Python有哪些常见的、好用的爬虫框架?
319 人赞同了该回答
在这里推荐几个值得关注的异步爬虫库,给你的爬虫提速。看看有没有你没听过的?类似 Requests 的库为什么要推荐类似 Requests 的库呢?Requests 不够好吗?
虽然 Requests 对于新手很容易上手,但它是同步的、并不是异步设计的。在 HTTP 请求的时候是需要 IO 等待的。比如说,当你使用 Requests 库进行请求,网站进行返回的时候,这时 IO 就会阻塞,程序就需要等待网站的返回,这就让爬取速度变慢了。
那么异步的好处在哪呢?
Python 的代码是一行行去执行。也就是说,如果哪一行是非常耗时间的,之后的所有事情都会等到它完成才执行。因此 Python 异步编程也就应运而生用来解决这个问题。异步的方式在于你写的这些代码中哪些是执行时间非常短的,那么就先执行,耗时的操作会被搁在后面,并且执行这个过程完全都由 Python 的异步库自己来进行调控。
这样的好处就是只写少量的代码也能达到不错的效率,同时在代码可读性上也变得更加直观了。下面这几个库,都是类似 Requests 的用法但是基于异步的设计。
▍ 最推荐:aiohttp
 aio-libs/aiohttpgithub.com/aio-libs/aiohttp
aio-libs/aiohttpgithub.com/aio-libs/aiohttp aiohttp 是纯粹的异步框架,同时支持 HTTP 客户端和 HTTP 服务端,可以快速实现异步爬虫。==坑比其他框架少。==并且 aiohttp 解决了requests 的一个痛点,aiohttp 可以轻松实现自动转码,对于中文编码就很方便了。
aiohttp 是纯粹的异步框架,同时支持 HTTP 客户端和 HTTP 服务端,可以快速实现异步爬虫。==坑比其他框架少。==并且 aiohttp 解决了requests 的一个痛点,aiohttp 可以轻松实现自动转码,对于中文编码就很方便了。
▍ 第二推荐:asks
 theelous3/asksgithub.com/theelous3/asks
theelous3/asksgithub.com/theelous3/asks Python 自带一个异步的标准库 asyncio,但是这个库很多人觉得不好用,甚至是 Flask 库的作者公开抱怨自己花了好长时间才理解这玩意,于是就有好事者撇开它造了两个库叫做 curio 和 trio,而这里的 ask 则是封装了 curio 和 trio 的一个 http 请求库。
Python 自带一个异步的标准库 asyncio,但是这个库很多人觉得不好用,甚至是 Flask 库的作者公开抱怨自己花了好长时间才理解这玩意,于是就有好事者撇开它造了两个库叫做 curio 和 trio,而这里的 ask 则是封装了 curio 和 trio 的一个 http 请求库。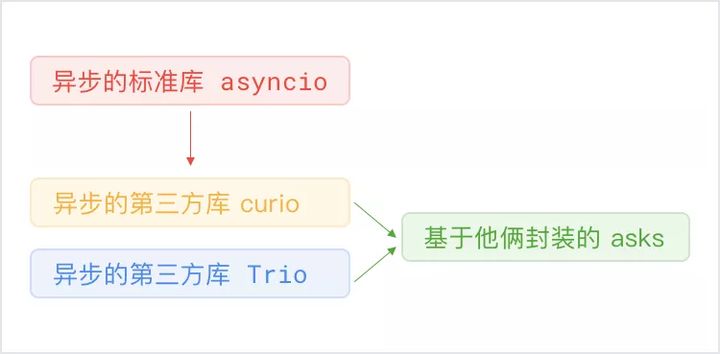 ask的家族谱系图用起来和 Requests 90%相似,新手也可以很快上手。
ask的家族谱系图用起来和 Requests 90%相似,新手也可以很快上手。
▍ 第三推荐:vibora
 vibora-io/viboragithub.com/vibora-io/vibora
vibora-io/viboragithub.com/vibora-io/vibora 号称是现在最快的异步请求框架,跑分是最快的。写爬虫、写服务器响应都可以用。但这个项目一直在重构,这谁受得了。现在页面上还挂着项目正在重构的警告,使用需谨慎啊。
号称是现在最快的异步请求框架,跑分是最快的。写爬虫、写服务器响应都可以用。但这个项目一直在重构,这谁受得了。现在页面上还挂着项目正在重构的警告,使用需谨慎啊。
类似 Selenium 的库
Selenium +webdriver 可以用来模拟用来模拟浏览器请求,Selenium也是同步的、而不是异步设计的。而下面这些库不光是从效率上,还有易用性上也比 Selenium 进化了不少。
▍ 最推荐:Pyppeteer
 miyakogi/pyppeteergithub.com/miyakogi/pyppeteer
miyakogi/pyppeteergithub.com/miyakogi/pyppeteer Pyppeteer 是异步无头浏览器(Headless Chrome),从跑分来看比 Selenium + webdriver 快,使用方式是最接近于浏览器的自身的设计接口的。它本身是来自 Google 维护的 puppeteer,但是按照 Python 社区的梗,作者进行了封装并且把名字中的 u 改成了 y特点是异步的设计,接口非常浏览器化,注入 JS 也很方便。
Pyppeteer 是异步无头浏览器(Headless Chrome),从跑分来看比 Selenium + webdriver 快,使用方式是最接近于浏览器的自身的设计接口的。它本身是来自 Google 维护的 puppeteer,但是按照 Python 社区的梗,作者进行了封装并且把名字中的 u 改成了 y特点是异步的设计,接口非常浏览器化,注入 JS 也很方便。
▍ 第二推荐:Requestium
