作者: Kaelzhang 链接:http://kaelzhang81.github.io/2016/04/21/%E5%8F%AF%E4%BC%B8%E7%BC%A9%E6%80%A7%E5%85%A5%E9%97%A8/
最近常被问到怎样能让web服务具备大规模伸缩能力。由于我的回答较长、其它人也可能对此感兴趣,因此我把解答在博客上以多篇博文的形式进行了分享。新的文章会定期更新。欢迎大家查阅和评论!
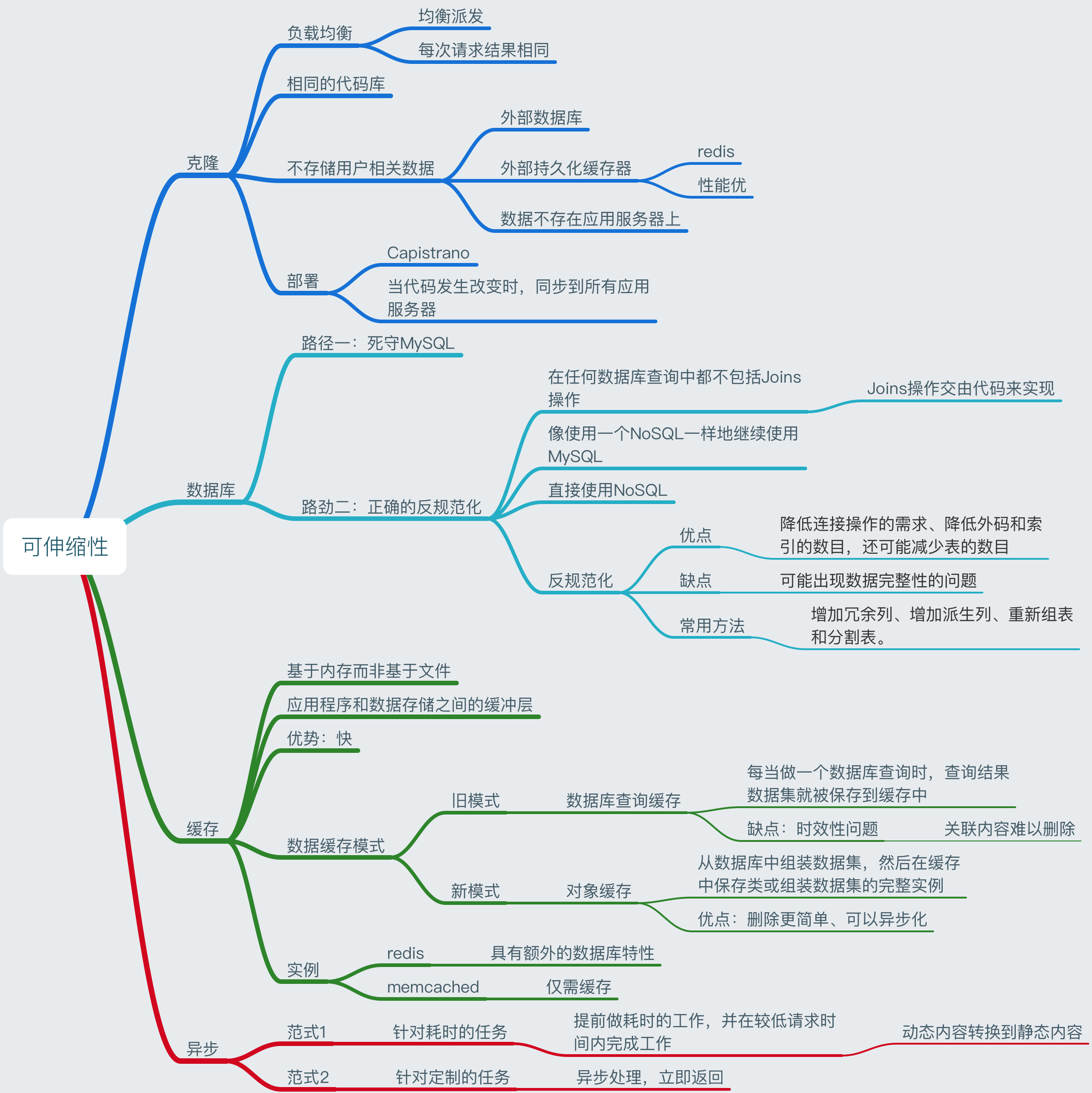
第一章 克隆
具备可伸缩web服务的公有服务器隐藏在负载均衡系统背后。负载均衡系统将来自用户的请求均匀派发到应用服务器组/集群。举个例子:如果用户Steve与你所提供的服务进行交互,他的第一个请求可能被2号服务器处理,第二个请求被9号服务器处理,而他的第三个请求又可能被2号服务器处理。
Steve应该一直得到相同的请求响应结果,而不依赖于他所具体登陆的服务器。这个例子引出可伸缩性的第一个黄金原则:每一个服务器都包含相同的代码库,且不存储用户相关数据(如:本地硬盘和内存上的会话、档案图片)。
会话需要被存放在一个能够被全部应用服务器访问的集中式数据仓储中。它可以是一个外部数据库,也可以是一个外部持久化缓存器(如:Redis)。外部持久化缓存器的性能要优于外部数据库。“外部”意味着数据仓储不在应用服务器上。反之,它位于应用服务器的数据中心内或附近的某个地方。
那部署呢?如何确保代码的一次变更会被发布到所有的服务器,如何确保没有一台服务器还在使用之前的代码呢?这个棘手的问题已经被一款很棒的工具Capistrano解决了(译者注:Capistrano是一款流行的远程系统管理工具)。你需要花精力学习它,特别是当你并不了解Ruby on Rails时(译者注:一个使用Ruby语言写的开源Web应用框架),但是这绝对值得的。
在“外包“你的会话并且使所有服务器共享代码库后,你现在可以从这些服务器之中选一个来创建镜像文件了(AWS称其为AMI-Amazon Machine Image)。使用该AMI作为一个你所有的新实例都基于的“超级克隆器”。每当你启动一个新实例/克隆时,仅需对最新代码做一个初始化部署就搞定了!
