在今天政府,企业都讲大数据的时代,大数据的价值被充分挖掘。在深入学习大数据庞大的技术家族之前,我们先简单认识大数据。大数据的基本特征有哪些?大数据的基础知识点有哪些?大数据技术的运用方式有哪些?
这篇文章,简单介绍大数据的基础技术,对大数据相关技术的定义,基本特征等内容作简单介绍。在对这些技术学习和理解的过程中,更加认识到大数据技术种类之多,实现之复杂。以写促思,一点点积累,也是进步的一小步。
Google引领大数据技术的三驾马车
首先,我们通过4个”V”来了解大数据的基本特征。Volume(容量大),Variety(种类多),Velocity(速度快),Value(价值大)。过去的互联网搜索和如今的移动互联网应用,都积累了大量的数据。网页内容,用户基本信息和行为记录,及视频/文章/图片等各种形式的数据。
在利用大数据发挥其价值之前,需要有相应可靠的技术,完成海量数据的存储。其次,及时的响应用户的数据需求,为用户提供满意的服务,这需要强大的计算能力来保障。
首先为大数据的存储和计算提供有效解决方案的是Google。在2003年至2006年期间,Google 先后通过三篇论文介绍了布式系统工程实践的三种技术,它们被形象的比喻为三驾马车,带动大数据技术的不断发展。
三驾马车分别是,实现分布式计算的MapReduce,一种列式存储存储系统BigTable,分布式的文件系统GFS。据说,GFS是由Google 创始人佩奇和布林在斯坦福大学攻读博士学位时提出的,试图解决在网页上下载大文件后,访问速度慢点现象。后来,由Google的工程师们,形成了GFS产品。
GFS(Google File System)本质上是一个文件系统,但同时具有高可用性,高可靠性,高资源利用率的特点。将一份数据复制3份,存放到不同的服务器上,通过数据冗余来提高高并发读取,一方面提高了其利用率,一方面也降低了数据遗失的风险。但是,如何在高并发场景下的数据变更请求,如何保证数据副本间的一致性,是主要的技术难点。
MapReduce 实际上是一种计算模式,其基本思想是,将大量数据的计算任务拆分为多个小任务,利用多台高性能计算机并行计算,来实现海量数据的计算需求。一个计算作业(Job)可分为Map,Reduce 两个任务(task),两个任务的输入,输出以键值对形式表示。
MapReduce 的工程实践非常复杂,实现的好坏极大的影响计算的效率。MapReduce 建立在分布式文件系统之上,需要完成数据分片,考虑如何避免Map任务的数据倾斜问题。此外,对于同时计算上千个作业时,如何有效分配资源,管理任务队列,依赖更复杂的技术实现。
BigTable 是Google 为海量结构化数据设计的存储结构。BigTable 的设计目标是,满足高适用性、高拓展性、高性能和高可用。BigTable已经支持Google多个产品大量数据存储,如Google Earth,Google Search等。
三个基础的大数据知识
大数据领域经过十几年的发展,先后出现了各种满足不同应用需求的技术,如Hadoop生态体系的HDFS+MapReduce+HIVE等,及满足实时计算需求的Flink、Storm、Kafka等。在学习这些技术之前,我们有必要先知道三个基础的大数据知识,通过对它们的学习和理解,能帮助我们更好、更快的理解其他技术。
大数据的分片和路由
将大文件数据记录按某种规则拆分成多个数据片,再将这些数据分片存放到分布式集群的不同机器节点上,这一过程就是数据分片。数据分片之后,如何快速找到需要的数据,依赖路由算法。
数据分片最大的优势在于,能极大的提高集群的数据响应性能,以相对更快的速度返回用户需要的数据。此外,数据分片通常伴随数据复制,因此能增加系统容错性。而且,数据分片为系统扩展性提供了解决方案。集群中不同节点负责特定用户的读写需求,灵活的实现节点的增减。需要注意的是,数据分片能提升数据的读性能上,但对于数据写入操作,性能提升不大。