 tryolabs/requestiumgithub.com/tryolabs/requestium
tryolabs/requestiumgithub.com/tryolabs/requestium
Requests 的作者 Kenneth Reitz 曾经转发称赞过这个库。 Requestium 是 Requests 和 Selenium 封装的产物,并且提供了友好的接口切换,这样就可以根据需求切换了。值得一提的是,Requestium 有一个 Wait Until 的方便设计,它的作用是确保页面中的某一个元素出现了才会进行下面的代码,这样一来就很轻松的避免了一些诡异的错误。GitHub 页面上有一组示例,是使用 Requestium 以及使用 Requests + Selenium + lxml 的对比,可以很明显看出区别。
Requestium 是 Requests 和 Selenium 封装的产物,并且提供了友好的接口切换,这样就可以根据需求切换了。值得一提的是,Requestium 有一个 Wait Until 的方便设计,它的作用是确保页面中的某一个元素出现了才会进行下面的代码,这样一来就很轻松的避免了一些诡异的错误。GitHub 页面上有一组示例,是使用 Requestium 以及使用 Requests + Selenium + lxml 的对比,可以很明显看出区别。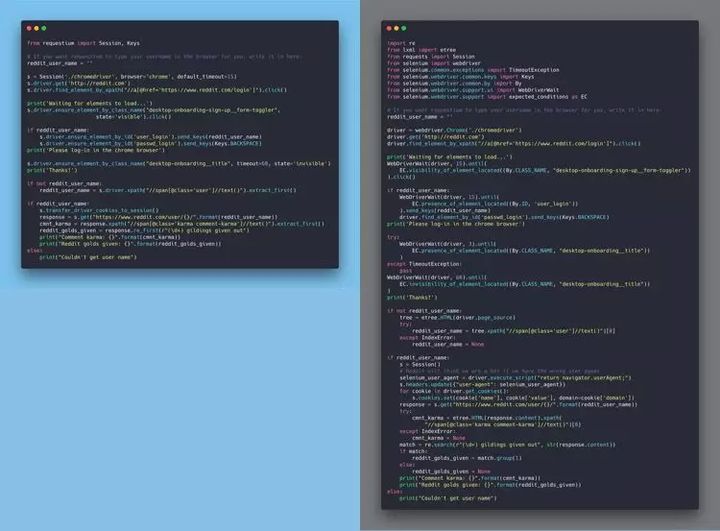 使用 Requestium 以及使用 Requests + Selenium + lxml 的对比
使用 Requestium 以及使用 Requests + Selenium + lxml 的对比
▍ 第三推荐:arsenic
 HDE/arsenicgithub.com/HDE/arsenic
HDE/arsenicgithub.com/HDE/arsenic HDE 公司用在了实际生产中的项目抽离出来的框架。和 selenium 接口几乎一致,学习成本相对较低。不同在于是异步的设计。不过文档有点糟糕。
HDE 公司用在了实际生产中的项目抽离出来的框架。和 selenium 接口几乎一致,学习成本相对较低。不同在于是异步的设计。不过文档有点糟糕。
框架**
▍ 最推荐:Grab
** lorien/grabgithub.com/lorien/grab
lorien/grabgithub.com/lorien/grab 前端圈很流行说渐进式框架,那么 Grab 可以说是爬虫界的渐进式框架。想简单用时有简单的用法,想复杂使用时也有复杂的用法。封装的很好,基于生成器异步的设计。
前端圈很流行说渐进式框架,那么 Grab 可以说是爬虫界的渐进式框架。想简单用时有简单的用法,想复杂使用时也有复杂的用法。封装的很好,基于生成器异步的设计。
▍ 第二推荐:botflow
** https://github.com/kkyon/botflowgithub.com/kkyon/botflow国人作者。概念很新颖,定位成了处理数据工作流的框架,可以用来爬虫、机器学习、量化交易等等。
https://github.com/kkyon/botflowgithub.com/kkyon/botflow国人作者。概念很新颖,定位成了处理数据工作流的框架,可以用来爬虫、机器学习、量化交易等等。
▍ 第三推荐:ruia**
 https://github.com/howie6879/ruiagithub.com/howie6879/ruia国人作者。比较接近 Scrapy 的使用方式,异步设计。作者也在知乎但是很低调 @howie
https://github.com/howie6879/ruiagithub.com/howie6879/ruia国人作者。比较接近 Scrapy 的使用方式,异步设计。作者也在知乎但是很低调 @howie
非 Python 框架
▍ Golang 爬虫框架

gocolly/collygithub.com/gocolly/colly
应该是 Golang 里使用量最多的爬虫框架了。Golang 语言本身就对并发支持很好。让你在使用时只考虑业务本身就可以。框架结构化、清晰、代码好读。
▍ nodejs 爬虫框架
yujiosaka/headless-chrome-crawlergithub.com/yujiosaka/headless-chrome-crawler
JS 圈里的一个奇葩,整个爬虫都基于 Chrome ,并且自带一个调度队列。实际测试速度和稳定性均不俗。
你还在低效努力吗?
用 Python 提升效率,4 小时工作 20 秒完成
112 人赞同了该回答
一、什么是Python爬虫框架
简单来说,==Python的爬虫框架就是一些爬虫项目的半成品。==比如我们可以将一些常见爬虫功能的实现代码写好,然后留下一些接口,在做不同的爬虫项目时,我们只需要根据实际情况,手写少量需要变动的代码部分,并按照需要调用这些接口,即可以实现一个爬虫项目。

二、常见的Python爬虫框架**
1、Scrapy框架
