堆排序是一种原地、时间复杂度 nlogn 的排序算法
堆
- 堆是一个完全的二叉树
- 堆中每一个节点的值必须大于或者等于(小于或者等于)其左右子树的值 [大顶堆、小顶堆]
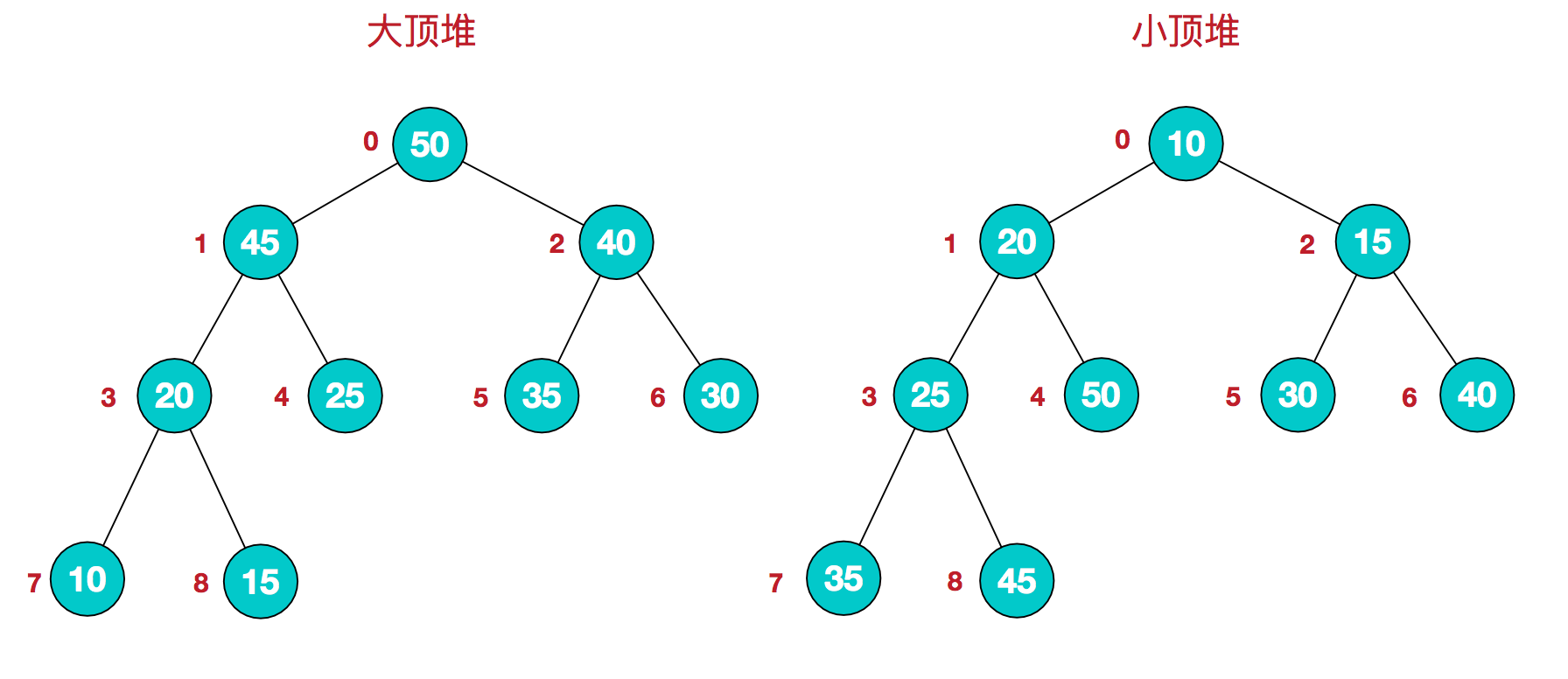
实现一个堆
上面提到堆是一个完全二叉树,而存储一个完全二叉树最适合的是使用数组,相比于链表不需要存储左、右子树的指针,通过数组的索引就可以随机访问到对应的元素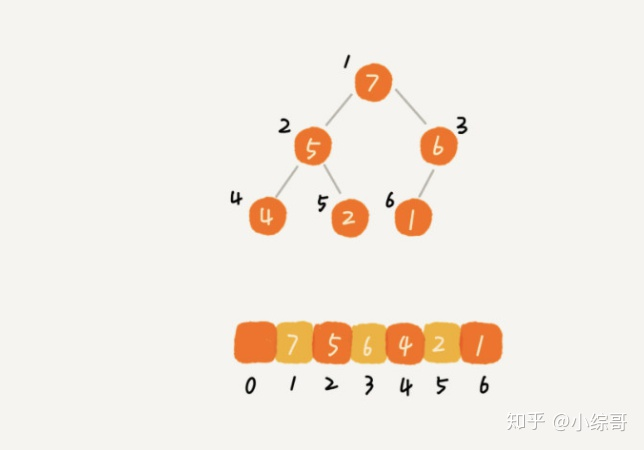
这里数组的第一个位置留空,是为了方便计算
某节点的下标为x,
- 左子树的下标是 2*x
- 右子树的下标是 2*x + 1
堆的常见操作
插入一个元素
