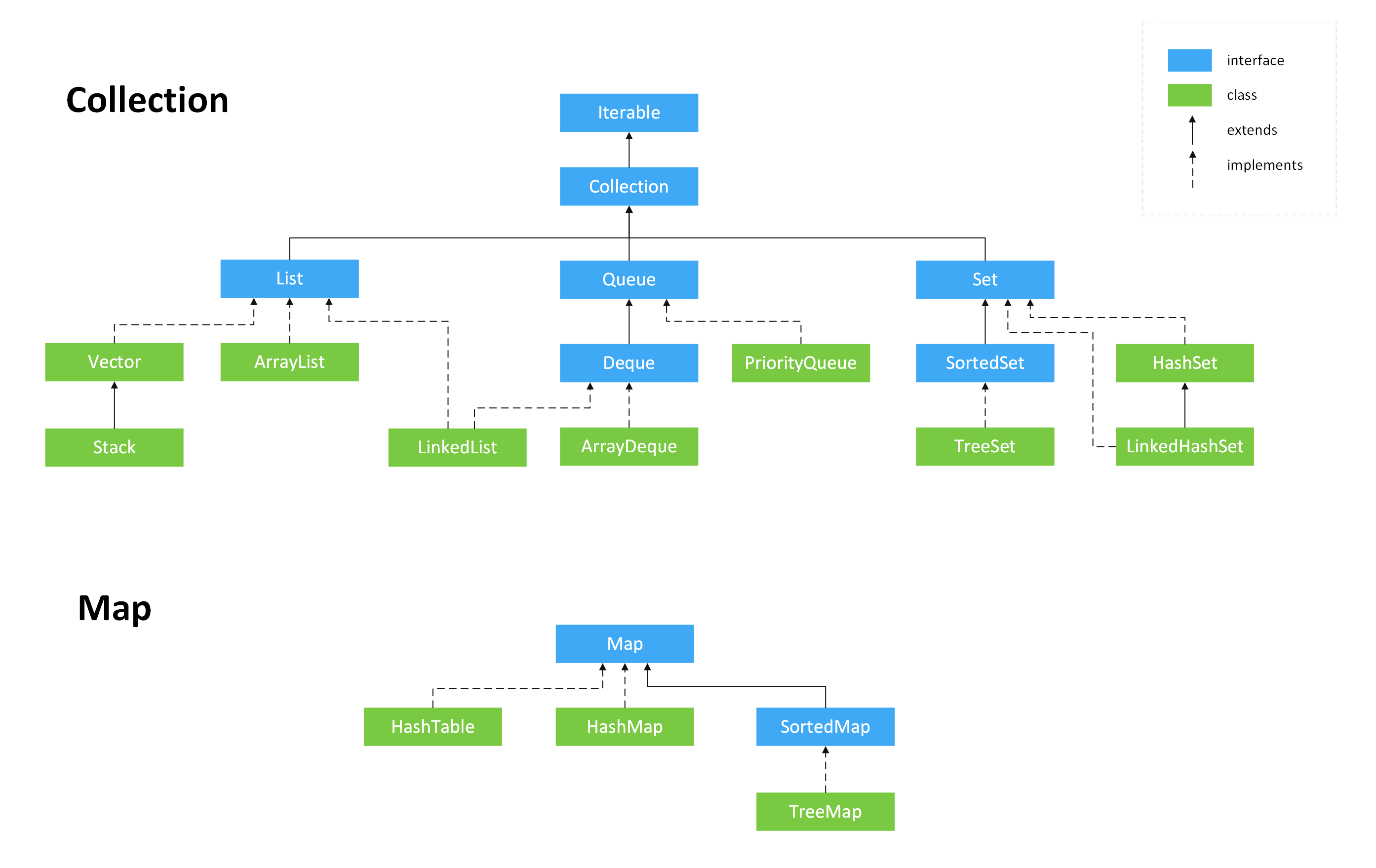
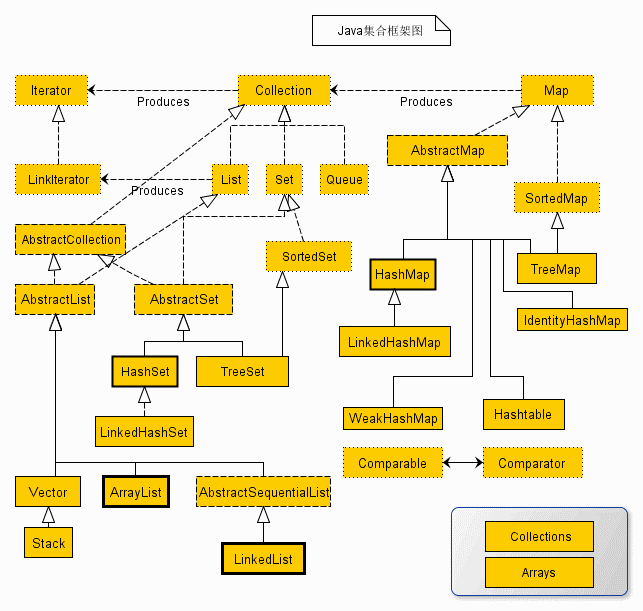
集合
- List(对付顺序的好帮手): 存储的元素是有序的、可重复的。
- Set(注重独一无二的性质): 存储的元素是无序的、不可重复的。
- Queue: 按特定的排队规则来确定先后顺序,存储的元素是有序的、可重复的。
- Map(用 key 来搜索的专家): 使用键值对(key-value)存储,类似于数学上的函数 y=f(x),”x” 代表 key,”y” 代表 value,key 是无序的、不可重复的,value 是无序的、可重复的,每个键最多映射到一个值。
集合和数组的区别:
1.数组长度在初始化时指定,意味着只能保存定长的数据。而集合可以保存数量不确定的数据。同时可以保存具有映射关系的数据(即关联数组,键值对 key-value)。
2.数组元素既可以是基本类型的值,也可以是对象。集合里只能保存对象(实际上只是保存对象的引用变量),基本数据类型的变量要转换成对应的包装类才能放入集合类中。 链接:https://www.jianshu.com/p/589d58033841
- 泛型容器类,不能兼容null
-
数组
private void grow(int minCapacity) {// 数组扩容elementData = Arrays.copyOf(elementData, newCapacity);}
数组排序
public void test() {String[] strs = new String[]{"abf", "abcd", "abb"};Arrays.sort(strs); // abb, abcd, abf}
Iterator和ListIterator
Iterator接口是Collection接口的父接口,主要用于遍历集合中的元素。
public class IteratorExample {public static void main(String[] args){List<String> list =Arrays.asList("java语言","C语言","C++语言");Iterator<String> iterator = list.iterator();while(iterator.hasNext()){// 集合元素的值传给了迭代变量,仅仅传递了对象引用。