8.1 文件
8.1.1 文件与文件流
文件用来存放数据的。文件在程序中以流的方式进行操作,输入流指数据从数据源 → 内存,输出流反之。数据源
8.1.2 文件类的构造器
java.io包中提供了File类,通过实例化该类可以实例化一个文件对象(这里的对象在内存而非实际的文件)。该类提供了四种构造方法,如下:
File(String)
通过将给定string转换成abstract pathname的方式实例化一个File对象。这里的抽象路径我简单理解为转换成与具体操作系统无关的一种路径形式,能够根据不同的系统自动转换成能读取的路径名。
File(File, String)
根据父抽象路径名和子路径字符串实例化一个File对象。
File(String, String)
根据父路径字符串和子路径字符串实例化一个File对象。
File(URI)
通过将给定的URI转化为abstract pathname的方式实例化一个File对象。
8.1.3 文件类的方法
当实例化一个文件对象后,就可以调用相关方法对文件进行操作了,下面介绍些常用的方法。
8.1.3.1 创建文件
通过file.createNewFile()可以创建一个实实在在的文件,即存在于硬盘中可见的。
8.1.3.2 读取文件对象信息
getName():获取文件或目录名getAbsolutePath():获取绝对路径getParent():获取父目录length():获取文件的大小exists():判断文件或目录是否存在isFile():判断是否为文件对象(前提:文件得存在)isDirectory():判断是否为目录(前提:目录得存在)
8.1.3.3 目录的操作和文件删除
mkdir():创建单级目录mkdirs():创建多级目录delete():删除空目录或文件
8.2 IO流原理及流的分类
8.2.1 IO流原理
java中,数据的输入、输出操作都是以流的方式进行的java.io包下提供了各种“流”类和接口,来获取不同种类的数据,并通过方法输入、输出数据- 输入
input,指读取外部数据到内存中 - 输出
output,指将内存中的数据输出到外部
8.2.2 流的分类

8.2.3 io流的体系图
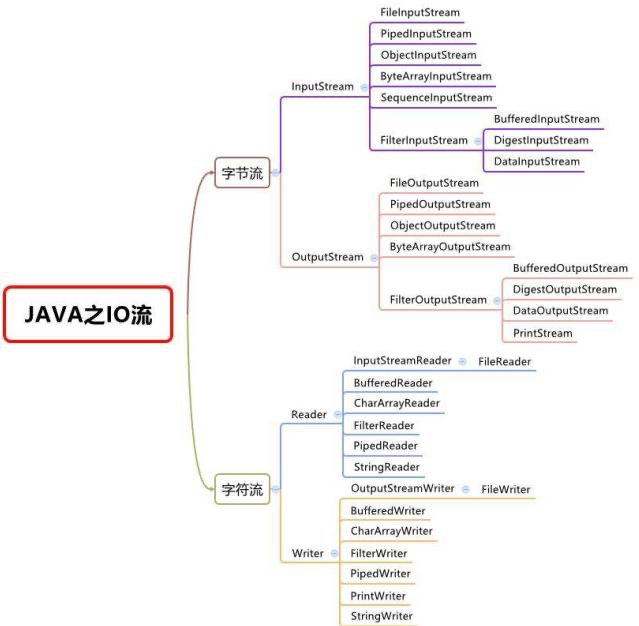
由上图可知,除了四个顶级父类(抽象类)之外,其他所有类都是派生于这四个顶级类的。所以针对其他类,只要看其后缀,就应该立刻明白其是输入还是输出流,它处理的对象是字节还是字符。
8.3 有关文件流讲解
这里主要针对文件系统的相关流进行了总结。文件系统只是和内存进行数据交互的一种外部渠道,但是即常见也重要。
8.3.1 FileInputStream
该类主要是用来处理文件输入字节流的,有三个构造器:
FileInputStream(File)FileInputStream(String)FileInputStream(FileDescriptor)
其方法也很多,比较重要的就是read()和read(byte[])。这是两个重载方法,第一个方法每次读取一个字节,第二个方法将一次读取指定大小的字节数组。
下面代码将使用这两种方法来读取hello.txt文件,该文件内容为字符串hello, world!。
// 1. 使用read()读取File file = new File("/Users/tianyichen/hello.txt");int readData = 0;FileInputStream fileInputStream = null;// 使用FileInputStream对象读取hello.txt的内容到控制台try {fileInputStream = new FileInputStream(file);while ((readData = fileInputStream.read()) != -1) {System.out.print((char) readData);}} catch (IOException e) {System.out.println(e.getMessage());} finally {try {fileInputStream.close();} catch (IOException e) {e.printStackTrace();}}代码分析: 首先会将txt文件的内容进行编码,之后会将编码后的结果,逐个字节赋值给readData,由于该文件内容的每个字符都可以用一个字节进行编码,所以解码后自然不会产生乱码。另外readData存储的值为int类型,实际上存储的就是每个字符的ascii十进制值。// 2. 使用read(byte[])读取int readLen = 0;byte[] byteArray = new byte[16];FileInputStream fileInputStream = null;try {fileInputStream = new FileInputStream(file);while ((readLen = fileInputStream.read(byteArray)) != -1) {System.out.println(new String(byteArray, 0, readLen));}} catch (IOException e) {e.printStackTrace();} finally {try {fileInputStream.close();} catch (IOException e) {e.printStackTrace();}}代码分析: 使用该方式相当于设置了一个缓冲区,缓冲区的大小为指定的byte数组的大小,比如这里设置为16,说明缓冲区大小为长度为16的字节数组。此时对文件进行读取时,将一次性的读取16个字节的文件内容到缓冲区中,该方法的返回值为存放在缓冲区内的字节个数,比如这里由于hello, world!占13个字节,所以这里的长度为13。由于13 < 16,所以一次性就可以读完该文件的全部内容。
8.3.2 FileOutputStream
该类的构造器如下,其中带有append参数的表示追加写入。
FileOutputStream(String): 如果目录不存在,write会失败FileOutputStream(file)FileOutputStream(file, boolean append)FileOutputStream(String, boolean append)FileOutPutStream(FileDescriptor)
