分布式锁一. 基于Zookeeper实现分布锁
1.1 zk有哪些使用场景?
2.2 Zookeeper分布式锁的基本原理
2.3 Zookeeper分布式锁的实现代码
2.3.1 基于临时节点实现Zookeeper分布式锁
2.3.2 基于临时顺序节点实现Zookeeper分布式锁
二. 基于Redis实现分布式锁
2.1 在Redis内创建一个key来充当锁
2.2 基于RedLock实现分布式锁
2.3 基于Redisson实现分布式锁
三. 各项分布锁的比较
一. 基于Zookeeper实现分布锁
1.1 zk有哪些使用场景?
分布式系统,对多个服务进行分布式协调工作
分布式协调工作可以理解成在分布式系统下,多个服务共同完成一项业务功能时,某个服务希望感知到另一个服务的处理情况。如下图所示,系统A没有直接调用系统B,而是将待处理的消息推送到MQ中,由系统B从MQ中获取并处理消息,那么问题来了,系统A如何感知到系统B是否执行成功呢?此时zookeeper就派上用场了。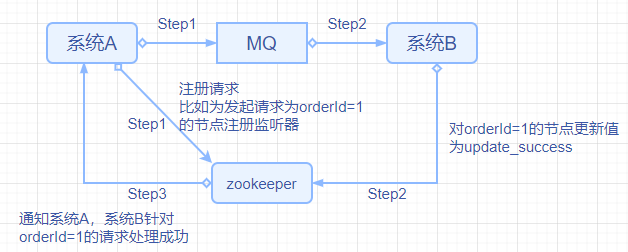
分布式锁
分布式系统下,同一时刻只能有一个服务执行某项服务时,需要使用分布式锁。使用过程大致如下: 系统A向zookeeper申请并得到锁,执行业务逻辑,与此同时,系统B也向zookeeper申请锁,但由于锁在系统A手上,因此请求被拒绝,接着,系统B会在zookeeper上注册一个监听器,当系统A释放锁后,系统B的监听器将立刻监听到该事件并通知系统B,此时系统B再次发起获取锁的请求,才能成功获得锁,最终执行自己的业务逻辑并释放锁。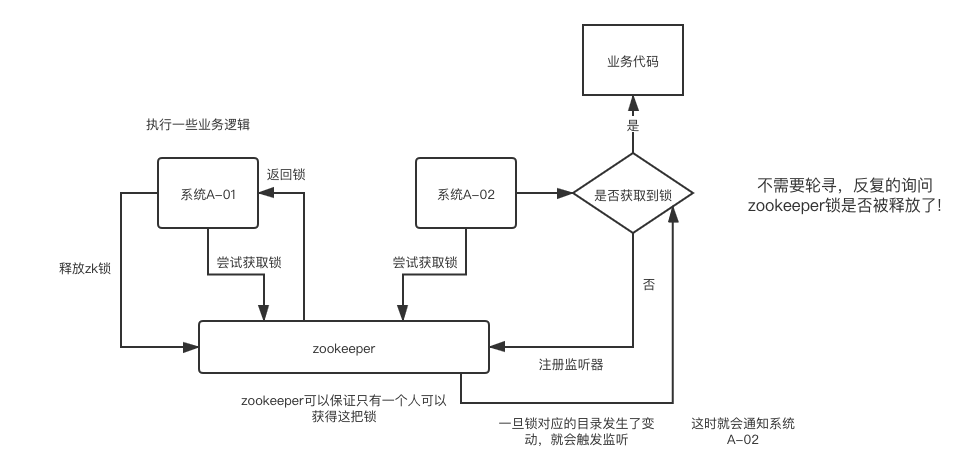
存储和配置元数据信息
zookeeper可以管理整套分布式系统配置信息,比如kafka、storm、dubbo等都使用了zk来管理元数据和配置信息。如下图所示,消费者在调用服务A之前,需要请求dubbo注册中心,以获取服务A所在的IP,此时有可能服务A尚未注册成功,那么dubbo注册中心可以专门做一个服务A的监听器,当服务A完成注册功能并向zookeeper中存储元数据后,监听器监听到事件并立刻返回结果给消费者。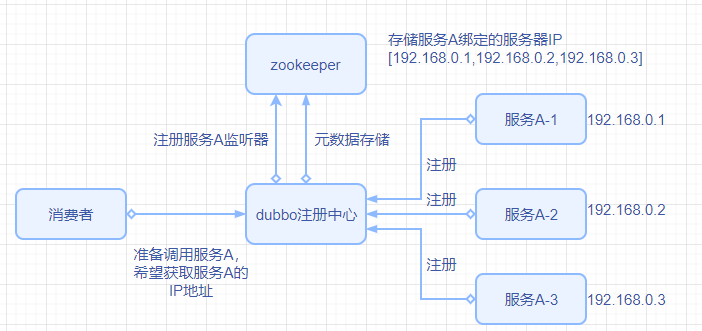
HA高可用性
有许多分布式系统都是使用zookeeper来实现HA高可用性,比如hdfs、yarn,它的原理是为一个重要的进程或者服务实现主备模式,出现故障时,zookeeper能立刻感知到主进程故障并将从进程切换成新的主进程对外提供服务。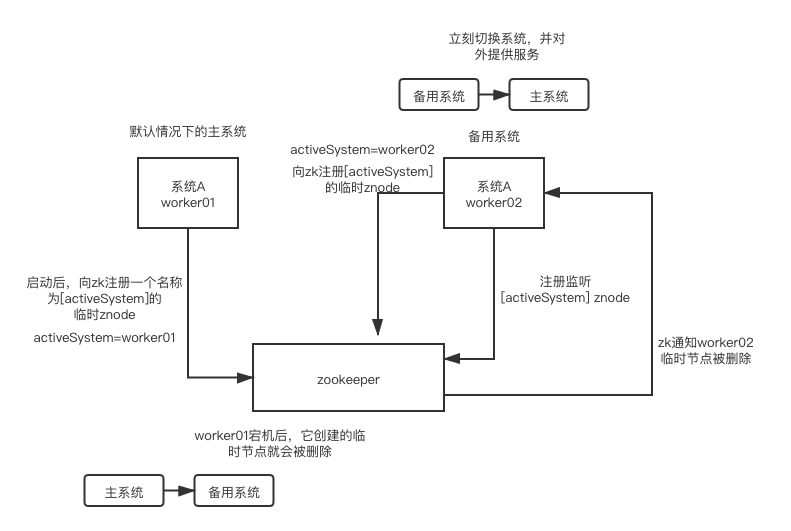
2.2 Zookeeper分布式锁的基本原理
假设有两个服务A、B希望获得同一把锁,执行过程大致如下:
Step1: 服务A向zookeeper申请获得锁,该请求将尝试在zookeeper内创建一个临时节点(ephemeral znode),如果没有同名的临时节点存在,则znode创建成功,标志着服务A成功的获得了锁。
Step2: 服务B向zookeeper申请获得锁,同样尝试在zookeeper内创建一个临时节点(名称必须与服务A的相同),由于同名znode已经存在,因此请求被拒绝。接着,服务B会在zk中注册一个监听器,用于监听临时节点被删除的事件。
Step3: 若服务A主动向zk发起请求释放锁,或者服务A宕机、断开与zk的会话,zk会将服务A(创建者)创建的临时节点删除。而删除事件也将立刻被监听器捕获到,并反馈给服务B。最后,服务B再次向zookeeper申请获得锁。
2.3 Zookeeper分布式锁的实现代码
2.3.1 基于临时节点实现Zookeeper分布式锁
思路非常简单,多个服务如果想竞争同一把锁,那就向Zookeeper发起创建临时节点的请求,若能成功创建则获得锁,否则借助监听器,当监听到锁被其它服务释放(临时节点被删除),则自己再尝试创建临时节点,反复这几个步骤直到成功创建临时节点或者与zookeeper建立的会话超时。
