报文结构
HTTP 协议的请求报文和响应报文的结构基本相同,由三大部分组成:
- 起始行(start line):描述请求或响应的基本信息;
- 头部字段集合(header):使用 key-value 形式更详细地说明报文;
- 消息正文(entity):实际传输的数据,它不一定是纯文本,可以是图片、视频等二进制数据。
这其中前两部分起始行和头部字段经常又合称为“请求头”或“响应头”,消息正文又称为“实体”,但与“header”对应,很多时候就直接称为“body”。
HTTP 协议规定报文必须有 header,但可以没有 body,而且在 header 之后必须要有一个“空行”,也就是“CRLF”,十六进制的“0D0A”。所以,一个完整的 HTTP 报文就像是下图的这个样子,注意在 header 和 body 之间有一个“空行”。
请求行
了解了 HTTP 报文的基本结构后,我们来看看请求报文里的起始行也就是请求行(request line),它简要地描述了客户端想要如何操作服务器端的资源。
请求行由三部分构成:
- 请求方法:是一个动词,如 GET/POST,表示对资源的操作;
- 请求目标:通常是一个 URI,标记了请求方法要操作的资源;
- 版本号:表示报文使用的 HTTP 协议版本。
这三个部分通常使用空格(space)来分隔,最后要用 CRLF 换行表示结束。
以百度为例: 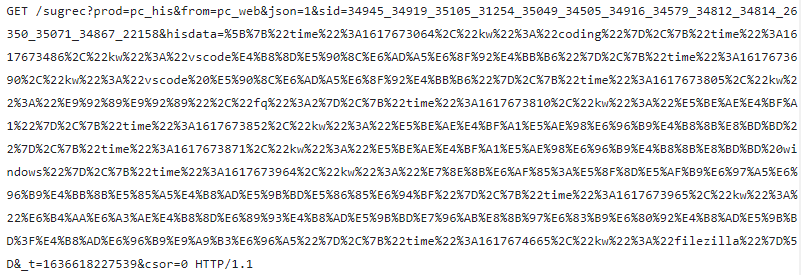 在这个请求行里,“GET”是请求方法,“/…?=0” 一直到结尾“=0”这一长串字符串是请求目标,“HTTP/1.1”是版本号,把这三部分连起来,意思就是“服务器你好,我想获取网站“xxx”位置的文件,我用的协议版本号是 1.1,请不要用 1.0 或者 2.0 回复我。”
在这个请求行里,“GET”是请求方法,“/…?=0” 一直到结尾“=0”这一长串字符串是请求目标,“HTTP/1.1”是版本号,把这三部分连起来,意思就是“服务器你好,我想获取网站“xxx”位置的文件,我用的协议版本号是 1.1,请不要用 1.0 或者 2.0 回复我。”
状态行
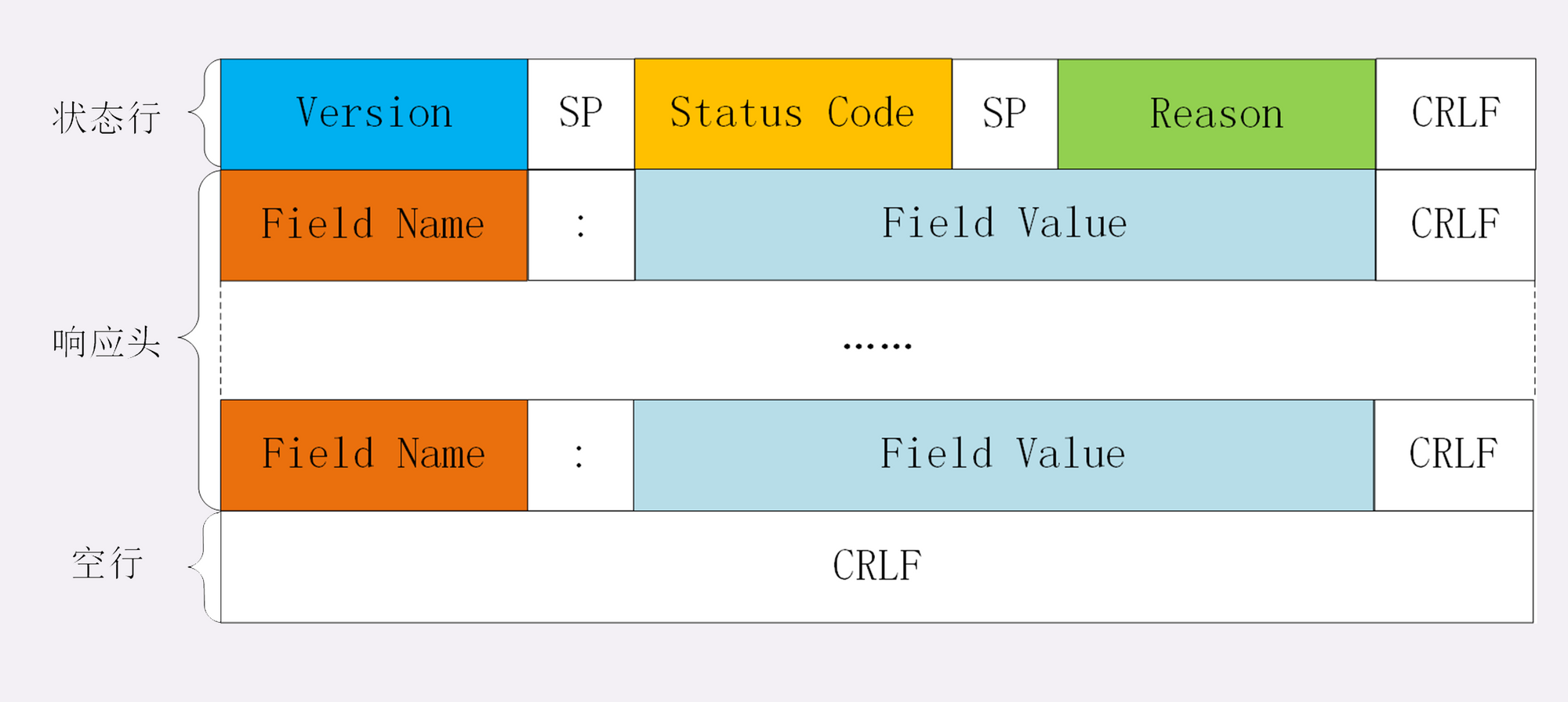
看完了请求行,我们再看响应报文里的起始行,在这里它不叫“响应行”,而是叫“状态行”(status line),意思是服务器响应的状态。
比起请求行来说,状态行要简单一些,同样也是由三部分构成:
- 版本号:表示报文使用的 HTTP 协议版本;
- 状态码:一个三位数,用代码的形式表示处理的结果,比如 200 是成功,500 是服务器错误;