该类的重要方法有两个,write(int)和write(byte[] b),前者接受一个int类型参数,但实际写入时只写入低8位,其他三个字节被舍弃,比如write(65)就是写入字符’A’;后者写入一个byte数组,效率比起前者更高。
简单案例理解方法的使用:
// 1. write(int)的使用String filename = "/Users/tianyichen/demo/hello.txt";FileOutputStream fileOutputStream = null;try {fileOutputStream = new FileOutputStream(filename);fileOutputStream.write(65);} catch (IOException e) {e.printStackTrace();} finally {try {fileOutputStream.close();} catch (IOException e) {e.printStackTrace();}}代码分析: 由于demo这个目录名不存在,所以write报错了。如果文件名不存在,会自动创建,无需担心。-------------// 2. 将字符串hello, world追加写入hello.txt,使用write(byte[] b)方法效率更高String s = "hello, world";try {fileOutputStream = new FileOutputStream(filename, true);fileOutputStream.write(s.getBytes());} catch (IOException e) {e.printStackTrace();} finally {try {fileOutputStream.close();} catch (IOException e) {e.printStackTrace();}}
8.3.3 FileReader和FileWriter
FileReader有5个构造器,没有方法实现,其方法都继承了父类InputStreamReader和Reader的方法。构造器定义如下:
FileReader(file)FileReader(String)FileReader(FileDescriptor)
FileWriter有9个构造器,同样没有方法声明。方法同样继承其父类OutputStreamWriter和Writer。
FileWriter(file)FileWriter(file, boolean append)FileWriter(String)FileWriter(String, boolean append)FileWriter(FileDescriptor)
FileReader使用案例
// 1. 使用read()一个字符一个字符的读取String filePath = "/Users/tianyichen/story.txt";FileReader fr = null;int data = 0;try {fr = new FileReader(filePath);while ((data = fr.read()) != -1) {System.out.print((char) data);}} catch (IOException e) {e.printStackTrace();} finally {if (fr != null) {try {fr.close();} catch (IOException e) {e.printStackTrace();}}}// 2. 以字符数组的方式读取int dataLen = 0;char[] cbuf = new char[100];try {fr = new FileReader(filePath);while ((dataLen = fr.read(cbuf)) != -1) {System.out.println(new String(cbuf, 0, dataLen));}} catch (IOException e) {e.printStackTrace();} finally {if (fr != null) {try {fr.close();} catch (IOException e) {e.printStackTrace();}}}
FileWriter使用案例
String filePath = "/Users/tianyichen/note.txt";FileWriter fw = null;try {fw = new FileWriter(filePath);fw.write(new String("风雨之后,才见彩虹").toCharArray());} catch (IOException e) {e.printStackTrace();} finally {try {if (fw != null) {fw.close();}} catch (IOException e) {e.printStackTrace();}}
8.4 节点流和处理流
8.4.1 概念解析
节点流用于处理点到点的数据传输,有一个明确的数据源,它处理的对象是节点;处理流是包装在节点流之上,以增强节点流的读写能力为目的,它处理的对象是节点流对象。
下图为节点流和处理流的总览图:
节点流和处理流的主要区别有以下几点:
- 节点流是底层流,直接与数据库相连
- 处理流包装节点流,既可以消除不同节点流的差异,也能提供更方便的方法完成输入输出
- 节点流使用了修饰器设计模式,不会与数据源直接相连
处理流的优点如下:
- 主要以增加缓冲区来提高读写效率
- 提供了一系列便捷的方法来一次读写大批量的数据,更加灵活便捷
8.4.2 BufferedReader与BufferedWriter
二者都属于字符处理流,关闭时只需要关闭外层流即可。
通过阅读源码可知,在构造BufferedReader和BufferedWriter对象时,底层初始化了一个大小为8KB的缓冲区(char[]),直接从缓冲区读取可以减少io数,提高效率。
BufferedReader应用举例:
