>
<result column="gender" property="gender"/>
</case>
</discriminator>
</resultMap>
动态 SQL

先建立一个子模块:
public interface EmployeeMapper {
List<Employee> getEmpsByConditionIf(Employee employee);
List<Employee> getEmpsByConditionTrim(Employee employee);
List<Employee> getEmpsByConditionChoose(Employee employee);
//查询员工的 id 在给定的集合中
List<Employee> getEmpsByConditionForeach(@Param("ids") List<Integer> ids);
void updateEmp(Employee employee);
//批量添加方式1
void addEmps(@Param("emps") List<Employee> employee);
//批量添加方式2
void addEmpsMultiSql(@Param("emps") List<Employee> employee);
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.atguigu.mybatis.mapper.EmployeeMapper">
<!--主要测试 if、choose、trim、foreach 标签的使用-->
<!--
这里面涉及 OGNL 表达式的使用:
''会被识别为空串,想用""可以写""
OGNL 会进行字符串与数字的转换判断,比如 "0"==0
-->
<!--where 标签只会去掉前面多出来的 and or-->
<select id="getEmpsByConditionIf" resultType="employee">
select * from tbl_employee
<where>
<if test="id != null">
id = #{id}
</if>
<if test="lastName != null and lastName != ''">
and last_name like #{lastName}
</if>
<if test="email != null and email.trim() != ''">
and email = #{email}
</if>
<if test="gender == 0 or gender == 1">
and gender = #{gender}
</if>
</where>
</select>
<!--
trim 标签可以解决后面多出来的 and or,有下面四个属性:
prefix:给拼接后的字符串加一个前缀
prefixOverrides:去掉整个字符串前面多余的字符
suffix:给拼接后的字符串加一个后缀
suffixOverrides:去掉整个字符串后面多余的字符串
-->
<select id="getEmpsByConditionTrim" resultType="employee">
select * from tbl_employee
<trim prefix="where" suffixOverrides="and">
<if test="id != null">
id = #{id} and
</if>
<if test="lastName != null and lastName != ''">
last_name like #{lastName} and
</if>
<if test="email != null and email.trim() != ''">
email = #{email} and
</if>
<if test="gender == 0 or gender == 1">
gender = #{gender}
</if>
</trim>
</select>
<!--choose 标签只会选择一列,如果传入多个列,就选择第一列-->
<select id="getEmpsByConditionChoose" resultType="employee">
select *
from tbl_employee
<where>
<choose>
<when test="id != null">
id = #{id}
</when>
<when test="lastName != null">
