概述

上图是一个计算机视觉发展的一个失败错误率的图,我们可以看到在2015年之后计算机视觉识别图像数据的错误率已经超过了人类,这使得有很多应用了人工智能的场景进入人们的生活,被人们熟知,并成为生活的一部分,如手机人脸识别解锁,车辆自动驾驶辅助驾驶等。
目前的人工智能主要分为机器学习和深度学习,深度学习的概念源于人工神经网络的研究。深度学习与传统的机器学习最主要的区别在于随着数据规模的增加其性能也不断增长。 当数据很少时,深度学习算法的性能并不好。 这是因为深度学习算法需要大量的数据来完美地理解它。 另一方面,在这种情况下,传统的机器学习算法使用制定的规则,性能会比较好,但是对开发人员的素质要求非常高。
绝大多数的人工智能的开发都是在python中进行的,因为它相对更语义话对于科研人员来说更容易理解。
机器学习主要使用scikit-learn实现
深度学习的框架有很多,主要的有:谷歌的TensorFlow框架,Meta(facebook)的pytorch看框架,百度的飞桨(paddlePaddle)框架,阿里的MNN框架,腾讯的TNN
目前可以用于web端的有由tensorFlowjs、onnxjs、MNNjs
深度学习可以做什么?
检测任务:深度学习可以检测图像中的物体,并识别出他们是什么,在自动驾驶领域中,特斯拉就是通过摄像头拍摄到的图片数据,传入模型进行检测后,告诉车辆是否进行规避,转向等操作。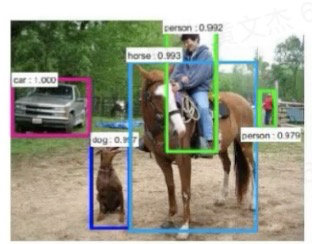
内容检索:深度学习可以通过传入图像的一些特征,寻找出相似的图片,在淘宝的图片拍照功能中就是使用了该技术,给用户推送类似的商品从而引导进行购买。
超分辨率重构:通过大量模糊图片数据和高清图片数据的训练,可以得出通过低分辨率图片生产高分辨率图片的模型,抖音的某些照片修复特效就是使用了类似的技术
语言语义识别:通过输入大量的语音的数据,训练出可以模拟人声的程序,如抖音中发视频的时候输入文字的自动阅读功能。
DeepFake:造假(手动狗头🐶),抖音的特效一部分是识别人脸特征点往上盖图片,另一部分是使用对抗神经网络(GAN)的方式去生成造假的图片。
常见的神经网络架构:
卷积神经网络CNN,递归神经网络RNN,对抗神经网络GAN,残差神经网络resNet,YOLOV5等
本次我们使用pytorch用CNN的神经网络架构训练模型再转到onnxjs的方式实现web端的手写数字识别功能。
在此之前我们需要理解一些基础概念:
向量,矩阵,前向传播,反向传播,卷积层,卷积步长,卷积核,边缘填充(padding),激活函数,池化层,全链接层,oneHot,损失函数,梯度下降,训练数据集,测试数据集,Dropout等
什么是前向传播?
所谓的前向传播算法就是:将上一层的输出作为下一层的输入,并计算下一层的输出,一直到运算到输出层为止。
什么是反向传播?
所谓的反向传播就是:计算神经网络参数梯度的方法。简单来说,反向传播就是经过前向传播后,按相反的顺序从输出层到输入层遍历网络,求得每个位置的权重参数。pytorch中设置参数会自动计算。
什么是卷积神经网络?
如图所示,前半部分是NN,就是神经网络的缩写,由输入层,隐层,输出层构成。后半部分是CNN,传入的矩阵大小为32x32x1,经过多次卷积变换以后,得到一条1xn的向量的网络,就是最后的分类结果。

以下图为例:输入图片大小为32x32x3(weight,height,depth)其中depth也就是channel就是颜色通道,经过卷积核一开始的卷积核的值是随机初始化的)为5x5x3采样((就是矩阵相乘x1*w1,对应位置相乘再相加,得到的是一个值)取值为最高的点,得到特征图,使用多个卷积核进行计算并堆叠在一起就可以得到下一层的数据的输入

经过不同大小的卷积核进行特征提取,在进行分类可以得到更好的结果。
什么是边缘填充(Padding)?
因为越居中的图像数据被计算的次数越多,而边缘的数据相对来说容易被忽视,所以我们给边缘拓展一圈为0的数据,使得本来图像边缘的数据可以更多的被计算。