数据分片技术有几个难点。第一,如何划分数据,让数据的响应时间最短,同时实现负载均衡。第二,当系统中节点需要增减时,如何重新完成数据分片,再次实现系统负载均衡(rebalance)。
数据分片算法可分为两类,一个是哈希分片,另一个是范围分片。前者能快速响应特定数据的查询结果,后者可完成点查询或范围区间内的数据查询。
数据分片一般由系统完成,可抽象为两个映射关系。第一层,数据按某种规则分片,获得key-partition 映射,第二级,partition-machine 之间的映射。
Round Robin 与虚拟桶
对于哈希分片,有不同的哈希函数,包括Robin Round,虚拟桶,一致性哈希。通过哈希函数,可以获取机器节点对应的哈希值。在数据的路由阶段,根据数据分片对应的哈希值,定位到对应的机器,从而提取数据。
Round Robin 也称取模法,实现方式比较简单。通过H(key)=hash(key) mod K 函数完成数据分片。K表示机器数量,key 指示对应的数据片,通过以上函数获得集群中各个物理机器的H(key)值。但是,当机器数量发生变动时,需要重新对所有数据分片重新分配编号,因此灵活性较差。
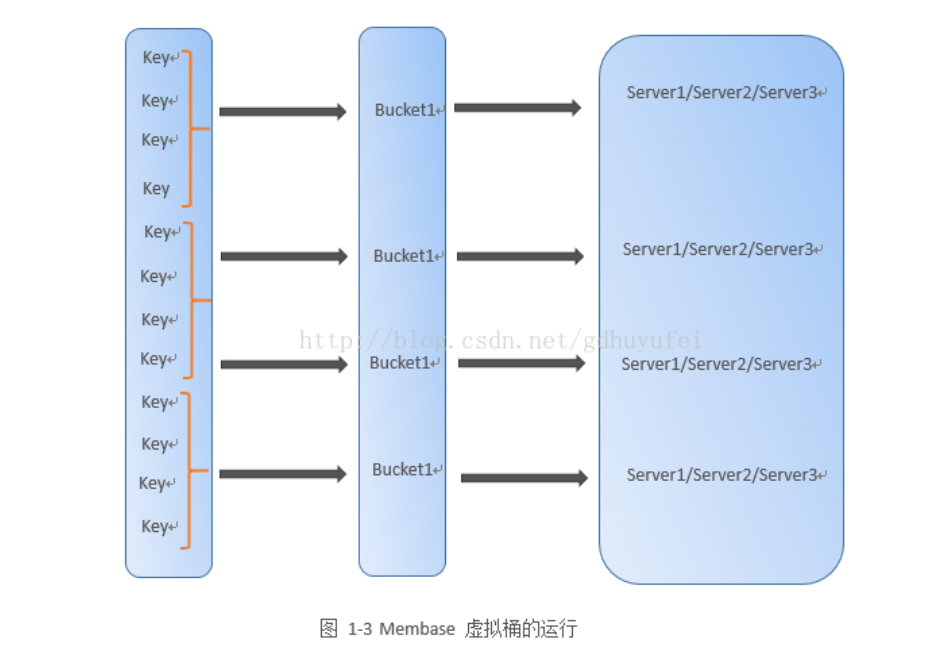
虚拟桶,在Round Robin 哈希分片方法上,增加了一层映射关系。将数据分片直接映射到机器的方式,解耦为两个过程:首先通过哈希函数获得key-partion,再完成partition-buket 的映射(多对一的关系),最后完成buket-machine 映射关系。分布式NoSQL数据库MemBase 即采用该方式实现数据分片。
虚拟桶的优势在于,增加了灵活性。当新加入机器时,只需要对部分虚拟桶重新分配机器位置,而无需改动所有数据记录,大大增强了灵活性。对数据的路由,则为每个节点维护了一张buket-machine 映射关系表,通过查表完成数据路由。
一致性哈希
一致性哈希是分布式哈希表(DHT)的一种实现方式,用于在多机分布式环境下,各个节点只承载部分数据存储时,通过哈希表实现数据的增、删、改、查等操作。Dynamo,Cassandra 等很多分布式存储系统都是这种算法变体。
一致性哈希算法建立在环状结构上。与上述两种算法不同,其不关心系统中节点数量。只根据机器的IP地址、端口号,通过哈希函数获得对应节点的哈希值,组成一个哈希空间(给定长度的二进制数值,如给定长度m=5,则哈希空间为0~31)。每台机器负责存储一段哈希值范围内的数据。
下图是一个简化的一致哈希表结构,其中节点表示机器,数字表示哈希值。N12存储主键哈希值落在为8-12范围区间的数据记录。每个节点存储前驱、后继节点信息,实现有向闭环。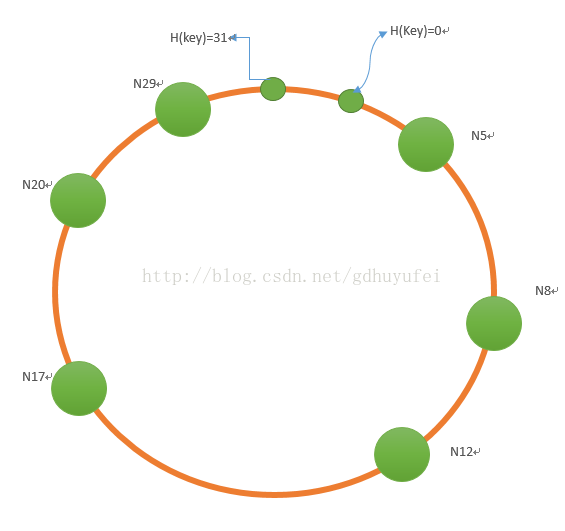
一致性哈希的路由算法,可以通过有向环的顺序查找完成,但该方法效率低下。其基本过程是,当节点接收到查询请求时,根据哈希函数(H(key)=j)获得待查数据主键的哈希值 j,如果其在自身管理范围内,则返回数据,否则将其转交给后继节点,直到查询到访问数据。
为了提高路由性能,可以为每一个节点配置一张路由表(如下表所示),存储m条路由信息(m为哈希空间的二进制数值比特位长度),每条路由信息记录该节点之后距离为2^i 的哈希值所在机器节点编号。

(N14 节点的路由表信息)
一致性路由哈希算法的步骤可简化为,当节点Nc接收到查询请求时,判断哈希值 j 是否在自身管理范围内。若不在,查询路由表,找到小于j 的最大编号节点Nh。由节点Nc向Nh发送消息,请它查找哈希值j 对应的数据内容,并将查询结果返回给Nc。
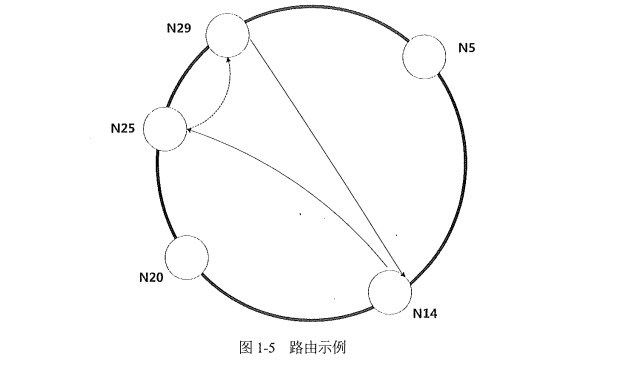
举个例子。以下的哈希空间内,节点N14接收到查询H(key)=27 的数据请求。N14 判断之后,该哈希值不在其管理范围内,查询路由表(如上所示),找到小于27的最大节点编号为25((14+8=22)<27<(14+16=30))。于是发送请求给节点N25,让其代表自己查询H(key)=27对应的数据记录。再由N25节点将查询结果返回为N14。
