Debugging and Visualisation in PyTorch using Hooks

PyTorch 101, Part 5: Understanding Hooks
PyTorch 101, Part 5: Understanding Hooks
In this post, we cover debugging and Visualisation in PyTorch. We go over PyTorch hooks and how to use them to debug our backpass, visualise activations and modify gradients.
Currently, a research assistant at IIIT-Delhi working on representation learning in Deep RL. Ex - Mathworks, DRDO.
More posts by Ayoosh Kathuria.

Ayoosh Kathuria
7 Jul 2019 • 8 min read
Hello readers. Welcome to our tutorial on debugging and Visualisation in PyTorch. This is, for at least now, is the last part of our PyTorch series start from basic understanding of graphs, all the way to this tutorial.
In this tutorial we will cover PyTorch hooks and how to use them to debug our backward pass, visualise activations and modify gradients.
Before we begin, let me remind you this Part 5 of our PyTorch series.
- Understanding Graphs, Automatic Differentiation and Autograd
- Building Your First Neural Network
- Going Deep with PyTorch
- Memory Management and Using Multiple GPUs
- Understanding Hooks
You can get all the code in this post, (and other posts as well) in the Github repo here.
Understanding PyTorch Hooks
Hooks in PyTorch are severely under documented for the functionality they bring to the table. Consider them like the the Doctor Fate of the superheroes. Haven’t heard of him? Exactly. That’s the point.
One of the reason I like hooks so much is that they provide you to do things during backpropagation. A hook is like a one of those devices that many heroes leave behind in the villain’s den to get all the information.
You can register a hook on a Tensor or a nn.Module. A hook is basically a function that is executed when the either forward or backward is called.
When I say forward, I don’t mean the forward of a nn.Module . forward function here means the forward function of the torch.Autograd.Function object that is the grad_fn of a Tensor. Last line seem gibberish to you? I recommend you to please checkout our article on computation graph in PyTorch. If you are just being lazy, then understand every tensor has a grad_fn which is the torch.Autograd.Function object which created the tensor. For example, if a tensor is created by tens = tens1 + tens2, it’s grad_fn is AddBackward. Still doesn’t make sense? You should definitely go back and read this article.
Notice, that a nn.Module like a nn.Linear has multiple forward invocations. It’s output is created by two operations, (Y = W * X + B), addition and multiplication and thus there will be two forward calls. This can mess things up, and can lead to multiple outputs. We will touch this in more detail later in this article.
PyTorch provides two types of hooks.
- The Forward Hook
- The Backward Hook
A forward hook is executed during the forward pass, while the backward hook is , well, you guessed it, executed when the backward function is called. Time to remind you again, these are the forward and backward functions of an Autograd.Function object.
Hooks for Tensors
A hook is basically a function, with a very specific signature. When we say a hook is executed, in reality, we are talking about this function being executed.
For tensors, the signature for backward hook is,
hook(grad) -> Tensor or None
There is no forward hook for a tensor.
grad is basically the value contained in the grad attribute of the tensor after backward is called. The function is not supposed modify it’s argument. It must either return None or a Tensor which will be used in place of grad for further gradient computation. We provide an example below.
import torcha = torch.ones(5)a.requires_grad = Trueb = 2*ab.retain_grad() # Since b is non-leaf and it's grad will be destroyed otherwise.c = b.mean()c.backward()print(a.grad, b.grad)# Redo the experiment but with a hook that multiplies b's grad by 2.a = torch.ones(5)a.requires_grad = Trueb = 2*ab.retain_grad()b.register_hook(lambda x: print(x))b.mean().backward()print(a.grad, b.grad)
There are several uses of functionality as above.
- You can print the value of gradient for debugging. You can also log them. This is especially useful with non-leaf variables whose gradients are freed up unless you call
retain_gradupon them. Doing the latter can lead to increased memory retention. Hooks provide much cleaner way to aggregate these values. - You can modify gradients during the backward pass. This is very important. While you can still access the the
