简介
原文:https://hadrienj.github.io/posts/Deep-Learning-Book-Series-2.1-Scalars-Vectors-Matrices-and-Tensors/
这是深度学习系列的第一篇,该系列跟随Goodfellow《深度学习》一书的第二章——线性代数,是我在阅读书的过程中产生的思考、细节、延伸和举例,便于你更好的理解线性代数。
第一篇内容很简单,主要介绍了线性代数中的基本元素及其定义,也补充了我们在该系列中将要用到的Python/Numpy中的重要函数。本文也会举例介绍如何创建、操作向量和矩阵对象。
2.1 标量,向量,矩阵和张量
让我们首先从它们的基本定义开始: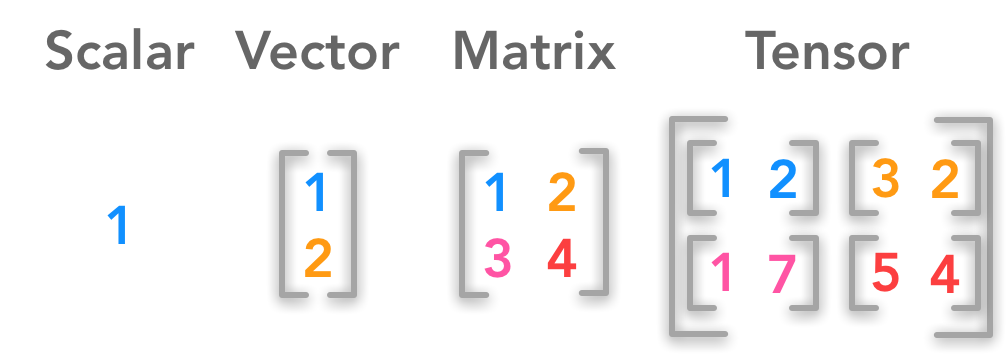
- 标量是一个数字
- 向量是一组数字

- 矩阵是一个2维数组

- 张量是一个n维数组,其中n>2
我们将遵从《深度学习》书中的规定:
标量使用小写、斜体字母表示,例如:
向量使用小写、斜体、粗体字母表示,例如:
矩阵使用大写、斜体、粗体字母表示,例如:
例 1
使用Python和Numpy创建一个向量
我们从创建一个向量开始,以下为一个1维数组:
x = np.array([1, 2, 3, 4])x
array([1, 2, 3, 4])
例 2
使用括号组合创建一个 的距征
的距征
np.array()函数也可以被来来创建一个2维数组
A = np.array([[1, 2], [3, 4], [5, 6]])A
array([[1, 2],[3, 4],[5, 6]])
形状(Shape)