对于一致性哈希,当加入新节点时,只需要对特定节点的数据分片重新分配,同时修改后继节点信息。此外,一致性哈希路由算法还提供节点的稳定性检测,定期完成前驱、后继节点的更新和数据迁移。当节点离开时,对数据的分片重新分配步骤与之类似。
| Round Robin | 虚拟桶 | 一致性哈希 | |
|---|---|---|---|
| 基本思想 | H(key)=hash(key) mod K key-partition partition-machine |
节点的虚拟桶层 key-partition partition-bucket bucket-machine |
不关心集群集群数量 给定哈希空间,有向环,记录前驱、后继节点信息 维护节点的路由表信息 |
| 路由过程 | 通过取模函数获取机器哈希值 | 为节点维护bucket-machine 映射表,通过查表实现 | 一致性路由算法,节点之间互相通信 |
| 优点 | 简单 | 提高数据分片的灵活性 | 将数据分片与机器数量解耦,极大增强数据分片的灵活性 |
| 不足 | 灵活性差,增加或删除节点时成本大 | 系统增减节点的rebalance性能好 | 一致性路由算法实现难,维护成本高 |
| 应用场景 | memBase | Dynamo、Cassandra |
范围分片算法,通过对数据记录按主键排序,划分数据分片,再将数据分片维护到一张映射关系表。表内记录每一个分片的最小主键及对应的机器地址,当需要对记录增/删/改时,查询映射表即可查找对应的数据记录。数据分片的管理实现,则通过LSM树完成。Google BigTable 即遵循该模式。
将海量数据通过哈希函数,完成数据片划分,再将各个分片存放到分布式集群各个节点上,负责特定数据块响应,提高系统对数据的访问查询效率。相应的数据路由,可以通过维护映射表,或者一致性哈希的路由表,完成数据的定位。数据分片,还涉及更深层的技术问题,比如负载均衡等问题。
数据更新与副本一致性
在分布式系统环境下,当一个用户对一份数据做了修改,同时保证其他副本数据的一致性,以便让同一时刻的其他用户也能访问到正确的数据,这就是数据更新操作过程中,需要思考的副本一致性。
首先,数据的一致性有几个分类。强一致性,弱一致性,最终一致性。
同一时间下,同一系统的两个数据库文件内容保持一致,称为强一致性。允许用户访问不是最新状态的数据,称为弱一致性。例如,某一时刻,用户A修改了数据,同时另一个用户B访问了被修改前的历史状态数据;当B过了一会儿之后再次访问数据,此时获取了最新状态的值,称为最终一致性。如果同一时刻,用户A修改了数据,但同时用户B在历史值基础上,再次更新了数据,也就造成数据不一致了。
关于数据更新操作和数据一致性,有几个重要的理论,可以更好的理解一致性。
CAP 理论
早期的CAP理论指出,在一个同时访问的并发数据系统中,只能满足CAP三个原则的任意两个。CAP分别指,consistency(一致性),availability(可用性),partition tolerance(分区容错性)。一致性是指,多个用户同时访问一份数据,最终返回的结果一致;可用性指,任何时候任何地点用户均可访问数据;分区容错性,当网络故障发生时,用户仍可以访问数据,这是分布式系统的基本特征。
为什么说,系统发生故障时,只能满足CAP三者中的两者?假定以下的分布式系统,有两个节点N1,N2,对应两个应用程序A和B,及两个数据库V。此时有两个用户小明和小华同时访问数据库,且小明将N1数据从V0改为了V1,但此时出现网络故障,N1节点无法立即将最新数据发送给N2,因此小华拿到的数据是V0。以上过程只满足了CAP 理论的A和P。但是当网络修复后,N2节点的数据再次和N1节点保持一致,即最终一致。
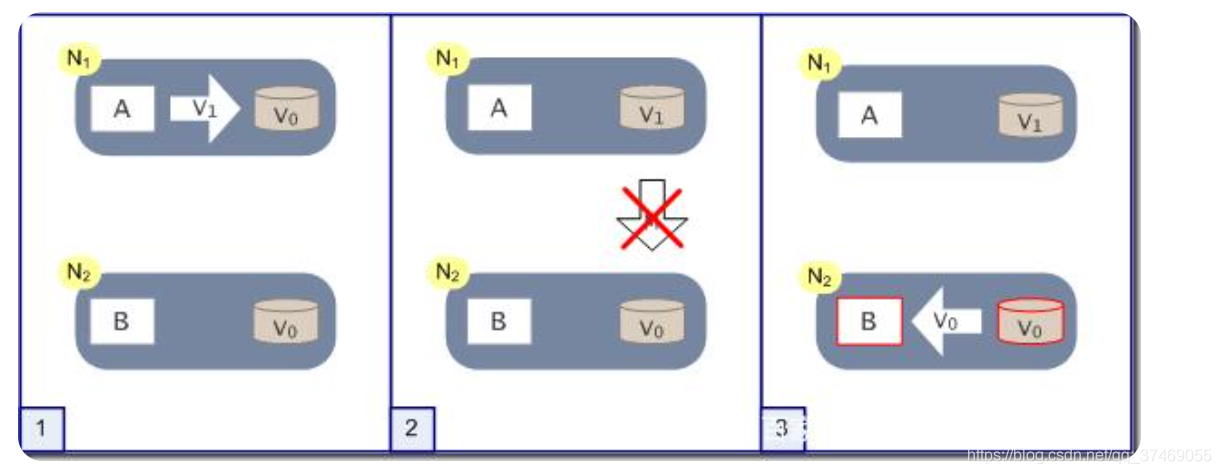
