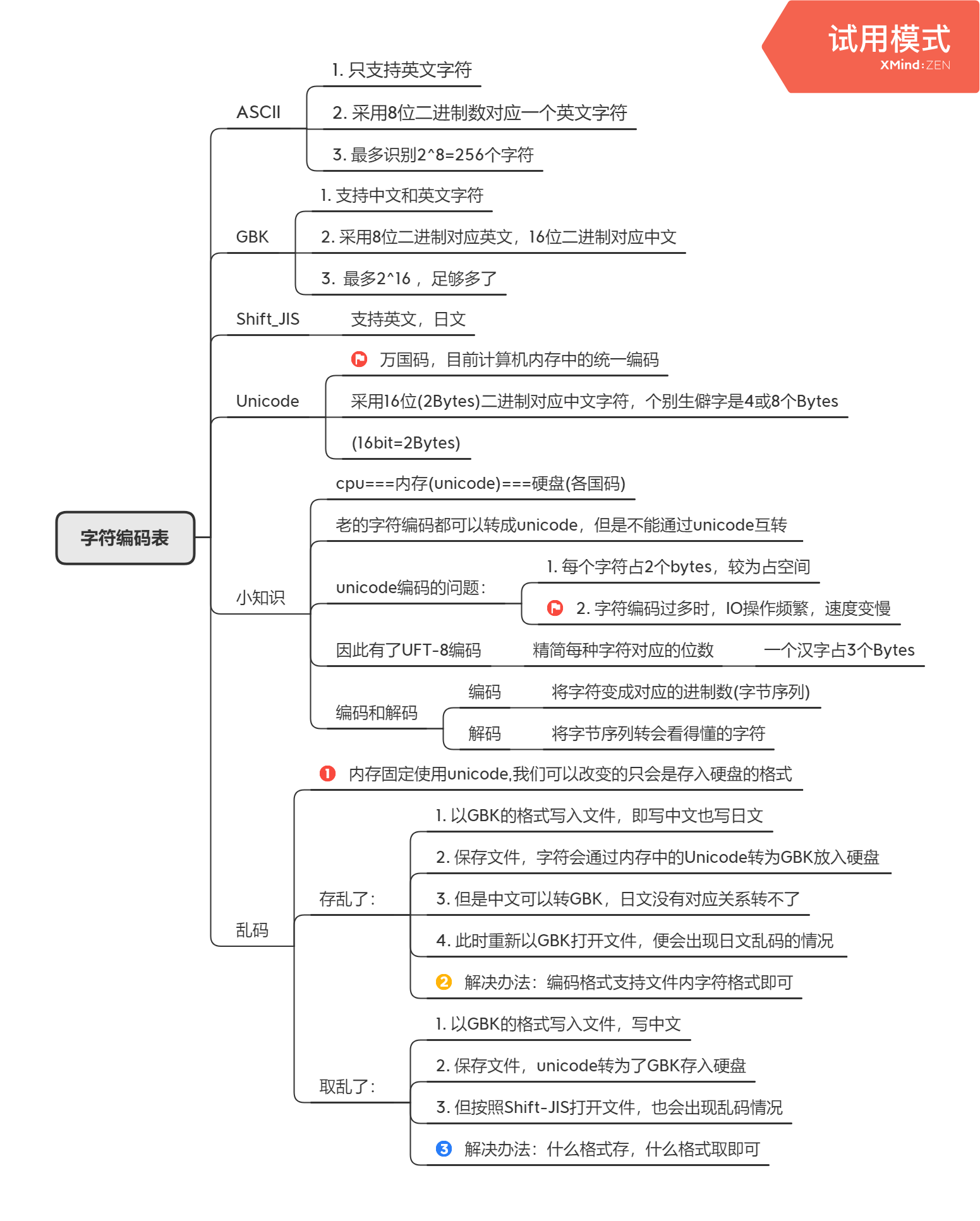
字符编码表
python解释器和编码

编码与解码

文件及操作
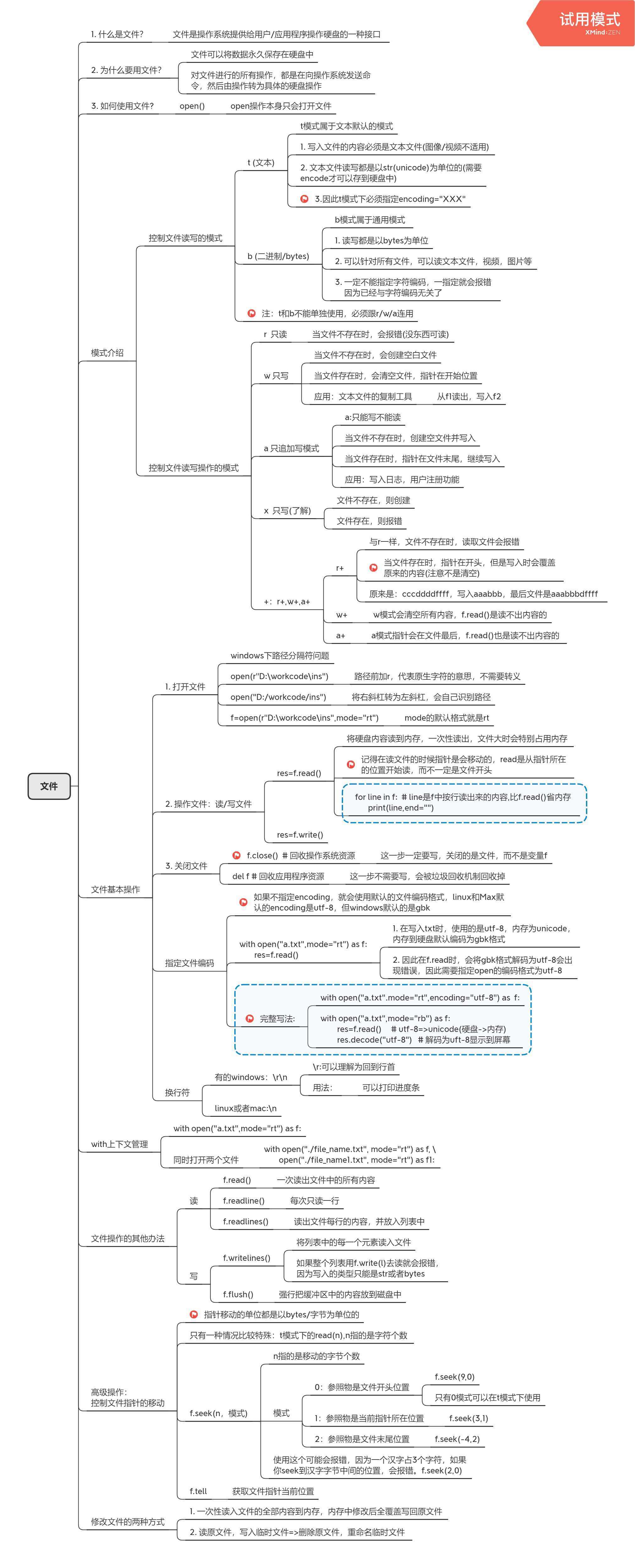
文件修改的方式
# 文件a.txt内容如下张一蛋 山东 179 49 12344234523李二蛋 河北 163 57 13913453521王全蛋 山西 153 62 18651433422# 执行操作with open('a.txt',mode='r+t',encoding='utf-8') as f:f.seek(9)f.write('<妇女主任>')# 文件修改后的内容如下张一蛋<妇女主任> 179 49 12344234523李二蛋 河北 163 57 13913453521王全蛋 山西 153 62 18651433422# 强调:# 1、硬盘空间是无法修改的,硬盘中数据的更新都是用新内容覆盖旧内容# 2、内存中的数据是可以修改的# 3、我们平时修改的文本编辑器,其实改的是内存中的内容,当你按下ctrl+S时,才会重新写入硬盘
# 边打开边写入:文件会被直接清空,也没有任何内容输出。with open('file_n.txt', mode='rt', encoding='utf-8') as f:with open('file_n.txt', mode='wt', encoding='utf-8') as f1:res = f.read().replace("1", "aaa")f1.write(res)# 方式一with open('db.txt',mode='rt',encoding='utf-8') as f:data=f.read()with open('db.txt',mode='wt',encoding='utf-8') as f:f.write(data.replace('kevin','hahaha'))"""实现思路:将文件内容发一次性全部读入内存,然后在内存中修改完毕后再覆盖写回原文件- 优点: 在文件修改过程中同一份数据只有一份- 缺点: 会过多地占用内存(也有断电清空内容的风险)"""
import oswith open('db.txt',mode='rt',encoding='utf-8') as read_f,\open('.db.txt.swap',mode='wt',encoding='utf-8') as wrife_f:for line in read_f:wrife_f.write(line.replace('SB','kevin'))os.remove('db.txt') # 删除原来的文件os.rename('.db.txt.swap','db.txt') # 重命名新的文件"""实现思路:以读的方式打开原文件,以写的方式打开一个临时文件,一行行读取原文件内容修改完后写入临时文件,删掉原文件,将临时文件重命名原文件名- 优点: 不会占用过多的内存- 缺点: 在文件修改过程中同一份数据存了两份"""
文件中的一些坑(+模式)