数组的形状可以告诉我们每一维的数值,对于一个2维数组,2个数值分别表示行数和列数。因为A是一个Numpy数组,我们可以通过以下代码得到它的形状:
A.shape
(3, 2)
可以看到A有3行,2列。
同样,让我们观察下第一个向量的形状:
x.shape
(4,)
矩阵转置(Transposition)
通过转置我们可以讲一个列向量转化为一个行向量,反之亦然。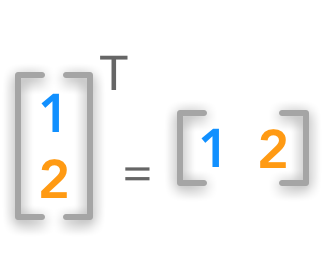
转置前后的矩阵有相同的对称轴,如果矩阵为一个方阵: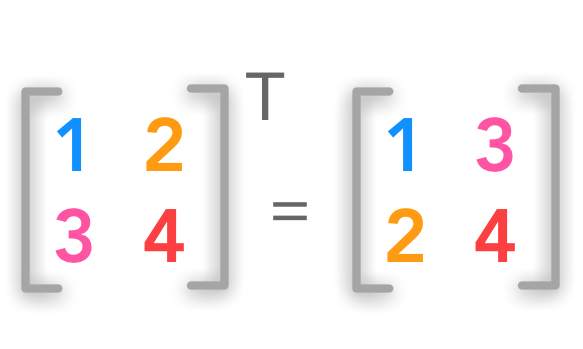
假如矩阵不是方阵,道理也是一样的: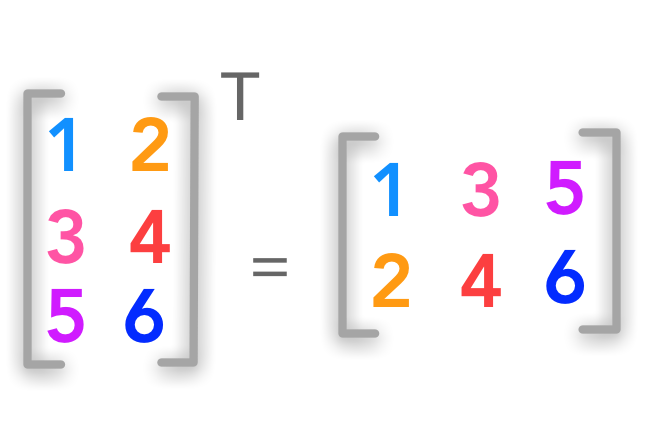
 用来表示转置矩阵:
用来表示转置矩阵:
(MN)的矩阵经过转置后变为了(NM)。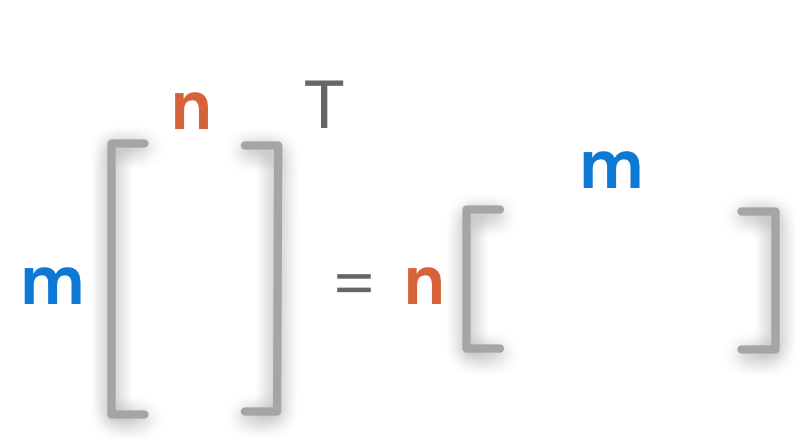
例 3
创建一个矩阵并将其转置
A = np.array([[1, 2], [3, 4], [5, 6]])A
array([[1, 2],[3, 4],[5, 6]])
A_t = A.TA_t
array([[1, 3, 5],[2, 4, 6]])
我们可以通过以下代码得到矩阵的维度信息:
A.shape
(3, 2)
A_t.shape
(2, 3)
矩阵相加(Addition)
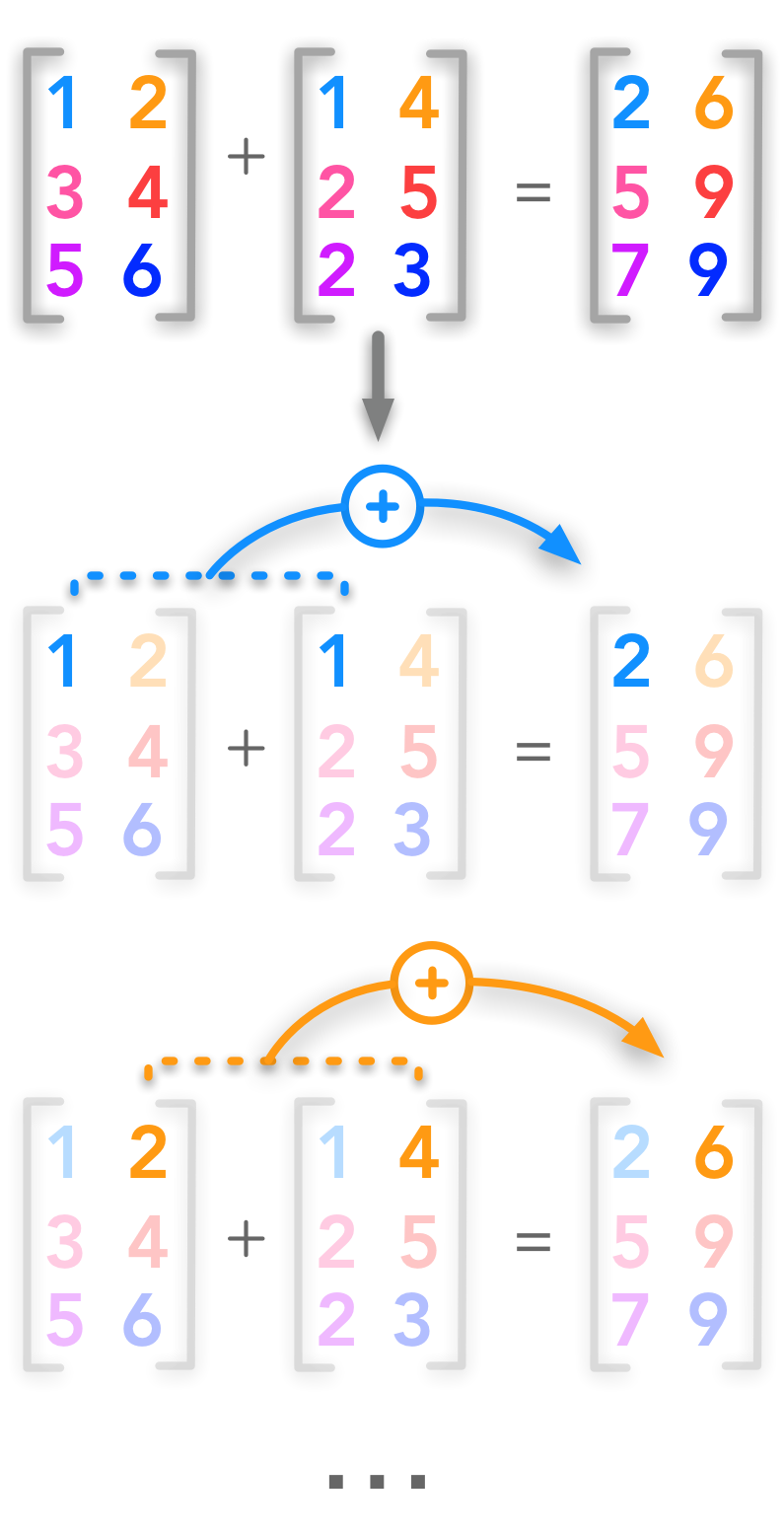
两个矩阵可以相加的条件是它们有相同的形状:
A矩阵的每个元素与B矩阵对应位置上的元素相加,得到的矩阵C与矩阵A、B的拥有同样的形状:
例 3
创建两个矩阵A、B,求矩阵之和