定义变量
/*
与Zookeeper成功建立连接的信号标志
*/
private CountDownLatch connectedSemaphore = new CountDownLatch(1);
/**<br /> * 创建分布式锁的过程中,开始和等待请求创建分布式锁的信号标志<br /> */<br /> private CountDownLatch creatingSemaphore;/**<br /> * Zookeeper客户端<br /> */<br /> private ZooKeeper zookeeper;/**<br /> * 分布式锁的过期时间 单位:毫秒<br /> */<br /> private static final Long DISTRIBUTED_KEY_OVERDUE_TIME = 30000L;<br />构造函数<br />public ZookeeperLock() {<br /> try {<br /> this.zookeeper = new ZooKeeper("192.168.0.93:2181", 5000, new ZookeeperWatcher());<br /> try {<br /> connectedSemaphore.await();<br /> } catch (InterruptedException ite) {<br /> log.error("等待Zookeeper成功建立连接的过程中,线程抛出异常", ite);<br /> }<br /> log.info("与Zookeeper成功建立连接");<br /> } catch (Exception e) {<br /> log.error("与Zookeeper建立连接时出现异常", e);<br /> }<br />}
获取分布式锁
实际上就是在尝试创建临时节点znode
create(final String path, byte data[], List acl,CreateMode createMod)
path: 从根节点”/“到当前节点的全路径
data: 当前节点存储的数据 (由于这里只是借助临时节点的创建来实现分布式锁,因此无需存储数据)
acl: Access Control list 访问控制列表 主要涵盖权限模式(Scheme)、授权对象(ID)、授予的权限(Permission)这三个方面 OPEN_ACL_UNSAFE 完全开放的访问控制 对当前节点进行操作时,无需考虑ACL权限控制
createMode: 节点创建的模式
EPHEMERAL(临时节点) 当创建节点的客户端与zk断开连接后,临时节点将被删除
EPHEMERAL_SEQUENTIAL(临时顺序节点)
PERSISTENT(持久节点)
PERSISTENT_SEQUENTIAL(持久顺序节点)
public boolean acquireDistributeLock(Long lockId) {
String path = “/product-lock-“ + lockId;
try {<br /> zookeeper.create(path, "".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);<br /> log.info("ThreadId=" + Thread.currentThread().getId() + "创建临时节点成功");<br /> return true;<br /> } catch (Exception e) {<br /> // 若临时节点已存在,则会抛出异常: NodeExistsException<br /> while (true) {<br /> // 