大多数情况下,系统选择牺牲一致性C,保证系统稳定的向用户提供数据。但是,在一些对数据一致性要求非常高的场景中,牺牲数据可用性A,来保证数据一致性。如银行系统中,用户发起转账业务,但此时网络出现问题,银行系统只能终止交易,保障用户账户金额的准确。
ACID 事务四原则
业务数据系统的主要操作是事务处理,因此需要遵循事务的4原则。ACID分别指,atomic(原子性),consistency(一致性),isolation(隔离性),durability(持久性)。原子性指,一个事务操作要么不做,要么全做,如果过程遇到故障,那么对事务回滚。隔离性,指高并发需求下,各个事务间不受影响,各自独立,对用户而言就好像只有一个任务。持久性,指一个操作一旦完成,数据将用户保持该状态,除非出现不可抗外力损坏。原子性,隔离性,持久性,都是为了保证数据的一致性。
大数据的BASE 理论
相对于业务系统的ACID原则和CAP理论,BASE理论更适用于大数据系统。BASE理论包括三个定义,basic available(基本可用),soft state(软状态),eventual consistency(最终一致)。
因为大数据计算的延时性,及网络传输的压力,大数据的应用采取保持基本可用和最终一致的协议。软状态指,数据状态不要求任意时刻保持同步,处于一个有状态或无状态之间的中间状态。
| CAP理论 | 事务4原则ACID | 大数据BASE理论 | |
|---|---|---|---|
| 基本特征 | 一致性,可用性,分区容错性 | 原子性,原子性,隔离性,持久性 | 基本可以,软状态,最终一致性 |
| 一致性分类 | 选择AP,牺牲C;或选择CP,牺牲A | 强一致性 | 最终一致,弱一致性 |
| 一致性算法 | — | 2PC,3PC | Paxos |
| 应用场景 | 分区容错可用,但数据若一致性;或分区容错数据一致,但不可用 | 业务操作系统,如银行系统 | 分布式系统 |
此外,幂等(idempotent)也是大数据遵循的一个理论,即在任意多次执行操作后,执行操作结束后的影响不变。举个例子,用户完成在线支付操作。对任意一个订单,用户执行一次支付,和对该订单执行多次支付操作,最终结果只会完成一次金额的扣除。再比如,用户完成一次点赞行为,和执行多次点赞操作,其结果都只会累加一次。
实现操作的幂等性,有几种方式。MVCC,多版本并发控制。或者创建一张去重表,通过构建唯一索引。引入Token 机制,为每次操作生成唯一凭证。
一致性协议
以上提及的三张一致性理论,CAP/ACID/BASE,为数据副本一致性给出了比较明确的定义和标准。为了实现数据更新操作后的副本一致性,可以通过两阶段提交协议(2PC),三阶段提交协议(3PC),Paxos 协议等其他一致性协议/算法来完成。
2PC和3PC协议,将分布式系统中机器节点划分为协调者和参与者,事务的变更操作由一个协调者发起,其他参与者按2阶段,或3阶段来完成事务操作。2PC和3PC协议,有以下三个特点:
- 简单:引入协调者,参与者,按照preCommit(canCommit,preCommit),doCommit 三阶段执行
- 阻塞:所有参与者的资源都被加锁,无法完成其他操作,限制了分布式系统的灵活性
- 无容错机制:2PC中doCommit 阶段,若协调者若出现故障(单点故障),参与者持续等待,资源无法被利用;doCommit 阶段若某个参与者出现网络问题,无法完成事务提交,造成数据不一致
为了解决2PC的单点故障,减小参与者的阻塞范围,3阶段在2阶段基础上,做了一些改变。一是,增加了询问请求(参与者都返回yes,再提交执行事务请求),减少了2PC在第一阶段的资源阻塞范围(发起事务操作,等待回复,若一个参与者返回no,终止事务操作);二是,在doCommit 阶段,若协调者出现故障,其他参与者在等待超时后,继续完成事务提交,仍可能造成数据不一致。