// 保存的仅仅是指向对象内存空间的地址String next = iterator.next();next ="修改后的";System.out.println(next);}System.out.println(list);}}
与Iterator相比,ListIterator增加了前向迭代的功能(
hasPrevious()、previous),还可以通过add()方法向List集合中添加元素。RandomAccess 接口
RandomAccess 接口不过是一个标识罢了,标识实现这个接口的类具有随机访问功能,ArrayList 实现了 RandomAccess 接口。
public interface RandomAccess {}
Set
性能对比
EnumSet性能 > HashSet性能 > LinkedHashSet > TreeSet性能
- EnumSet内部以位向量的形式存储,结构紧凑、高效,且只存储枚举类的枚举值,所以最高效。
- HashSet以hash算法进行位置存储,特别适合用于添加、查询操作。
- LinkedHashSet由于要维护链表,性能比HashSet差点,但是有了链表,LinkedHashSet更适合于插入、删除以及遍历操作。
- TreeSet需要额外的红黑树算法来维护集合的次序,性能最次。
HashSet
HashSet如何检查重复
两个对象比较 具体分为如下四个情况:
1.如果有两个元素通过equal()方法比较返回false,并且它们的hashCode()方法返回不相等,HashSet将会把它们存储在不同的位置。
正常添加
2.如果有两个元素通过equal()方法比较返回true,但它们的hashCode()方法返回不相等,HashSet将会把它们存储在不同的位置。
说明没有同时重写equal和hashCode,不是正常情况
3.如果两个对象通过equals()方法比较不相等,hashCode()方法比较相等,HashSet将会把它们存储在相同的位置,在这个位置以链表式结构来保存多个对象。这是因为当向HashSet集合中存入一个元素时,HashSet会调用对象的hashCode()方法来得到对象的hashCode值,然后根据该hashCode值来决定该对象存储在HashSet中存储位置。