相当于给znode注册了一个监听器,查看监听器是否存在<br /> try {<br /> Stat stat = zookeeper.exists(path, true);<br /> if (stat != null) {<br /> this.creatingSemaphore = new CountDownLatch(1);<br /> this.creatingSemaphore.await(DISTRIBUTED_KEY_OVERDUE_TIME, TimeUnit.MILLISECONDS);<br /> this.creatingSemaphore = null;<br /> }<br /> zookeeper.create(path, "".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);<br /> return true;<br /> } catch (Exception ex) {<br /> log.error("ThreadId=" + Thread.currentThread().getId() + ",查看临时节点时出现异常", ex);<br /> }<br /> }<br /> }<br />}
释放分布式锁
public void releaseDistributedLock(Long lockId) {
String path = “/product-lock-“ + lockId;
try {
// 第二个参数version是数据版本 每次znode内数据发生变化,都会使version自增,但由于分布式锁创建的临时znode没有存数据,因此version=-1
zookeeper.delete(path, -1);
log.info(“成功释放分布式锁, lockId=” + lockId + “, ThreadId=” + Thread.currentThread().getId());
} catch (Exception e) {
log.error(“释放分布式锁失败,lockId=” + lockId, e);
}
}
建立Zookeeper的监听器
ps: 不论是zk客户端与服务器连接成功,还是删除节点,watcher监听到的事件都是SyncConnected,很奇怪zookeeper为什么不加以区别。
private class ZookeeperWatcher implements Watcher {
@Override
public void process(WatchedEvent event) {
log.info(“接收到事件: “ + event.getState() + “, ThreadId=” + Thread.currentThread().getId());
if (Event.KeeperState.SyncConnected == event.getState()) {<br /> connectedSemaphore.countDown();<br /> }if (creatingSemaphore != null) {<br /> creatingSemaphore.countDown();<br /> }<br /> }<br />}
main方法
我创建了两个线程,其中第一个线程先执行,且持有锁5秒钟才释放锁,第二个线程后执行,当且仅当第一个线程释放锁(删除临时节点)后,第二个线程才能成功获取锁。
public static void main(String[] args) throws InterruptedException{
long lockId = 20200730;
