1、join语句优化
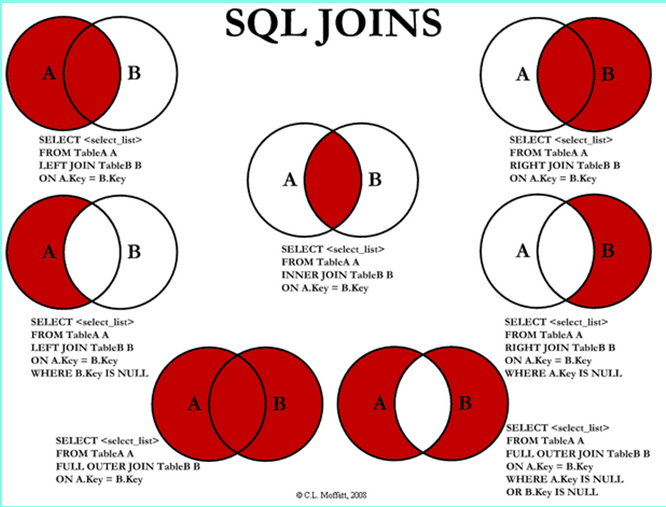
1.1、join种类
cross join
select * from employees a CROSS JOIN salaries b 相当于笛卡尔积,A表记录数 B表记录数
`select from employees a CROSS JOIN salaries b on a.emp_no = b.emp_no` 相当于inner join
1.2、join算法
(1)Simple Nested-Loop Join(简单嵌套循环连接)
简单嵌套循环连接实际上就是简单粗暴的嵌套循环,如果table1有1万条数据,table2有1万条数据,那么数据比较的次数=1万 1万 =1亿次,这种查询效率会非常慢。
当执行select from user A left join level B on A.id=B.id相当于以下伪代码
for(A表的行 r1: A表){for(B表的行 r2: B表){if(r1.id == r2.id){//返回成功匹配的数据}}}
特点:
简单粗暴,效率低
(2)Index Nested-Loop Join(索引嵌套循环连接)
索引嵌套循环连接是基于索引进行连接的算法,索引是基于内层表的,通过外层表匹配条件直接与内层表索引进行匹配,避免和内层表的每条记录进行比较, 从而利用索引的查询减少了对内层表的匹配次数,优势极大的提升了 join的性能:
原来的匹配次数 = 外层表行数 内层表行数 优化后的匹配次数= 外层表的行数 内层表索引的高度
使用场景:只有内层表join的列有索引时,才能用到Index Nested-LoopJoin进行连接。
由于用到索引,如果索引是辅助索引而且返回的数据还包括内层表的其他数据,则会回内层表查询数据,多了一些IO操作。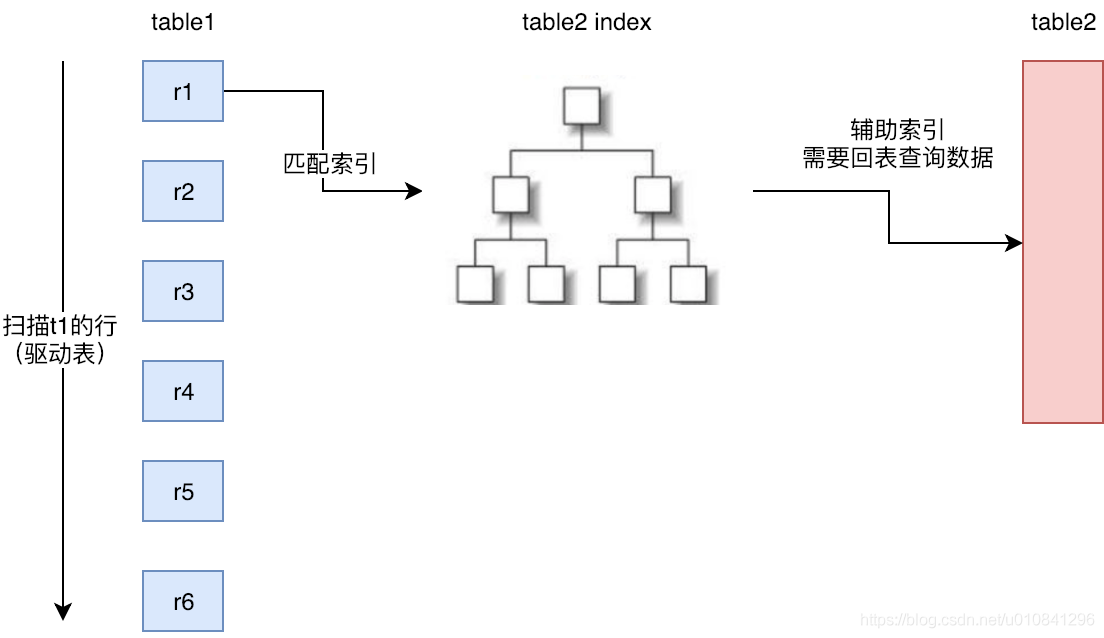
(3)Block Nested-Loop Join(BNLJ)
缓存块嵌套循环连接通过一次性缓存多条数据,把参与查询的列缓存到Join Buffer 里,然后拿join buffer里的数据批量与内层表的数据进行匹配,从而减少了内层循环的次数(遍历一次内层表就可以批量匹配一次Join Buffer里面的外层表数据)。
当不使用Index Nested-Loop Join的时候,默认使用Block Nested-Loop Join。
什么是Join Buffer?
Join Buffer会缓存所有参与查询的列而不是只有Join的列。- 可以通过调整
join_buffer_size缓存大小 join_buffer_size的默认值是256K,join_buffer_size的最大值在MySQL 5.1.22版本前是4G,而之后的版本才能在64位操作系统下申请大于4G的Join Buffer空间。- 使用
Block Nested-Loop Join算法需要开启优化器管理配置的optimizer_switch的设置block_nested_loop为on,默认为开启。
使用join buffer的条件
- 连接类型是ALL、index或range
- 第一个nonconst table不会分配join buffer ,即使类型是ALL或者index
- join buffer只会缓存需要的字段,而非整行数据
- 每个能被缓存的join都会分配一个join buffer , 一个查询可能拥有多个join buffer
- join buffer在执行联接之前会分配, 在查询完成后释放。