出现了哈希碰撞,说明hashCode算法不好,应尽量避免
4.如果有两个元素通过equal()方法比较返回true,但它们的hashCode()方法返回true,HashSet将不予添加。
正常的重复元素,不添加
HashSet判断两个元素相等的标准:两个对象通过equals()方法比较相等,并且两个对象的hashCode()方法返回值也相等。
相当于HashMap的key集合
HashSet的实质是一个HashMap。HashSet的所有集合元素,构成了HashMap的key,其value为一个静态Object对象。
LinkedHashSet类
- 使用双向链表维护元素的次序,使得元素是以插入的顺序来保存的。
当遍历LinkedHashSet集合里的元素时,LinkedHashSet将会按元素的添加顺序来访问集合里的元素。
TreeSet
TreeSet中的可变变量被修改后,TreeSet不会再次调整它们的顺序,推荐不要修改放入TreeSet集合中元素的关键实例变量。
Sorted和Comparable,Comparator
sorted():自然排序,流中元素需实现Comparable接口
Java的一些常用类已经实现了Comparable接口,并提供了比较大小的标准。例如,String按字符串的UNICODE值进行比较,Integer等所有数值类型对应的包装类按它们的数值大小进行比较。
@Datapublic class MenuDto implements Comparable<MenuDto>, Serializable {@Overridepublic int compareTo(MenuDto dto) {return this.sortNum - dto.getSortNum();}}
sorted(Comparator comparator):Comparator排序器自定义排序 ```java private List
searchRoots(List tblMenus) { return menuDtos.stream()
.sorted(Comparator.comparing(MenuDto::getSortNum)).collect(Collectors.toList());
}
// Comparator.nullsLast
private List