new Thread(() ->{<br /> ZookeeperLock zookeeperLock = new ZookeeperLock();<br /> System.out.println("ThreadId1=" + Thread.currentThread().getId());<br /> System.out.println("ThreadId=" + Thread.currentThread().getId() + "获取到分布式锁: " + zookeeperLock.acquireDistributeLock(lockId));<br /> try {<br /> TimeUnit.SECONDS.sleep(5);<br /> } catch (InterruptedException e) {<br /> log.error("ThreadId=" + Thread.currentThread().getId() + "暂停时出现异常", e);<br /> }<br /> zookeeperLock.releaseDistributedLock(lockId);<br /> }).start();TimeUnit.SECONDS.sleep(1);<br /> new Thread(() -> {<br /> ZookeeperLock zookeeperLock = new ZookeeperLock();<br /> System.out.println("ThreadId2=" + Thread.currentThread().getId());<br /> System.out.println("ThreadId=" + Thread.currentThread().getId() + "获取到分布式锁: " + zookeeperLock.acquireDistributeLock(lockId));<br /> }).start();<br />}
2.3.2 基于临时顺序节点实现Zookeeper分布式锁
仍然是通过创建znode来实现分布式锁,只不过当前方法中使用临时顺序节点。
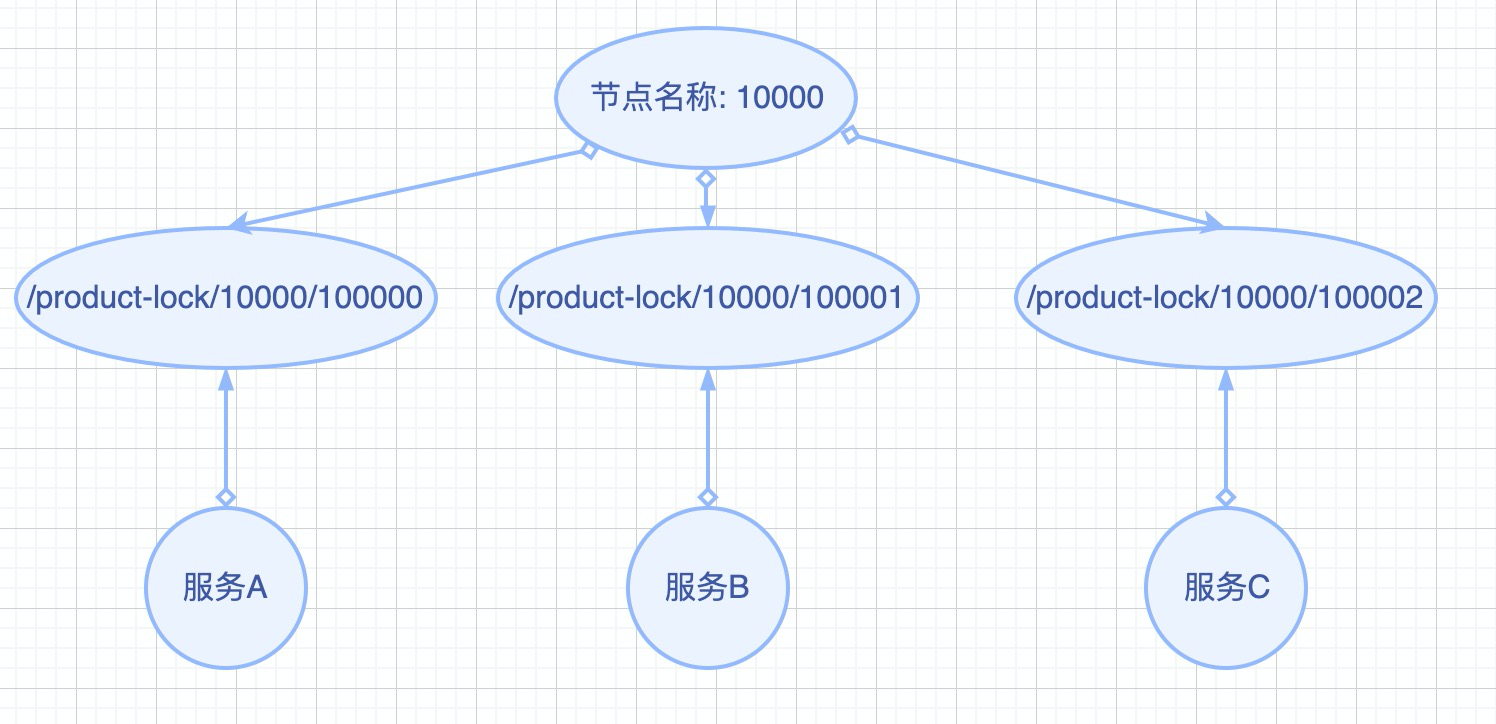
如图所示,使用临时顺序节点后,Zookeeper会针对同一个名称创建多个临时节点,在创建出的临时节点的名称后面加上一串数字,用以区分创建节点的顺序。服务B如果想获得锁,必须检查它所创建节点的前一个紧挨着的节点是否存在,当且仅当/product-lock/10000/100000这个临时顺序节点被释放后,服务B才能获得锁。同理,服务C需要依次等待服务B和服务A所创建的临时节点被释放,才能获得锁。
创建一个名为ZookeeperTempOrderLock的类,实现org.apache.zookeeper.Watcher接口
定义变量
/*
Zookeeper客户端
*/
private ZooKeeper zookeeper;
/*
锁的唯一标识
*/
private String lockId;
/*
与Zookeeper建立会话的信号量
*/
private CountDownLatch connectedLatch;
/*
创建分布式锁的过程中,开始和等待请求创建分布式锁的信号标志
*/
private CountDownLatch creatingLatch;
/*
分布式锁路径前缀
*/
private String locksRootPath = “/locks”;
/*
排在当前节点前面一位的节点的路径
*/
private String waitNodeLockPath;
/*
为了获得锁,本次创建的节点的路径
*/
private String currentNodeLockPath;
构造函数
public ZookeeperTempOrderLock(String lockId) {
this.lockId = lockId;
try {
// 会话超时时间
int sessionTimeout = 30000;
//