gradvariable of a tensor in a network, you can only access it after the entire backward pass has been done. For example, let us consider what we did above. We multipliedb‘s gradient by 2, and now the subsequent gradient calculations, like those ofa(or any tensor that will depend uponbfor gradient) use the 2 grad(b) instead of grad(b). In contrast, had we individually updated the parameters *after thebackward, we’d have to multiplyb.gradas well asa.grad(or infact, all tensors that depend onbfor gradient) by 2.
a = torch.ones(5)a.requires_grad = Trueb = 2*ab.retain_grad()b.mean().backward()print(a.grad, b.grad)b.grad *= 2print(a.grad, b.grad) # a's gradient needs to updated manually
Hooks for nn.Module objects
For nn.Module object, the signature for the hook function,
hook(module, grad_input, grad_output) -> Tensor or None
for the backward hook, and
hook(module, input, output) -> None
for the forward hook.
Before we begin, let me make it clear that I’m not a fan of using hooks on nn.Module objects. First, because they force us to break abstraction. A nn.Module is supposed to be a modularised object representing a layer. However, a hook is subjected a forward and a backward, of which there can be an arbitrary number in a nn.Module object. This requires me to know the internal structure of the modularised object.
For example, a nn.Linear involves two forward calls during it’s execution. Multiplication and Addition ( y = w * x + b). This is why the input to the hook function can be a tuple containing the inputs to two different forward calls and output s the output of the forward call.
grad_input is the gradient of the input of nn.Module object w.r.t to the loss (dL / dx, dL / dw, dL / b). grad_output is the gradient of the output of the nn.Module object w.r.t to the gradient. These can be pretty ambiguous for the reason of multiple calls inside a nn.Module object.
Consider the following code.
import torchimport torch.nn as nnclass myNet(nn.Module):def __init__(self):super().__init__()self.conv = nn.Conv2d(3,10,2, stride = 2)self.relu = nn.ReLU()self.flatten = lambda x: x.view(-1)self.fc1 = nn.Linear(160,5)def forward(self, x):x = self.relu(self.conv(x))return self.fc1(self.flatten(x))net = myNet()def hook_fn(m, i, o):print(m)print("------------Input Grad------------")for grad in i:try:print(grad.shape)except AttributeError:print ("None found for Gradient")print("------------Output Grad------------")for grad in o:try:print(grad.shape)except AttributeError:print ("None found for Gradient")print("\n")net.conv.register_backward_hook(hook_fn)net.fc1.register_backward_hook(hook_fn)inp = torch.randn(1,3,8,8)out = net(inp)(1 - out.mean()).backward()
The output produced is.
Linear(in_features=160, out_features=5, bias=True)------------Input Grad------------torch.Size([5])torch.Size([5])------------Output Grad------------torch.Size([5])Conv2d(3, 10, kernel_size=(2, 2), stride=(2, 2))------------Input Grad------------None found for Gradienttorch.Size([10, 3, 2, 2])torch.Size([10])------------Output Grad------------torch.Size([1, 10, 4, 4])
In the code above, I use a hook to print the shapes of grad_input and grad_output. Now my knowledge about this may be limited, and please do comment if you have a alternative, but for the love of pink floyd, I cannot figure out what grad_input is supposed to represent what?
In conv2d you can guess by shape. The grad_input of size [10, 3, 3, 2] is the grad of weights. That of [10] is maybe bias. But what about grad of input feature maps. None? Add to that Conv2d uses im2col or it’s cousin to flatten an image such that convolutional over the whole image can be done through matrix computation and not looping. Were there any backward calls there. So in order to get the gradient of x, I’ll have to call the grad_output of layer just behind it?
The linear is baffling. Both the grad_inputs are size [5] but shouldn’t the weight matrix of the linear layer be 160 x 5.
For such confusion I’m not a fan of using hooks with nn.Modules. You could do it for simple things like ReLU, but for complicated things? Not my cup of tea.
Proper Way of Using Hooks : An Opinion
So, I’m all up for using hooks on Tensors. Using named_parameters functions, I’ve been successfully been able to accomplish all my gradient modifying / clipping needs using PyTorch. named_parameters allows us much much more control over which gradients to tinker with. Let’s just say, I wanna do two things.