(4)Batched Key Access Join(BKA)
MySQL 5.6版本开始引入,BKA的基石: Multi Range Read (MRR)
MRR的作用就是把普通索引叶子节点找到的主键值的集合存储到read_rnd_buffer中,然后再该buffer中对主键值进行排序,最后利用已经排序好的主键值的集合,去访问表中的数据,这样就由原来的随机io变为了顺序io,降低了查询过程中的io开销。
BKA的原理很简单,对于多表的join语句,当mysql使用索引访问第二个join表时,使用一个join buffer 来收集第一个操作对象生成的相关列值,BKA构建好key后,批量传给引擎层做索引查找。
(5)Hash Join
- MySQL 8.0.18引入,用来替代BNLJ
- join buffer缓存外部循环的hash表,内层循环遍历时到hash表匹配
- MySQL 8.0.18才引入,且有很多限制,比如不能作用于外连接,比如left join/right join等等。从8.0.20开始限制少了很多,建议用8.0.20或更高版本
- 从MySQL 8.0.18开始, hash join的join buffer是递增分配的,这意味着,你可以为将join buffer_size设置得比较大。而在MySQL 8.0.18中,如果你使用了外连接,外连接没法用hash join ,此时join buffer size会按照你设置的值直接分配内存。因此join buffer. size还是得谨慎设置。
- 8.0.20开始, BNUJ已被删除了,用hash join替代了BNLJ
1.3、join优化
驱动表: 外层循环时驱动表
被驱动表:内存循环是被驱动表
JOIN调优原则
- 小表驱动大表
一般无需人工考虑,关联查询优化器会自动选择最优的执行顺序
例1:explain select * from employees LEFT JOIN salaries on employees.emp_no = salaries.emp_no where employees.emp_no = 278257
employees是驱动表 salaries是被驱动表
例2:explain select * from employees e LEFT JOIN dept_emp de on e.emp_no = de.emp_no LEFT JOIN departments d on de.dept_no = d.dept_no where e.emp_no = 278257
e 为 de的驱动表,de为d的驱动表
- 如果有where条件,应当要能够使用索引,并且尽可能减少外层循环的数据量
- join的字段尽可能创建索引
当join字段的类型不同时,索引无法使用
- 尽量减少扫描行数
- 参与join的表不要太多
阿里规约建议参与join的表不要超过三张
2、limit优化
explain select * from employees limit 300000,10
--方案1 覆盖索引 + join
explain select * from employees e INNER JOIN (select emp_no from employees limit 300000,10) t on e.emp_no = t.emp_no
--方案2 覆盖索引 + 子查询
explain select * from employees where emp_no >= (select emp_no from employees limit 300000,1) LIMIT 10