什么是激活函数?
如下图所示,在没有激活函数的情况下,神经网络的权重、偏置全是线性的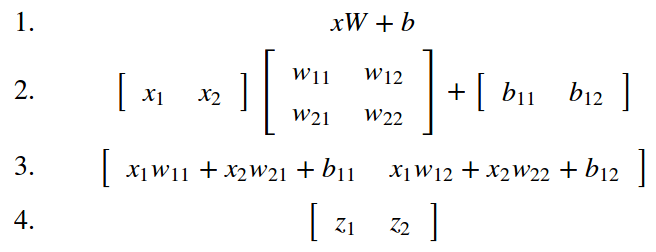
这样的神经网络,甚至连下面这样的简单分类问题都解决不了:
在这个二维特征空间上,蓝线表示负面情形(y=0),绿线表示正面情形(y=1)
没有激励函数的加持,神经网络最多能做到这个程度:
线性边界——看起来不怎么好,是吧?
这时候,激活函数出手了,扭曲翻转一下空间:
线性边界出现了!再还原回去,不就得到了原特征空间中的边界?
常见的激活函数有:sigmoid,tanh,relu
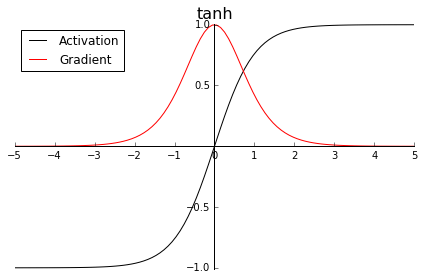
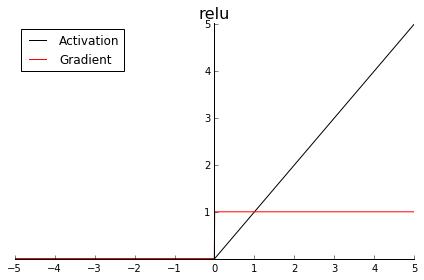
对比三个激活函数,sigmoid将输入挤压进0到1区间(这和概率的取值范围一致)
tanh的形状和sigmoid类似,只不过tanh将“挤压”输入至区间(-1, 1)。因此,中心为零,(某种程度上)激活值已经是下一层的正态分布输入了。
至于梯度,它有一个大得多的峰值1.0(同样位于z = 0处),但它下降得更快,当|z|的值到达3时就已经接近零了。这是所谓梯度消失(vanishing gradients)问题背后的原因,会导致网络的训练进展变慢。
ReLU处理了它的sigmoid、tanh中常见的梯度消失问题,同时也是计算梯度最快的激励函数。
什么是池化层?
在经过多次卷积计算后,数据里的depth的数量会越来越多,数据量会越来越大,这样就会使得电脑的计算速度随着计算次数的增多变得更慢,所以我们需要去有意识地降低数据量,池化层就是这样的作用,如下图所示,他可以通过选择各种算法(取最大值等方式)使得尺寸大幅减小。例如一开始是32x32x3经过多次卷积变成了16x16x12,那么经过池化就可以让其变成4x4x12,然后经
什么是全链接层?
是每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来。 由于其全相连的特性,一般全连接层的参数也是最多的。
整体的卷积神经网络流程:


什么是损失函数?
损失函数(loss function)是用来估量模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。
什么是梯度下降?
我们要怎么才能降低损失函数的值呢?这里就要用到梯度下降算法。
我们看下图,简易的理解一下什么是梯度下降。
https://p1-jj.byteimg.com/tos-cn-i-t2oaga2asx/gold-user-assets/2020/4/3/1713d58bb10f8bf5~tplv-t2oaga2asx-zoom-in-crop-mark:1304:0:0:0.awebp
拓展到多维度就是这样
https://www.google.com.hk/url?sa=i&url=https%3A%2F%2Fharmonyhu.com%2F2019%2F01%2F05%2Fgradient-descent%2F&psig=AOvVaw2XyxMSZirlA3b9hj6CAU1J&ust=1648259767726000&source=images&cd=vfe&ved=0CAgQjRxqFwoTCMCR26SU4PYCFQAAAAAdAAAAABAO
简而言之,我们每次迭代时通过减少一个很小的步长,向下去取比目前更优的值,在当前的梯度无线趋近0的时候,我们可以认为我们已经拿到了比较好的结果。
什么是Dropout?
在数据量过小的情况下,很容易出现过拟合(训练的损失值很小但是时间表现不好,因为过度地提取了图片的特征,相当于训练时只用苹果手机去做训练,在做手机分类任务的时智能识别出苹果手机而识别不出安卓手机)。我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。
实现流程:
1、安装 anaconda、pytorch
https://blog.csdn.net/wuwei1005_/article/details/109022776
2、下载minist模型
3、区分训练数据集和测试数据集
4、编写神经网络
5、训练模型
6、测试模型
7、打包模型
8、web端加载模型
9、进行web端测试

若有收获,就点个赞吧
0 人点赞