- 原因:作为数字状态码补充,是更详细的解释文字,帮助人理解原因。

依然是以百度为例: 
意思就是:“浏览器你好,我已经处理完了你的请求,这个报文使用的协议版本号是 1.1,状态码是 200,一切 OK。”
头部字段
请求行或状态行再加上头部字段集合就构成了 HTTP 报文里完整的请求头或响应头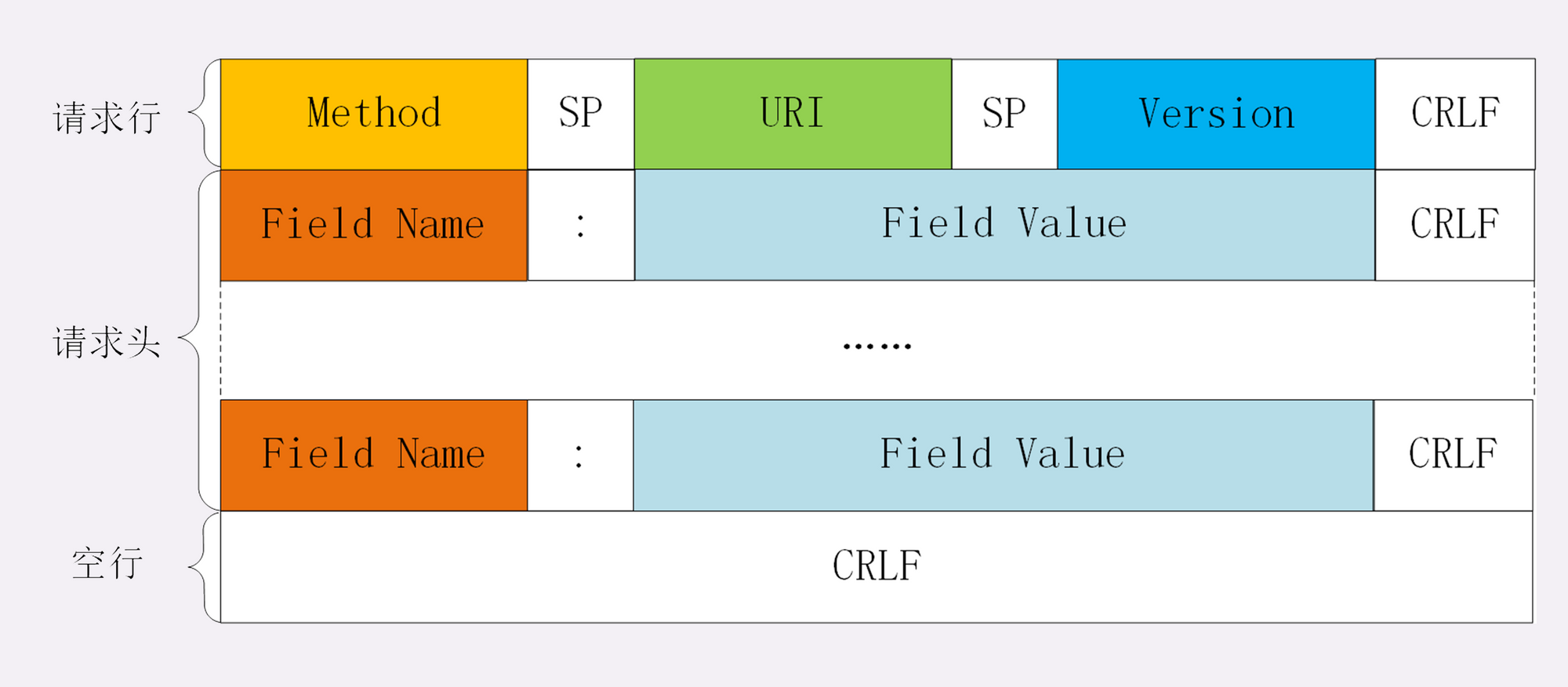
 请求头和响应头的结构是基本一样的,唯一的区别是起始行
请求头和响应头的结构是基本一样的,唯一的区别是起始行
头部字段是 key-value 的形式,key 和 value 之间用“:”分隔,最后用 CRLF 换行表示字段结束。比如在“Host: 127.0.0.1”这一行里 key 就是“Host”,value 就是“127.0.0.1”。
HTTP 头字段非常灵活,不仅可以使用标准里的 Host、Connection 等已有头,也可以任意添加自定义头,这就给 HTTP 协议带来了无限的扩展可能。
不过使用头字段需要注意下面几点:
- 字段名不区分大小写,例如“Host”也可以写成“host”,但首字母大写的可读性更好;
- 字段名里不允许出现空格,可以使用连字符“-”,但不能使用下划线“_”。例如,“test-name”是合法的字段名,而“test name”“test_name”是不正确的字段名;
- 字段名后面必须紧接着“:”,不能有空格,而“:”后的字段值前可以有多个空格;
- 字段的顺序是没有意义的,可以任意排列不影响语义;
- 字段原则上不能重复,除非这个字段本身的语义允许,例如 Set-Cookie。
常用头字段
HTTP 协议规定了非常多的头部字段,实现各种各样的功能,但基本上可以分为四大类:
- 通用字段:在请求头和响应头里都可以出现;
- 请求字段:仅能出现在请求头里,进一步说明请求信息或者额外的附加条件;
- 响应字段:仅能出现在响应头里,补充说明响应报文的信息;
- 实体字段:它实际上属于通用字段,但专门描述 body 的额外信息。
对 HTTP 报文的解析和处理实际上主要就是对头字段的处理,理解了头字段也就理解了 HTTP 报文。
首先要说的是 Host 字段,它属于请求字段,只能出现在请求头里,它同时也是唯一一个 HTTP/1.1 规范里要求必须出现的字段,也就是说,如果请求头里没有 Host,那这就是一个错误的报文。
Host 字段告诉服务器这个请求应该由哪个主机来处理,当一台计算机上托管了多个虚拟主机的时候,服务器端就需要用 Host 字段来选择,有点像是一个简单的“路由重定向”。
