一、Redis简介
Redis是单线程+IO复用技术,同时 Redis 的操作也是原子性的。
多路复用
使用一个线程来检查多个文件描述符(Socket)的就绪状态,比如调用select和poll函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回;否则阻塞直到超时。得到就绪状态后进行真正的操作可以在同一个线程里执行,也可以启动线程执行(比如使用线程池)。
原子性
原子操作是指不会被线程调度机制打断的操作。这种操作一旦开始就一直运行到结束,中间不会有任何 context switch(切换到另一个线程)。
- 在单线程中,能够在单条指令中完成的操作都可以认为是“原子操作”,因为中断只能发生于指令之间。
- 在多线程中,不能被其他进程(线程)打断的操作就叫原子操作。
Redis 单命令的原子性主要得益于 Redis 的单线程。
Redis特点如下:
- Redis是一个开源的
key-value存储系统。 - Redis操作都是
原子性的。 - Redis为了保证效率,数据都是
缓存在内存中。 - Redis会
周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件。 - 实现
master-slave(主从)同步。
二、Redis安装
1.1 Redis官网
官网:http://redis.io
中文官网:http://redis.cn
1.2 安装Redis
1.2.1 检查gcc环境
gcc --version
当出现下面内容时,表示已有 gcc 环境,可以直接下一步:
[root@VM-4-8-centos ~]# gcc --version // 命令gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-44) // 版本号Copyright (C) 2015 Free Software Foundation, Inc.This is free software; see the source for copying conditions. There is NOwarranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
如果没有上述内容,执行下面命令:
yum install centos-release-scl scl-utils-buildyum install -y devtoolset-8-toolchainscl enable devtoolset-8 bash
1.2.3 安装redis
通过 xftp 工具将redis 安装包上传到 /opt 目录下。
进入到 /opt目录下,解压 redis 安装包。
// 解压安装包tar -zxvf redis-6.2.1.tar.gz// 进入解压包目录cd redis-6.2.1// 直接输入make命令编译make// 安装make install
安装完毕后,redis 会被安装到/usr/local/bin目录下。
1.3 配置 redis
# 进入 /opt/redis... 目录下# 复制 redis.conf 到 /etc 目录下cp redis.conf /etc/ redis.conf# 进入 etc 目录下cd /etc# 编辑模式打开 redis.confvim redis.conf
开始编辑redis.conf文件:
# 第75行,注释下面代码:取消只能本机访问,让所有网段能访问到Redisbind 127.0.0.1 -::1# 第94行,将yes改为no:将只能本机访问设置为noprotected-mode no# 第247行,将no改为yes:允许后台启动Redisdaemonize yes# 388行# 设置为no:当 Redis 无法写入磁盘的话,直接关掉 Redis 的写操作# 如果这里不设置为 no 的话,一会 Redis 就会被关闭# 推荐设置为 true (当无法挂在硬盘时,设置为 no ,方便测试 Redis)stop-writes-on-bgsave-error no# 保存退出
1.4 启动Redis
# 进入到 redis 安装目录cd /usr/local/bin# 后台启动 redisredis-server /etc/redis.conf# 前台启动 redis:能看到日志,但是窗口关闭 Redis 就关闭了redis-server# 访问redisredis-cli# 多个端口指定端口号访问redis-cli -p 6379# 测试redis是否连接成功127.0.0.1:6379> pingPONG# redis关闭redis-cli shutdown或者127.0.0.1:6379> shutdownexit# 指定端口号关闭redis-cli -p 6379 shutdown
1.5 安装目录介绍
| redis-benchmark | 性能测试工具 |
|---|---|
| redis-check-aof | 修复有问题的AOF文件 |