A = np.array([[1, 2], [3, 4], [5, 6]])A
array([[1, 2],[3, 4],[5, 6]])
B = np.array([[2, 5], [7, 4], [4, 3]])B
array([[2, 5],[7, 4],[4, 3]])
# Add matrices A and BC = A + BC
array([[ 3, 7],[10, 8],[ 9, 9]])
标量和矩阵相加也是可行的,意味着标量和矩阵中的每个元素相加:
例 5
标量和矩阵相加:
A
array([[1, 2],[3, 4],[5, 6]])
# Exemple: Add 4 to the matrix AC = A+4C
array([[ 5, 6],[ 7, 8],[ 9, 10]])
Numpy可以处理不同形状的数组之间的运算,较小的数组会被扩充至较大的数组的形状;扩充操作由C语言代码实现,因此有较高的效率。事上上,在例5中有广播机制的参与,标量被扩充至和矩阵A一样的形状。
下面是一个更为普遍的例子:
等价于
对矩阵的一列进行复制后,(31)的矩阵被扩充为(32)的矩阵;如果形状符合广播规则,Mumpy将自动操作。
例 6
将两个不同形状的矩阵相加
A = np.array([[1, 2], [3, 4], [5, 6]])A
array([[1, 2],[3, 4],[5, 6]])
B = np.array([[2], [4], [6]])B
array([[2],[4],[6]])
# BroadcastingC=A+BC
rray([[ 3, 4],[ 7, 8],[11, 12]])
关于矩阵的更多基本操作,请点击这里。

若有收获,就点个赞吧
0 人点赞