3、count语句优化
3.1、几种count的使用
(1)count (*)
explain select count(*) from employees
1、当没有非主键索引时,会使用主键索引
2、如果存在非主键索引,会使用非主键索引
3、如果存在多个非主键索引,会选择较小的非主键索引
原因:
innodb非主键索引: 叶子节点存储的是 索引 + 主键
主键索引叶子节点: 主键+ 表数据
在一个页中,非主键索引能存储更多的条目,所以使用最小的非主键索引性能更好
(2)count(字段)
count(字段)只会针对该字段进行统计,如果该字段存在索引则走索引否则全表扫描
count(字段)会排除该字段值为null的行 count(*)不会排除
(3)count(1)
innodb count(*) 和 count(1)相同
3.2、count优化
对于Mysql 8.0.13 以上Inno DB引擎,如果count(*)没有where条件,查询被优化,性能有所提升
方案1: 创建一个更小的非主键索引
4、order by优化
https://www.cnblogs.com/songwenjie/p/9418397.html
MySQL中的两种排序方式
1.通过有序索引顺序扫描直接返回有序数据
因为索引的结构是B+树,索引中的数据是按照一定顺序进行排列的,所以在排序查询中如果能利用索引,就能避免额外的排序操作。EXPLAIN分析查询时,Extra显示为Using index。
2.Filesort排序,对返回的数据进行排序
所有不是通过索引直接返回排序结果的操作都是Filesort排序,也就是说进行了额外的排序操作。EXPLAIN分析查询时,Extra显示为Using filesort。
在使用order by时,经常出现Using filesort,因此对于此类sql语句需尽力优化,使其尽量使用Using index。
核心原则:尽量减少额外的排序,通过索引直接返回有序数据。
order by 排序模式
- rowid排序(常规排序)
1、从表中获取满足WHERE条件的记录
2、 对于每条记录,将记录的主键及排序键(id,order column)取出放入sort buffer (由sort buffer size控制)
3、如果sort buffer能存放所有满足条件的(id,order column) ,则进行排序;否则sort buffer满后,排序并写到临时文件
排序算法:快速排序算法
4、若排序中产生了临时文件,需要利用归并排序算法,从而保证记录有序
5、循环执行上述过程,直到所有满足条件的记录全部参与排序
6、 扫描排好序的(id,order_ column)对 ,并利用id去取SELECT需要返回的其他字段
- 全字段排序(优化排序)
直接取出SQL中需要的所有字段,放到sort buffer
由于sort buffer已经包含了查询需要的所有字段,因此在sort buffer中排序完成后可直接返回
好处:性能的提升,无需两次IO
缺点:一行数据占用的空间一般比rowid排序多; 如果sort buffer比较小,容易导致临时文件
算法如何选择?
max length for sort data :当ORDER BY SQL中出现字段的总长度小于该值,使用全字段排序,否则使用rowid排序
- 打包字段排序
MySQL 5.7引入
全字段模式的优化,工作原理一样,但是将字段紧密地排列在一起而不是使用固定长度空间
例:VARCHAR(255) “yes” : 不打包: 255字节;打包: 2+3字节
order by 排序参数