return menuDtos.stream().sorted(Comparator.comparing(MenuDto::getSortNum, Comparator.nullsLast(Integer::compareTo))).collect(Collectors.toList());
}
```javapublic void customSorted() {Stream<String> stringStream = Stream.of("a1", "c6", "b3");stringStream.sorted(Comparator.comparingInt(x -> Integer.parseInt(x.substring(1)))).forEach(System.out::println);}
- 一个类实现了 Comparable 接口,意味着该类的对象可以直接进行比较(排序),但比较(排序)的方式只有一种,很单一。
一个类如果想要保持原样,又需要进行不同方式的比较(排序),就可以定制比较器(实现 Comparator 接口)。
TreeSet和TreeMap插入时就自动排序,无需调用sorted()
- TreeSet要求存放的对象所属类必需实现Comparable接口,该接口提供了比较元素的 compareTo( ) 方法,当插入元素的时候会回调该方法比较元素的大小。
- TreeMap要求存放的键值对映射的键必须实现Comparable接口从而根据键对元素进行排序。
TreeSet自然排序和判断相等
- 如果试图把一个对象添加到TreeSet时,则该对象的类必须实现Comparable接口,否则就会出现异常。
- 注意:TreeSet中只能添加同一种类型的对象,否则无法比较,会出现异常。
- 如果通过compareTo(Object obj)方法比较返回0,TreeSet则会认为它们相等,不予添加入集合内。
-
TreeSet定制排序
如果要实现定制排序,则需要在创建TreeSet时,调用一个带参构造器,传入Comparator对象。并由该Comparator对象负责集合元素的排序逻辑。
TreeSet<Person> set = new TreeSet<Person>(comparator);
EnumSet
EnumSet<ResponseStatus> sets = EnumSet.allOf(ResponseStatus.class);