last_name like #{lastName}
</when>
<when test="email != null">
email = #{email}
</when>
<otherwise>
gender=0
</otherwise>
</choose>
</where>
</select>
<!--更新操作,使用 set 标签或者 trim 标签都可以处理","的问题-->
<update id="updateEmp">
update tbl_employee
<trim prefix="set" suffixOverrides=",">
<if test="lastName != null">
last_name = #{lastName},
</if>
<if test="email != null">
email = #{email},
</if>
<if test="gender != null">
gender = #{gender}
</if>
</trim>
<where>
id = #{id}
</where>
</update>
<!--
foreach 标签的使用:
collection:指定要遍历的集合。
item:将当前遍历出的元素赋值给指定的变量。
separator:每个元素之间的分隔符。
open:遍历出所有结果拼接一个开始的字符。
close:遍历出所有结果拼接一个结束的字符。
index:索引。遍历list的时候是index就是索引,item就是当前值;遍历map的时候index表示的就是map的key,item就是map的值
-->
<select id="getEmpsByConditionForeach" resultType="employee">
select * from tbl_employee where id in
<foreach collection="ids" item="item_id" separator="," open="(" close=")">
#{item_id}
</foreach>
</select>
<!--批量添加 方式1-->
<insert id="addEmps">
insert into tbl_employee(last_name, gender, email, d_id)
values
<foreach collection="emps" item="emp" separator=",">
(#{emp.lastName}, #{emp.gender}, #{emp.email}, #{emp.dept.id})
</foreach>
</insert>
<!--
批量添加 方式2,发送多条SQL语句的形式
需要 mysql 数据库连接的 url 加上 allowMultiQueries=true
-->
<insert id="addEmpsMultiSql">
<foreach collection="emps" item="emp" separator=";">
insert into tbl_employee (last_name, gender, email, d_id)
values (#{emp.lastName}, #{emp.gender}, #{emp.email}, #{emp.dept.id})
</foreach>
</insert>
</mapper>
jdbc.driver=com.mysql.cj.jdbc.Driver
jdbc.url=jdbc:mysql://localhost:3306/mybatis?serverTimezone=Asia/Shanghai&allowMultiQueries=true
jdbc.username=root
jdbc.password=12345678
缓存
新建一个子模块:

一级缓存
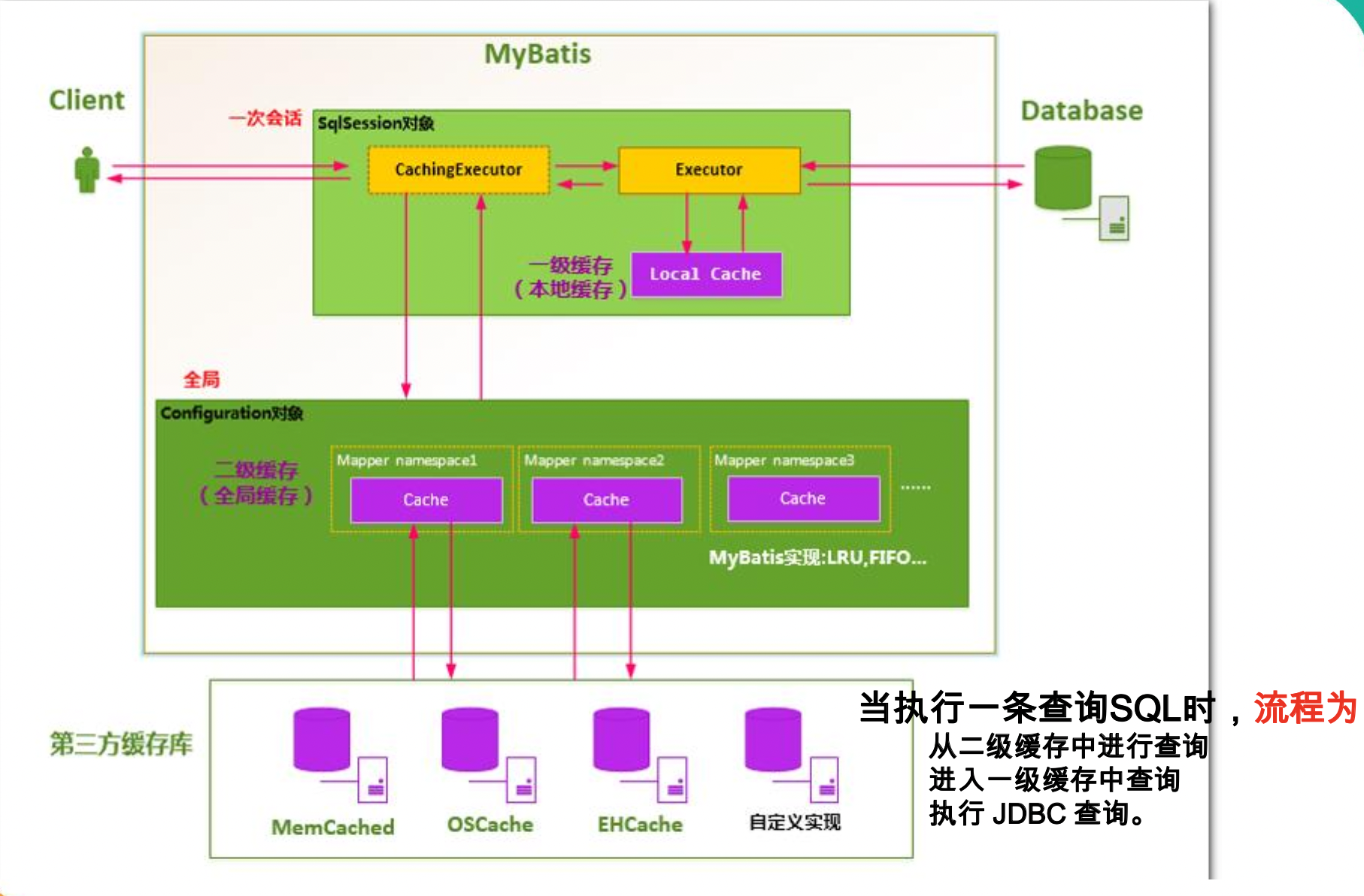
一级缓存(本地缓存):sqlSession级别的缓存,一级缓存默认是一直开启的。
/**
* 一级缓存:(本地缓存):sqlSession级别的缓存。一级缓存默认是一直开启的;SqlSession级别的一个Map
* 与数据库同一次会话期间查询到的数据会放在本地缓存中。
* 以后如果需要获取相同的数据,直接从缓存中拿,没必要再去查询数据库;
*
* 一级缓存失效情况(没有使用到当前一级缓存的情况,效果就是,还需要再向数据库发出查询):
* 1、sqlSession不同。
* 2、sqlSession相同,查询条件不同.(当前一级缓存中还没有这个数据)