- Turn gradients of linear biases into zero while backpropagating.
- Make sure that for no gradient going to conv layer is less than 0.
import torchimport torch.nn as nnclass myNet(nn.Module):def __init__(self):super().__init__()self.conv = nn.Conv2d(3,10,2, stride = 2)self.relu = nn.ReLU()self.flatten = lambda x: x.view(-1)self.fc1 = nn.Linear(160,5)def forward(self, x):x = self.relu(self.conv(x))x.register_hook(lambda grad : torch.clamp(grad, min = 0)) #No gradient shall be backpropagated#conv outside less than 0# print whether there is any negative gradx.register_hook(lambda grad: print("Gradients less than zero:", bool((grad < 0).any())))return self.fc1(self.flatten(x))net = myNet()for name, param in net.named_parameters():# if the param is from a linear and is a biasif "fc" in name and "bias" in name:param.register_hook(lambda grad: torch.zeros(grad.shape))out = net(torch.randn(1,3,8,8))(1 - out).mean().backward()print("The biases are", net.fc1.bias.grad) #bias grads are zero
The output produced is:
Gradients less than zero: FalseThe biases are tensor([0., 0., 0., 0., 0.])
The Forward Hook for Visualising Activations
If you noticed, the Tensor doesn’t have a forward hook, while nn.Module has one, which is executed when a forward is called. Notwithstanding the issues I already highlighted with attaching hooks to PyTorch, I’ve seen many people use forward hooks to save intermediate feature maps by saving the feature maps to a python variable external to the hook function. Something like this.
visualisation = {}inp = torch.randn(1,3,8,8)def hook_fn(m, i, o):visualisation[m] = onet = myNet()for name, layer in net._modules.items():layer.register_forward_hook(hook_fn)out = net(inp)
Generally, the output for a nn.Module is the output of the last forward. However, the above functionality can be safely replicated by without use of hooks. Just simply append the intermediate outputs in the forward function of nn.Module object to a list. However, it might be a bit problematic to print the intermediate activation of modules inside nn.Sequential. To get past this, we need to register a hook to children modules of the Sequential but not the to Sequential itself.
import torchimport torch.nn as nnclass myNet(nn.Module):def __init__(self):super().__init__()self.conv = nn.Conv2d(3,10,2, stride = 2)self.relu = nn.ReLU()self.flatten = lambda x: x.view(-1)self.fc1 = nn.Linear(160,5)self.seq = nn.Sequential(nn.Linear(5,3), nn.Linear(3,2))def forward(self, x):x = self.relu(self.conv(x))x = self.fc1(self.flatten(x))x = self.seq(x)net = myNet()visualisation = {}def hook_fn(m, i, o):visualisation[m] = odef get_all_layers(net):for name, layer in net._modules.items():#If it is a sequential, don't register a hook on it# but recursively register hook on all it's module childrenif isinstance(layer, nn.Sequential):get_all_layers(layer)else:# it's a non sequential. Register a hooklayer.register_forward_hook(hook_fn)get_all_layers(net)out = net(torch.randn(1,3,8,8))# Just to check whether we got all layersvisualisation.keys() #output includes sequential layers
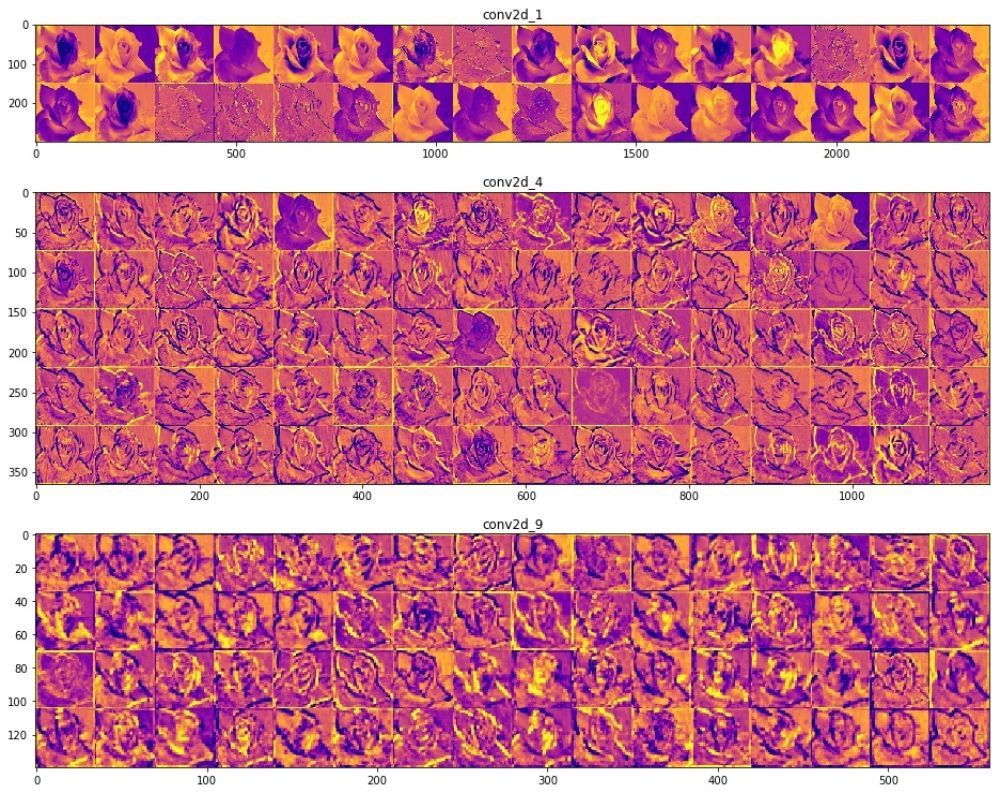
Finally, you can turn this tensors into numpy arrays and plot activations.
Conclusion
That wraps up our discussion on PyTorch, an unreasonable effective tool in visualising and debugging the back pass. Hope this article would help you in solving your bugs much quicker.
More in PyTorch
24 Jan 2020 – 14 min read
30 Oct 2019 – 7 min read
27 Jun 2019 – 11 min read

[
Announcement
Train ML Models on Free Cloud GPUs ⚡
When we started Paperspace back in 2014, our mission was to make cloud GPU resources more accessible and less expensive for everyone. Since inception, we have continued to offer a
](/free-cloud-gpu/)
- Moses M. Feaster

Moses M. Feaster 16 Jul 2019 • 2 min read

[
Tutorial
PyTorch 101, Part 4: Memory Management and Using Multiple GPUs
This article covers PyTorch’s advanced GPU management features, including how to multiple GPU’s for your network, whether be it data or model parallelism. We conclude with best practises for debugging memory error.
](/pytorch-memory-multi-gpu-debugging/)
- Ayoosh Kathuria
Ayoosh Kathuria 27 Jun 2019 • 11 min read
Paperspace Blog © 2020
Latest Posts Facebook Twitter Ghost
Try Paperspace for free
Sign Up
https://blog.paperspace.com/pytorch-hooks-gradient-clipping-debugging/

若有收获,就点个赞吧
0 人点赞