EnumSet以枚举值在EnumSet类内的定义顺序来决定集合元素的顺序。
- EnumSet集合不允许加入null元素
List
List判断两个对象相等只要通过equals()方法比较返回true即可。// 重写了equals()方法,如果两个Book对象的name属性相同public static void main(String[] args){Book book1 = new Book();book1.name = "Effective Java";Book book2 = new Book();book2.name = "Effective Java";List<Book> list = new ArrayList<Book>();list.add(book1);list.remove(book2);// 输出结果:0System.out.println(list.size());}
性能对比
- 对于需要快速插入,删除元素,应该使用LinkedList。
- 对于需要快速随机访问元素,应该使用ArrayList。
ArrayList
ArrayList是一个动态扩展的数组,如果开始就知道ArrayList或Vector集合需要保存多少个元素,则可以在创建它们时就指定initalCapacity的大小,这样可以提高性能。遍历方式
性能:随机访问(索引序号) > for循环 > 迭代器Arrays.asList和List.of
- Arrays.asList使用指南,JDK11后推荐用List.of
- 不能将原生数据类型数据的数组作为参数
Array.asList返回的一个由指定数组生成的固定大小的 List
LinkedList(Deque接口)
LinkedList实现了Deque接口,可以被当作成双端队列来使用,因此既可以被当成“栈”来使用,也可以当成队列来使用。
Node<E> node(int index) {// assert isElementIndex(index);if (index < (size >> 1)) {Node<E> x = first;for (int i = 0; i < index; i++)x = x.next;return x;} else {Node<E> x = last;for (int i = size - 1; i > index; i--)x = x.prev;return x;}}