zookeeper = new ZooKeeper(“192.168.0.93:2181”, sessionTimeout, this);
connectedLatch.await();
} catch (IOException ioe) {
log.error(“与Zookeeper建立连接时出现异常”, ioe);
} catch (InterruptedException ite) {
log.error(“等待与Zookeeper会话建立完成时出现异常”, ite);
}
}
实现Zookeeper的watcher
@Override
public void process(WatchedEvent event) {
if (Event.KeeperState.SyncConnected == event.getState()) {
connectedLatch.countDown();
}
if (creatingLatch != null) {<br /> creatingLatch.countDown();<br /> }<br />}
获取分布式锁
/*
获取锁
*/
public void acquireDistributedLock() {
try {
while(!tryLock()) {
// 等待前一项服务释放锁的等待时间 不能超过一次Zookeeper会话的时间
long waitForPreviousLockRelease = 30000;
waitForLock(waitNodeLockPath, waitForPreviousLockRelease);
}
} catch (InterruptedException | KeeperException e) {
log.error(“等待上锁的过程中出现异常”, e);
}
}
public boolean tryLock() {
try {
// 创建顺序临时节点
currentNodeLockPath = zookeeper.create(locksRootPath + “/“ + lockId,
“”.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
// 查看刚刚创建的节点是不是最小节点
// 比如针对于这个同名节点,之前有其它服务曾申请创建过,因此Zookeeper中临时顺序节点形如:
// /locks/10000000000, /locks/10000000001, /locks/10000000002
List
Collections.sort(nodePaths);
if(currentNodeLockPath.equals(locksRootPath + “/“ + nodePaths.get(0))) {
// 如果是最小节点,则代表获取到锁
return true;
}
// 如果不是最小节点,则找到比自己小1的节点 (紧挨着自己)
int previousLockNodeIndex = -1;
for (int i = 0; i < nodePaths.size(); i++) {
if(currentNodeLockPath.equals(locksRootPath + “/“ + nodePaths.get(i))) {
previousLockNodeIndex = i-1;
break;
}
}
this.waitNodeLockPath = nodePaths.get(previousLockNodeIndex);
} catch (KeeperException | InterruptedException e) {<br /> log.error("创建临时顺序节点失败", e);<br /> }<br /> return false;<br />}
等待其他服务释放锁
/*
等待其他服务释放锁