第二章 数据库
在第一章克隆之后,你的服务器已经具备水平伸缩的能力且能够支撑数以千计的并发请求了。从某时开始你的应用变得越来越慢,最后崩溃。症结在于你的数据库,它会是MySQL吗?
现在需要比增加更多的克隆服务器更加激进的改变了,这甚至可能需要一些魄力。最后你有两条路可供选择:
第一条路:死守MySQL,继续“野兽般”的运行。雇佣一个数据库管理员(DBA),告诉他做主备复制(从备份读出,并写入主站)并且通过增加内存、内存、更多的内存来升级你的主站。在某些时候,DBA还是会跑过来说出像“分片”,“非规范化”和“SQL调优”等词汇,并担心在接下来的几周必需要加班来处理。此时维持你的数据库的运转的每个新动作都会比之前更昂贵、更费时。你可能最好还是远离它,如果你使用的是路径2的话,你的数据集仍会很小并且易于迁移。
路经二:从一开始就正确地反规范化,在任何数据库查询中都不包括Joins操作。你可以像使用一个NoSQL一样地继续使用MySQL,也可以切换到一个更好、更易于伸缩的NoSQL数据库,如:MongoDB或CouchDB。Joins此时将要在你的应用程序代码来完成。越早做到这一步,未来你将会更少发生地代码变更。但即使成功地切换到最新、最好的NoSQL数据库,并让你的应用程序来完成数据集的Joins操作,很快你的数据库请求将会再次变慢。你将需要引入缓存。
第三章 缓存
依照上一章,你现在有了一个可伸缩的数据库解决方案。仅就你而言不用再害怕TB级存储了,一切看起来都很好。但当大量的数据从数据库中读取的时候,用户仍然不得不忍受缓慢的页面请求,其解决方案是使用缓存。
对于“缓存”,我总是指代内存缓存,如同Memcached或Redis。请永远不要使用基于文件的缓存,它只会给你的服务器的复制和自动伸缩带来痛苦。
但是,让我们回到在内存缓存的话题上。缓存是一个简单的key-value存储,它应作为应用程序和数据存储之间的缓冲层而存在。每当你的应用程序来读取数据,应该首先尝试从缓存中检索数据。仅当数据在缓存中不存在时,才尝试从主数据源获取数据。为什么要这么做呢?因为缓存速度是极快的。它在内存中保存了每个数据集,请求在技术可能的范围得到最快速处理。例如,在标准的服务器上部署的Redis可以达到每秒成千上万次读操作。对于写操作的提升也是非常非常大的。尝试将其与数据库一起使用吧!
有新旧两种数据缓存模式:
1 - 数据库查询缓存 这仍是最常用的缓存模式。每当做一个数据库查询时,查询结果数据集就被保存到缓存中。一个哈希版本的查询是缓存关键。下一次执行查询时,将先在缓存中检测是否已经存在该查询的结果。该模式有几个问题,里面最主要的问题是时效性问题。当你缓存一个复杂查询时,难以删除一个缓存结果(谁没有过呢?)。当一点数据发生变化时(例如表格中的一个单元格),你需要删除所有涵盖该单元格的查询缓存。明白了吧?
