一、加锁规则
innodb存储引擎加锁规则可以总结为两个原则、两个优化、一个bug,这个规则仅限于当前最新版本,即5.x系列 <= 5.7.24,8.0系列 <= 8.0.13
原则一:加锁的基本单位是临键锁next-key lock,临键锁是前开后闭区间。
原则二:查找过程中访问到的对象才会加锁
优化一:索引上的等值查询,给唯一索引加锁的时候,临键锁会退化为行锁。
优化二:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,临键锁会退化为间隙锁。
一个bug:唯一索引上的范围查询会访问到不满足条件的第一个值为止
1.1、案例分析

案例一:唯一索引等值查询间隙锁
| 事务A | 事务B | 事务C |
|---|---|---|
| begin; update user set money = 10 where id = 3; |
||
| insert into user values(2,’牛魔王’,20,20); 阻塞 |
||
| update user set money = 10 where id = 4; 成功 |

事务A:更新 id = 3 的记录
根据原则一,加锁的基本单位是临键锁,所以锁住区间是(1,4]
根据优化二,索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,临键锁会退化为间隙锁,所以退化为(1,4)
事务B:写入id = 2的记录
因为(1,4)区间被锁,所以事务B被阻塞。
事务C:更新id = 4的记录
因为(1,4)区间被锁,是开区间,所以事务C可正常执行。
案例二:唯一索引等值查询行锁
| 事务A | 事务B | 事务C |
|---|---|---|
| begin; update user set money = 10 where id = 4; |
||
| insert into user values(2,’牛魔王’,20,20); 成功 |
||
| update user set money = 10 where id = 4; 阻塞 |

事务A:更新 id = 4 的记录
根据原则一,加锁的基本单位是临键锁,所以锁住区间是(1,4]
根据优化二,索引上的等值查询,给唯一索引加锁的时候,临键锁会退化为行锁,所以退化为 4
事务B:写入id = 2的记录
因为记录id = 4被锁,所以事务B执行成功。
事务C:更新id = 4的记录
因为记录id = 4被锁,所以事务C被阻塞。
案例三:非唯一索引等值锁
| 事务A | 事务B | 事务C |
|---|---|---|
| begin; select id from user where age = 40 lock in share mode |
||
| update user set money = 400 where id = 4; 成功 |
||
| insert into user values(5,’如来佛祖’,50,50); 阻塞 |

事务A:对 age = 40 的记录加乐观锁
根据原则一,加锁的基本单位是临键锁,所以锁住区间是(10,40]
但是age为普通索引,因此访问到age = 40这一条记录不会停下来,需要继续向右访问,直到访问到age = 70才停止,索引锁区间就变成了(40,70]
根据优化二,等值判断,不满足条件,所以退化成间隙锁(40, 70)
根据原则二,只有访问到的对象才会加锁,这个查询使用的是覆盖索引,并不需要访问主键索引,所以主键的索引树不会加锁,所以事务B可以执行成功。
事务B:更新id = 4的记录
由于主键的索引树不会加锁,所以事务B可以执行成功。
事务C:写入id = 5的记录
应为事务A锁住的age区间是(10,40]、(40,70),所以事务C被阻塞。
注意:
- 锁是加在索引上的;
- 在用lock in share mode来给行加读锁避免数据被更新的话,就必须得绕过覆盖索引的优化,例如用select * from
案例四:主键索引范围锁
| 事务A | 事务B | 事务C | | —- | —- | —- | | begin;select * from user where id = 4 for update;select * from user where id >= 4 and id < 5 for update;问:这两句sql加锁效果一样吗?
select * from user where id >= 4 and id < 5 for update; | | | | | insert into user values(2,’如来佛祖’,20,20);
成功
insert into user values(8,’观音’,80,80);
成功
insert into user values(5,’如来佛祖’,50,50);
阻塞 | | | | | update user set money = 400 where id = 7;
阻塞 |

事务A:select * from user where id >= 4 and id < 5 for update
根据原则一,加锁的基本单位是临键锁,所以锁住区间是(1,4]
根据优化一,主键id上的等值查询,退化成行锁,所以只加 id = 4这一行的记录
范围查找就继续往后查,找到id = 7这一行停止,加临键锁(4,7]
由于后面没有等值判断,所以最终加锁范围为 id = 4的行锁和(4,7]的临键锁,而id < 5, 5这列并不存在。所以对最后的锁区间没有影响。
案例五:非唯一索引范围锁
| 事务A | 事务B | 事务C |
|---|---|---|
| begin; select * from user where age >= 40 and age < 50 for update; |
||
| insert into user values(2,’如来佛祖’,20,20); 阻塞 |
||
| update user set money = 400 where age = 70; 阻塞 |