首先会比较“index”和“双向链表长度的1/2”;若前者小,则从链表头开始往后查找,直到index位置;否则,从链表末尾开始先前查找,直到index位置。这就是“双线链表和索引值联系起来”的方法。
到此我们便会明白,LinkedList在插入、删除元素时性能比较出色,随机访问集合元素时性能较差。
LinkedList支持多种遍历方式,采用逐个遍历的方式,效率比较高,采用随机访问的方式去遍历LinkedList的方式效率最低。
- 通过迭代器遍历LinkedList
- 通过快速随机访问遍历LinkedList
- 通过for循环遍历LinkedList
- 通过pollFirst()遍历LinkedList
- 通过pollLast()遍历LinkedList
- 通过removeFirst()遍历LinkedList
- 通过removeLast()遍历LinkedList
Quene
队列不允许随机访问队列中的元素。PriorityQueue
PriorityQueue 本质也是一个动态数组,在这一方面与ArrayList是一致的。
- 不是按添加顺序排序,Comparable自然排序或Comparator自定义排序,和TreeSet一样。
- 注意:如果多个元素都是最小值,则头是其中一个元素——选择方法是任意的。
- 不允许插入 null 元素
ArrayDeque(Deque接口)
维护的是循环数组和双指针,可以动态扩容。
ArrayDeque不是线程安全的。 当作为栈使用时,性能比Stack好;当作为队列使用时,性能比LinkedList好。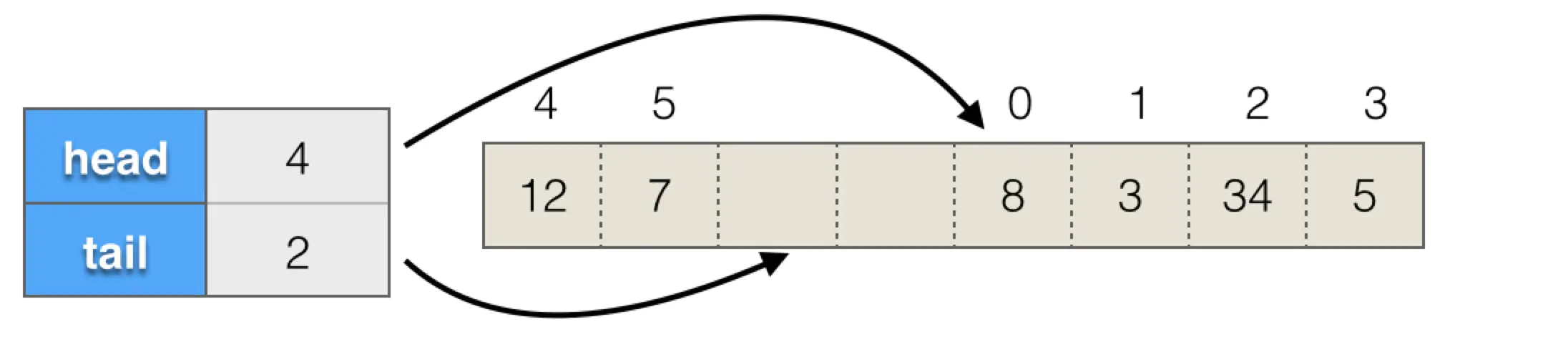
| ArrayDeque | LinkedList | |
|---|---|---|
| 底层数据 | 可变长的数组和双指针 | 链表 |
| 是否支持Nulll | 否 | 是 |
| 时间复杂度 | 插入时可能存在扩容过程, 不过均摊后的插入操作依然为 O(1) | 每次插入数据时均需要申请新的堆空间,均摊性能相比更慢 |
Map
性能及使用场景
HashMap > LinkedHashMap > TreeMap
- 一般的应用场景,尽可能多考虑使用HashMap,因为其为快速查询设计的。