# 前提文件内容为:with open(r"file_n.txt", mode="wt", encoding="utf-8") as f:f.write("123\n456\n中文字符\n")# 写入后的文件内容:123456中文字符#### 写出一下语句输出内容和文件中的内容# 语句一with open(r"file_n.txt", mode="r+t", encoding="utf-8") as f:f.write("88")res = f.read()print(res)"""# 输出内容:3456中文字符# 文件内容:883456中文字符出现原因:r+模式:- r+模式下写入 是从文件首部进行覆盖,因此88会覆盖原来的12- f.write之后文件指针的位置在88之后,因此从88之后开始读取文件"""## 语句二with open(r"file_n.txt", mode="w+t", encoding="utf-8") as f:f.write("88")res = f.read()f.write("66")print(res)"""# 输出内容无内容输出# 文件内容8866出现原因:w+模式- w 模式打开文件,就会将原来的文件清空。- w+模式后又写入了88,文件指针在88之后,因此读不出来内容"""## 语句3with open(r"file_n.txt", mode="wt", encoding="utf-8") as f:pass"""即使没有内容运行,open()以w模式打开文件,文件也会被清空"""## 语句4with open(r"file_n.jpg", mode="rt", encoding="utf-8") as f:pass"""以t模式,打开非文本文件,即使指定了编码,也不会报错。因为这条语句仅仅是打开了文件,并没有进行任何操作"""
关于读的一些操作(循环读取文件)
for
with open(r"test.txt", mode="rt", encoding="utf-8") as f:for line in f: # 按行读文件f.read(line)with open(r"test.jpg", mode="rb") as f:for line in f: # 按行读文件f.read(line)
while
with open(r'test.jpg',mode='rb') as f:while True:res=f.read(1024) # 每次读1024个字节if not res: # 判断一下是否还有字节,没有字节就跳出breakprint(res)"""注:当文件一行内容过多时,使用for循环按行读取可能会占用内存过多,最好还是使用while根据指定字节数读取"""
关于写的一些操作(重点为wb模式)