事务A:select * from user where age >= 40 and age < 50 for update;
根据原则一,加锁的基本单位是临键锁,所以锁住区间是(10,40]
由于索引是非唯一索引,没有优化原则,也就不会变为行锁
继续往后扫描,加临键锁(40,70]
所以最终的加锁范围是(10,40]、(40,70]两把临键锁
案例六:唯一索引范围锁bug
| 事务A | 事务B | 事务C |
|---|---|---|
| begin; select * from user where id > 4 and id <= 7 for update; |
||
| insert into user values(8,’如来佛祖’,20,20); 阻塞 |
||
| update user set money = 400 where id = 10; 阻塞 |

事务A:select * from user where id > 4 and id <= 7 for update;
根据原则一,加锁的基本单位是临键锁,所以锁住区间是(4,7],因为id是唯一键,所以判断id = 7这一行就应该停止,但是innodb往后扫描到了第一个不满足条件的行为止,也就是id=10,所以最终的加锁为
(4,7]、(7,10]
官方bug系统上提到了这个问题,但是并未被认证修复
案例七:非唯一索引上存在等值的例子
写入一条sql语句insert into user values(15,’如来佛祖’,40,20),age索引如下。
| 事务A | 事务B | 事务C |
|---|---|---|
| begin; delete from user where age = 40; |
||
| insert into user values(8,’如来佛祖’,20,20); 阻塞 insert into user values(8,’如来佛祖’,90,90); 阻塞 |
||
| insert into user values(12,’如来佛祖’,80,80); 成功 insert into user values(2,’如来佛祖’,80,80); 成功 insert into user values(5,’如来佛祖’,80,80); 成功 update user set money = 400 where id = 7; 成功 update user set money = 400 where id = 4; 阻塞 |


根据演示结果,得出加锁范围age为(10-70)的开区间。
对比:如果删除语句加上limit
| 事务A | 事务B |
|---|---|
| begin; delete from user where age = 40 limit 2; |
|
| insert into user values(8,’如来佛祖’,20,20); 阻塞 insert into user values(8,’如来佛祖’,50,50); 成功 |

事务A的delete语句加了limit 2,而表中只有两条符合条件的数据,加limit 2与不加limit 2删除的效果是一样的,但是加锁的效果却不同,通过案例演示发现,age的加锁范围为(10,40],sql扫描到两条符合记录的时候就停止了继续向后扫描。加锁区间如下图所示。所以在删除数据的时候尽量加limit,这样可以控制删除的条数,也能减小加锁范围。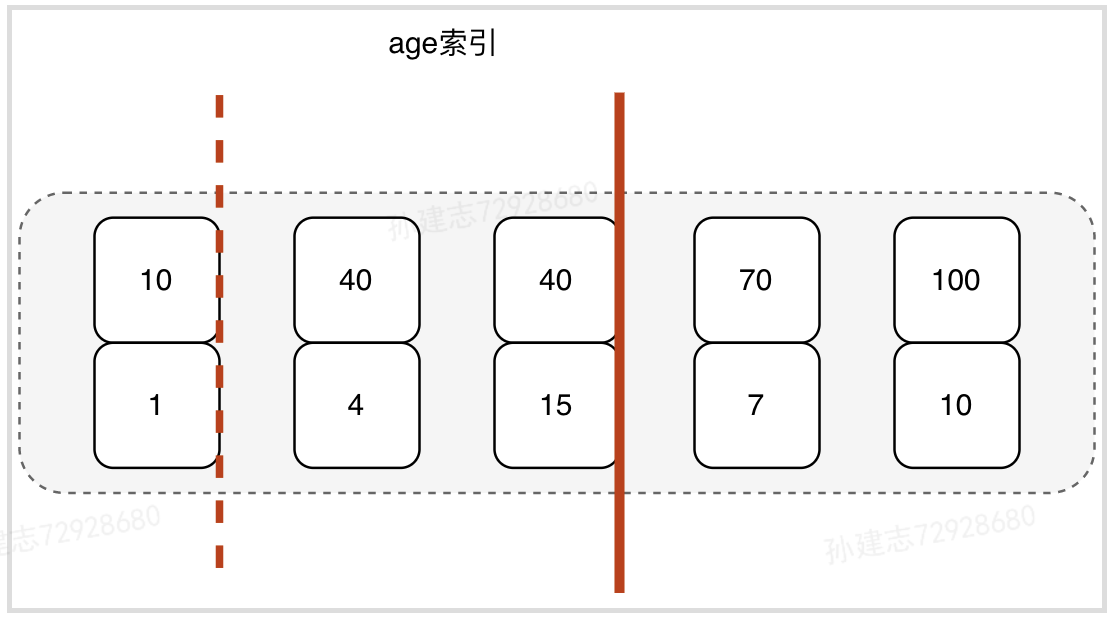
二、死锁
| 事务A | 事务B |
|---|---|
| begin; select * from user where id = 4 for update; |
|
| update user set money = 40000 where age = 40; 阻塞 |
|
| insert into user values(2,’如来’,20,20); |