String filePath = "/Users/tianyichen/iofile/hello.java";String line;BufferedReader br = null;try {br = new BufferedReader(new FileReader(filePath));while ((line = br.readLine()) != null) {System.out.println(line);}} catch (IOException e) {e.printStackTrace();} finally {if (br != null) {try {br.close();} catch (IOException e) {e.printStackTrace();}}}
BufferedWriter应用举例:
String filePath = "/Users/tianyichen/iofile/gushi.txt";BufferedWriter bw = null;try {bw = new BufferedWriter(new FileWriter(filePath));bw.write("人生得意须尽欢");bw.newLine();bw.write("莫使金樽空对月", 0, 4);} catch (IOException e) {e.printStackTrace();} finally {if (bw != null) {try {bw.close();} catch (IOException e) {e.printStackTrace();}}}
8.4.3 BufferedInputStream和BufferedOutputStream
BufferedInputStream用来处理字节流,在实例化对象时,底层创建了一个长度为8k的byte[];BufferedOutputStream同样处理字节流,它会将内容写入缓冲区,当缓冲区满时写入文件,减少了io次数,提高了效率。
以下代码演示通过这两个类实现图片的复制:
String src = "/Users/tianyichen/iofile/jobs.jpg";String dest = "/Users/tianyichen/iofile/copyjobs.jpg";BufferedInputStream bis = null;BufferedOutputStream bos = null;int readLen = 0;byte[] cbuf = new byte[1024];try {bis = new BufferedInputStream(new FileInputStream(src));bos = new BufferedOutputStream(new FileOutputStream(dest));while ((readLen = bis.read(cbuf)) != -1) {bos.write(cbuf, 0, readLen);}} catch (IOException e) {e.printStackTrace();} finally {try {if (bis != null) {bis.close();}if (bos != null) {bos.close();}} catch (IOException e) {e.printStackTrace();}}代码分析: 在第8行定义了一个长度为1024的byte数组,用于接收从缓冲区获得的数据,避免逐个字节的去读。这里需要区分自定义的byte数组和Buffered流底层创建数组的区别。简单解释为,Buffered流底层创建的数组在内存中是一块特殊的区域叫缓冲区,在读文件时,我们首先会new一个Buffered流的对象,此时底层的缓冲区已经分配好了,我们自定义的数组不过是从这个缓冲区去读写数据,而非直接从外部设备读取,这两个都可以叫缓冲区,因为同在内存中且同为byte数组,但是还是有本质区别。
8.4.4 对象流-ObjectInputStream和ObjectOutputStream
对象流的概念
对象流提供了对基本类型或对象类型的序列化和反序列化的方法。
所谓序列化指的是:保存数据时,保存数据的值和数据类型;所谓反序列化:恢复数据时,既恢复数据的值,也恢复数据的类型。
对象想要进行序列化,必须实现Serializable或Externalizable接口。
FileOutputStream代码示例
***先后写入了5个对象,Dog与SmallDog类的定义未展示***String filePath = "/Users/tianyichen/iofile/data.dat";ObjectOutputStream oos = null;try {oos = new ObjectOutputStream(new FileOutputStream(filePath));// 写入基本数据类型oos.writeInt(26);oos.writeBoolean(false);oos.writeUTF("dog is cute");// 写入一个Dog类对象oos.writeObject(new Dog("小黄", 3));oos.writeObject(new SmallDog("小小黄", 1, "very small"));} catch (IOException e) {e.printStackTrace();} finally {try {if (oos != null) {oos.close();}} catch (IOException e) {e.printStackTrace();}}
FileInputStream代码示例
String filePath = "/Users/tianyichen/iofile/data.dat";ObjectInputStream ois = null;try {ois = new ObjectInputStream(new FileInputStream(filePath));System.out.println(ois.readInt());System.out.println(ois.readBoolean());System.out.println(ois.readUTF());System.out.println(ois.readObject());System.out.println(ois.readObject());} catch (IOException | ClassNotFoundException e) {e.printStackTrace();} finally {if (ois != null) {try {ois.close();} catch (IOException e) {e.printStackTrace();}}}
注意事项
- 对象的读写顺序需要一致