实际上就是在等待前一个临时节点被删除
@param nodePath 希望被删除的节点的相对路径
@param waitTime 等待时长 单位:毫秒
*/
private boolean waitForLock(String nodePath, long waitTime) throws KeeperException, InterruptedException {
Stat stat = zookeeper.exists(locksRootPath + “/“ + nodePath, true);
if (stat != null) {
this.creatingLatch = new CountDownLatch(1);
this.creatingLatch.await(waitTime, TimeUnit.MILLISECONDS);
this.creatingLatch = null;
}
return true;
}
释放分布式锁
/*
释放锁
实际上就是删除当前创建的临时节点
/
public void releaseLock() {
log.info(“准备删除的节点路径: “ + currentNodeLockPath);
try {
zookeeper.delete(currentNodeLockPath, -1);
currentNodeLockPath = null;
zookeeper.close();
} catch (Exception e) {
log.error(“删除节点失败”, e);
}
}
二. 基于Redis实现分布式锁
2.1 在Redis内创建一个key来充当锁
假设有两个服务A、B都希望获得锁,执行过程大致如下:
Step1: 服务A为了获得锁,向Redis发起如下命令: SET productId:lock 0xx9p03001 NX PX 30000 其中,”productId”由自己定义,可以是与本次业务有关的id,”0xx9p03001”是一串随机值,必须保证全局唯一(原因在后文中会提到),“NX”指的是当且仅当key(也就是案例中的”productId:lock”)在Redis中不存在时,返回执行成功,否则执行失败。”PX 30000”指的是在30秒后,key将被自动删除。执行命令后返回成功,表明服务成功的获得了锁。
并发拿锁的原理就在这里,只能有一个服务把KEY SET到Redis中,如果KEY已存在,则会抛出nil异常。
Step2: 服务B为了获得锁,向Redis发起同样的命令: SET productId:lock 0000111 NX PX 30000
由于Redis内已经存在同名key,且并未过期,因此命令执行失败,服务B未能获得锁。服务B进入循环请求状态,比如每隔1秒钟(自行设置)向Redis发送请求,直到执行成功并获得锁。
Step3: 服务A的业务代码执行时长超过了30秒,导致key超时,因此Redis自动删除了key。此时服务B再次发送命令执行成功,假设本次请求中设置的value值为0000222。
Step4: 服务A执行完毕,为了释放锁,服务A会主动向Redis发起删除key的请求。注意: 在删除key之前,一定要判断服务A持有的value与Redis内存储的value是否一致。比如当前场景下,Redis中的锁早就不是服务A持有的那一把了,而是由服务2创建,如果贸然使用服务A持有的key来删除锁,则会误将服务2的锁释放掉。此外,由于删除锁时涉及到一系列判断逻辑,因此一般使用lua脚本,具体如下:
if redis.call(“get”, KEYS[1])==ARGV[1] then
return redis.call(“del”, KEYS[1])
else
return 0
end
缺点: 如果Redis是单节点部署的,当Redis节点宕机后,锁就会失效。如果Redis是主从部署且在Redis master宕机时,没有来得及把锁信息同步至Redis slave,那么当从节点被切换成主节点时,别的服务实例就会错误的拿到锁。