------------------------
LATEST DETECTED DEADLOCK
------------------------
2022-03-11 10:18:27 0x7000093dc000
*** (1) TRANSACTION:
TRANSACTION 18941, ACTIVE 7 sec starting index read
-- 事务18941,活跃7sec,正在根据索引读数据
mysql tables in use 1, locked 1
--当前事务使用一个表,表上有一把锁(lock_ix)意向排他锁
LOCK WAIT 3 lock struct(s), heap size 1136, 2 row lock(s)
--LOCK WAIT表示正在等待锁,3 lock struct(s)表示 trx->trx_locks 锁链表的长度为3,每个链表节点代表该事务持有的一个锁结构,包括表锁,记录锁以及自增锁等
-- 2 row lock 表示两行被锁定
MySQL thread id 13, OS thread handle 123145457631232, query id 382 localhost root updating
update user set money = 40000 where age = 40
--执行的sql语句
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 49 page no 3 n bits 80 index PRIMARY of table `test`.`user` trx id 18941 lock_mode X locks rec but not gap waiting
Record lock, heap no 10 PHYSICAL RECORD: n_fields 6; compact format; info bits 0
--等待记录锁
0: len 4; hex 00000004; asc ;;
1: len 6; hex 0000000049ef; asc I ;;
2: len 7; hex a1000001120110; asc ;;
3: len 9; hex e5ad99e6829fe7a9ba; asc ;;
4: len 4; hex 80000028; asc (;;
5: len 4; hex 80000028; asc (;;
*** (2) TRANSACTION:
TRANSACTION 18940, ACTIVE 10 sec inserting
mysql tables in use 1, locked 1
3 lock struct(s), heap size 1136, 2 row lock(s), undo log entries 1
MySQL thread id 12, OS thread handle 123145457352704, query id 383 localhost root update
insert into user values(2,'如来',20,20)
-- 执行的sql语句
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 49 page no 3 n bits 80 index PRIMARY of table `test`.`user` trx id 18940 lock_mode X locks rec but not gap
Record lock, heap no 10 PHYSICAL RECORD: n_fields 6; compact format; info bits 0
-- 锁住的是一个索引,不是范围
0: len 4; hex 00000004; asc ;;
1: len 6; hex 0000000049ef; asc I ;;
2: len 7; hex a1000001120110; asc ;;
3: len 9; hex e5ad99e6829fe7a9ba; asc ;;
4: len 4; hex 80000028; asc (;;
5: len 4; hex 80000028; asc (;;
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 49 page no 4 n bits 80 index idx_age of table `test`.`user` trx id 18940 lock_mode X locks gap before rec insert intention waiting
Record lock, heap no 6 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
--表示事务 2 的 insert 语句正在等待插入意向锁 lock_mode X locks gap before rec insert intention waiting ( LOCK_X + LOCK_REC_gap )
0: len 4; hex 80000028; asc (;;
1: len 4; hex 00000004; asc ;;
*** WE ROLL BACK TRANSACTION (1)
事务A:
select * from user where id = 4 for update;
—最终锁住id = 4的索引记录,加记录锁。
事务B:
update user set money = 40000 where age = 40;
— 对age为(10,40)的区间加锁,在获取40的行锁阻塞
事务A:
写入的时候需要获取(10,40)的间隙,由于被事务B占用,所以等待。
2.1、概念
死锁是指两个或两个以上的事务在执行过程中,因争夺锁资源而造成的一种互相等待的现象
2.2、解决死锁方案
- 遇等待回滚解决死锁最简单的办法就是不要有等待,当遇到任何等待的时候,选择回滚事务,这是解决死锁最简单的办法,但是同样会产生很严重的性能问题,事务回滚之后需要重试,问题很难被发现而且浪费资源。
- 超时即当两个事务相互等待时,当一个等待时间超过设置的某一阈值时,将其中一个事务进行回滚,另一个等待的事务就能继续执行,在innodb存储引擎中,通过参数innodb_lock_wait_timeout设置超时等待时间,单位为秒。(show variables like “Innodb_lock_wait_timeout”; set Innodb_lock_wait_timeout = 500;)
死锁检测超时机制虽然简单,但是仅通过超时机制来处理,可能会得不偿失,假如事务更新了很多行,占用了较多的undo log,超时的话就需要对undo log进行回滚,可能回滚这个事务的时间相对于另一个事务所占用的时间更长。因此除了超时机制,数据库普遍采用wait-for graph(等待图)的方式来进行死锁检测,目前innodb存储引擎也采用此种方式进行死锁检测。wait-for graph会要求数据库保存以下两种信息。1、锁的信息链表2、事务等待链表
2.2.1、死锁检测原理