| redis-check-dump | 修复有问题的dump.rdb文件 |
| redis-sentinel | Redis集群使用 |
| redis-server | Redis服务器启动命令 |
| redis-cli | 客户端,操作入口 |
三、常用五大数据类型
2.1 key常用操作
| keys * | 查看当前库所有的 key |
|---|---|
| keys *10 | 查看指定库的所有 key(验证获取不到) |
| exists key | 判断某个 key 是否存在 |
| type key | 查看 key 的类型 |
| del key | 删除指定 key 数据,同时 key 也没有了 |
| unlink key | 根据 value 选择非阻塞删除:仅将 key 从 keyspace 元数据中删除,真正的删除会在后续异步操作执行 |
| expire key 10 | 为给定的 key 设置 10 秒过期时间 |
| ttl key | 查看还有多少秒过期。 -1:表示永不过期 -2:表示已过期 |
| select 1 | 切换数据库(0-15) |
|---|---|
| dbsize | 查看当前数据库的 key 的数量 |
| flushdb | 清空当前库 |
| flushall | 清空所有库 |
2.2 String常用操作
2.2.1 String 数据结构
String 的数据结构为简单动态字符串(Simple Dynamic String,缩写 SDS)。是可以修改的字符串,内部结构实现上类似于 Java 的 ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配。
capacity是当前字符串实际分配的空间,一般高于实际字符串长度len。- 当字符串长度小于
1M时,扩容都是加倍现有的空间;如果超过1M,扩容时一次只会多扩充1M的空间。 - 字符串最大长度为
512M。
String类型是一个 key 对应一个 value。同时它是二进制安全的,所以 Redis 的 String 可以包含任何数据。比如jpg图片或者序列化对象。
2.2.2 String 常用命令
| set [key] [value] | 添加键值对 |
|---|---|
| get [key] | 查询对应 key 的值 |
| append [key] [value] | 将给定的 value 追加到原值的末尾 |
| strlen [key] | 获取值的长度 |
| setnx [key] [value] | 只有在 key 不存在时,设置key的值 |
| incr [key] | 将key中存储的数字值增1,只能对数字值操作,如果为空,新增值为1 |
| decr [key] | 将key中存储的数字值减1,只能对数字值操作,如果为空,新增值为-1 |
| incrby [key] [步长] | 将key中存储的数字值增加,增加值为步长 |
| decrby [key] [步长] | 将key中存储的数字值减少,减少值为步长 |
| mset [k1] [v1] [k2] [v2] … | 同时设置1个或多个value |
| mget [k1] [k2] … | 同时获取一个或多个value |
| msetnx [k1] [v1] [k2] [v2] … | 同时设置一个或多个key-value对,当且仅当所有给定的key都不存在 |
| getrange [key] [起始位置] [结束位置] | 获得值的范围,类似java中的substring,前包后包,如果结束位置为-1,则表示到最后 |
| setrange [key] [起始位置] [value] | 用value覆写key所存储的字符串值,从[起始位置]开始(索引从0开始) |
| setex [key] [过期时间] [value] | 设置键值的同时,设置过期时间,单位秒 |
| getset [key] [value] | 以新换旧,设置了新值同时获得旧值 |
2.2.3 Redis 提示释义
在 Redis 中输入 set 命令时,后面会跟有提示,内容如下:
set key value [EX seconds|PX milliseconds|EXAT timestamp|PXAT milliseconds-timestamp|KEEPTTL] [NX|XX] [GET]
| NX | 当数据库中 key 不存在时,可以将 key-value 添加到数据库 |
|---|---|
| XX | 当数据库中 key 存在时,可以将 key-value 添加到数据库,与 NX 参数互斥 |
| EX | key 的超时秒数 |
| PX | key 的超时毫秒数,与 EX 互斥 |
2.3 List常用操作
2.3.1 List 数据结构
Redis列表是简单的字符串列表,按照插入顺序排序。可以添加一个元素到列表头部(左边)或者尾部(右边)。List的数据结构为快速链表quickList。