* 3、sqlSession相同,两次查询之间执行了增删改操作(这次增删改可能对当前数据有影响)
* 4、sqlSession相同,手动清除了一级缓存(缓存清空)
*/
@Test
public void testFirstLevelCache() throws IOException{
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
SqlSession openSession = sqlSessionFactory.openSession();
try{
EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class);
Employee emp01 = mapper.getEmpById(1);
System.out.println(emp01);
//xxxxx
//1、sqlSession不同。
//SqlSession openSession2 = sqlSessionFactory.openSession();
//EmployeeMapper mapper2 = openSession2.getMapper(EmployeeMapper.class);
//2、sqlSession相同,查询条件不同
//3、sqlSession相同,两次查询之间执行了增删改操作(这次增删改可能对当前数据有影响)
//mapper.addEmp(new Employee(null, "testCache", "cache", "1"));
//System.out.println("数据添加成功");
//4、sqlSession相同,手动清除了一级缓存(缓存清空)
//openSession.clearCache();
Employee emp02 = mapper.getEmpById(1);
//Employee emp03 = mapper.getEmpById(3);
System.out.println(emp02);
//System.out.println(emp03);
System.out.println(emp01==emp02);
//openSession2.close();
}finally{
openSession.close();
}
}
二级缓存
1、需要先在 MyBatis 全局配置文件(mybatis-config.xml) 文件中手动开启:
<setting name="cacheEnabled" value="true"/>
2、需要在SQL映射文件中做如下配置:
二级缓存(全局缓存):基于namespace级别的缓存:一个namespace对应一个二级缓存。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.atguigu.mybatis.mapper.EmployeeMapper">
<cache eviction="FIFO" readOnly="true" size="1024"/>
<!--
eviction:缓存的回收策略:
• LRU – 最近最少使用的:移除最长时间不被使用的对象。
• FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
• SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。
• WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
• 默认的是 LRU。
flushInterval:缓存刷新间隔
缓存多长时间清空一次,默认不清空,设置一个毫秒值
readOnly:是否只读:
true:只读;mybatis认为所有从缓存中获取数据的操作都是只读操作,不会修改数据。
mybatis为了加快获取速度,直接就会将数据在缓存中的引用交给用户。不安全,速度快
false:非只读:mybatis觉得获取的数据可能会被修改。
mybatis会利用序列化&反序列的技术克隆一份新的数据给你。安全,速度慢
size:缓存存放多少元素;
type="":指定自定义缓存的全类名;
实现Cache接口即可;
-->
<select id="getEmpById" resultType="employee">
select * from tbl_employee where id = #{id}
</select>
</mapper>
3、测试代码:
/**