在分布式系统中,Paxos 协议是被公认的解决分布式一致性最有效的协议。Paxos 算法,由Lamport 于1990 年发表了一篇文章,《Paxos made simple》,给出了详细描述。Paxos 基于消息传递保证操作记录的数据一致性,具有高容错性。
Paxos 算法较难理解,可以通过以下概念或特征来理解Paxos 一致性的实现过程。
三个角色
- proposor:提议者,发起一次提议请求,生成一个唯一序列号n,该值会不断递增
- acceptor:接收者,需要稳定存储三个内容,最小提议号,已经接收的提议号,已经接收的数值
- leader:Multi Paxos 协议下引入的角色,用以解决多点写入时引起的冲突和性能开销。leader 节点通过选举产生,之后任意时刻只能由leader 发起提议,消除大量prepare过程
Paxos 协议4个特征
- 一个或多个服务器可同时发起提议
- 系统必须同意一个值被选中
- 只有一个值被选中
- 服务器不会知道哪个值被选中,除非这个值已经被选中
两个阶段
- 提议发起阶段(投票):由一个节点发起提议,向其他节点广播一个唯一序号n。其他接收者对n进行响应,如果n>minPropoal,minPropoal=n,并返回acceptedValue;否则不进行响应。
- 接收提议阶段:当提议者接收到半数以上的返回响应,向其他节点再次广播,返回(n,value);否则终止本次提议。value 可以是更改值内容,或其他操作。接受者再次响应,如果n>=minPropoal,接收value,向提议者返回n。若提议者接收到半数以上返回值,则确定最终value,否则再次进入提议阶段。
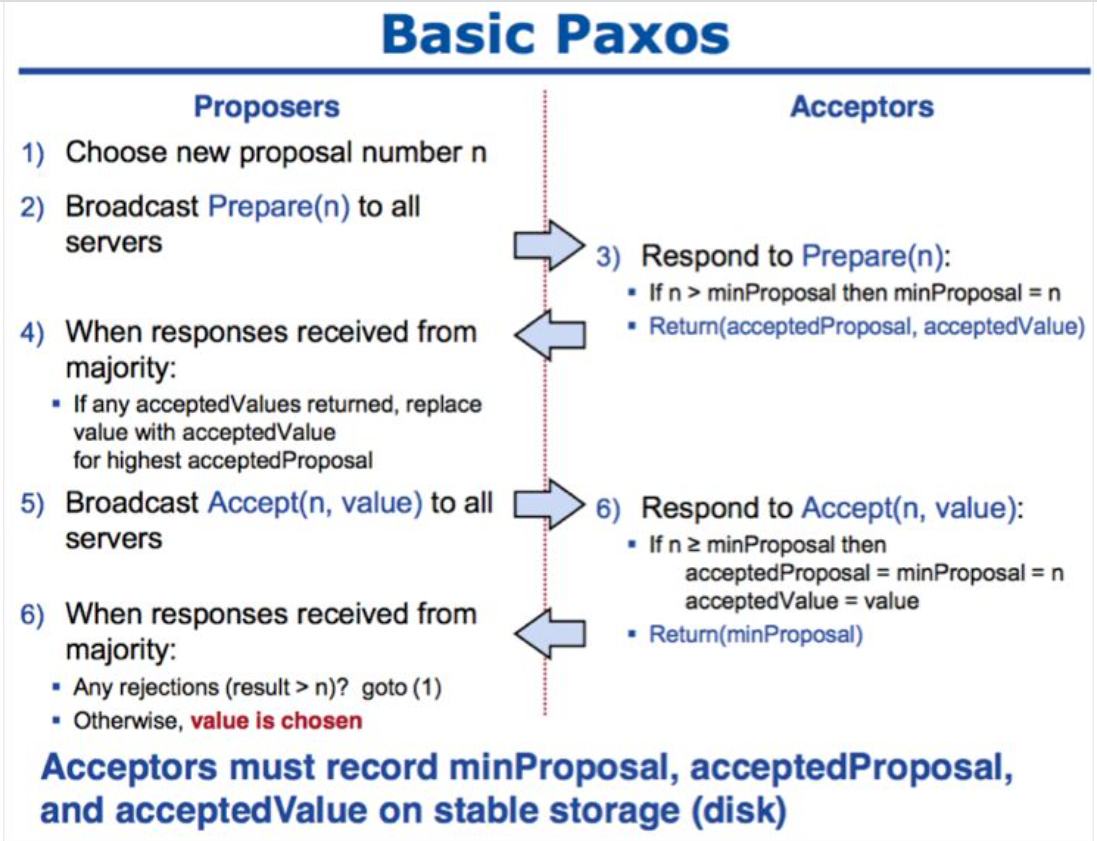
理解Paxos 算法两个阶段的核心思想
- 理解第一阶段acceptor 的处理流程:如果acceptor 已写入的提议号大于新的提议号,直接返回已写入已写入的值,不接收请求;如果未写入,则记录下请求的提议号,同时不再接收其他小于改提议号的请求。即接收节点只信任最后一次的提议号,使其他提议号失效。
- 理解第二阶段proposer 的处理流程:如果有半数以上的节点返回接收提议响应,且如果半数以上节点返回值都是空,则将proposer自身节点的值写入,否则,将非空节点中的最大值作为此次提议的值写入。(大多数节点接收提议后,是写入自身的值,还是写入其他节点的值)而如果不足半数以上的节点响应,则终止此次提议。
Paxos 算法能有效解决分布式系统的一致性问题,但其实现过程也更复杂。在实际生产中,多个不同的、互不关联的提议会同时产生,此时需要引入数据日志,存储有序的数据操作指令,来保证强一致性。而为了提升性能,也引入了leader选举,及优化方案,使得paxos 两阶段协议变成一阶段,提升性能。
| 2pc | 3pc | paxos | |
|---|---|---|---|
| 节点角色划分 | 协调者(一个)、参与者 | 协调者(一个)、参与者 | 提议者(一个或多个)、接收者 |
| 基本步骤 | 1. preCommit 1. doCommit |
1. canCommit 1. preCommit 1. doCommit |
1. 提议阶段,唯一提议号和接收节点的承诺 1. 接收阶段,半数投票通过,选中值 |
| 优点 | 简单、事务原子性 | 简单、解决单点故障、减少资源阻塞范围 | 有效保证数据一致性、高容错性 |
| 缺点 | 容错性低(单点故障、资源阻塞) | 数据不一致性问题 | 工程实现困难 |
让大数据算力更快的技术
GFS 分布式文件系统为大数据存储提供了解决方案,MapReduce 计算思想也极大的提高了计算速率,但在让大数据跑的更快的技术方案上,还需要数据结构和算法的加持。
LSM树:快速顺序写
LSM树,全称是Log Structured Merge Tree(日志结构合并树),其并非一种数据结构,而是一种数据结构的设计思想。在处理亿级别数据的存储和检索时,非关系型数据库NoSQL,如HBase,Leveldb,RocksDB等通常是最好的选择。这些数据库的共性是,大量参考了Google 的BigTabele 的文件组织方式,即LSM树。