2 - 对象缓存 这是我强烈推荐的模式。总之是以对象来看待你的数据,就像你在代码(类,实例等)里已经做的那样。让你的类从数据库中组装数据集,然后在缓存中保存类或组装数据集的完整实例。我知道这听起来比较理论化,但只是看看你的代码一般是怎样的,举个例子:你有一个名为“Product”的类,它有一个名为“data”的属性。“data”是一个包含价格、文本、图片及顾客评价的数组。“data”属性是由类中的几个方法通过几个数据库请求来填充的,由于请求间的关联性是很难以缓存的。现在参照下面去做:当你的类完成了数组的“组装”时,直接存储数组或直接把类的完整实例存到缓存中(更好)!每当发生改变时你就很容易地删除对象,这使代码的整体操作更快,更符合逻辑。
而最好的回报是:它使异步处理成为可能!试想一下,大量工作者(服务器)来帮你组装你对象!应用程序仅使用最新缓存的对象,几乎不再与数据库直接接触了!
对对象缓存的一些想法:
用户会话(不要使用数据库!) 完全渲染博客文章 活动流 用户<->友好关系 正如你可能已经意识到,我是一个缓存的死忠。这是很易于理解的,它非常容易应用且结果也总是令人惊叹的。通常我相较于Memcached我更喜欢Redis,因为Redis具有额外的数据库特性,如:持久性、内置像列表、集合这样的数据结构。通过Redis和一个聪明的键,你甚至可以完全地摆脱数据库。但如果你仅需缓存就使用Memcached吧,因为其伸缩能力令人难以抗拒。
缓存快乐!
第四章 异步
本系列的第四章通过一个情景开始:请想象一下你想在最喜欢的面包店买面包。因此你走进面包房买一个面包,但那里没有面包!相反,你被要求回来在2小时内再回来取你订的面包。这是不是很讨厌?
为了避免这种“请等一会儿”的情况下,需要异步做事。而对面包店有好处的,也许也对Web服务或Web应用有好处。通常有两种方法/异步范式可以做到。
异步#1 让我们回到先前面包店的情景。
异步处理的第一种方式是“晚上烤面包并在早上售卖”的方式。没有在收银台前等待时间和一个愉快的客户。谈回Web应用程序时,这意味着提前做耗时的工作,使得在较低的请求时间内完成工作。
该范例往往用于将动态内容转换为静态内容。一个网站的页面可能使用一个庞大的框架或CMS来构建,每当发生变化时,页面会被预渲染并本地保存为静态HTML文件。通常这些计算任务是定期进行的,也可能由一个脚本每隔一小时被一个cronjob调用(译者注:Cron 是UNIX,SOLARIS,LINUX下的一个十分有用的工具。通过Cron脚本能使计划任务定期地在系统后台自动运行。这种计划任务在UNIX,SOLARIS, LINUX下术语为cron jobs)。该整体数据的预计算可以显著改善网站和网络应用的可伸缩性和性能。试想一下如果脚本上传这些预渲染HTML页面到AWS S3(译注:Amazon Simple Storage Service为开发人员和IT 团队提供安全、耐久且扩展性高的云存储。)、Cloudfront(译注:Amazon CloudFront 是一项全球内容交付网络服务,即CDN)或其他网络加速器后,你的网站的可伸缩性会是怎样?你的网站将具备超凡响应能力,并能每小时处理数以百万计访客量!
异步#2 回到面包店。不幸的是,有时客户有像“生日快乐,史蒂夫!”生日蛋糕这样的个性化需求。面包店无法预见这类客户的期望,因此当客户在面包店时必须启动任务,并告诉他第二天再回来。谈回Web服务时,这意味着异步处理任务。
下面是一个典型的工作流:
用户到你的网站启动一个将需要几分钟来完成的高计算密集型任务。因此网站的前端发送一个任务到任务队列,并立即向用户响应到:你的任务正在工作,请继续浏览页面。任务队列不断被一批工作者检查。如果有一个新的工作工作者此时就会执行该任务,并在一定时间后发送作业已完成的信号。前端会不断检查新的“任务完成”信号,当任务已完成时通知用户。这是一个非常简单的例子。
如果想更深入地了解相关细节和具体技术设计,推荐看一看在RabbitMQ的网站上的前三个教程。 RabbitMQ是有助于实现异步处理众多系统中的一个。你也可以使用ActiveMQ或一个简单Redis列表。基本原理是有一个工作者可以处理任务或工作队列。异步虽然看起来很复杂,但绝对值得你花时间来学习和实践的。在后端具备几乎无限扩展能力的同时前端也变得更佳友好,这是非常棒的整体用户体验。
如果你要做一些费时的事,尽量以异步方式来实现吧。
原文地址:
1.http://www.lecloud.net/post/7295452622/scalability-for-dummies-part-1-clones
2.http://www.lecloud.net/post/7994751381/scalability-for-dummies-part-2-database
3.http://www.lecloud.net/post/9246290032/scalability-for-dummies-part-3-cache
4.http://www.lecloud.net/post/9699762917/scalability-for-dummies-part-4-asynchronism

若有收获,就点个赞吧
0 人点赞