首先在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist,也就是压缩列表。它将所有的元素紧挨在一起存储,分配的是一块连续的内存。
当数据量比较多的时候才会改成quicklist。因为普通的链表需要的附加指针空间太大,会比较浪费空间。比如这个列表里存的只是int类型的数据,结构上还需要两个额外的指针prev和next。
Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针串起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。

2.3.2 List 常用命令
| lpush [k1] [v1] [k2] [v2] … | 从左边插入一个或多个值 |
|---|---|
| rpush [k1] [v1] [k2] [v2] … | 从右边插入一个或多个值 |
| lpop [key] | 从左边吐出一个值,值在键在,值光键亡 |
| rpop [key] | 从右边吐出一个值,值在键在,值光键亡 |
| rpop|push [k1] [k2] | 从 k1 列表右边吐出一个值,插到 k2 列表左边 |
| lrange [key] [start] [stop] | 按照索引下标获得元素(从左到右) |
| lrange [key] 0 -1 | 0左边第一个,-1 右边第一个,(0 -1 表示获取所有) |
| lindex |
按照索引下标获得元素(从左到右) |
| llen |
获得列表长度 |
| linsert |
在 value 的后面插入 newValue 值 |
| lrem |
从左边删除 n 个 value (从左到右) |
| lset |
将列表 key 下标为 index 的值替换成 value |
2.4 Set常用操作
2.4.1 Set 数据结构
Redis的set对外提供的功能与list类似,都是一个列表的功能,特殊之处在于set是可以自动重排的,当你需要存储一个列表数据,又不希望出现重复数据时,set是很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
Redis的set是String类型的无序集合,其数据结构是dict字典,底层是一个value为null的hash表,所以添加、删除、查找的复杂度都是O(1)。
一个算法,随着数据的增加,执行时间的长短,如果是 O(1),那么随着数据增加,查找数据的时间不变。
2.4.2 Set 常用命令
| sadd [key] [v1] [v2] … | 将一个或多个 member 元素加入到集合key中,已经存在的 member 元素将被忽略 |
|---|---|
| smembers [key] | 取出指定集合的所有值 |
| sismember [key] [value] | 判断集合 key 是否含有value这个值,1表示有,0表示没有 |
| scard [key] | 返回该集合的元素个数 |
| srem [key] [v1] [v2] … | 删除集合中的元素 |
| spop [key] | 随机从集合中吐出一个值 |
| srandmember [key] [n] | 随机从该集合中取出n个值。不会从集合中删除。 |
| smove [source] [destination] [value] | 把集合中一个值从一个集合移动到另一个集合 |
| sinter [k1] [k2] | 返回两个集合的交集元素 |
| sunion [k1] [k2] | 返回两个集合的并集元素 |
| sdiff [k1] [k2] | 返回两个集合的差集元素(k1中的,不包含k2中的) |
2.5 Hash常用操作
2.5.1 Hash 数据结构
Hash类型对应的数据结构是两种:ziplist 压缩列表和hashtable 哈希表。当field-value长度较短且个数较少时,使用ziplist,否则使用hashtable。
2.5.2 Hash 常用命令
| hset [key] [field] [value] | 给key集合中的 field 键赋值 value |
|---|---|
| hget [key] [field] | 从key集合 field 取出 value |
| hmset [k1] [field1] [value1] [field2] [value2] … |
批量设置 hash 的值 |
| hexists [key] [field] | 查看哈希表key中,给定的 field 是否存在 |
| hkeys [key] | 列出该 hash 集合的所有 field |
| hvals [key] | 列出该 hash 集合的所有 value |
| hincrby [key] [field] [increment] | 为哈希表 key 中的域 field 的值加上增量 1 -1 |