例如我们的试验环境,在 127.0.0.1 上有三个虚拟主机:“www.chrono.com”“www.metroid.net”和“origin.io”。那么当使用域名的方式访问时,就必须要用 Host 字段来区分这三个 IP 相同但域名不同的网站,否则服务器就会找不到合适的虚拟主机,无法处理。
User-Agent 是请求字段,只出现在请求头里。它使用一个字符串来描述发起 HTTP 请求的客户端,服务器可以依据它来返回最合适此浏览器显示的页面。
但由于历史的原因,User-Agent 非常混乱,每个浏览器都自称是“Mozilla”“Chrome”“Safari”,企图使用这个字段来互相“伪装”,导致 User-Agent 变得越来越长,最终变得毫无意义。
不过有的比较“诚实”的爬虫会在 User-Agent 里用“spider”标明自己是爬虫,所以可以利用这个字段实现简单的反爬虫策略。
Date 字段是一个通用字段,但通常出现在响应头里,表示 HTTP 报文创建的时间,客户端可以使用这个时间再搭配其他字段决定缓存策略。
Server 字段是响应字段,只能出现在响应头里。它告诉客户端当前正在提供 Web 服务的软件名称和版本号,例如在我们的实验环境里它就是“Server: openresty/1.15.8.1”,即表明使用的是 OpenResty 1.15.8.1。
Server 字段也不是必须要出现的,因为这会把服务器的一部分信息暴露给外界,如果这个版本恰好存在 bug,那么黑客就有可能利用 bug 攻陷服务器。所以,有的网站响应头里要么没有这个字段,要么就给出一个完全无关的描述信息。
小结:
- HTTP 报文结构就像是“大头儿子”,由“起始行 + 头部 + 空行 + 实体”组成,简单地说就是“header+body”;
- HTTP 报文可以没有 body,但必须要有 header,而且 header 后也必须要有空行,形象地说就是“大头”必须要带着“脖子”;
- 请求头由“请求行 + 头部字段”构成,响应头由“状态行 + 头部字段”构成;
- 请求行有三部分:请求方法,请求目标和版本号;
- 状态行也有三部分:版本号,状态码和原因字符串;
- 头部字段是 key-value 的形式,用“:”分隔,不区分大小写,顺序任意,除了规定的标准头,也可以任意添加自定义字段,实现功能扩展;
- HTTP/1.1 里唯一要求必须提供的头字段是 Host,它必须出现在请求头里,标记虚拟主机名。

若有收获,就点个赞吧
0 人点赞