- 如果需要特定的排序时,考虑使用TreeMap。
- 如果仅仅需要插入的顺序时,考虑使用LinkedHashMap。
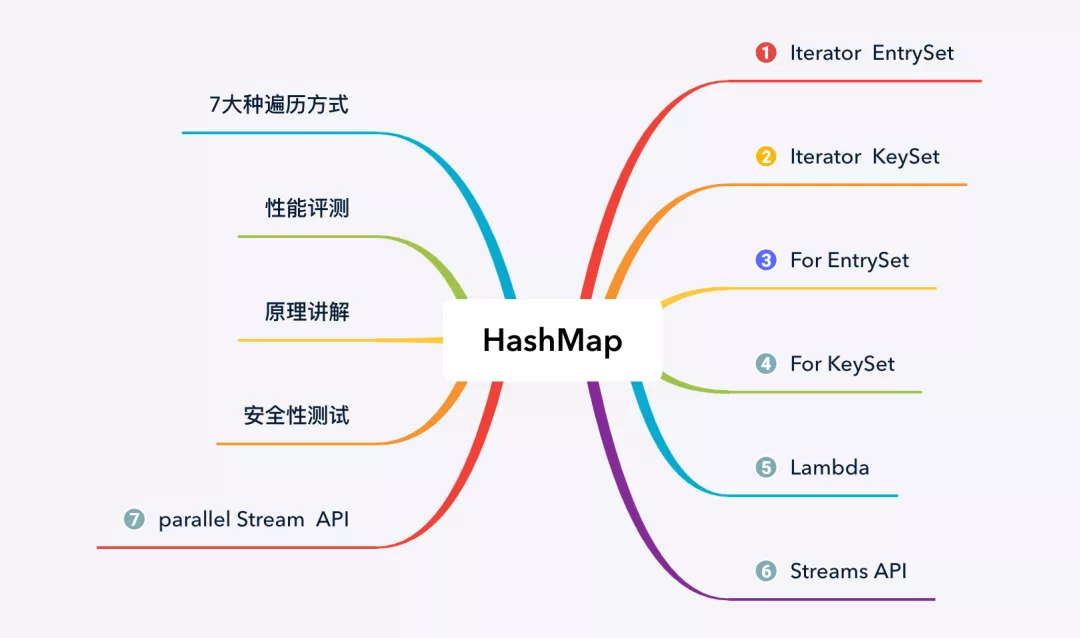
- HashMap 的 7 种遍历方式、性能分析和安全性分析
我们不能在遍历中使用集合 map.remove() 来删除数据,这是非安全的操作方式,但我们可以使用迭代器的 iterator.remove() 的方法来删除数据,这是安全的删除集合的方式。同样的我们也可以使用 Lambda 中的 removeIf 来提前删除数据,或者是使用 Stream 中的 filter 过滤掉要删除的数据进行循环,这样都是安全的,当然我们也可以在 for 循环前删除数据再遍历也是线程安全的。 我们应该尽量使用迭代器(Iterator)来遍历 EntrySet 的遍历方式来操作 Map 集合
HashMap
- HashMap可以使用null作为key或value,但 null 作为键只能有一个
- HashMap的哈希表可动态扩容
注意:如果是加入HashMap的key是个可变对象,在加入到集合后又修改key的成员变量的值,可能导致hashCode()值以及equal()的比较结果发生变化,无法访问到该key。一般情况下不要修改。
判断相等
key判断相等的标准: 两个key通过equals()方法比较返回true,两个key的hashCode值也相等
- value判断相等的标准: 两个对象通过equals()方法比较返回true
散列表
有没有一种数组结构來综合一下数组和链表,以便发挥它们各自的优势?答案是肯定的!就是:哈希表。哈希表具有较快(常量级)的查询速度,及相对较快的增刪速度。
“拉链法”解决哈希冲突,如果链表长度大于阈值,将链表转为红黑树。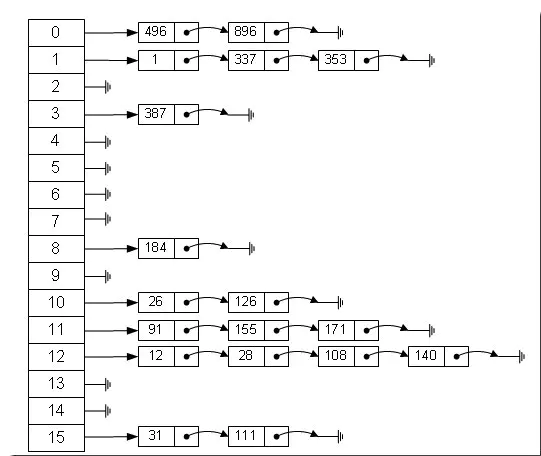
所以每个数组元素代表一个链表(红黑树),其中的共同点就是hash(key)相等。
遍历方式
getOrDefault
Map<String, Boolean> testMap = new HashMap();testMap.put("a", true);testMap.put("b", false);Boolean isValid =testMap.getOrDefault("c", false);