| hsetnx [key] [field] [value] | 将哈希表 key 中的域 field 的值设置为 value,当且仅当域 field 不存在 |
2.6 Zset常用操作
2.6.1 Zset 数据结构
Redis 有序集合zset和普通集合set非常相似,是一个没有重复元素的字符串集合。
不同之处是有序集合的每个成员都关联了一个评分(score),这个评分(score)会将集合中的成员按照从最低分到最高分的方式排列。
集合的成员是唯一的,但是评分是可以重复的。
因为元素是有序的,所以可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。访问有序集合的中间元素也是非常快的,因此可以将zset作为一个没有重复成员的智能列表。
SortedSet(zset)是一个特别的数据结构,一方面等价于 Java 的数据结构 Map<String,Double>,可以给每一个元素 value 赋予一个权重 score,另一方面它又类似于 TreeSet,内部的元素会按照权重 score 进行排序,可以得到每个元素的名字,还可以通过 score 的范围来获取元素的列表。
zset 底层使用了两个数据结构:
hash:关联元素 value 和权重 score,保证元素 value 的唯一性,可以通过元素 value 找到相应的 score 值。跳跃表:跳跃表的目的是在于给元素 value 排序,根据 score 的范围获取元素列表。
2.6.2 跳跃表(跳表)
有序集合比较常见,例如根据成绩对学生排名,根据得分对玩家排名等。对于有序集合的底层实现,可以用数组、平衡树、链表等:
- 数组不变元素的插入、删除;
- 平衡树或红黑树虽然效率高但结构复杂;
- 链表查询需要遍历所有效率低;
- 跳跃表效率堪比红黑树,实现远比红黑树简单。
有序列表的查询
有序列表的查询是按照顺序一步一步往下查询,数据越多查询越慢。
跳跃表的查询
跳跃表的查询,先查第2层,当比这个值小时,往前查,当比这个值大时往后查;当第二次没有找到开始查询第一层,数据多时查询速度比较快。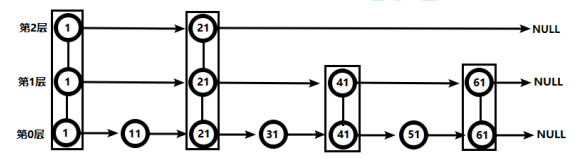
2.6.3 Zset 常用命令
| zadd [key] [score1] [value1][score2] [value2] … | 将一个或多个member元素及其 score 值加入到有序集key中。 |
|---|---|
| zrange [key] [start] [stop] [WITHSCORES] | 返回有序集合key中,下标在 start 和 stop 之间的元素,带 WITHSCORES 可以让分数一起和值返回到结果集。 |
| zrangebyscore key minmax [withscores] [limit offset count] | 返回有序集key中,所有score值介于min和max之间(包括等于min和max)的成员。有序集成员按score值递增(从小到大)次序列。 |
| zrevrangebyscore key maxmin [withscores] [limit offset count] | 同上,改为从大到小排列。 |
| zincrby [key] [increment] [ value] | 为元素的score加上增量。 |
| zcount [key] [min] [max] | 统计该集合,分数区间内的元素个数。 |
| zrank [key] [value] | 返回该值的集合中的排名,从 0 开始。 |
| zrem [key] [value] | 删除该集合下,指定值的元素。 |
四、Redis6配置文件
Redis 的配置文件位于:/解压包目录/redis.conf。
4.1 单位:Units
配置大小单位,开头定义了一些基本的度量单位,只支持bytes,不支持bit。大小写不敏感。
# 1k => 1000 bytes# 1kb => 1024 bytes# 1m => 1000000 bytes# 1mb => 1024*1024 bytes# 1g => 1000000000 bytes# 1gb => 1024*1024*1024 bytes
4.2 引入:INCLUDES
引入其他的配置文件,多实例的情况可以把公用的配置文件提取出来。
# include /path/to/local.conf# include /path/to/other.conf
4.3 网络:NETWORK