* 二级缓存:(全局缓存):基于namespace级别的缓存:一个namespace对应一个二级缓存:
* 工作机制:
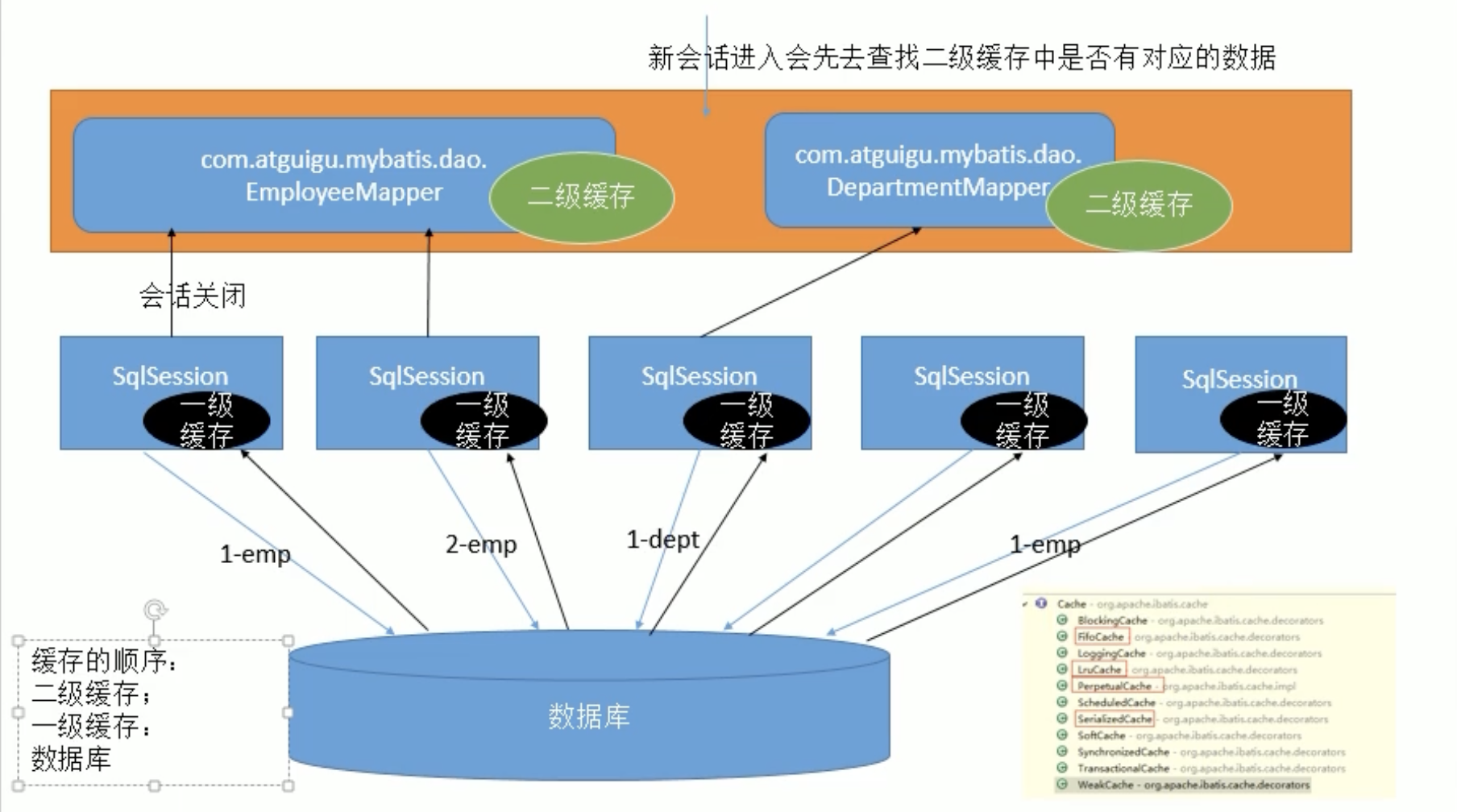
* 1、一个会话,查询一条数据,这个数据就会被放在当前会话的一级缓存中;
* 2、如果会话关闭;一级缓存中的数据会被保存到二级缓存中;新的会话查询信息,就可以参照二级缓存中的内容;
* 3、sqlSession===EmployeeMapper==>Employee
* DepartmentMapper===>Department
* 不同namespace查出的数据会放在自己对应的缓存中(map)
* 效果:数据会从二级缓存中获取
* 查出的数据都会被默认先放在一级缓存中。
* 只有会话提交或者关闭以后,一级缓存中的数据才会转移到二级缓存中
* 使用:
* 1)、开启全局二级缓存配置:<setting name="cacheEnabled" value="true"/>
* 2)、去mapper.xml中配置使用二级缓存:
* <cache></cache>
* 3)、我们的POJO需要实现序列化接口
*/
@Test
public void test1() throws IOException {
//必须使用同一个sqlSessionFactory
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
SqlSession sqlSession01 = sqlSessionFactory.openSession();
SqlSession sqlSession02 = sqlSessionFactory.openSession();
EmployeeMapper mapper01 = sqlSession01.getMapper(EmployeeMapper.class);
EmployeeMapper mapper02 = sqlSession02.getMapper(EmployeeMapper.class);
Employee emp01 = mapper01.getEmpById(1);
System.out.println(emp01);
sqlSession01.close();
Employee emp02 = mapper02.getEmpById(1);//Cache Hit
System.out.println(emp02);
System.out.println(emp01 == emp02);//true
sqlSession02.close();
}
和缓存有关的属性或设置
1、全局配置文件中的setting标签中的
cacheEnabled属性false:表示关闭二级缓存关闭,一级缓存仍可使用。true:表示开启二级缓存。
localCacheScope属性,表示本地缓存作用域。SESSION:一级缓存,也是默认值,当前会话的所有数据保存在会话缓存中。STATEMENT:可以禁用一级缓存。
2、每个select标签都有useCache属性
true:表示使用二级缓存。false:表示不使用二级缓存,但是一级缓存依然可以使用。
3、每个insert、update、delete标签的:flushCache="true":表示一级二级都会清除。
增删改执行完成后就会清楚缓存;
测试:flushCache=”true”:一级缓存就清空了;二级也会被清除;
4、每个select标签的:flushCache="false":表示不会清除缓存,但是如果设置flushCache=true,那么每次查询之后都会清空缓存,缓存是没有被使用的。
5、如果程序中调用:sqlSession.clearCache();表示只是清除当前session的一级缓存,二级缓存不受影响。
缓存结构图
整合第三方缓存库
比如和 Ehcahae 整合,官网:http://mybatis.org/ehcache-cache/
1、pom **文件引入依赖**
<!--日志-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.14.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.14.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.32</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.32</version>