2.2 基于RedLock实现分布式锁
假设有两个服务A、B都希望获得锁,有一个包含了5个redis master的Redis Cluster,执行过程大致如下:
Step1: 客户端获取当前时间戳,单位: 毫秒
Step2: 服务A轮寻每个master节点,尝试创建锁。(这里锁的过期时间比较短,一般就几十毫秒) RedLock算法会尝试在大多数节点上分别创建锁,假如节点总数为n,那么大多数节点指的是n/2+1。
Step3: 客户端计算成功建立完锁的时间,如果建锁时间小于超时时间,就可以判定锁创建成功。如果锁创建失败,则依次(遍历master节点)删除锁。
Step4: 只要有其它服务创建过分布式锁,那么当前服务就必须轮寻尝试获取锁。
缺点: RedLock算法无非就是在最原始的上锁方式上增加了集群的概念,防止某个Redis节点宕机,导致分布式锁不可用。但是这个算法不够严谨,并且向大多数节点上上锁的超时时间需要设置成多少,这个也比较麻烦。
2.3 基于Redisson实现分布式锁
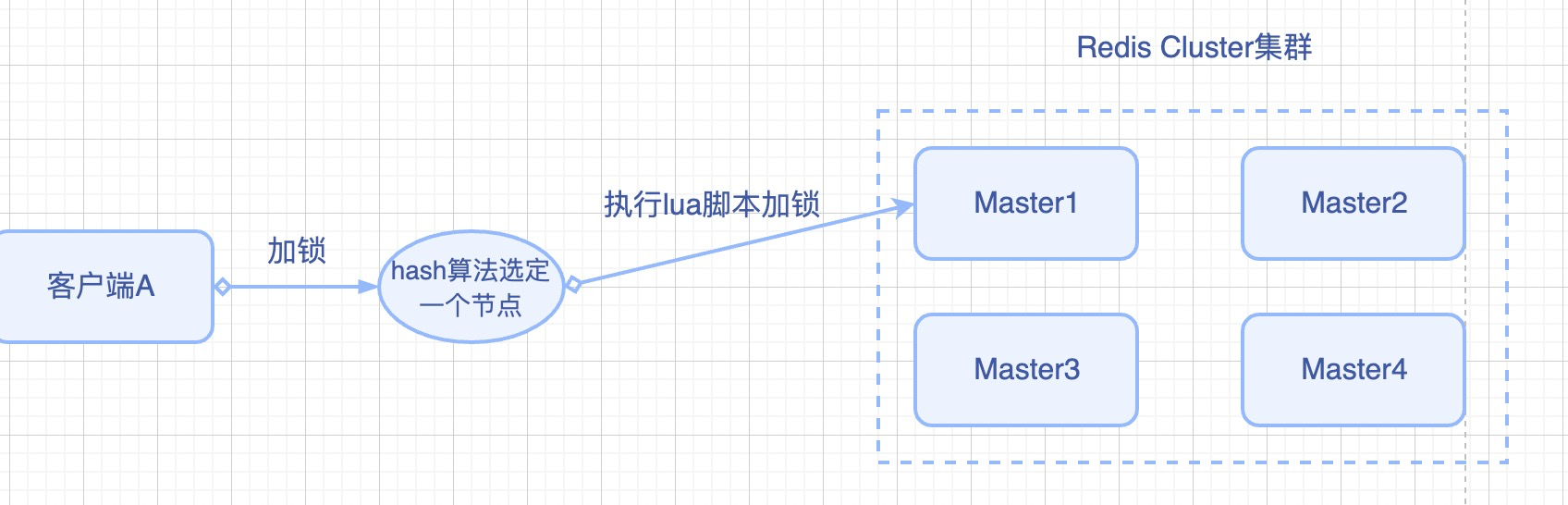
无论是RedLock也好,Redisson也罢,它们实现分布式锁时,都需要借助”看看是否已经有人创建了这个KEY->尝试创建KEY”这项动作。如下图所示:
Redisson的使用方式:
// 准备为名为”mylock”的key加锁
RLock lock = redisson.getLock(“mylock”);
// 加锁
lock.lock();
// 解锁
lock.unlock();
Redisson可以支持Redis单实例、Redis Cluster、Redis Sentinal、Redis Mater-slave等各种部署架构。下面以Redis Cluster架构为例,简要的叙述执行过程。
Step1: 加锁
客户端集成Redisson,在加锁之前,首先需要通过hash算法选定集群内某一个Redis Master,后续加锁、解锁等各种过程都是在这个Redis Master和与之绑定的slave节点之间。
Step2: 执行lua脚本实现加锁
lua脚本如下所示,其中
KEYS[1]: 我们准备加锁的Key。
ARGV[1]: key的生存时间(看作ttl吧),默认30秒。
ARGV[2]: 加锁的客户端的ID,类似这种形式: 8743c9c0-0795-4907-87fd-6c719a6b4586:1
首先,判断锁是否存在——exists()
接着,创建锁(插入key)——hset()
最后,设置生存时间——pexpire()
“if (redis.call(‘exists’, KEYS[1]) == 0) then” +
“redis.call(‘hset’, KEYS[1], ARGV[2], 1)” +
“redis.call(‘pexpire’, KEYS[1], ARGV[1]);” +
“return nil;” +
“end; “ +
“if (redis.call(‘hexists’, KEYS[1], ARGV[2]) == 1) then “ +
“redis.call(‘hincrby’, KEYS[1], ARGV[2], 1); “ +
“redis.call(‘pexpire’, KEYS[1], ARGV[1]); “ +
“return nil; “ +
“end; “ +
“return redis.call(‘pttl’, KEYS[1]);”
执行后返回:
mylock:
{
“8743c9c0-0795-4907-87fd-6c719a6b4586:1”: 1
}
其中,最右边的1就是针对客户端的加锁次数。
如果此时另一个客户端也来对同一个key进行加锁,会出现什么情况呢?