传统的关系型数据库,通常维护一个B+树结构,能快速找到数据,但是数据的写入和修改并不高效。由于数据以随机方式写入,当数据更新时,需要在磁盘上找到对应数据,再进行修改。而磁盘IO耗时很长(寻道时间、等待时间、传输时间),这会产生大量的磁盘IO,影响数据写入速度。
相对于传统数据库,LSM树最大的优势是,快速的顺序写入方式。
如前所说,LSM树是一种数据结构的设计方式,其通常包括两种以上的存储结构。这些数据结构可以是,memTable,WAL log,SSTable等。
- memTable:内存中的数据结构,保存最近更新的数据,按Key,保证数据记录有序。保证数据有序,具体可以是SkipList或红黑树,或其他结构来维护。
- Immutable memTable:同样存在内存中,当memTable达到一定大小后,将其转化成Immutable memTable。
- WAL log:Write-ahead logging,预写式日志,位于硬盘中,预防断电后内存中数据被丢失后,数据的被顺利恢复。
- ssTable:sorted string table,排序字符串表。ssTable 中的数据文件格式,一是按键排序,二是排序后的数据键唯一,不存在重复。数据排序之后,能高效的完成数据的合并操作。
LSM树的数据写入方式可以概括为两个步骤:
- 插入步骤(log append):当写入一条操作记录时,将其按键-值对方式写入内存memTable、WAL log。写入方式是按日志方式,直接追加,速度非常快。
- 合并步骤(compact):可以分为两个阶段。首先,将Immutable memTable 中的数据写入到硬盘第0层的ssTable(Minor Compaction),该层中不同的ssTable 中可能存在重复的key(取最新写入的记录),level 0 层的不同ssTable 不进行合并。然后,将达到一定大小的ssTable 进行合并(Major Compaction),此时会删除已经失效的数据,并对多个版本数据进行合并。而对有序数据的合并,执行效率很快。
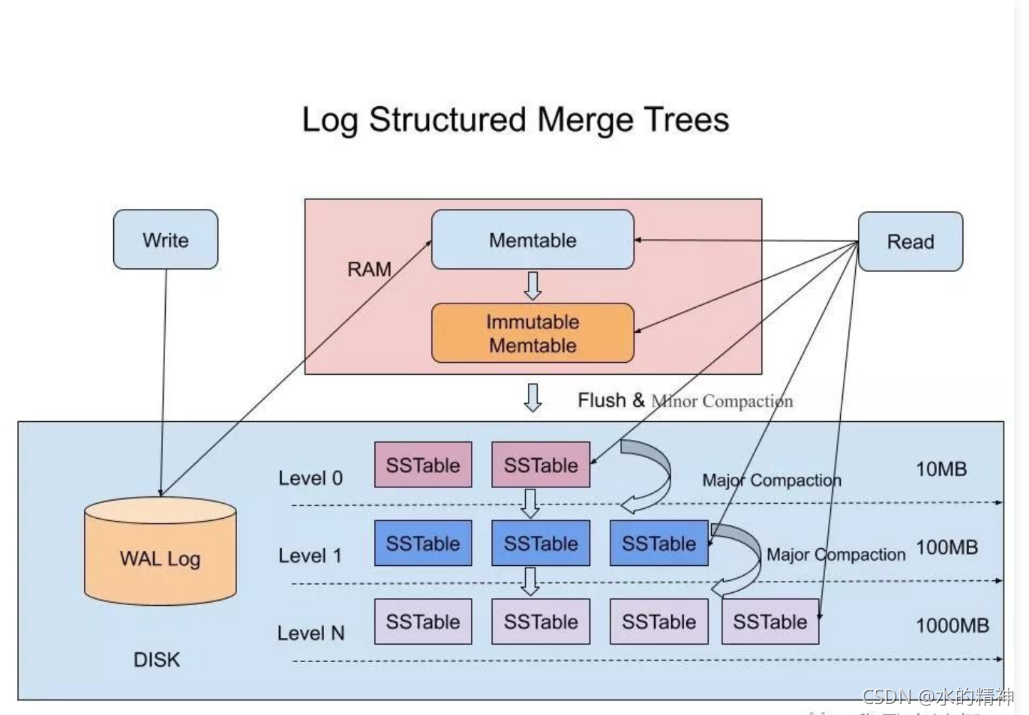
LSM 树结构最关键的是ssTable 的合并(compaction操作),KV形式有序存放的数据,加快数据查找和比较。 不同层级的ssTable 存放数据大小不同,由系统统一管理数据存放内容,协同使用过滤算法或数据结构,快速找到需要数据。
SkipList:近二分查找,快速且简单
SkipList,是一种分层的数据链表,相比普通链表,具有更快的查找效率。SkipList 在查找、删除、插入的数据复杂度都是O(logN),具有类似二叉树等平衡树的性能,但实现方式更简单。SkipList 被应用在许多开源软件中,如LevelDB、HBase的memTable,Redis的有序集合zset,Lucenne等。
SkipList 的基本思想是,在基础的有序链表上,对某些节点分层,增加一些节点,作为某种意义的索引,实现近似二分查找效率。具体而言,对第1层的节点,对部分节点增加3个或更多的指针,指向更远的后续节点。如当我们查找39是否存在,可以快速定位在值为18节点位置,再往后进行查找。
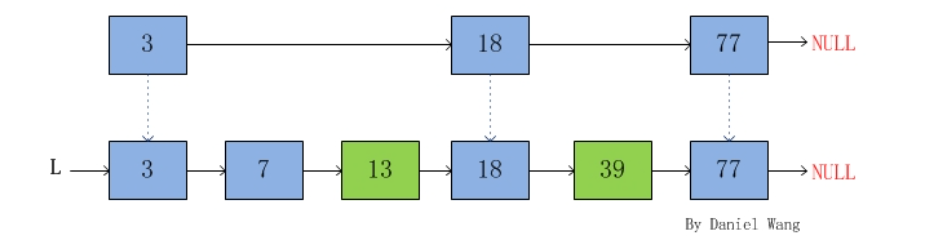
SkipList 有以下几个特征特:
- 一个跳表有多个层次。层级数由节点的指针数确定,拥有最多指针数的作为跳表的层数。链表的表头具有MaxLevel层级
- 跳表的第一层包括所有的元素
- 每一层都是有序链表
Bloom Filter:位数组实现巨量集合元素判断
Bloom Filter ,也称布隆过滤器,适用于判断大数据集中某个元素是否存在。BF 是Howard Bloom 于1970年提出的一个二进制向量数组,具有很好的空间和时间效率。