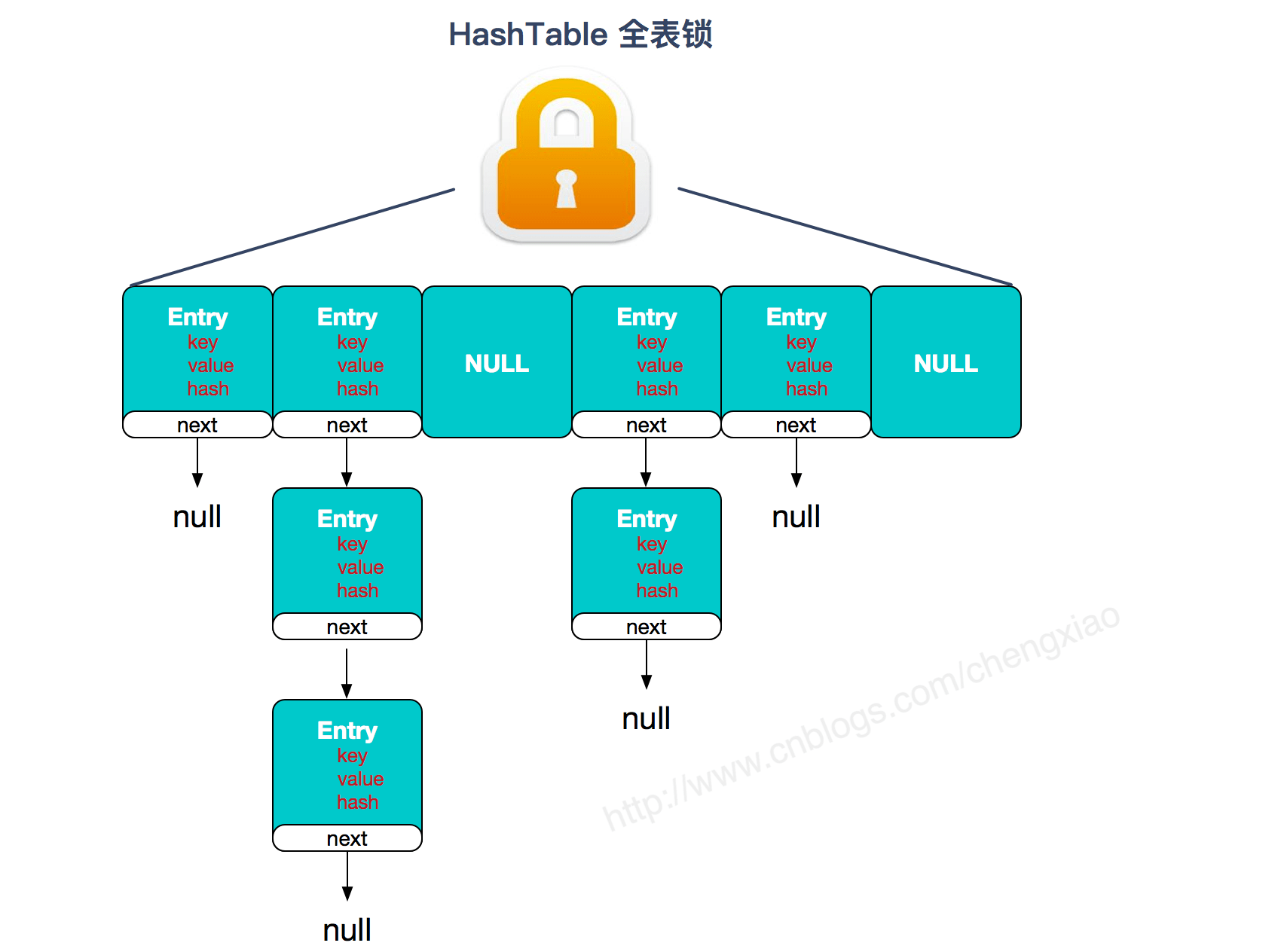
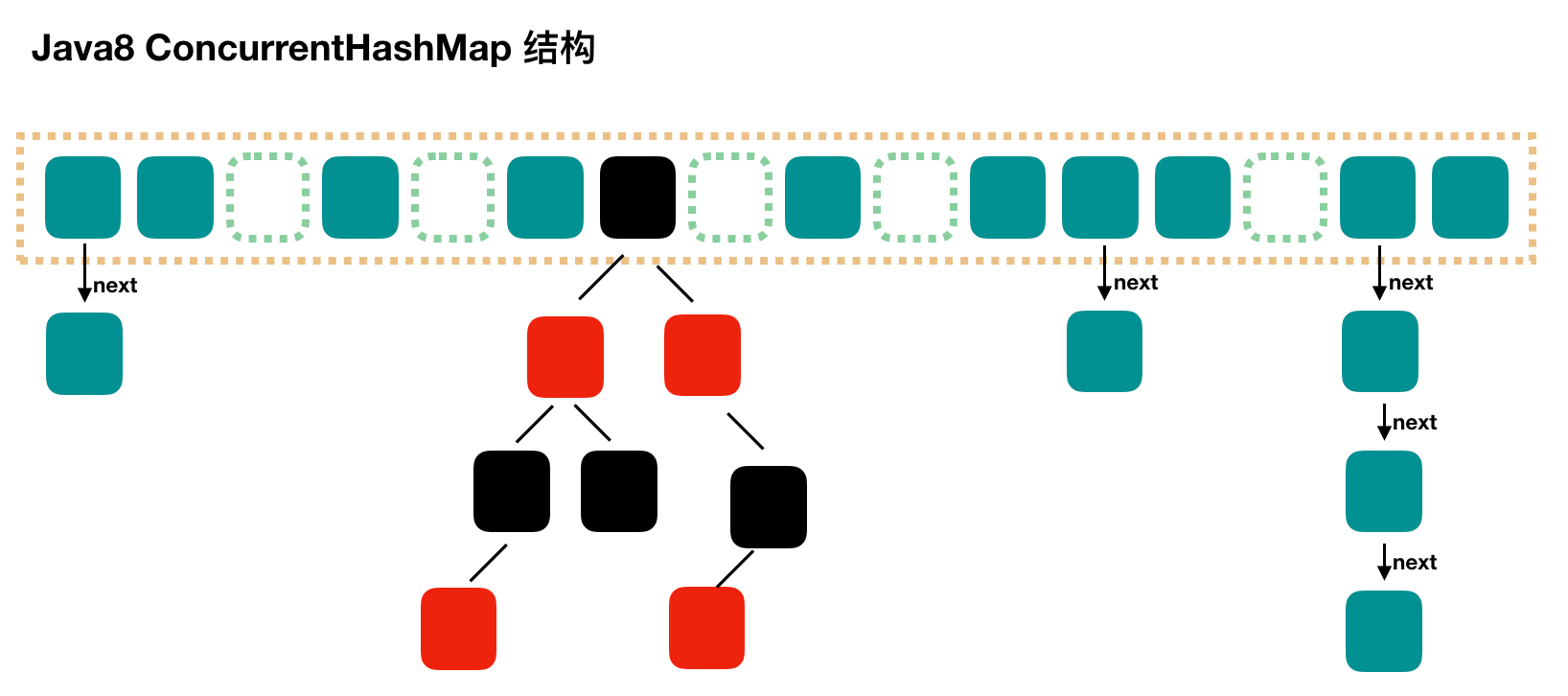
ConcurrentHashMap
- 数据结构:
Node 数组 + 链表或TreeNode 数组 + 红黑树 - 并发控制使用 synchronized 和 CAS 来操作
- synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发。
LinkedHashMap
- LinkedHashMap使用双向链表来维护key-value对的次序。
- LinkedHashMap需要维护元素的插入顺序,因此性能略低于HashMap的性能;但是因为它以链表来维护内部顺序,所以在迭代访问Map里的全部元素时有较好的性能。迭代输出LinkedHashMap的元素时,将会按照添加key-value对的顺序输出。
本质上来讲,LinkedHashMap=散列表+循环双向链表
TreeMap
每个key-value对即作为红黑树的一个节点
-
判断相等
判断两个key相等的标准是:两个key通过compareTo()方法返回0,TreeMap即认为这两个key是相等的。(重写equals()方法和compareTo()方法时应保持一致的返回结果,两个key通过equals()方法比较返回true时,它们通过compareTo()方法比较应该返回0)。
判断两个value相等的标准是:两个value通过equals()方法比较返回true
遍历方式
entrySet(),keySet(),value()
SortedMap: 根据键排序的能力
-
线程安全的集合类
ConcurrentHashMap、CopyOnWriteArrayList、CopyOnWriteArraySet、LinkedBlockingQuene、ConcurrentLinkedQuene问题
- Java 8 Iterable.forEach() vs foreach loop
stream不保证顺序
forEach vs forEachOrder: 虽然对串行stream来说forEach是按顺序的,但是可以显式地用forEachOrder,便于突出

若有收获,就点个赞吧
0 人点赞
