统一资源标识符(Uniform Resource Identifier)用于标记服务器上的资源。因为它经常出现在浏览器的地址栏里,所以俗称为“网络地址”,简称“网址”。
严格地说,URI 不完全等同于网址,它包含有 URL 和 URN 两个部分,在 HTTP 世界里用的网址实际上是 URL——统一资源定位符(Uniform Resource Locator)。但因为 URL 实在是太普及了,所以常常把这两者简单地视为相等。
URI的格式
这里需要注意:URI不仅能标识万维网资源,也可以标记其他的,比如邮件系统、本地文件系统等资源。而“资源”既可以是存在磁盘上的静态文本、页面数据,也可以是由 Java、PHP 提供的动态服务。
下面的这张图显示了 URI 最常用的形式,由 scheme、host:port、path 和 query 四个部分组成,但有的部分可以视情况省略。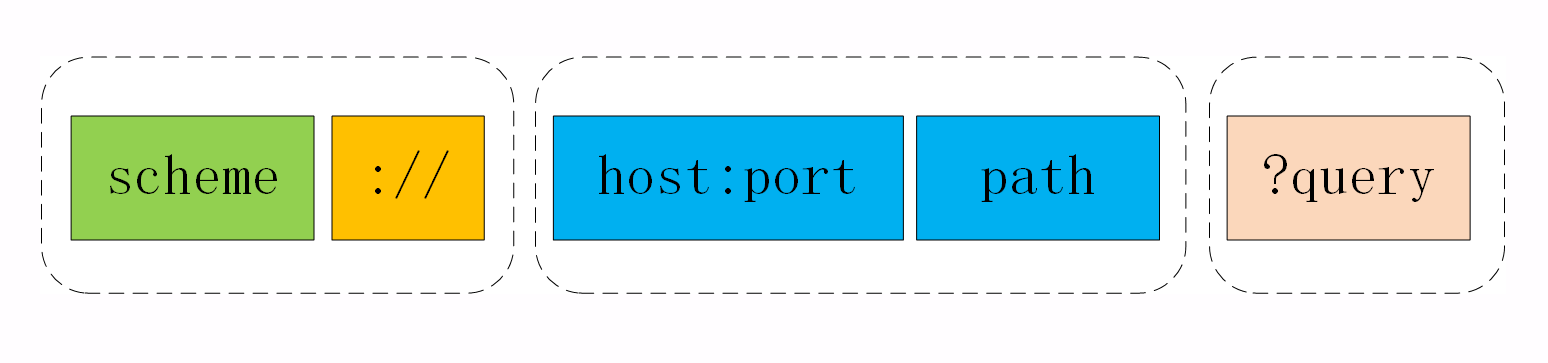
URI的基本组成
URI 第一个组成部分叫 scheme,翻译成中文叫“方案名”或者“协议名”,表示资源应该使用哪种协议来访问。
最常见的就是http,还有https,除此以外还有ftp、file等。
浏览器或应用程序看到URI中的scheme,就会调用相应的HTTP或者HTTPS下层API。
在scheme之后,必须接三个特定字符 “://”,它把scheme和后面区分开。
在 “://” 之后,是被称为“authority”的部分,表示资源所在的主机名,通常的形式是“host:port”,即主机名加端口号。
主机名可以是IP地址或者域名,必须要有,否则浏览器会找不到服务器。端口号可以省略,浏览器会根据协议访问默认端口。http默认端口是80,https默认端口是443。
再之后是path,标记资源所在位置,URI 里 path 采用了类似文件系统“目录”“路径”的表示方式,因为早期互联网上的计算机多是 UNIX 系统,所以采用了 UNIX 的“/”风格。
这里注意,URI 的 path 部分必须以“/”开始,也就是必须包含“/”,不要把“/”误认为属于前面 authority。
URI的查询参数
使用“协议名 + 主机名 + 路径”的方式,就可以精确定位网络上的任何资源了。但这还不够,很多时候我们还想在操作资源的时候附加一些额外的修饰参数。
举几个例子:获取商品图片,但想要一个 32×32 的缩略图版本;获取商品列表,但要按某种规则做分页和排序;跳转页面,但想要标记跳转前的原始页面。
仅用“协议名 + 主机名 + 路径”的方式是无法适应这些场景的,所以 URI 后面还有一个“query”部分,它在 path 之后,用一个“?”开始,但不包含“?”,表示对资源附加的额外要求。
查询参数 query 有一套自己的格式,是多个“key=value”的字符串,这些 KV 值用字符“&”连接,浏览器和服务器都可以按照这个格式把长串的查询参数解析成可理解的字典或关联数组形式。
http://www.chrono.com:8080/11-1?uid=1234&name=mario&referer=xxx
如下的添加query参数的URI,Chrome浏览器解码出query中的KV对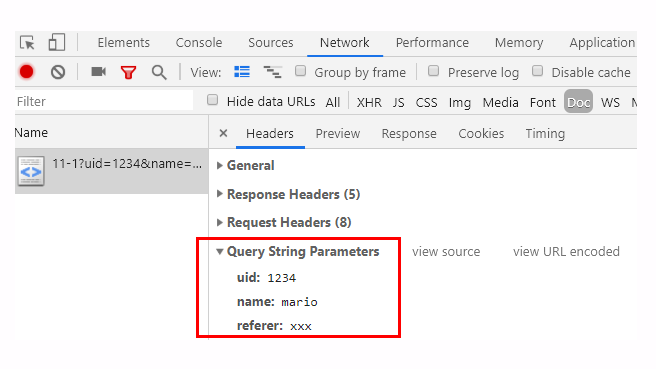
URI的编码
我们经常会在浏览器的地址栏里看见很多很长很复杂的字符串,这是因为URI里只能使用ASCII。
如果我们使用了除英语外的其他语言或者是 “@&” 等特殊字符,URI为了处理这些特殊字符,会对其进行转义,例如空格被转义成“%20”,“?”被转义成“%3F”。而中文、日文等则通常使用 UTF-8 编码后再转义,例如“银河”会被转义成“%E9%93%B6%E6%B2%B3”。
小结:
- URI 是用来唯一标记服务器上资源的一个字符串,通常也称为 URL;
- URI 通常由 scheme、host:port、path 和 query 四个部分组成,有的可以省略;
- scheme 叫“方案名”或者“协议名”,表示资源应该使用哪种协议来访问;
- “host:port”表示资源所在的主机名和端口号;
- path 标记资源所在的位置;
- query 表示对资源附加的额外要求;
- 在 URI 里对“@&/”等特殊字符和汉字必须要做编码,否则服务器收到 HTTP 报文后会无法正确处理。

若有收获,就点个赞吧
0 人点赞