# 默认只能本机访问,因此我们需要注释掉这一行代码# 注释掉就表示允许任何 ip 访问# 生产环境肯定要写你应用服务器的地址;服务器是需要远程访问的,所以需要将其注释掉bind 127.0.0.1 -::1# 本机访问保护模式,默认值为 yes,我们需要修改成 no,才能配合bind让我们远程访问protected-mode no# Redis的默认端口号port 6379# 设置 top 的backlog。# backlog 是一个连接队列,backlog 队列总和 = 未完成三次握手队列 + 已完成三次握手队列# 高并发环境下需要也高 backlog 值来避免慢客户端连接问题# Linux内核会将这个值减小到 /proc/sys/net/core/somaxconn 的值(128)# 所以需要确认增大 /proc/sys/net/core/somaxconn 和 /proc/sys/net/ipv4/tcp_max_syn_backlog(128)# 两个值来达到想要的效果tcp-backlog 511# 一个空闲的客户端维持多少秒会关闭。# 0表示关闭该功能,即永不关闭。timeout 0# 对访问客户端的一种心跳检测,每过 n 秒检测一次# 单位为秒,如果设置为0,则不会进行 Keepalive 检测,建议设置为 60tcp-keepalive 300
4.4 全体的:GENERAL
# 是否为后台进程,默认为 no# 需要设置为 yes,守护进程,后台启动daemonize yes# 存放pid文件的位置,每个实例会产生一个不同的pid文件pidfile /var/run/redis_6379.pid# 指定日志记录级别:dubug、verbose、notice、warning,默认为:noticeloglevel notice# 日志文件名称logfile ""# 设置库的数量,默认为16。# 默认使用的数据库为 0# 可以使用 select <index> 命令在连接上指定数据库 iddatabases 16
4.5 安全:SECURITY
# 设置 Redis 的密码# 在命令行中配置,重启 redis 后密码还原# 永久设置密码需要在配置文件中设置requirepass foobared
在命令行中设置 Redis 临时密码:
# 连接上 redis 后# 查看redis密码配置config get requirepass# 设置redis密码,设置完后,上面的命令就会失败,需要使用下面的命令之后才能后续操作config set requirepass "123456"# 验证密码auth 123456
4.6 限制:LIMITS
# 【此行配置被注释】# 设置redis同时可以与多少个客户端进行连接# 默认情况下为 10000 个客户端# 如果达到了此限制,redis会拒绝新的连接请求,并且想这些连接请求方发出:# “max number of clients reached” 以作回应maxclients 10000# 【此行代码被注释】# 设置 redis 可以使用的内存量。# 1:一旦到达内存使用上限,redis 将会试图移除内部数据,# 移除规则可以通过 maxmemory-policy 来指定;# 2:如果 redis 无法根据移除规则来移除内存中的数据,或者设置了“不允许移除”,# 那么 redis 则会针对那些需要申请内存的指令返回错误信息,比如 SET、LPUSH等;# 3:但对于无内存申请的指令,仍然会正常响应,比如 GET 等。# 如果当前 redis 是主 redis (说明当前 redis 有从 redis),那么在设置内存使用# 上限时,需要在系统中留出一些内存空间给同步队列缓存,只有在你设置的是“不移除”# 的情况下,才不用考虑这个因素。# 建议 【必须设置】,否则内存占满,造成服务器宕机maxmemory <bytes># 【此行代码被注释】# 内存到达使用上限,会试图按照移除规则进行移除,共有以下几种配置:# 1:volatile-lru:使用 LRU 算法移除 key,只对设置了【过期时间】的键;(最近最少使用规则)# 2:allkeys-lru:在所有集合 key 中,使用 LRU 算法移除 key。# 3:volatile-random:在过期集合中移除随机的 key,只对设置了过期时间的键。# 4:allkeys-random:在所有集合 key 中,移除随机的 key。# 5:volatile-ttl:移除那些 TTL 值最小的 key,即那些最近要过期的 key。# 6:noeviction:不进行移除。针对写操作,只是返回错误信息。maxmemory-policy noeviction# 【此行代码被注释】# 设置样本数量,LRU 算法和最小 TTL 算法都并非是精确的算法,而是估算值,所以可以# 设置样本的大小,redis 默认会检查这么多个 key 并选择其中 LRU 的那个。# 一般设置 3 到 7 的数字,数值越小样本越不不准确,但性能消耗越小。maxmemory-samples 5
五、Redis6发布与订阅
5.1 发布和订阅概念
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。Redis 客户端可以订阅任意数量的频道。当这个频道发布消息后,消息就会发送给所有订阅该频道的客户端。
发布的消息没有持久化,只能收到订阅后发布的消息;订阅前的消息收不到。
5.2 实例代码
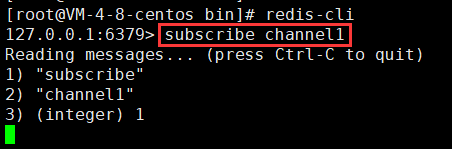
步骤1:打开客户端 A,订阅 channel1(通道名可以随便起)