我们在堆中插入一个元素后,需要对新的堆进行调整,使其能够满足上面提到的堆的两个特性,那么这个过程我们称为堆化。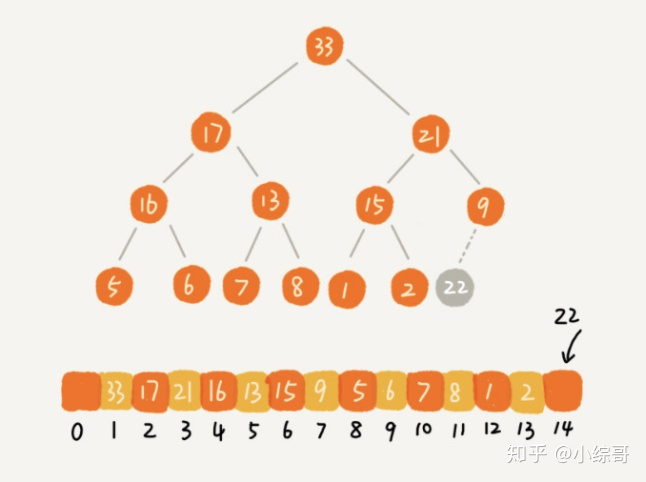
从下往上堆化就是指把该元素与其父节点对比、满足条件后交换位置、继续对比、交换,直到不能交换了
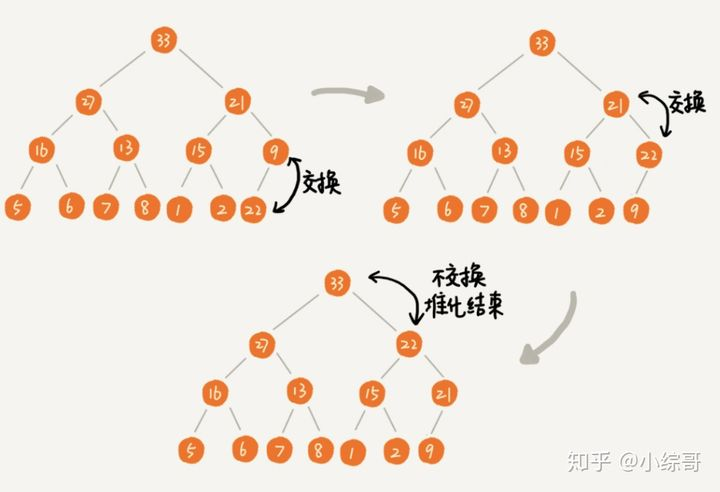
删除堆顶元素
大顶堆、小顶堆的堆顶位置存储的分别是最大值、最小值。
这里以大顶堆为例,当我们删除掉堆顶元素的时候,我们需要将之前第二大的元素移动到堆顶的位置,依次类推,我们依次删除第二大节点、第三大节点、直到叶子节点。
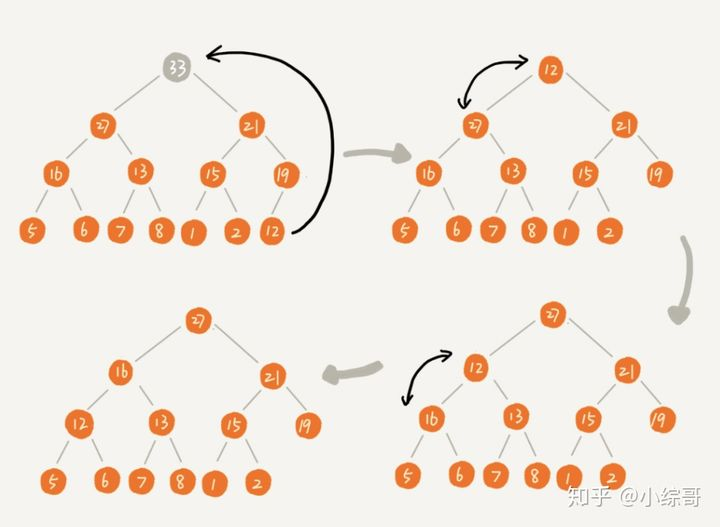
操作:删除堆顶的元素,直接将最后一个元素向上放到堆顶的位置,然后从上向下进行堆化,如果父节点的值小于其子节点
基于堆排序
建堆
