1、长字段的索引调优
InnoDB单列索引长度不能超过767bytes,联合索引还有一个限制是长度不能超过3072。
(1)构造Hash索引
新建一列用于存储该字符列的hash值(哈希函数不要使用SHA1(),MD5(),因为会产生很长的字符串,浪费空间,比较也慢,最好是返回整数的hash函数),在该列建立索引。
例
CREATE TABLE `long_index_hash` (
`id` int NOT NULL AUTO_INCREMENT,
`str` varchar(2048) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`str_hash` int NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `hash_idx`(`str_hash`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
INSERT into long_index_hash(str,str_hash) VALUES ('x9a0oau9fjcdosdiufy0-qfw098-fqijw09p8uf9wjxklsaocqc8q=-w9fieujq-980ufvq',CRC32('x9a0oau9fjcdosdiufy0-qfw098-fqijw09p8uf9wjxklsaocqc8q=-w9fieujq-980ufvq'))
EXPLAIN select * from long_index_hash where str_hash = CRC32('x9a0oau9fjcdosdiufy0-qfw098-fqijw09p8uf9wjxklsaocqc8q=-w9fieujq-980ufvq') and str = 'x9a0oau9fjcdosdiufy0-qfw098-fqijw09p8uf9wjxklsaocqc8q=-w9fieujq-980ufvq'
(2)前缀索引
查看索引选择性,选择合适的前缀长度
SELECT count(DISTINCT str) /count(*) from long_index_hash #该字段的最大索引选择性
SELECT count(DISTINCT left(str,5)) /count(*) from long_index_hash
创建前缀索引sql ALTER table 表名 add index index_name(列名(100))
局限性**:
无法做order by,group by,无法使用覆盖索引
——后缀索引,额外创建一个字段,str_reverse,在存储时将str翻转过来存储
2、单列索引和组合索引
为salaries的from_date和to_date 分别创建单列索引
create index from_date_idx on salaries(from_date);
create index to_date_idx on salaries(to_date);
explain select * from salaries where from_date ='1986-06-23' and to_date = '1987-06-23'
 Using
Using
type为index_merge
为salaries的from_date和to_date 创建组合索引
drop index from_date_idx on salaries;
drop index to_date_idx on salaries;
create index date_idx on salaries(from_date,to_date);
explain select * from salaries where from_date ='1986-06-23' and to_date = '1987-06-23'
type为ref
结论:组合索引的性能优于单例索引做索引合并
- SQL存在多个条件,多个单列索引,会使用索引合并
- 如果出现索引合并,往往说明索引不够合理
- 如果SQL暂时没有性能问题,暂时可以不管
3、覆盖索引
查询的字段即索引数据,无需通过索引查询主键,再查询数据
索引无法覆盖查询字段时explain select * from salaries where from_date ='1986-06-23' and to_date = '1987-06-23'
type: ref Extra : null
索引覆盖查询字段时explain select from_date,to_date from salaries where from_date ='1986-06-23' and to_date = '1987-06-23'

type: ref Extra : Using index
4、重复索引,冗余索引
- 重复索引: 尽量避免重复索引,如果发现重复索引应该删除
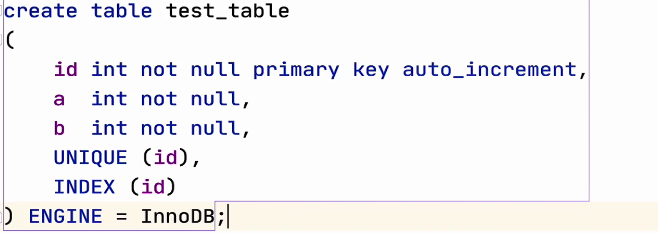
- 如果已经存在索引lindex(A, B) , 又创建了index(A) ,那么index(A)就是index(A, B)的冗余索引
特殊情况:
删除salaries的所有索引,为from_date创建索引
create index from_date_idx on salaries(from_date);
explain select * from salaries where from_date ='1986-06-23' ORDER BY emp_no;

删除from_date索引,为from_date,to_date创建联合索引
drop index from_date_idx on salaries;
create index date_idx on salaries(from_date,to_date);
explain select * from salaries where from_date ='1986-06-23' ORDER BY emp_no;
此时,无法使用索引排序,只能使用文件序排序了
**
—index(from_date) : type=ref extra =null 使用了索引
—index(from_date,to_date) : type=ref extra =Using filesort ,order by无法使用索引
index(from_date)为非主键索引,非主键索引会在B+Tree的叶子节点存储主键值,非主键索引会先去查询主键是什么,
index(from_date) 某种意义上来说相当于index(from_date,emp_no),所以排序可以使用索引
index(from_date,to_dtae) 某种意义上来说相当于index(from_date,to_dtae,emp_no),不符合最左前缀原则,所以无法使用索引

若有收获,就点个赞吧
0 人点赞