在transaction wait list中可以看到共有四个事务t1、t2、t3、t4,估在wait-for graph中共有四个节点
row1:t2持有row1的x锁,t1准备获取row1的s锁,等待t2的x锁释放
row2:t1、t2持有row2的s锁,t2等待获取row2的x锁,等待t1释放s锁
最终如下图所示。发现wait-for graph出现回路,证明存在死锁,wait-for graph通过深度优先算法实现死锁的检测,若发现死锁,innodb存储引擎通常选择回滚undo量最小的事务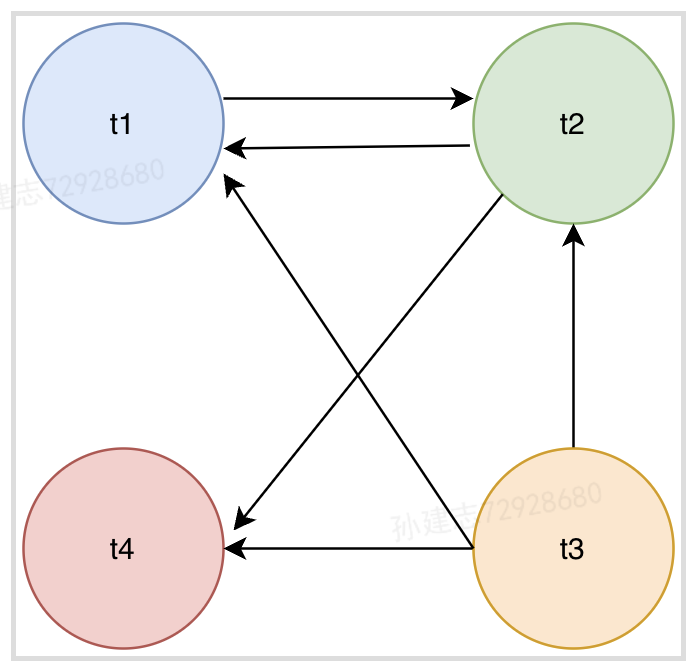
2.3、死锁防御
合理的索引设计,区分度高的列放到组合索引前面,使业务sql通过索引定位到更少的行,减少锁竞争。
- 调整业务逻辑 SQL 执行顺序, 避免长时间持有锁的 SQL 在事务前面。
- 避免大事务,尽量将大事务拆成多个小事务来处理,小事务发生锁冲突的几率也更小。
- 以固定的顺序访问表和行。比如两个更新数据的事务,事务 A 更新数据的顺序为 1,2;事务 B 更新数据的顺序为 2,1。这样更可能会造成死锁。
- 在并发比较高的系统中,尽量不要显式加锁,特别是是在事务里显式加锁。如 select … for update 语句。
- 尽量按主键/索引去查找记录,范围查找增加了锁冲突的可能性,也不要利用数据库做一些额外额度计算工作(可能会导致锁表)。
- 优化 SQL 和表设计,减少同时占用太多资源的情况。比如说,减少连接的表,将复杂 SQL 分解为多个简单的 SQL。

若有收获,就点个赞吧
0 人点赞