# 订阅通道subscribe channel1
步骤2:打开客户端 B,给通道 channel1 发布消息
# 给通道发送消息publish channel1 HelloRedis!!!

步骤3:打开客户端 A , 查看订阅到的消息
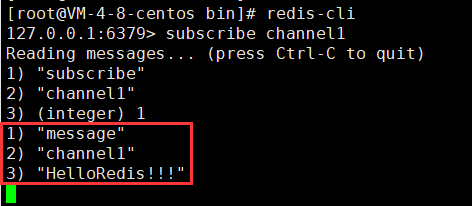
六、Redis6新类型数据
6.1 Bitmaps
6.1.1 Bitmaps 简介
字符串“abc”由 3 个字节组成,但在计算机存储时将其用二进制存储,“abc”分别对应 ASCII 码分别是 97、98、99,对应的二进制分别是 01100001、01100010、01100011。
合理的使用操作位能够有效地提高内存使用率和开发效率。
Redis 提供了 Bitmaps 这个“数据类型”可以实现对位的操作:
- Bitmaps 不是一种数据类型,实际上就是字符串(key-value),但是它可以对字符串的位进行操作。
- Bitmaps 单独提供了一套命令,所以在 Redis 中使用 Bitmaps 和使用字符串的方法不相同。可以把 Bitmaps 想象成一个以位为单位的数组,数组的每个单元只能存储 0 和 1,数组的下标在 Bitmaps 中叫做偏移量。
6.1.2 Bitmaps 命令
设置命令:setbit
# offset:偏移量从 0 开始setbit [key] [offset] [value]
实例:
将每个独立用户是否访问过网站存放在 Bitmaps 中,将访问的用户记作 1,没有访问的用户记作 0,用偏移量作为用户的 id。
设置键的第 offset 个位的值(从0算起),假设现在有 20 个用户,userid = 1、6、11、15、19 的用户对网站进行了访问,那么当前 Bitmaps 初始化结果如下图:
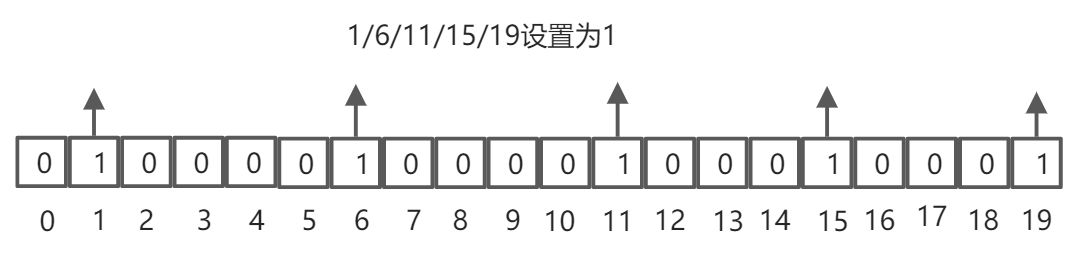
存储 Bitmaps 时,key 为 unique:users:20220126 代表 2022-01-26 这天的独立访问用户的 Bitmaps,命令如下: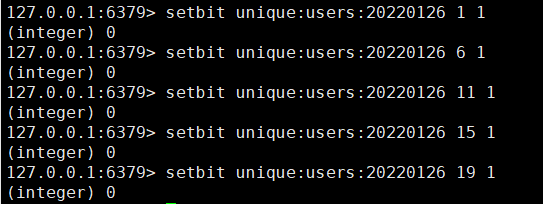
注意:
很多应用的用户 id 以一个指定数字(例如 10000)开头,直接将用户 id 和 Bitmaps 的偏移量对应,这样会造成一定的浪费(也就是:setbit userid_1000 1000 1,这里偏移了1000),通常的做法是每次做 setbit 操作时将用户 id 减去这个指定数字。
在第一次初始化 Bitmaps 时,加入偏移量非常大,那么整个初始化过程执行会比较慢,可能会造成 Redis 的阻塞。
获取命令:getbit
# 获取 Bitmaps 中某个偏移量的值getbit [key] [offset]
分别获取 id = 100/15/5 的用户是否在 2022-01-26 这天访问过,返回 0 说明没有访问过,返回 1 说明访问过。这里 100 的用户因为不存在,所以肯定是返回 0。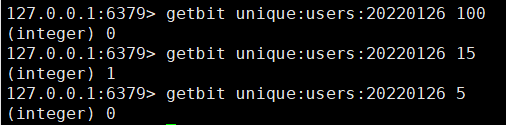
统计命令:bitcount
# 统计字符串被设置为 1 的 bit 数# start 和 end 都可以使用负数: -1:表示最后一位 -2:表示倒数第二位bitcount [key] [start] [end]

这里的下标指的是字节的下标,而不是位的下标,例如(00001111)这里 start 和 end 都传入 0,则返回的值是 4。因为按照字节计算下标,而不是按照位的下标来计算,如果按照位来计算,传入的 end 值为7,参照下方命令结果: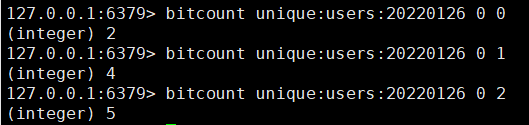
【注意】redis 的 setbit设置或清除的是bit位置,而bitcount计算的是byte位置。
复合操作:bitop