In[1]:"哈哈哈".encode("utf-8")Out[1]: b'\xe5\x93\x88\xe5\x93\x88\xe5\x93\x88'In[2]:bytes("哈哈哈",encoding="utf-8")Out[2]: b'\xe5\x93\x88\xe5\x93\x88\xe5\x93\x88'In[3]:"哈哈哈".encode("gbk")Out[3]: b'\xb9\xfe\xb9\xfe\xb9\xfe'In[4]:bytes("哈哈哈",encoding="gbk")Out[4]: b'\xb9\xfe\xb9\xfe\xb9\xfe'In[5]:bytes("abc123",encoding="utf-8")Out[5]: b'abc123'In[6]:"abc123".encode("utf-8")Out[6]: b'abc123'
f.writelines()
with open(r"file_n.txt", mode="wt", encoding="utf-8") as f:# 只写444会报错的,只要不是字符串或者bytes类型都会报错,无法写入l = ["第一个", "第二个", "第三个", "555"]f.writelines(l)# f.write(l)>>> 文件内容为 "第一个第二个第三个555"with open(r"file_name.txt", mode="wb") as f:# 如果是b模式,写入的内容可以编码转化# l1 = [# "111".encode("utf=8"),# "222".encode("utf-8"),# "ccc".encode("utf-8")# ]# 1. 但如果只有英文和数字,可以直接加前缀b得到bytes类型l1 = [b"111",b"222",b"ccc"]# 2. '中文'.encode("utf-8")等同于bytes("中文", encoding="utf-8")l1 = [bytes("哈哈哈", encoding="utf-8"),bytes("你好", encoding="utf-8"),bytes("我爱你", encoding="utf-8")]f.writelines(l1)
f.flush()
with open(r"file_n.txt", mode="wt", encoding="utf-8") as f:# 只写444会报错的,只要不是字符串或者bytes类型都会报错,无法写入ls = ["第一个", "第二个", "第三个", "555"]f.writelines(ls)f.flush() #强行把缓冲区中的内容放到磁盘中# f.write(l)"""当没有输入回车键时,数据也依然写入到文件中,如果没有flush()方法的话,那么只有按下回车键才会把数据保存到文件中"""
打印进度条(\r)
import timefor i in range(1, 101):# print("\r[{}{} {}/100]".format('#'*i, '-'*(100 - i),i),end="")print(f"\r[{'#' * i}{'-' * (100 - i)} {i}/100]", end="")# print("\r" + "[" + "#" * i + "-" * (100 - i) + " " + str(i) + "/100]", end="")time.sleep(0.1)

若有收获,就点个赞吧
0 人点赞