**Scrapy框架是一套比较成熟的Python爬虫框架,是使用Python开发的快速、高层次的信息爬取框架,可以高效的爬取web页面并提取出结构化数据。Scrapy应用范围很广,爬虫开发、数据挖掘、数据监测、自动化测试等。Scrapy官网
官方文档请参考Scrapy入门教程 - Scrapy 0.24.6 文档
**简单用法:
scrapy startproject tutorial #创建项目该命令将会创建包含下列内容的 tutorial 目录:tutorial/ scrapy.cfg tutorial/ __init__.py items.py pipelines.py settings.py spiders/ __init__.py ...定义Item:import scrapy class DmozItem(scrapy.Item): title = scrapy.Field() link = scrapy.Field() desc = scrapy.Field()编写爬虫:import scrapy class DmozSpider(scrapy.Spider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls = [ "http://www.dmoz.org/Computers/Programming/Languages/Python/Books/", "http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/" ] def parse(self, response): filename = response.url.split("/")[-2] with open(filename, 'wb') as f: f.write(response.body)运行爬虫:scrapy crawl dmoz
2、Crawley框架
Crawley也是Python开发出的爬虫框架,该框架致力于改变人们从互联网中提取数据的方式。官网是 Crawley Project · Crawley Project
简单用法,参考文档 Crawley’s DocumentationTo start a new project run~$ crawley startproject [project_name] ~$ cd [project_name]Write your Models""" models.py """ from crawley.persistance import Entity, UrlEntity, Field, Unicode class Package(Entity): #add your table fields here updated = Field(Unicode(255)) package = Field(Unicode(255)) description = Field(Unicode(255))Write your Scrapers""" crawlers.py """ from crawley.crawlers import BaseCrawler from crawley.scrapers import BaseScraper from crawley.extractors import XPathExtractor from models import * class pypiScraper(BaseScraper): #specify the urls that can be scraped by this class matching_urls = ["%"] def scrape(self, response): #getting the current document's url. current_url = response.url #getting the html table. table = response.html.xpath("/html/body/div[5]/div/div/div[3]/table")[0] #for rows 1 to n-1 for tr in table[1:-1]: #obtaining the searched html inside the rows td_updated = tr[0] td_package = tr[1] package_link = td_package[0] td_description = tr[2] #storing data in Packages table Package(updated=td_updated.text, package=package_link.text, description=td_description.text) class pypiCrawler(BaseCrawler): #add your starting urls here start_urls = ["http://pypi.python.org/pypi"] #add your scraper classes here scrapers = [pypiScraper] #specify you maximum crawling depth level