# 将多个 Bitmaps 的 and(交集)、or(并集)、not(非)、xor(异或) 操作# 并将结果保存在 destkey 中bitop [and/or/not/xor] [destkey] [key...]
实例:
# 2022年1月1日访问网站的用户有:1、2、5、9setbit user_20220101 1 1setbit user_20220101 2 1setbit user_20220101 5 1setbit user_20220101 9 1# 2022年1月2日访问网站的用户有:0、1、4、9setbit user_20220102 0 1setbit user_20220102 1 1setbit user_20220102 4 1setbit user_20220102 9 1
计算出两天都访问过网站的用户数量:2
计算出两天都访问过网站的用户数量(类似月活):6
6.1.3 Bitmaps 与 set 对比
假设网站有1亿用户,每天独立访问的用户5千万,如果每天用集合类型和Bitmaps分别存储用户得到的表如下:
| set 和 Bitmaps 存储一天活跃用户对比 | |||
|---|---|---|---|
| 数据类型 | 每个用户id占用空间 | 需要存储的用户量 | 全部内存量 |
| 集合类型 | 64位 | 5000万 | 64*0.5亿=400MB |
| Bitmaps | 1位 | 1亿 | 1*1亿=12.5M |
set占用8个字节,共64位,而 Bitmaps 只占用1位。set需要存储5000万的活跃用户,而Bitmaps 需要存储所有的用户,只有活跃的用户将值存为 1,其他存为 0。
按照上面的方式计算,得到下面的对比表:
| set 和 Bitmaps 存储独立用户空间对比 | |||
|---|---|---|---|
| 数据类型 | 一天 | 一个月 | 一年 |
| 集合类型 | 400M | 12GB | 144GB |
| Bitmaps | 12.5MB | 375M | 4.5G |
当然 Bitmaps 的缺陷是,当该网站每天的独立访问用户很少,比如只有10万活跃用户(大量的僵尸用户),那么Bitmaps将会存储大量的 0 ,对比如下表:
| set 和 Bitmaps 存储一天活跃用户对比(独立用户少) | |||
|---|---|---|---|
| 数据类型 | 每个userid占用空间 | 需要存储的用户量 | 全部内存量 |
| 集合类型 | 64位 | 10万 | 64*10万=800KB |
| Bitmaps | 1位 | 1亿 | 1*1亿=12.5M |
6.2 HyperLogLog
6.2.1 HyperLogLog 简介
在统计相关的功能需求中,如统计网站PV(PageView页面访问量),可以使用Redis的incr、incrby轻松实现。但像UV(UniqueVisitor,独立访客)、独立IP数、搜索记录数等需要去重和计数的问题如何解决?这种求集合中不重复元素个数的问题称为基数问题。
解决基数问题有很多种方案:
- 数据存储在MySQL表中,使用distinct count计算不重复个数
- 使用Redis提供的hash、set、bitmaps等数据结构来处理
上面方案结果精确,但随着数据不断增加,导致占用空间越来越大,对于非常大的数据集是不切实际的。
Redis 推出了HyperLogLog,它降低一定的精度来平衡存储空间。HyperLogLog的优点是,在输入元素的数量或者体积非常大时,计算基数所需的空间总是固定的、并且是很小的。
在Redis 里面,每个HyperLogLog键只需要花费12KB内存,就可以计算接近 2^64个不同元素的基数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。但是,因为HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以HyperLogLog不能像集合那样,返回输入的各个元素。
什么是基数?