第一步就是将一个无序的数组建成一个二叉堆
如果你需要对无序数组进行从小到大排序,那么你应该构建为大顶堆
如果你需要对无序数组进行从大到小排序,那么你应该构建为小顶堆
堆化时间复杂度:O(n)
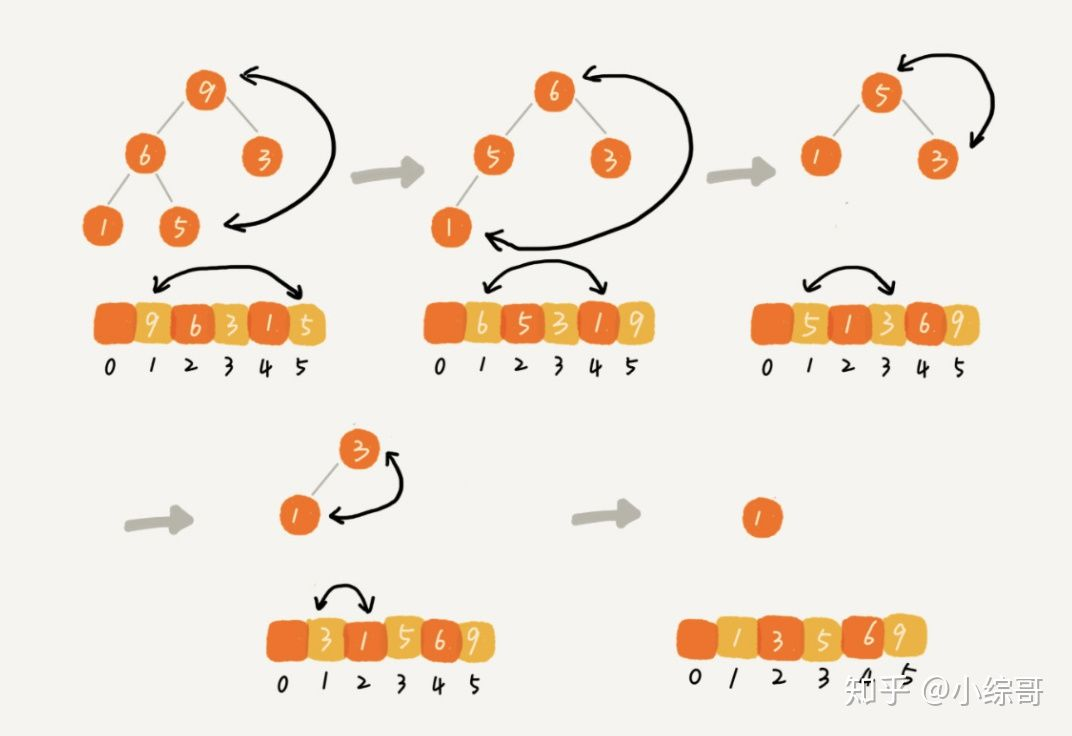
排序
建堆结束后就要开始排序了,假设是按照大顶堆的方式来组织的,那么数组中第一个元素就是堆顶,也就是最大的元素,将最大元素放到下标n的位置,然后依照上面的“删除堆顶元素”
当堆顶元素移除之后,我们把下标为 n 的元素放到堆顶,然后再通过堆化的方法,将剩下的 n−1 个元素重新构建成堆
堆化完成之后,我们再取堆顶的元素,放到下标是 n−1 的位置,一直重复这个过程,直到最后堆中只剩下标为 1 的一个元素,排序工作就完成了

若有收获,就点个赞吧
0 人点赞