max_depth = 0 #select your favourite HTML parsing tool extractor = XPathExtractorConfigure your settings""" settings.py """ import os PATH = os.path.dirname(os.path.abspath(__file__)) #Don't change this if you don't have renamed the project PROJECT_NAME = "pypi" PROJECT_ROOT = os.path.join(PATH, PROJECT_NAME) DATABASE_ENGINE = 'sqlite' DATABASE_NAME = 'pypi' DATABASE_USER = '' DATABASE_PASSWORD = '' DATABASE_HOST = '' DATABASE_PORT = '' SHOW_DEBUG_INFO = TrueFinally, just run the crawler~$ crawley run
3、Portia框架
Portia框架是一款允许没有任何编程基础的用户可视化地爬取网页的爬虫框架,GitHub: scrapinghub/portia
可以直接使用网页版的Portia框架,地址 Login · Scrapinghub
相关信息填写好后,单击“Create Project”,就可以爬取网站了
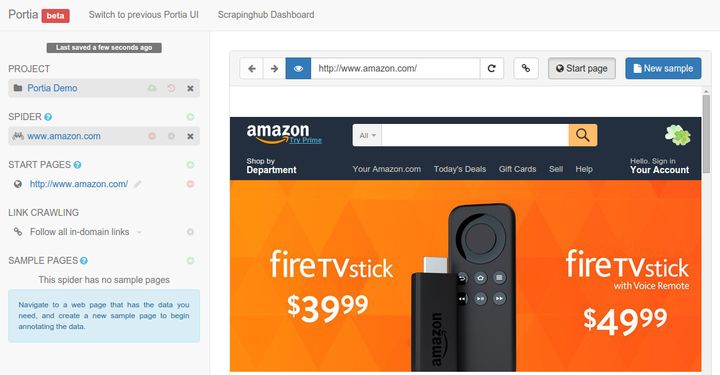
通过可视化界面,很方便配置爬虫。
4、newspaper框架
newspaper框架是一个用来提取新闻、文章以及内容分析的Python爬虫框架,GitHub: codelucas/newspaper
简单用法:>>> from newspaper import Article >>> url = 'http://news.163.com/17/0525/08/CL95029O0001875P.html' >>> a = Article(url, language='zh') >>> a.download() >>> a.parse() Building prefix dict from C:\Python35\lib\site-packages\jieba\dict.txt ... Dumping model to file cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache Loading model cost 1.6619999408721924 seconds. Prefix dict has been built succesfully. >>> print(a.title) 主播直播上山采蘑菇遇腐尸 1000多网友在线观看 >>> print(a.text) (原标题:震惊!主播直播上山采蘑菇突遇腐烂尸体 1000多网友在线观看) 南都讯 记者彭彬 5月23日下午四点半左右,直播平台主播吴权彼在直播上山采蘑菇时,意外发现一 具腐烂多日、发黑发紫的尸体,吴权彼当即中断直播报警,1000多在线网友观看了这惊魂一幕。随后 ,警方到达现场,目前案件仍在进一步调查之中。 '''
5、Python-goose框架
Python-goose框架可提取的信息包括:文章主体内容文章主要图片文章中嵌入的任何Youtube/Vimeo视频元描述元标签GitHub: grangier/python-goose
简单用法:>>> from goose import Goose >>> from goose.text import StopWordsChinese >>> url = 'http://www.bbc.co.uk/zhongwen/simp/chinese_news/2012/12/121210_hongkong_politics.shtml' >>> g = Goose({'stopwords_class': StopWordsChinese}) >>> article = g.extract(url=url) >>> print article.cleaned_text[:150] 香港行政长官梁振英在各方压力下就其大宅的违章建筑(僭建)问题到立法会接受质询,并向香港民众道歉。 梁振英在星期二(12月10日)的答问大会开始之际在其演说中道歉,但强调他在违章建筑问题上没有隐瞒的意图和动机。 一些亲北京阵营议员欢迎梁振英道歉,且认为应能获得香港民众接受,但这些议员也质问梁振英有当然还有更多, @笑虎 介绍的 PSpider 一个极为简洁的Python爬虫框架 , @花开不败 介绍的 PySpider Pyspider框架 — Python爬虫实战之爬取 V2EX 网站帖子 ,都是非常好用的。
三、总结
在Python中,开源爬虫框架很多,我们自己也可以写一些。我们并不需要掌握每一种爬虫框架,只需要深入掌握一种即可。大部分爬虫框架实现方式都是大同小异,建议学习最流行的Python爬虫框架——Scrapy。

若有收获,就点个赞吧
0 人点赞