比如数据集{1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。
6.2.2 HyperLogLog 命令
添加命令:pfadd
# 添加指定元素到 HyperLogLog 中pfadd [key] [element...]
将元素添加到HyperLogLog数据结构中,如果执行命令后HyperLogLog估计近似基数发生变化,则返回 1,否则返回 0。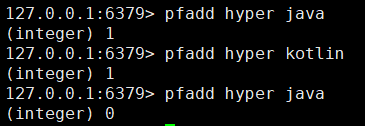
计算个数:pfcount
# 计算HyperLogLog近似基数,可计算多个pfcount [key...]

合并结果:pfmerge
# 将一个或多个HyperLogLog合并后的结果存储在另一个HyperLogLog上# 比如每月活跃用户可以使用每天活跃用户合并计算pfmerge [destkey] [sourcekey...]
6.3 Geospatial
GEO:Geospatial,地理信息的缩写。Geospatial就是元素的2维坐标,在地图上就是经纬度。Redis 基于该类型,提供了经纬度设置、查询、范围查询、距离查询、经纬度Hash等操作。
添加命令:geoadd
# 添加一个或多个地理位置(经度、维度、名称)geoadd [key] [longitude] [latitude] [member] ...
两级无法直接添加,一般操作为先下载城市数据,直接通过 Java 程序一次性导入。
其中,有效的经度从 -180 度到 180 度,有效的维度从 -85.05112878 度到 85.05112878 度。当坐标位置超过指定范围时,该命令将会返回一个错误。已经添加的数据,无法再次添加。
geoadd china:city 121.47 31.23 shanghaigeoadd china:city 106.50 29.53 chongqinggeoadd china:city 114.05 22.52 shenzhengeoadd china:city 116.38 39.90 beijing
获取:geopos
# 获取指定区域的坐标值geopos [key] [member...]

获取直线距离:geodist
# 获取两个位置之间的直线距离,但是 m/km 等# m(默认值)、km、mi(英里)、ft(英尺)gendist [key] [member1] [member2] [m|km|ft|mi]

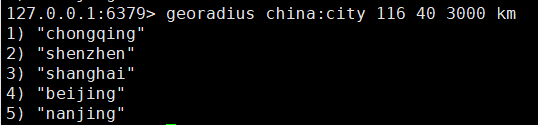
获取半径内元素:georadius
# 以给定的经纬度为中心,找出某一半径内的元素georadius [key] [longitude] [latitude] [radius] [m|km|ft|mi]
七、Jedis操作Redis
7.1 Jedis 依赖包
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>3.2.0</version></dependency>
7.2 连接 Jedis
public static void main(String[] args) {// 主机号String host = "124.223.64.141";// 端口号int port = 6379;// 创建 jedis 对象Jedis jedis = new Jedis(host, port);// 测试:返回 PONG 表示连接成功String ping = jedis.ping();System.out.println(ping);// 关闭 jedisjedis.close();}
7.3 Jedis 示例
需求如下:
- 输入手机号,点击发送后随机生成 6 位数字码,2分钟有效;
- 输入验证码,点击验证,返回成功或失败;
- 每个手机号每天只能输入 3 次;
八、SpringBoot与Redis整合
九、Redis与事务
十、Redis持久化与RDB
十一、Redis持久化与AOF
十二、Redis与主从复制
十三、Redis与集群
十四、Redis应用问题
十五、Redis新功能

若有收获,就点个赞吧
0 人点赞