示例
(1)mysql优化器发现用全表扫描的成本更低时,会直接使用全表扫描
索引条件
CREATE index name_idx on employees(first_name,last_name)
explain select * from employees ORDER BY first_name,last_name
explain select * from employees ORDER BY first_name,last_name LIMIT 10

结论:mysql优化器发现用全表扫描的成本更低时,会直接使用全表扫描
(2)排序字段在多个索引中,无法利用索引排序
索引条件
CREATE index name_idx on employees(first_name,last_name)
explain select * from employees ORDER BY first_name,emp_no

当排序字段不在同一个索引时,无法满足在一颗B+树中完成排序,必须再进行一次额外的排序
(3)排序字段顺序与索引列顺序不一致,无法利用索引排序
这条是针对组合索引而言的,我们都知道使用组合索引必要要遵循最左原则,WHERE子句必须有索引中第一列,虽然ORDER BY子句没有这个要求,但是也要求排序字段顺序和组合索引列顺序匹配。我们平常在使用组合索引的时候,一定要养成按照组合索引列顺序书写的好习惯。
可以利用索引排序
explain select * from employees where first_name = 'Georgi' ORDER BY first_name,last_name
explain select * from employees where first_name = 'Georgi' ORDER BY last_name
无法利用索引排序
explain select * from employees where last_name = 'Georgi' ORDER BY first_name
(4)升降序不一致,无法利用索引排序
explain select * from employees ORDER BY first_name DESC,last_name ASC

(5)key_part1范围查询,key_part2排序,无法使用索引排序
explain select * from employees where first_name > 'Georgi' ORDER BY last_name
5、Group By 优化
mysql处理group by方法,共有三种,性能一次递减
- 松散索引扫描( Loose Index Scan )
- 紧凑索引扫描( Tight Index Scan )
- 临时表( Temporary table )
5.1、松散索引扫描
(1)松散索引扫描分析
举例: 查询每个员工拿到过的最少的工资是多少
select emp_no,min(salary) from salaries GROUP BY emp_no``select emp_no,min(salary) from salaries GROUP BY emp_noselect emp_no,min(salary) from salaries GROUP BY emp_noselect emp_no,min(salary) from salaries GROUP BY emp_noselect emp_no,min(salary) from salaries GROUP BY emp_no
创建[emp_no,salary]的索引 CREATE index emp_no_salary_idex on salaries(emp_no,salary) 分析sql的执行过程: [emp_no,salary] ,按照索引顺序,数据如下 [10001,50000] [10001,52000] [10001,60000] [10002,48000] [10002,51000] ….. 推断执行过程 1、先扫描emp_no=10001的数据,并查出最小的salary是多少 2、扫描emp_no=10002的数据,并查出最小的salary是多少 … 依次类推,遍历出每个员工的薪资,最后返回结果 实际执行过程 (因为索引是有顺序的) 1、扫描emp_no=10001的数据,取出第一条数据 => 该员工最小salary 2、跳过所有emp_no=10001的数据,扫描emp_no=10002的数据,取出第一条数据 … 依次类推 这个改进就是松散索引扫描 Using index for group-by
explain select emp_no,min(salary) from salaries GROUP BY emp_no

(2)使用松散索引扫描 条件
- 查询作用在单张表上
- GROUP指定的所有字段要符合最左前缀原则,且没有其他字段
- 比如有索引index(c1, c2, c3) ,如果GROUP BY c1,c2则可以使用松散索引扫描;
但GROUP BY c2, c3、GROUP BY c1, c2, c4则不能使用
- 如果存在聚合函数,只支持MIN()/MAX() , 并且如果同时使用了MIN)和MAX() ,则必须作用在同一个字段。聚合函数作用的字段必须在索引中,并且要紧跟GROUP BY所指定的字段
- 比如有索引index(c1, c2, c3) ,SELECT c1,c2, MIN(c3), MAX(c3)FROM t1 GROUP BY c1,c2可使用松散索引扫描
- 如果查询中存在除GROUP BY指定的列以外的其他部分,则必须以常量的形式出现
- SELECT c1,c3 FROM t1 GROUP BY c1,c2 :不能使用
- SELECT c1,c3 FROM t1 WHERE c3 = 3 GROUP BY c1,c2 :可以
- 索引必须索引整个字段的值,不能是前缀索引
比如有字段c1 VARCHAR(20) ,但如果该字段使用的是前缀索引index(c1(10))而不是index(c1) ,无法使用松散索引扫描



5.2、紧凑索引扫描
需要扫描满足条件的所有索引键才能返回结果
性能-般比松散索引扫描差,但一般都可接受
explain select emp_no,sum(salary) from salaries GROUP BY emp_no

5.3、临时表
explain select max(birth_date) from employees GROUP BY hire_date

6、DISTINCT优化
DISTINCT是在GROUP BY操作之后,每组只取1条
和GROUP BY优化思路-样,避免临时表,使用松散索引扫描或紧凑索引扫描

若有收获,就点个赞吧
0 人点赞