- 要求序列化和反序列化的对象,必须实现
Serializable接口 - 序列化的类建议添加
SerialVersionUID,提高版本兼容性(有关SerialVersionUID的解释) - 序列化对象时,默认将里面的所有属性都进行了序列化,除了
static和transient修饰的成员 - 序列化对象时,需要里面属性的类型也实现序列化接口
- 序列化具备继承性,即如果某类已经实现了序列化,则它的所有子类也已经默认实现了序列化
8.4.5 标准输入输出流
| 编译类型 | 运行类型 | 默认设备 | |
|---|---|---|---|
System.in (标准输入) |
InputStream |
BufferedInputStream |
键盘 |
System.out(标准输出) |
PrintStream |
PrintStream |
显示器 |
8.4.6 转换流-InputStreamReader和OutputStreamWriter
转换流可以将字节流转换成字符流,并指定编码的方式。
InputStreamReader
- 是Reader的子类,可以将InputStream转换成Reader
- 可以在转换的时候指定编码方式
使用案例:将字节流FileInputStream转换成字符流InputStreamReader,对文件进行读取,进而再包装成BufferedReader。
// 异常声明在方法中,所以代码不包含try-catch了。
// 本案例相当于包装了两层,第一层进行转换,第二层进行读取
String filePath = "/Users/tianyichen/iofile/f1.txt";
FileInputStream fis = new FileInputStream(filePath);
InputStreamReader isr = new InputStreamReader(fis, "utf-8");
BufferedReader br = new BufferedReader(isr);
String s = br.readLine();
System.out.println(s);
br.close();
OutputStreamWriter
- 该类为Writer的子类,实现将OutputStream转换成Writer
- 可以在转换的时候指定编码方式
使用案例:将字符串以gbk编码方式输出到文件f2.txt中。
String filePath = "/Users/tianyichen/iofile/f2.txt";
FileOutputStream fos = new FileOutputStream(filePath);
OutputStreamWriter osw = new OutputStreamWriter(fos, "GBK");
osw.write("不知天上宫阙,今夕是何年?");
osw.close();
8.4.7 打印流-PrintStream和PrintWriter
打印流只有输出流,没有输入流。可以在构造方法中指定打印的位置。比较简单不举例了,参考该文。
8.4.8 Properties类
8.4.8.1 不使用Properties读取配置文件
String filePath = "./src/mysql.properties";
BufferedReader br = new BufferedReader(new FileReader(filePath));
String s = "";
while((s = br.readLine()) != null) {
String[] strArr = s.split("=");
System.out.println(strArr[0] + "的值为: " + strArr[1]);
}
代码分析: 该方式使用io操作+字符串操作来读取配置文件,麻烦不灵活,且代码量大
8.4.8.2 Properties类解析
Properties是Hashtable的子类,实现了Map接口- 使用特点与
Hashtable类似 - 用于读取xxx.properties配置文件
Properties类的常用方法如下:
- load: 加载配置文件的键值对到Properties对象
- list: 将数据显示到指定设备
- getProperty(key): 根据key获取对应值,底层使用put方法
- setProperty(key, value): 设置key对应的值
- store: 将Properties中的键值对存储到配置文件,如果含有中文,存储为unicode码
配置文件需要注意以下两点:
- 等号两边不能带空格
- 值不需要用双引号括起来,默认为
String类型
8.4.8.3 代码示例
// 1. 读取配置文件
String filePath = "./src/mysql.properties";
Properties ppt = new Properties();
ppt.load(new FileInputStream(filePath));
System.out.println("ip=" + ppt.getProperty("ip"));
System.out.println("user=" + ppt.getProperty("user"));
System.out.println("pwd=" + ppt.getProperty("pwd"));
// 2. 创建、修改配置文件
String filePath2 = "./src/mysql2.properties";
Properties ppt2 = new Properties();
ppt2.setProperty("charset", "utf-8");
ppt2.setProperty("user", "Tom");
ppt2.setProperty("pwd", "54321");
ppt2.store(new FileOutputStream(filePath2), "comments");
System.out.println("保存配置文件成功");
代码分析:
- setProperty()底层调用了hashtable的put方法, 如果key不存在,就相当于添加;如果key已存在,就相当于替换
- store(Writer[OutputStream], String)用来创建properties配置文件,第二个参数用于配置文件的注释,如果不需要可以填null

若有收获,就点个赞吧
0 人点赞