BF 通过哈希函数和位向量数组来表征数据集合,从而减少额外存储数据集合的空间。
BF 的基本原理是,给定长度为m 的位向量数组,对集合S 中的元素 a ,分别通过K 个哈希函数,映射到位向量数组中。hi(a) = x ( 1<=i <=k, 1<=x <=m) ,若满足条件,则将位数组的第 x 位置为1 。当K 个哈希函数完成计算后,可能位数组中的 w 位(w<=k) 都为1。此时完成集合中a 元素在位数组中的映射。

若查询某个元素 a 是否在集合S 中存在时,分别用K 个相同的哈希函数计算,若位数组中对应的w 位均为1,则判断其属于集合S,若任意一位为0,则判断其不属于集合S。

但是,布隆过滤器存在误判的可能,因此不允许误判的使用场景并不适用。即某个元素实际上不在集合S 中,但BF 返回结果表明其在集合内。误判率和位数组长度m,哈希函数个数k 及集合大小n 三者有关。在实际应用中,通常根据集合大小和期望的误判率,计算BF 需要的内存大小,即位数组长度m 的大小。

虽然BF 存在误判,但是其不会漏判。即某个元素属于集合S,那么BF 返回结果一定是其存在与集合中。
由于基础的二进制的BF 无法实现集合内元素的删除,后来便提出了计数BF,通过增加位多个比特位来表示基础信息单元。但是,计数BF 使用的空间大小翻倍,同时也存在计数溢出问题。
BF 应用于各个大数据计算场景,如Google 浏览器判断恶意URL,网络爬虫判断已爬取过的URL,缓存对海量数据中的元素查找等。在BigTable 中使用BF 也能提高数据读取效率。由于BigTable 中很多数据记录存储在磁盘的多个ssTable 中,为了实现一次读取,可以将包含数据记录的key 形成BF 结构,存储在内存中,从而实现极高的查找速度,减少对磁盘的IO次数。
Snappy:不只是压缩,还要更快
Snappy 是Google 开源的高效压缩和解压缩算法库,在实现合理的压缩率的技术上,通过一些优化,让压缩速率更快,更适应大数据的计算场景。如Hbase,Hadoop 等系统都集成了Snappy。
Snappy 压缩算法的基础是 LZSS 算法。LZSS 则是LZ77 压缩算法的进一步优化。
LZ77 是Abraham Lempel 和Jacob Ziv 于1977 年提出,是一种基于滑动窗口缓存的动态词典编码技术。当后续待处理字符与滑动窗口的字符片段匹配时,基于某种格式编码,而不是输出源字符,实现数据压缩。
LZ77 算法包括滑动窗口和前向缓冲区(Lookahead Buffer),前者存储已经处理过的若干源字符,后者包含输入流中待处理的后续字符。前向缓冲区与滑动窗口内字符进行最长匹配,若缓冲区未匹配上,则将其输出;若找到匹配字符串,则输出一个三元组<指针,长度,后续字符>。指针可以是滑动窗口内匹配子串的起始位置,或与匹配子串的差值,表示二者的相对位置。对于滑动窗口,会将存在最久的字符移除。
LZSS 算法在LZ77 算法上做了几点优化,其中最主要的是,增加了最小匹配长度限制。当匹配字符串小于指定匹配子串长度时,不压缩,仍然滑动窗口右移一个字符。
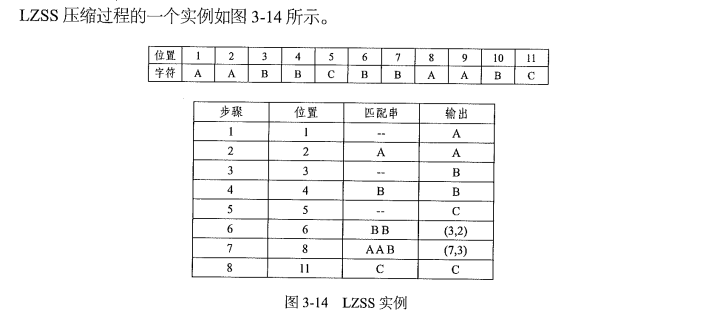
实际实现LZ 系列算法时,影响计算效率的主要步骤是,如何在滑动窗口内快速找到最长匹配子串。一个常用的技巧是,利用哈希表存储滑动窗口内的字符片段及其对应的位置。假如滑动窗口内字符串为ABC,哈希表内可存储AB, ABC, BC 字符片段的起始位置。而为了简便,可以指定字符片段的固定长度,如长度为2,则只记录AB, BC 。进行匹配时,若前向缓冲区起始字符串在哈希表内存在,则可以定位其位置,再进一步查找最长匹配,从而加快匹配速度。
Snappy 算法整体上遵循LZSS 的压缩编码和解码方案,同时在其之上做了几点优化。
- 设定最小匹配长度为4
- 哈希表内字符串片段固定长度也为4
- 输出字符串压缩形式为:<编码方案,匹配子串起始位置差值,匹配子串长度>
- 切割数据为32KB大小,数据块之间无关联,两个字节即可表示匹配字符串的相对位置