<scope>test</scope>
</dependency>
<!--ehcache-->
<dependency>
<groupId>org.ehcache</groupId>
<artifactId>ehcache</artifactId>
<version>3.9.6</version>
</dependency>
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-ehcache</artifactId>
<version>1.2.1</version>
</dependency>
2、SQL映射文件
在 xxxxMapper.xml 文件中,添加标签:
<cache type="org.mybatis.caches.ehcache.EhcacheCache"/>
其它映射文件如果想用,可以采用引入的方式:
<!-- 引用缓存:namespace:指定和哪个名称空间下的缓存一样 -->
<cache-ref namespace="com.atguigu.mybatis.dao.EmployeeMapper"/>
3、添加 ehcache.xml
<?xml version="1.0" encoding="UTF-8" ?>
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://ehcache.org/ehcache.xsd" updateCheck="false">
<!--diskStore: ehcache分为内存和磁盘两级, 此属性定义磁盘的缓存位置-->
<diskStore path="/opt/ehcache"/>
<!--default 默认缓冲策略, 当ehcache找不到定义的缓存时, 则使用这个缓存策略, 这个只能定义一个-->
<!--
maxElementsInMemory:设置在内存中缓存对象的个数
maxElementsOnDisk:设置在硬盘中缓存对象的个数
eternal:设置缓存是否永远不过期
overflowToDisk:当系统宕机的时候是否保存到磁盘上,maxElementsInMemory的时候,是否转移到硬盘中
timeToIdleSeconds:当2次访问超过该值的时候,将缓存对象失效
timeToLiveSeconds:一个缓存对象最多存放的时间(生命周期)
diskExpiryThreadIntervalSeconds:设置每隔多长时间,通过一个线程来清理硬盘中的缓存
clearOnFlush: 内存数量最大时是否清除
memoryStoreEvictionPolicy:当超过缓存对象的最大值时,处理的策略;LRU (最少使用),FIFO (先进先出), LFU (最少访问次数)
-->
<defaultCache
maxElementsInMemory="10000"
maxElementsOnDisk="10000000"
eternal="false"
overflowToDisk="true"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU">
</defaultCache>
</ehcache>
4、配置 log4j.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd">
<log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/">
<appender name="STDOUT" class="org.apache.log4j.ConsoleAppender">
<param name="Encoding" value="UTF-8" />
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%-5p %d{MM-dd HH:mm:ss,SSS} %m (%F:%L) \n" />
</layout>
</appender>
<logger name="java.sql">
<level value="debug" />
</logger>
<logger name="org.apache.ibatis">
<level value="info" />
</logger>
<root>
<level value="debug" />
<appender-ref ref="STDOUT" />
</root>
</log4j:configuration>

若有收获,就点个赞吧
0 人点赞