首先,lua脚本内的第一个if中,执行exists()方法后发现key已存在,因此开始执行第2个if。接着,通过hexists()方法获取这个key绑定的客户端id,判断是否为当前请求加锁的客户端id(明显不是啊),最后客户端2会获取到这个key的剩余生存时间,此时客户端2的redisson会进入while循环,不停地尝试加锁。
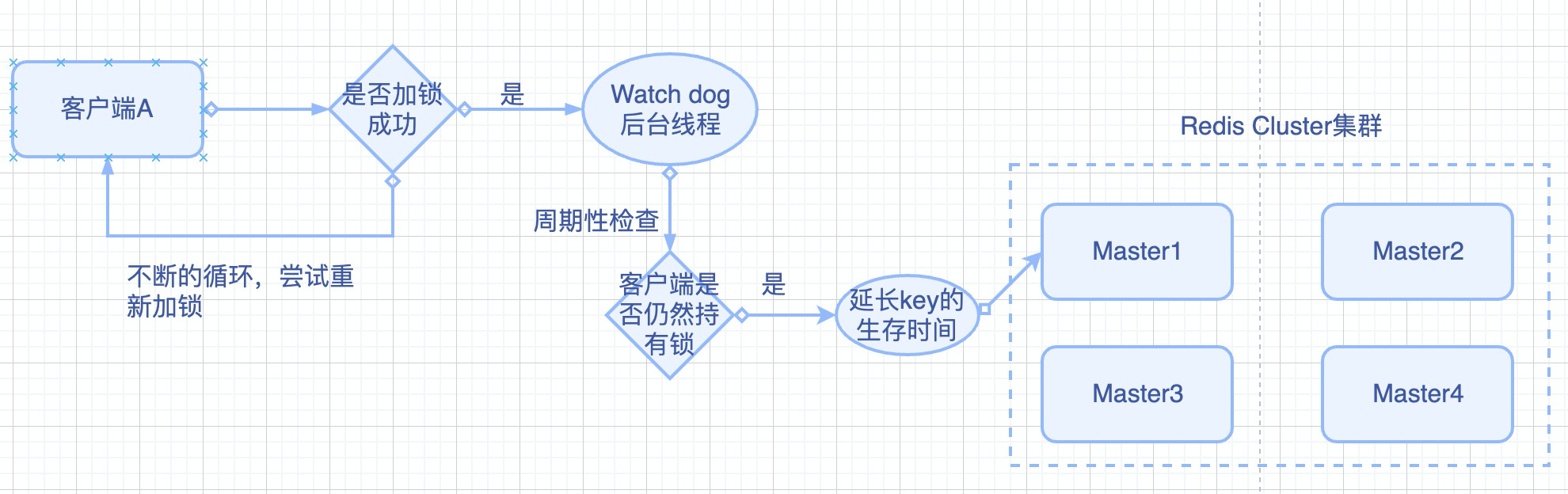
Step3: watch dog自动延期机制
watch dog是一个后台线程,它会每隔10秒观察当前客户端是否仍然持有锁,如果持有,说明客户端可能仍然在使用锁,因此延长锁的剩余生存时间。
Step4: 可重入锁机制
如果客户端1已经持有了这把锁,接着又加了一次锁,会怎么样呢?
比如下面的代码:
RLock lock = redisson.getLock(“myLock”);
lock.lock();
// 业务代码…
lock.lock();
// 业务代码…
lock.unlock();
lock.unlock();
此时可以看看lua脚本。
当执行第二个lock.lock()时,lua脚本内的第一个if显然不成立,因为锁尚未被释放。第二个if中,由于hexists()方法返回的客户端ID相同,因此进入处理可重入锁的逻辑片段:
incrby mylock 8743c9c0-0795-4907-87fd-6c719a6b4586:1 1
1
这条命令使得对客户端1的加锁次数累加1。因此lua脚本执行后,返回得到的结果为:
mylock:
{
“8743c9c0-0795-4907-87fd-6c719a6b4586:1”: 2
}
Step5: 释放锁机制
如果执行lock.unlock(),Redis会找到上方mylock数据结构,将加锁次数减一。如果减完后发现加锁次数为0,则说明当前客户端不再持有锁,因此执行: del mylock命令, 从Redis中删除这条key。
三. 各项分布锁的比较
借助Redis实现分布式锁时,有一个共同的缺陷: 当获取锁被决绝后,需要不断的循环,重新发送获取锁(创建key)的请求,直到请求成功。这就造成空转,浪费宝贵的CPU资源。
RedLock算法本身有争议,并不能保证健壮性。
Redisson实现分布式锁时,除了将key新增到某个指定的master节点外,还需要由master自动异步的将key和value等数据同步至绑定的slave节点上。那么问题来了,如果master没来得及同步数据,突然发生宕机,那么通过故障转移和主备切换,slave节点被迅速升级为master节点,新的客户端加锁成功,旧的客户端的watch dog发现key存在,误以为旧客户端仍然持有这把锁,这就导致同时存在多个客户端持有同名锁的问题了。
反观Zookeeper,它在实现分布式锁时,通过在ZK上注册监听器,不需要不断的主动尝试获取锁,因此性能开销小。

若有收获,就点个赞吧
0 人点赞