- 滑动窗口每次后移长度为4
将数据压缩,能降低存储成本,也为数据传输过程中的网络、IO降本提速,而提升数据压缩速度,在大数据计算领域非常重要。在MapReduce 过程中,Map 任务输出的中间结果存储在磁盘中,再将结果作为Reduce 任务的输入。若通过Snappy 算法将Map 的中间结果快速压缩、解压缩,将极大提高MR 任务速度,这对于大数据的批计算意义重大。
至此,我们对大数据存储、计算领域的一些数据结构、算法有了基本了解,对它们在大数据系统体系中发挥的作用也知晓一二。不论是负责快速顺序写的LSM树思想,实现类二分查找的SkipList 结构,应用位数组实现集合元素判断的Bloom Filter,还是实现高速压缩、解压缩的Snappy,这些算法都在大数据领域的各个方面获得广泛应用。
大数据上”云”
云计算的本质。
- 云计算提供数据共享。用户随时随地可以访问数据,处理数据,也能非常方便的与他人共享数据。
- 云计算提供大量的计算资源,包括CPU处理器和存储器(内存和磁盘),用户可以使用这些资源而无需自己配置。
随着全球企业和研究学者在大数据技术领域的研究投入,从2003年之后,大数据的技术也涌现在了不同应用场景,为各种业务发展难题提供了多张解决方案。如Apache 基金会下的Hadoop 生态体系HDFS+Map Reduce+YARN,满足实时计算需求的Flume,Kafka,Storm,Flink等,支撑实时查询等数据库系统如HBase,Redis,MongoDB,ElasticSearch 等。
参考资料
- https://blog.csdn.net/gdhuyufei/article/details/42101231 数据分片与路由
- https://baijiahao.baidu.com/s?id=1702952809825057563&wfr=spider&for=pc 大数据分区,分桶
- https://www.jianshu.com/p/7f7c4b472782?utm_campaign=maleskine&utm_content=note&utm_medium=seo_notes&utm_source=recommendation 数据哈希算法比较
- https://blog.csdn.net/qq_37469055/article/details/116571929 分布式系统CAP理论
- https://mp.weixin.qq.com/s/eTTmbCx0k2sSrARMBkAHgg 大数据学习路线
- https://mp.weixin.qq.com/s/QAC4uqMQSrcbwXD8qcGRVw 分布式系统的一致性协议
- https://blog.csdn.net/m0_37840000/article/details/119743288 3PC 提交协议
- https://blog.csdn.net/a284365/article/details/120889099 paxos 协议操作举例
- https://blog.csdn.net/initiallht/article/details/123991713 paxos 协议解释
- https://baijiahao.baidu.com/s?id=1717546400851699033&wfr=spider&for=pc LSM树介绍
- https://blog.csdn.net/star1210644725/article/details/120384972 LSM树深入解析
- https://www.jianshu.com/p/58c7ea19bceb 阿里云 2022年发表产品合集
- https://www.processon.com/outline/view/link/5f43cb5b5653bb57696ea5e8?pw=null 腾讯云 产品汇总

若有收获,就点个赞吧
0 人点赞
